
MySQL笔记
一、MySQL基础架构
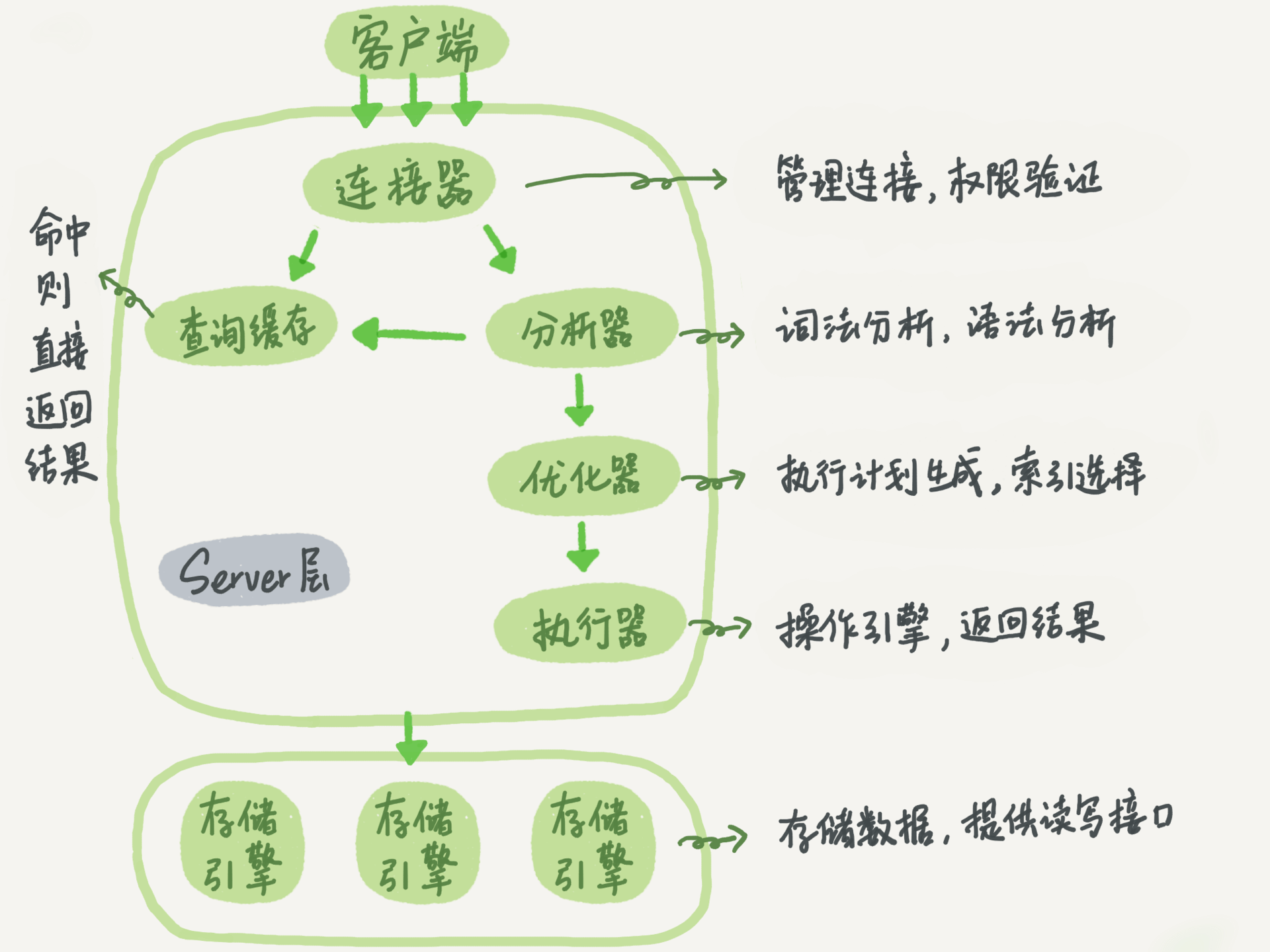
- MySQL架构可大体分为Server层和存储引擎两个部分
- Server层可分为连接器,分析器,优化器
- 存储引擎层负责数据的存储和提取。其架构模式是插件式的,需要在建表的时候,指定你需要的存储引擎,默认是Innodb。
连接器
- 连接器负责跟客户端建立连接、获取权限、维持和管理连接。
- 用户登录成功后连接器会查询权限表,后续操作均依赖此时的权限,若该用户后续权限变化需重新登录
- 连接默认时间为8小时,这个时间是由参数wait_timeout控制。
- 使用showprocesslist可以查看连接
- 连接类型分为长连接和短连接
- 短连接:每次执行完很少的几次查询就断开连接,下次查询再重新建立一个
- 长连接:连接成功后,如果客户端持续有请求,则一直使用同一个连接
如何解决长连接占用大量资源?
