Python基础进程和线程
一 背景知识
进程的概念起源于操作系统,是操作系统最核心的概念。
进程是对正在运行程序的一个抽象,操作系统的其他所有内容都是围绕进程的概念展开的。所以想要真正了解进程,必须事先了解操作系统,egon介绍==》点击进入
进程是操作系统提供的最古老也是最重要的抽象概念之一。即使可以利用的cpu只有一个(早期的计算机确实如此),也能保证支持(伪)并发的能力。将一个单独的cpu变成多个虚拟的cpu(多道技术:时间多路复用和空间多路复用+硬件上支持隔离),没有进程的抽象,现代计算机将不复存在。
本文将将着重介绍进程以及它的亲戚->线程
线程
首先弄清进程和线程之间的区别,这一点是非常重要的。线程与进程的不同之处在于,它们共享状态、内存和资源。对于线程来说,这个简单的区别既是它的优势,又是它的缺点。一方面,线程是轻量级的,并且相互之间易于通信,但另一方面,它们也带来了包括死锁、争用条件和高复杂性在内的各种问题。幸运的是,由于 GIL 和队列模块,与采用其他的语言相比,采用 Python 语言在线程实现的复杂性上要低得多。无论是创建进程或者线程都是为了实现并发操作
Python进程、线程之间的原理图
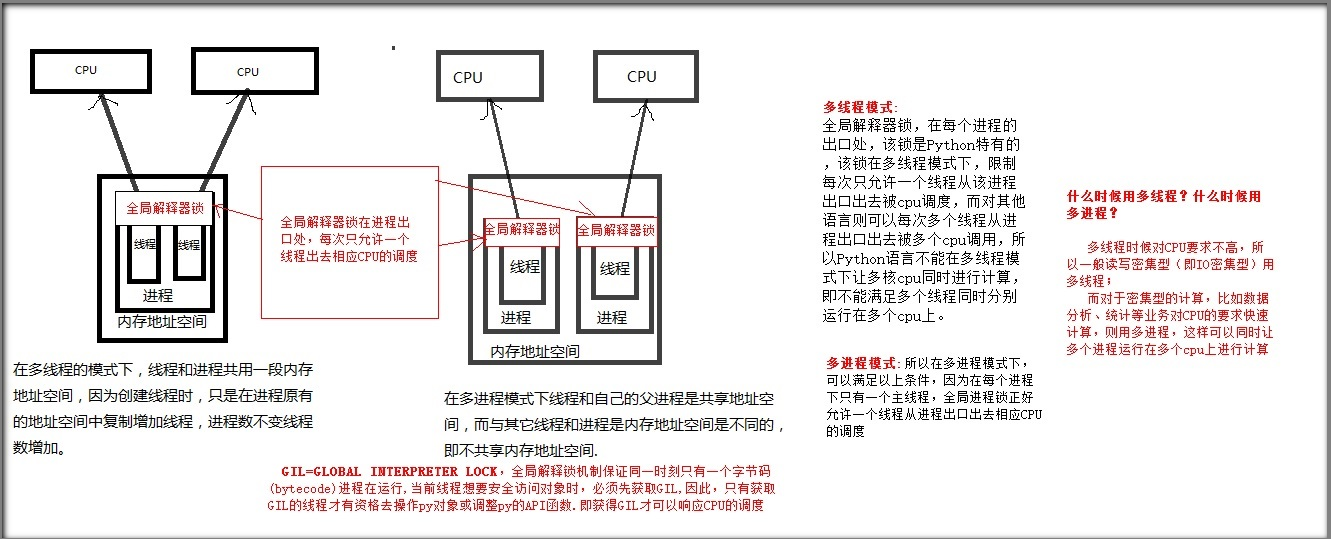
计算机有进程和线程的目的:提高执行效率
计算机默认有主进程和主线程
进程:
优点:同时利用多个CPU,能够同时进行多个操作
缺点:耗费资源(重新开辟内存空间)
进程不是越多越好,理论上CPU个数(核数)=进程个数
计算密集型适用于进程,因为计算之类的需要CPU运算(占用CPU)
线程:
优点:共享内存,IO操作时,创造并发操作
缺点:枪战资源
线程不是越多越好,具体案例具体分析,请求上下文切换耗时
IO密集型适用于线程,IO操作打开文件网络通讯类,不需要占用CPU,只是由CPU调度一下(不占用CPU)
自定义进程和线程:注意python解释器自带了主进程和主线程,比如在代码文件里没有定义线程和进程,程序也能运行就是靠的解释器自带主进程的主线程执行的
自定义进程:
由主进程创建,子进程
自定义线程:
由主线程创建,子线程
GIL全局解释器锁:
GIL全局解释器锁在进程入口,控制着进程数量与CPU的相应
multiprocessing进程模块
multiprocessing是python的多进程管理包,和threading.Thread类似。直接从侧面用subprocesses替换线程使用GIL的方式,由于这一点,multiprocessing模块可以让程序员在给定的机器上充分的利用CPU。
在multiprocessing中,通过创建Process对象生成进程,然后调用它的start()方法,
Process()创建进程对象【有参】
注意:wds系统下必须if __name__ == "__main__"才能创建进程,我们调试没关系,以后在Linux系统没这个问题
使用方法:定义变量 = multiprocessing.Process(target=要创建进程的函数, args=元祖类型要创建进程函数的参数、多个参数逗号隔开)
格式:t = multiprocessing.Process(target=f1, args=(133,))
start()激活进程【无参】
使用方法:Process对象变量.start()
格式:t.start()
创建10条进程
#!/usr/bin/env python # -*- coding:utf8 -*- import multiprocessing #导入进程模块 def f1(r): #创建函数 print(r) #打印传值 if __name__ == "__main__": #wds系统下必须if __name__ == "__main__"才能创建进程,我们调试没关系,以后在Linux系统没这个问题 for i in range(10): #循环10次,创建10条进程 t = multiprocessing.Process(target=f1, args=(133,)) #创建进程对象 t.start() #激活进程 # 输出 # 133 # 133 # 133 # 133 # 133 # 133 # 133 # 133 # 133 # 133
daemon主进程是否等待子进程执行完毕后,在停止主进程,daemon=True(主进程不等待子进程)、daemon=False(主进程等待子进程)
使用方法:Process对象变量.daemon=True或者False
格式:t.daemon = True
import multiprocessing
import time
def worker(interval):
print("work start:{0}".format(time.ctime()))
time.sleep(interval)
print("work end:{0}".format(time.ctime()))
if __name__ == "__main__":
p = multiprocessing.Process(target = worker, args = (3,))
p.start()
print ("end!")
# end!
# work start:Wed Jun 28 10:36:50 2017
# work end:Wed Jun 28 10:36:53 2017


import multiprocessing import time def worker(interval): print("work start:{0}".format(time.ctime())) time.sleep(interval) print("work end:{0}".format(time.ctime())) if __name__ == "__main__": p = multiprocessing.Process(target = worker, args = (3,)) p.daemon=True p.start() print ("end!") # end!
注:因子进程设置了daemon属性,主进程结束,它们就随着结束了
