浙大数据结构 第五讲 树(下)
第五讲 树(下)
5.1 堆(heap)
优先队列:特殊的“队列”,取出元素的顺序是依照元素的优先权(关键字)大小,而不是元素进入队列的先后顺序。
Q :如何组织优先队列?
若采用数组或链表实现优先队列
-
数组:
插入——元素总是插入尾部 O(1)
删除——查找最大(或最小)的关键字 O(n)
从数组中删除需要移动的元素 O(n)
-
链表:
插入——元素总是插入链表的头部 O(1)
删除——查找最大(或最小)关键字 O(n)
删除结点O(1)
-
有序数组
插入——找到合适位置 O(n) or O(logn)
移动元素并插入 O(n)
删除——删去最后一个元素 O(1)
-
有序链表
插入——找到合适位置 O(n)
插入元素 O(1)
删除——删除首元素或最后元素 O(1)
优先队列的完全二叉树表示

堆的两个特性
结构性:用数组表示的完全二叉树
有序性:任一结点的关键字是其子树所有结点的最大值(或最小值)
最大值(MaxHeap),也称“大顶堆”:根结点的关键字比左右子树都大
最小值(MinHeap),也称“小顶堆”:根结点的关键字比左右子树都小
※注意:从根结点到任意结点的路径上结点序列的有序性!
堆的抽象数据类型
类型名称:最大堆(MaxHeap)
数据对象集:完全二叉树,每个结点的元素值不小于其子结点的元素值
操作集:最大堆H∈MaxHeap,元素item∈ElementType,主要操作有:
MaxHeap Create(int MaxSize);//创建一个空的最大堆
Boolean Isfull(MaxHeap H);//判断最大堆H是否已满
Insert(MaxHeap H,ElementType item);//将元素item插入最大堆H
Boolean IsEmpty(MaxHeap H);//判断最大堆H是否为空
ElementType DeleteMax(MaxHeap H);//返回H中最大元素(高优先级)
最大堆的操作
最大堆的创建
typedef struct HeapStruct *MaxHeap;
struct HeapStruct
{
ElementType *Elements;//存储堆元素的值
int Size;//堆当前元素的个数
int Capacity;//堆的最大容量
};
MAxHeap Create(int MaxSize)
{
MaxHeap H = malloc(sizeof(struct HeapStruct));
H->Elements = malloc((MaxSize + 1) * sizeof(ElementType));//array[0]为哨兵结点,不存堆中元素
H->Size = 0;
H->Capacity = MaxSize;
H->Elements[0] = MaxData;//定义“哨兵”为大于堆中所有可能元素的值,便于以后快速操作,"小根堆"改为小于所有可能元素的值
return H;
}
最大堆的插入(O(logN))
算法:将新增结点插入到从其父结点到跟结点的有序序列中(插到底部后上浮)
void Insert(MaxHeap H,ElementType item)
{
if(IsFull(H))
{
printf("最大堆已满!\n");
return;
}
//H->Elements[0]已定义为哨兵结点,循环条件中不需要i>0
for(int i = ++H->size;item > H->elements[i/2];i=i/2)//size先加一,i指向堆中最后一个元素的位置
{
H->elements[i] = H->elements[i/2];//向下过滤结点,给item腾出位置
}
H->elements[i] = item;//插入item
}
最大堆的删除(T(N) = O(log N))
取出根结点最大值的元素,同时删除堆的一个结点
ElementType DeleteMax(MaxHeap H)
{
int Parent,Child;
ElementType MaxItem,temp;
if(IsEmpty(H))
{
printf("最大堆为空!\n");
return;
}
MaxItem = H->Elements[1];//取出根结点最大值
//用最大堆中最后一个元素从根结点开始向上过滤下层结点
temp = H->Elements[H->Size--];
for(Parent = 1;Parent*2<=H->Size;Parent = Child)
{
Child = Parent*2;
if((Child!=H->Size)&&(H->Elements[Child] < H->Elements[Child+1]))//若child=size时,没有右儿子
{
Child++;//Child指向左右子结点的较大者
}
if(temp >= H->Elements[Child]) break;//移动temp元素到下一层
else H->Elements[Parent] = H->Elements[Child];
}
H->Elements[Parent] = temp;
return MaxItem;
}

最大堆的建立
建立最大堆:将已经存在的N个元素按最大堆的要求存放在一个一维数组中
方法1:通过插入操作,将N个元素一个个相继插入到一个初始为空的堆中去,其时间复杂度为O(N*logN)
方法2:在线性时间复杂度下建立最大堆。
(1)将N个元素按输入顺序存入,先满足完全二叉树的结构特性
(2)调整各结点的位置,以满足最大堆的有序特性
5.1节知识自测