MySQL在执行过程中临时使用的内存是管理在连接对象里面的。这些资源会在连接断开的时候才释放
- 定时或在大查询后断开连接
- MySQL5.7版本后使用mysql_reset_connection命令,该命令不需要重连和重新做权限验证,会使连接恢复到刚创建完的状态
查询缓存
- 缓存通过Key-Value 进行存储,key是查询的语句,value是查询的结果
- 查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。不建议使用
- 表更新后,该表缓存将会被清空,仅建议在静态表(长期不更新)使用
- 将参数query_cache_type设置成DEMAND,这样对于默认的SQL语句都不使用查询缓存
- 显示使用缓存:select SQL_CACHE * from T where ID=10;
- MySQL8.O之后版本已移除缓存
分析器
- 词法分析:MySQL需要识别出里面的字符串分别是什么,代表什么
- MySQL从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别 成“表名T”,把字符串“ID”识别成“列ID”。
- 语法分析:检查输入语句是否符合MySQL语法标准
优化器
- 决定使用哪个索引
- 决定表如何 join,哪个表用来join,哪个表用来被连接
- 决定执行的方案
执行器
- 验证权限
- 根据表的引擎定义,去使用这个引擎提供的接口
- 慢查询日志中看到一个rows_examined的字段,表示这个语句执行过程中扫描了多少行。
- 在有些场景下,执行器调用一次,在引擎内部则扫描了多行,因此引擎扫描行数跟rows_examined并不是完全相同的。
二、日志系统
redo log
redo log是Innodb特有的日志
- redo log占用空间固定。
- redo log是一个循环写入、擦除的过程。当redo log写满时,会擦除掉开始的部分日志。
- 当有一条记录需要更新的时候,InnoDB引擎就会先把记录写到redo log里面,并更新内存,之后会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做。
- 有了redo log,InnoDB就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe。
redo log用于保证crash-safe能力。innodb_flush_log_at_trx_commit这个参数设置成1的时候, 表示每次事务的redo log都直接持久化到磁盘。这个参数我建议你设置成1,这样可以保证 MySQL异常重启之后数据不丢失
redo log 设置过小的问题:
如果redolog 设置过小,说明需要一直去推进checkpoint, 说明需要一直刷盘,产生大量的随机写,影响效率
binlog
binlog(归档日志)是Server层日志,MySQL都有该日志
- redo log是InnoDB引擎特有的;binlog是MySQL的Server层实现的,所有引擎都可以使用。
- redo log是物理日志,记录的是“在某个数据页上做了什么修改”;binlog是逻辑日志,记录的 是这个语句的原始逻辑,比如“给ID=2这一行的c字段加1 ”。
- redo log是循环写的,空间固定会用完;binlog是可以追加写入的。“追加写”是指binlog文件 写到一定大小后会切换到下一个,并不会覆盖以前的日志。
- 两者的作用不同,binlog 用于归档、复制,redolog 用于异常恢复