import multiprocessing import time def worker(interval): print("work start:{0}".format(time.ctime())) time.sleep(interval) print("work end:{0}".format(time.ctime())) if __name__ == "__main__": p = multiprocessing.Process(target = worker, args = (3,)) p.daemon=True p.start() p.join() print ("end!") # work start:Wed Jun 28 10:39:28 2017 # work end:Wed Jun 28 10:39:31 2017 # end!
join()逐个执行每个进程,等待一个进程执行完毕后继续往下执行,该方法使得进程程变得无意义【有参可选】
有参可选,参数为等待时间,秒为单位,如t.join() 就是一个进程不在是等待它执行完,而是只等待它1秒后继续下一个进程
import multiprocessing #导入进程模块 import time def f1(r): #创建函数 time.sleep(1) print(r) #打印传值 if __name__ == "__main__": #wds系统下必须if __name__ == "__main__"才能创建进程,我们调试没关系,以后在Linux系统没这个问题 for i in range(10): #循环10次,创建10条子进程 t = multiprocessing.Process(target=f1, args=(133,)) #创建进程对象 t.start() #激活进程 t.join() #逐个执行每个进程,等待一个进程执行完毕后继续往下执行 print("host") #输出 133 host 133 host 133 host 133 host 133 host 133 host 133 host 133 host 133 host 133 host
把上周所学的socket通信变成并发的形式
from socket import * from multiprocessing import Process server=socket(AF_INET,SOCK_STREAM) server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) server.bind(('127.0.0.1',8080)) server.listen(5) def talk(conn,client_addr): while True: try: msg=conn.recv(1024) if not msg:break conn.send(msg.upper()) except Exception: break if __name__ == '__main__': #windows下start进程一定要写到这下面 while True: conn,client_addr=server.accept() p=Process(target=talk,args=(conn,client_addr)) p.start()
from socket import * client=socket(AF_INET,SOCK_STREAM) client.connect(('127.0.0.1',8080)) while True: msg=input('>>: ').strip() if not msg:continue client.send(msg.encode('utf-8')) msg=client.recv(1024) print(msg.decode('utf-8'))
每来一个客户端,都在服务端开启一个进程,如果并发来一个万个客户端,要开启一万个进程吗,你自己尝试着在你自己的机器上开启一万个,10万个进程试一试。
解决方法:进程池
Process对象的其他方法或属性
from multiprocessing import Process import time # import random def piao(name): print('%s is piaoing' % name) time.sleep(1) print('%s is piao end' % name) if __name__ == '__main__': p1=Process(target=piao,args=('egon',)) p2=Process(target=piao,args=('alex',)) p3=Process(target=piao,args=('wupeiqi',)) p4=Process(target=piao,args=('yuanhao',)) p_l=[p1,p2,p3,p4] for p in p_l: p.start() for p in p_l: p.join() print('主进程')
from multiprocessing import Process import time import random def piao(name): print('%s is piaoing' % name) time.sleep(random.randint(1,3)) print('%s is piao end' % name) if __name__ == '__main__': p1=Process(target=piao,args=('egon',)) p1.daemon=False #默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置 p1.start() p1.terminate()#强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁 print(p1.is_alive())#如果p仍然运行,返回True time.sleep(1) print(p1.is_alive())#如果p仍然运行,返回True print('主进程') print(p1.name) #为子进程的名称 print(p1.pid) #进程的pid
