第11组结对编程 - 词频统计
一、GitHub地址
二、结对的PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(h) | 实际耗时(h) |
| Planning | 计划 | 7h | 8h |
| ·Estimate | · 估计这个任务需要多少时间 | 7h | 8h |
| Development | 开发 | 4h | 5h |
| ·Analysis | · 需求分析 (包括学习新技术) | 0.3h | 0.3h |
| ·Design Spec | · 生成设计文档 | 0.5h | 0.5h |
| ·Design Review | · 设计复审 (和同事审核设计文档) | 0.4h | 0.4h |
| ·Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0.3h | 0.3h |
| ·Design | · 具体设计 | 0.3 | 0.3h |
| ·Coding | · 具体编码 | 1.5h | 2.5h |
| ·Code Review | · 代码复审 | 0.4h | 0.4h |
| ·Test | · 测试(自我测试,修改代码,提交修改) | 0.3h | 0.3h |
| Reporting | 报告 | 3h | 3h |
| · Test Report | · 测试报告 | 0.5h | 0.6h |
| · Size Measurement | · 计算工作量 | 0.5h | 0.4h |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 2h | 2h |
| 合计 | 7h | 8h |
三、解题思路描述。即刚开始拿到题目后,如何思考,如何找资料的过程
1.读文件用什么好?用scanner读取文件
2.正则表达式如何写?求助正则表达式的百度百科
3.字符如何计数?若Ascii码在0-127之间则计数
4.单词如何计数?使用map的containsKey
5.如何对单词个数进行排序?使用list存map,并对map的value值进行排序( Collections.sort(list,valueComparator))
四、设计实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?单元测试是怎么设计的?
一个主函数,调用两个函数,countChar(File file,PrintStream printStream)函数统计字符数,countWord(File file, PrintStream printStream)统计单词数,并对单词的频率进行排序,两个函数之间没有关联。
单元测试设计
import org.junit.Assert;