回档操作
- 取出全量备份,还原到某个时间点
- 备份的binlog依次取出来,重放到误删表之前的那个时刻
更新操作流程
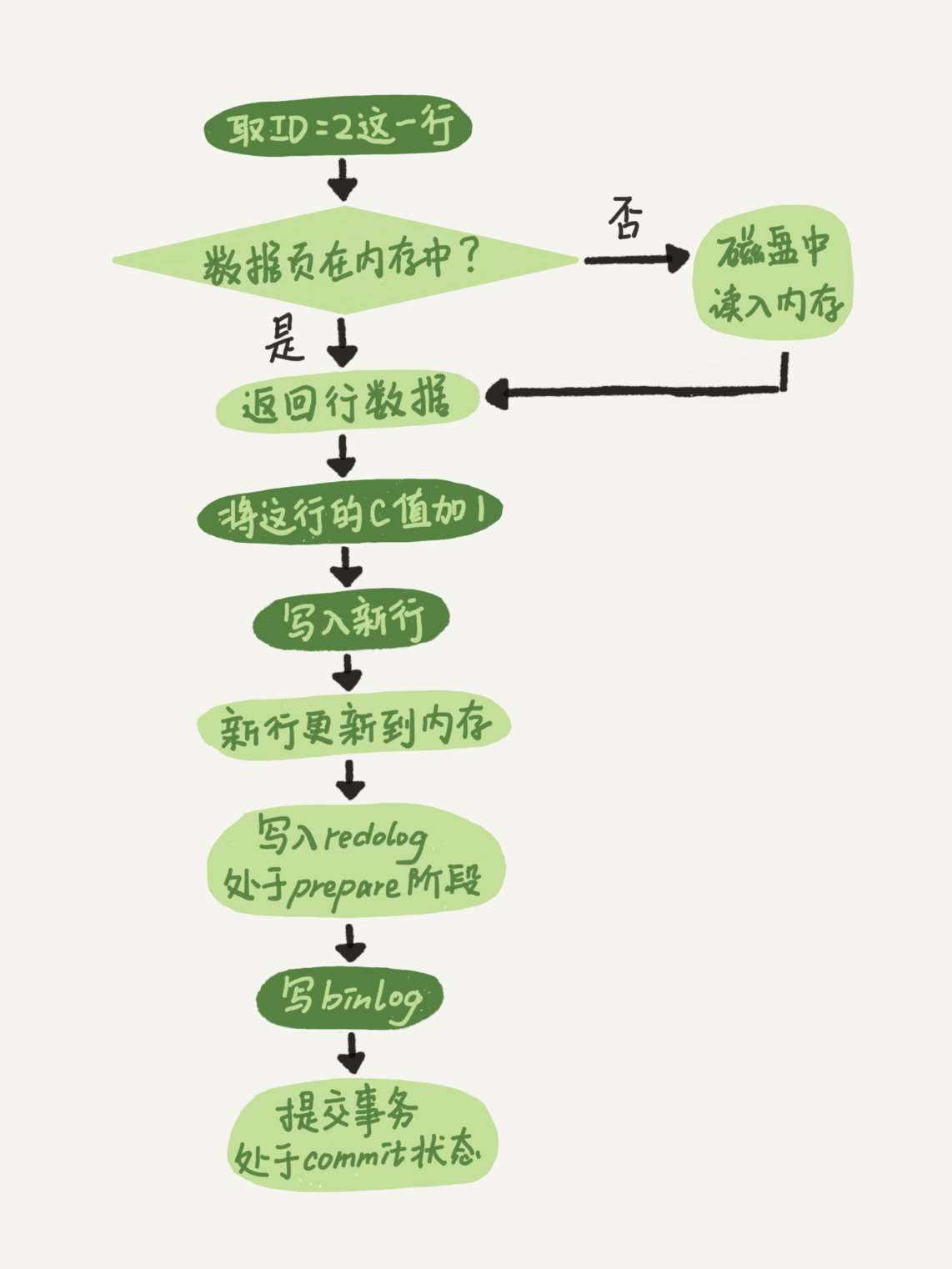
- 执行器先找引擎取ID=2这一行。ID是主键,引擎直接用树搜索找到这一行。如果ID=2这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上1,比如原来是N,现在就是N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到redo log里面,此时redo log处于prepare状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的binlog,并把binlog写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的redo log改成提交(commit)状态,更新完成。
三、索引
1.索引模型
- HASH索引:Key:Value结构的索引类型,通过Hash算法计算Key值,读取时计算数组下标直接取值,缺点:无序,只适合等值查询,范围查询时需要全部扫描
- 有序数组:顺序保存数据,通过二分法可以很快查找到数据,缺点:新增数据时需要后移数据,只适合长期不修改的数据。
- 二叉树:树的非叶子节点上面存在的是节点的整个数据信息,需要多次IO。
2.Innodb索引类型
B+树
- 主键索引上存储的是整行的数据(聚簇索引)
- 非主键索引上存储的是主键(二级索引、非聚簇索引)
3.相关问题
Ⅰ.何时使用业务字段作为主键
1.只有一个索引
2.该索引必须是唯一索引
Ⅱ.主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小
4.覆盖索引
- 尽量将索引覆盖的需要查询的字段上,这样一次性查询完成不需要回表查询主键索引
5.最左前缀原则
- 当存在(a,b)索引时,a字段不需要单独建立索引,b字段无法单独使用该索引,所以建立索引时需要考虑好索引字段的顺序。
6.索引下推
- MySql5.6后进行查询条件筛选时,会先对索引内包含字段进行筛选过滤,以此来减少回表次数。
四、事务
1.事务的隔离性与隔离级别
- 读未提交 :一个事务还未提交,其他事务可以读取到已修改的数据
- 读提交:事务未提交时,其他事务只能读取到未提交的数据
- 可重复读:事务读取到的数据永远是事务开始时的数据
- 串行化:"写"会加锁,"读"会读琐,当读写锁发生冲突时,必须等另一个事务执行完成,才能继续操作
2.事务隔离性的实现
- 事务隔离性的实现主要通过操作日志,mysql进行每条数据更新时会记录一条回滚日志,记录上的最新值,通过回滚操作,都可以得到前一个状态的值
3.长事务的缺点
- 长事务会导致回滚日志(undolog)过长
4.如何开启事务
- 显示的启动事务 begin 或者 start transaction 配合 commit 或者是 rollback
- 通过set autocommit = 0,关闭自动提交,直到你主动去 commit 或者 rollback
如何避免数据库长事务
在开发过程中,尽可能的减小事务范围,少用长事务,如果无法避免,保证逻辑日志空间足够用,并且支持动态日志空间增长。监控Innodb_trx表,发现长事务报警。
未完待续...


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下