#多进程共享一套文件系统
from multiprocessing import Process def work(filename,msg): with open(filename,'a',encoding='utf-8') as f: f.write(msg) if __name__ == '__main__': for i in range(5): p=Process(target=work,args=('a.txt','进程%s\n' %str(i))) p.start()
进程3
进程0
进程2
进程4
进程1
进程1
进程0
进程2
进程3
进程4
进程间通信(IPC):队列
进程彼此之间互相隔离,要实现进程间通信,即IPC,multiprocessing模块支持两种形式:队列和管道,这两种方式都是使用消息传递的
#队列,先进先出
''' multiprocessing模块支持进程间通信的两种主要形式:管道和队列 都是基于消息传递实现的,但是队列接口 ''' from multiprocessing import Process,Queue import time q=Queue(3) #put ,get ,put_nowait,get_nowait,full,empty q.put(3) q.put(3) q.put(3) print(q.full()) #满了 print(q.get()) print(q.get()) print(q.get()) print(q.empty()) #空了
创建队列的类(底层就是以管道和锁定的方式实现)
1 Queue([maxsize]):创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。
方法介绍:
q.put方法用以插入数据到队列中,put方法还有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,该方法会阻塞timeout指定的时间,直到该队列有剩余的空间。如果超时,会抛出Queue.Full异常。如果blocked为False,但该Queue已满,会立即抛出Queue.Full异常。
q.get方法可以从队列读取并且删除一个元素。同样,get方法有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,那么在等待时间内没有取到任何元素,会抛出Queue.Empty异常。如果blocked为False,有两种情况存在,如果Queue有一个值可用,则立即返回该值,否则,如果队列为空,则立即抛出Queue.Empty异常.
q.get_nowait():同q.get(False)
q.put_nowait():同q.put(False)
q.empty():调用此方法时q为空则返回True,该结果不可靠,比如在返回True的过程中,如果队列中又加入了项目。
q.full():调用此方法时q已满则返回True,该结果不可靠,比如在返回True的过程中,如果队列中的项目被取走。
q.qsize():返回队列中目前项目的正确数量,结果也不可靠,理由同q.empty()和q.full()一样
基于队列实现生产者消费者模型
from multiprocessing import Process,Queue #队列模块 import time import random def consumer(q,name): while True: time.sleep(random.randint(1,3)) res=q.get() #从队列读取并且删除一个元素 print('\033[41m消费者%s拿到了%s\033[0m' %(name,res)) def producer(seq,q,name): for item in seq: time.sleep(random.randint(1,3)) q.put(item) #插入数据到队列中 print('\033[42m生产者%s生产了%s\033[0m' %(name,item)) if __name__ == '__main__': q=Queue() #对象 c=Process(target=consumer,args=(q,'egon'),) #进程调用和参数赋值 c.start() #开启进程 seq=['包子%s' %i for i in range(10)] #生产者函数 producer(seq,q,'厨师1') #生产者函数调用 print('主进程')
from multiprocessing import Process,Queue import time import random def consumer(q,name): while True: time.sleep(random.randint(1,3)) res=q.get() if res is None:break #检查从队列读取并且删除一个元素是否以为空 print('\033[41m消费者%s拿到了%s\033[0m' %(name,res)) def producer(seq,q,name): for item in seq: time.sleep(random.randint(1,3)) q.put(item) print('\033[42m生产者%s生产了%s\033[0m' %(name,item)) q.put(None) if __name__ == '__main__': q=Queue() c=Process(target=consumer,args=(q,'egon'),) c.start() seq=['包子%s' %i for i in range(10)] p=Process(target=producer,args=(seq,q,'厨师1')) p.start() print('主进程')
进程同步(锁),信号量,事件...