5.2 哈夫曼树与哈夫曼编码
【例题引入】将百分制的考试成绩转换成五分制的成绩
if(score<60) grade = 1;
else if(score<70) grade = 2;
else if(score<80) grade = 3;
else if(score<90) grade = 4;
else grade = 5;


修改判定树:
if(score < 80)
{
if(score < 70)
if(socre < 60) grade = 1;
else grade = 2;
else grade = 3;
}else if(score < 90) grade = 4;
else grade = 5;

如何根据结点不同的查找频率构造更有效的搜索树?
哈夫曼树的定义
带权路径长度(WPL):设二叉树有n个叶子结点,每个结点有权值Wk,从根结点到每个叶子结点的长度为Lk,则每个叶子结点的带权路径长度之和就是:
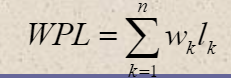
最优二叉树或哈夫曼树:WPL最小的二叉树
【例】有五个叶子结点,它们的权值为{1,2,3,4,5},用此权值序列可以构造出形状不同的多个二叉树。

哈夫曼树的构造
每次把权值最小的两棵二叉树合并:作为左右儿子,其父亲结点的权值为左右儿子权值之和

typedef struct TreeNode *HuffmanTree;
struct TreeNode
{
int Weight;
HuffmanTree Left,Right;
};
HuffmanTree Huffman(MinHeap H)
{
//假设H->Size个权值已经存在H->Elements[]->Weight里
int i;
HuffmanTree T;
BulidMinHeap(H);//将H->Elements[]按权值调整为最小堆
for(int i=1;i<H->Size;i++)//做H->Size - 1次合并
{
T = (HuffmanTree)malloc(sizeof(struct TreeNode));//建立新结点
T->Left = DeleteMin(H);//从最小堆中删除一个结点
T->Right = DeleteMin(H);
T->Weight = T->Left->Weight + T->Right->Weight;//计算新权值
Insert(H,T);//将新T插入最小堆
}
T = DeleteMin(H);//返回堆顶元素(树根)
return T;
}
哈夫曼树的特点
- 没有度为1的结点(哈夫曼树由两两合并形成新结点)
- n个叶子结点的哈夫曼树共有2n-1个结点(度为0的结点数总是比度为2的结点数多一个)
- 哈夫曼树的任意非叶结点的左右子树交换后仍是哈夫曼树
- 对同一组权值{w1,w2,...,wn},存在不同构的两个哈夫曼树,它们的带权路径长度之和(WPL)是相等的

哈夫曼编码
【例题引入】给定一段字符串,如何对字符进行编码,可以使得该字符串的编码存储空间最少?
【例】假设有一段文本,包含58个字符,并由以下7个字符构成:
a,e,i,st,空格(sp),换行(nl);
这7个字符出现的次数不同。如何对这7个字符进行编码,使得总编码空间最少?
不等长编码:出现频率高的字符用的编码短些,出现频率低的字符则可以编码长些
Q:怎样进行不等长编码?如何避免二义性?
A:前缀码(prefix code) 任何字符的编码都不是另一字符的编码的前缀,可以无二义地解码
二叉树用于编码
用二叉树进行编码:
- 左右分支:0、1
- 字符只在叶结点上,构成前缀码,以防止二义性


Q:怎样构造一棵编码代价最小的二叉树?
A:哈夫曼树、哈夫曼编码

课后练习

题2:

可以看出,a节点的度为1。哈夫曼树结点的度不能为1。所以不对。
5.3 集合与运算
集合运算:交、并、补、差,判定一个元素是否属于某一集合
并查集:集合并、查某元素属于什么集合
并查集问题中集合存储如何实现?

也可以采用数组存储形式
负数表示根结点,非负数表示双亲结点的下标
数组中每个元素的类型描述为:
typedef struct
{
ElementType Data;
int Parent;
}SetType;
集合运算
(1)查找某个元素所在的集合(用根结点表示)
int Find(SetType S[],ElementType X)
{
//在数组中查找值为X的元素所属的集合,MaxSize是全局变量,为数组S的最大长度
int i;
for(i=0;i<MaxSize&&S[i].Data!=X;i++);
if(i>=MaxSize) return -1;//未找到,返回-1
for(;S[i].Parent!=-1;i = S[i].Parent);
return i;//找到X所属集合,返回树根结点在数组S中的下标
}
(2)集合的并运算
分别找到X1和X2两个元素所在集合树的根结点
若它们不同根,则将其中一个根结点的父结点指针设置成另一个根结点的数组下标。
void Union(SetType S[],ElementType X1,ElementType X2)
{
int root1,root2;
root1 = Find(S,X1);
root2 = Find(S,X2);
if(Root1!=Root2) S[Root2].Parent = Root1;
}
为了改善合并后的查找性能,可以采用小的集合合并到相对大的集合中(修改Union函数)且将根结点的Parent设置为集合元素个数的相反数(-2,-3,-8....)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)