import java.io.File;
import java.io.PrintStream;
import static org.junit.Assert.*;
public class wordCountTest {
@org.junit.Test
public void countWord()throws Exception {
//wordCount wordCount = new wordCount();
File file = new File("txt/input.txt");
File file1 = new File("Out.txt");
PrintStream printStream = new PrintStream(file1);
Integer sum= wordCount.countChar(file,printStream);
Assert.assertEquals("5", sum.toString());
}
}

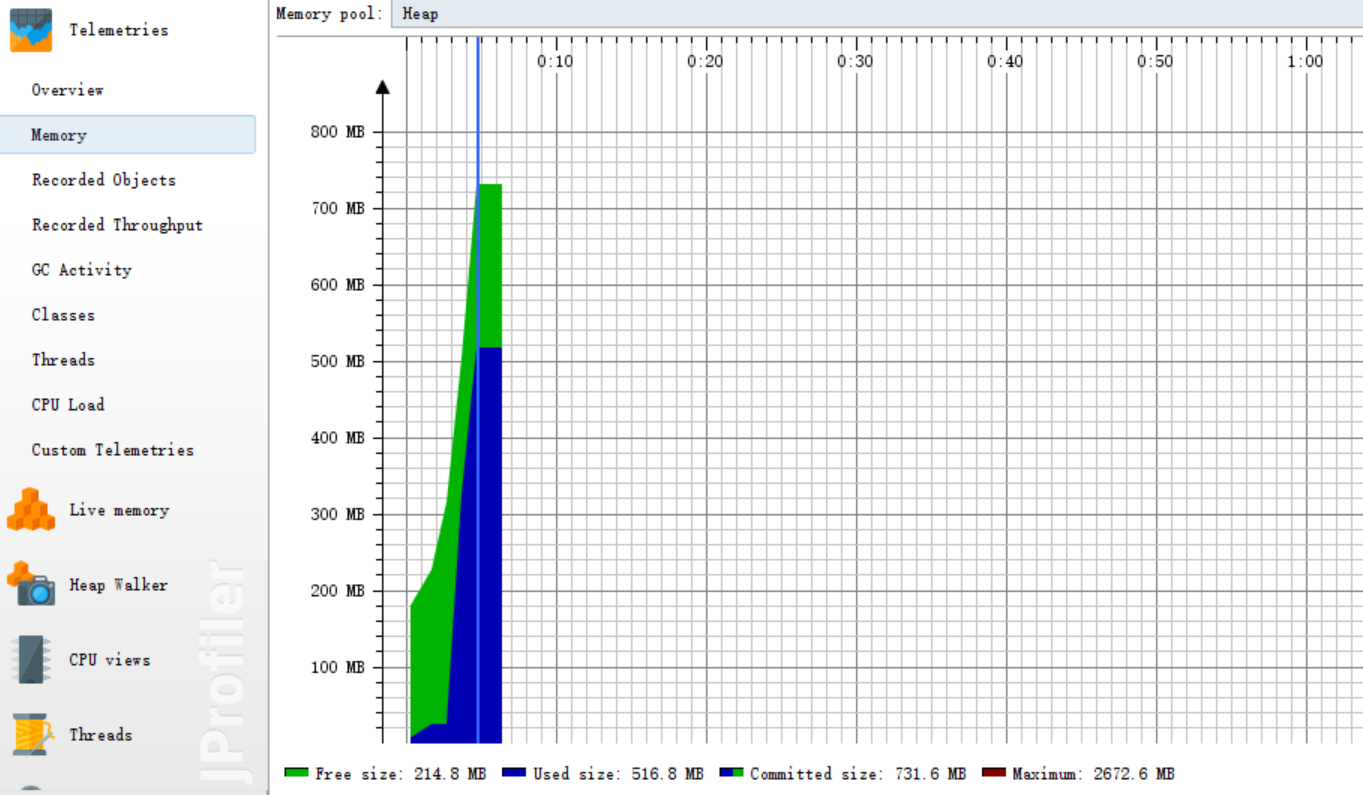
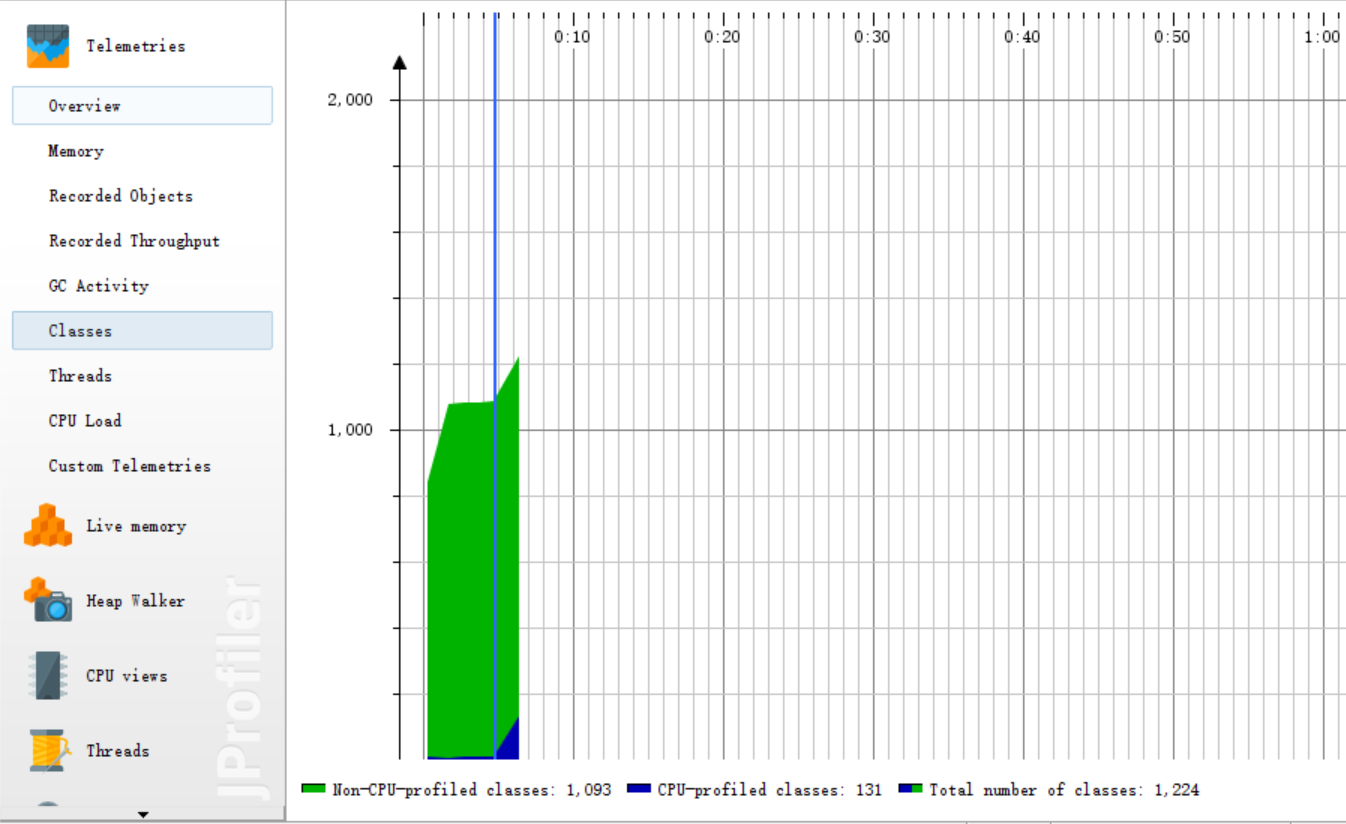
五、记录在改进程序性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2017的性能分析工具自动生成),并展示你程序中消耗最大的函数。
1.正则表达式花费时间较长,原来是只分割空格,后面加入正则表达式,分割空格,非字母数字空格,改进后的正则表达式为“\s*[0-9a-zA-Z]+”,'\'是\的转义符,'\s'是空格,'*'是零个或多个,'[0-9a-zA-Z]'为非字母数字字符,‘+’表示一次或多次,大概花费35min
2.在单词计数并排序的时候,使用list存map,并对map的value进行排序,大概花费30min
性能分析图
改进之后的效能分析图





六、代码说明
1,使用scanner扫描文件
2,统计Ascii码,扫描每个字符,若在Ascii码区间则计数
3,统计单词总数,两个正则表达式
String argex = "\\s*[^0-9a-zA-Z]+";
String argex1="[a-zA-Z]{4,}[a-zA-Z0-9]*";
argex 分隔符,筛选出每行的字母数字;argex1匹配是否至少以4个英文字母开头的单词
4,统计有效行数
if (!charline.trim().isEmpty()){
line++;
}
5.统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词
if (id_word){
String key = a[i].toLowerCase();
if (map.containsKey(key)){