模拟抢票(Lock互斥锁)
#文件db的内容为:{"count":1} #注意一定要用双引号,不然json无法识别 from multiprocessing import Process,Lock import json import time import random import os def work(filename,lock): #买票 # lock.acquire() with lock: with open(filename,encoding='utf-8') as f: dic=json.loads(f.read()) # print('剩余票数: %s' % dic['count']) if dic['count'] > 0: dic['count']-=1 time.sleep(random.randint(1,3)) #模拟网络延迟 with open(filename,'w',encoding='utf-8') as f: f.write(json.dumps(dic)) print('%s 购票成功' %os.getpid()) else: print('%s 购票失败' %os.getpid()) # lock.release() if __name__ == '__main__': lock=Lock() p_l=[] for i in range(100): p=Process(target=work,args=('db',lock)) p_l.append(p) p.start() for p in p_l: p.join() print('主线程')
#a.txt #{“count”:1} #!/usr/bin/python # -*- coding:utf-8 -*- from multiprocessing import Process,Lock import json import time import random def work(dbfile,name): # lock.acquire() with open(dbfile,encoding='utf-8') as f: dic=json.loads(f.read()) if dic['count'] > 0: dic['count']-=1 time.sleep(random.randint(1,3)) #模拟网络延迟 with open(dbfile,'w',encoding='utf-8') as f: f.write(json.dumps(dic)) print('\033[43m%s 抢票成功\033[0m' %name) else: print('\033[45m%s 抢票失败\033[0m' %name) # lock.release() if __name__ == '__main__': # lock=Lock() p_l=[] for i in range(100): p=Process(target=work,args=('a.txt','用户%s' %i)) p_l.append(p) p.start() for p in p_l: p.join() print('主进程') #这样票只剩一张也被多人抢到
进程池
开多进程的目的是为了并发,如果有多核,通常有几个核就开几个进程,进程开启过多,效率反而会下降(开启进程是需要占用系统资源的,而且开启多余核数目的进程也无法做到并行),但很明显需要并发执行的任务要远大于核数,这时我们就可以通过维护一个进程池来控制进程数目,比如httpd的进程模式,规定最小进程数和最大进程数...
当被操作对象数目不大时,可以直接利用multiprocessing中的Process动态成生多个进程,十几个还好,但如果是上百个,上千个目标,手动的去限制进程数量却又太过繁琐,此时可以发挥进程池的功效。
而且对于远程过程调用的高级应用程序而言,应该使用进程池,Pool可以提供指定数量的进程,供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,就重用进程池中的进程。
在利用Python进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间。
方法介绍:
p.apply(func [, args [, kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果。需要强调的是:此操作并不会在所有池工作进程中并执行func函数。如果要通过不同参数并发地执行func函数,必须从不同线程调用p.apply()函数或者使用p.apply_async() p.apply_async(func [, args [, kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果。此方法的结果是AsyncResult类的实例,callback是可调用对象,接收输入参数。当func的结果变为可用时,将理解传递给callback。callback禁止执行任何阻塞操作,否则将接收其他异步操作中的结果。 p.close():关闭进程池,防止进一步操作。如果所有操作持续挂起,它们将在工作进程终止前完成 p.terminate():立即终止所有工作进程,同时不执行任何清理或结束任何挂起工作。如果p被垃圾回收,将自动调用此函数 P.jion():等待所有工作进程退出。此方法只能在close()或teminate()之后调用
Pool
在利用Python进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间。当被操作对象数目不大时,可以直接利用multiprocessing中的Process动态成生多个进程,十几个还好,但如果是上百个,上千个目标,手动的去限制进程数量却又太过繁琐,此时可以发挥进程池的功效。
Pool可以提供指定数量的进程,供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来它。
使用进程池(非阻塞)
#coding: utf-8
import multiprocessing
import time
def func(msg):
print ("msg:", msg)
time.sleep(3)
print ("end")
if __name__ == "__main__":
pool = multiprocessing.Pool(processes = 3)
for i in range(4):
msg = "hello %d" %(i)
pool.apply_async(func, (msg, )) #维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
print ("Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~")
pool.close()
pool.join() #调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
print ("Sub-process(es) done.")
输出: Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~
msg: hello 0
msg: hello 1
msg: hello 2
end
msg: hello 3
end
end
end
Sub-process(es) done.
函数解释:
- apply_async(func[, args[, kwds[, callback]]]) 它是非阻塞,apply(func[, args[, kwds]])是阻塞的(理解区别,看例1例2结果区别)
- close() 关闭pool,使其不在接受新的任务。
- terminate() 结束工作进程,不在处理未完成的任务。
- join() 主进程阻塞,等待子进程的退出, join方法要在close或terminate之后使用。
执行说明:创建一个进程池pool,并设定进程的数量为3,range(4)会相继产生四个对象[0, 1, 2, 3],四个对象被提交到pool中,因pool指定进程数为3,所以0、1、2会直接送到进程中执行,当其中一个执行完事后才空出一个进程处理对象3,所以会出现输出“msg: hello 3”出现在"end"后。因为为非阻塞,主函数会自己执行自个的,不搭理进程的执行,所以运行完for循环后直接输出“mMsg: hark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~”,主程序在pool.join()处等待各个进程的结束。
使用进程池(阻塞)
#coding: utf-8 import multiprocessing import time def func(msg): print ("msg:", msg) time.sleep(3) print ("end") if __name__ == "__main__": pool = multiprocessing.Pool(processes = 3) for i in range(4): msg = "hello %d" %(i) pool.apply(func, (msg, )) #维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去 print ("Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~") pool.close() pool.join() #调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束 print ("Sub-process(es) done.") 输出: msg: hello 0 end msg: hello 1 end msg: hello 2 end msg: hello 3 end Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~ Sub-process(es) done.
回调函数:
编程分为两类:系统编程(system programming)和应用编程(application programming)。所谓系统编程,简单来说,就是编写库;而应用编程就是利用写好的各种库来编写具某种功用的程序,也就是应用。系统程序员会给自己写的库留下一些接口,即API(application programming interface,应用编程接口),以供应用程序员使用。所以在抽象层的图示里,库位于应用的底下。
当程序跑起来时,一般情况下,应用程序(application program)会时常通过API调用库里所预先备好的函数。但是有些库函数(library function)却要求应用先传给它一个函数,好在合适的时候调用,以完成目标任务。这个被传入的、后又被调用的函数就称为回调函数(callback function)。
打个比方,有一家旅馆提供叫醒服务,但是要求旅客自己决定叫醒的方法。可以是打客房电话,也可以是派服务员去敲门,睡得死怕耽误事的,还可以要求往自己头上浇盆水。这里,“叫醒”这个行为是旅馆提供的,相当于库函数,但是叫醒的方式是由旅客决定并告诉旅馆的,也就是回调函数。而旅客告诉旅馆怎么叫醒自己的动作,也就是把回调函数传入库函数的动作,称为登记回调函数
def a(i): print("this is a start") print(i) print("this is a stop") def b(func): print("this is b start") for i in range(10): func(i) print("this is b stop") if __name__ == '__main__': b(a)
this is b start this is a start 0 this is a stop this is a start 1 this is a stop this is a start 2 this is a stop this is a start 3 this is a stop this is a start 4 this is a stop this is a start 5 this is a stop this is a start 6 this is a stop this is a start 7 this is a stop this is a start 8 this is a stop this is a start 9 this is a stop this is b stop
开进程回调函数:
from multiprocessing import Process,Pool def a(x): print("this is a start") print(x) print("this is a stop") def b(num): return(num) if __name__ == '__main__': p = Pool(5) for i in range(10): # 这里表示,当b函数执行完成之后就会调用a函数,并且把b函数的返回值传给a函数。 p.apply_async(b, args=(i,), callback=a) p.close() p.join()
this is a start 0 this is a stop this is a start 1 this is a stop this is a start 2 this is a stop this is a start 3 this is a stop this is a start 4 this is a stop this is a start 5 this is a stop this is a start 6 this is a stop this is a start 7 this is a stop this is a start 8 this is a stop this is a start 9 this is a stop

 浙公网安备 33010602011771号
浙公网安备 33010602011771号