n=Integer.parseInt(map.get(key).toString())+1;
map.put(key,n);
}else {
map.put(key,1);
}
}
使用Map,key存单词,value存单词对应的个数,然后对单词个数进行排序
// map转换成list进行排序
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String,Integer>>(map.entrySet());
// 排序
Collections.sort(list,valueComparator);
// 升序比较器
Comparator<Map.Entry<String, Integer>> valueComparator = new Comparator<Map.Entry<String,Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1,
Map.Entry<String, Integer> o2) {
// TODO Auto-generated method stub
if (o2.getValue()==o1.getValue()){
int ab = o2.getKey().compareTo(o1.getKey());
return ab;
}else {
return o2.getValue()-o1.getValue();
}
}
};
for (Map.Entry<String, Integer> entry : list) {
if (is_out!=entry.getValue()){
printStream.println("<"+entry.getKey()+">:" + entry.getValue());
is_out=entry.getValue();
count1++;
if (count1==10){
break;
}
}
}
使用list将每个map存起来,并对map的value值进行排序,并输出频率最高的十个,单词频率相同时,compareTo可以比较出字典序靠前的单词
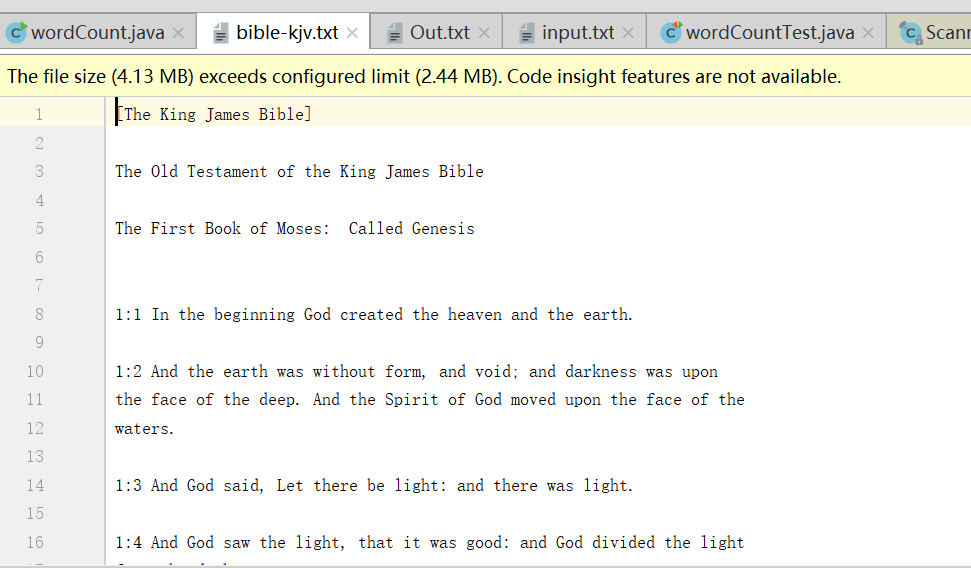
测试结果图


七、异常模块处理
public static void countChar(File file,PrintStream printStream)throws FileNotFoundException
异常捕获主要是在使用Scanner和PrintStream时需要捕获异常或者抛异常。
八、收获与心得
这次与亓老师一起结对,感觉自己学习了很多,在亓老师的指导下少走了很多弯路,大大提高了代码效率,也由此明白了团队协作的重要性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号