

教材习题
1-1 数据压缩的一个基本问题是“我们要压缩什么”,对此你是怎样理解的?
答:一般是一些需要传输的数据量信息量,包括物理空间、时间区间、电磁频段,也就是指某些信号集合所占的空域、时域和频域的空间。
1-2 数据压缩的另一个基本问题是“为什么进行数据压缩”,对此你又是怎样理解的?
答:1.对于物理世界:没有足够的空间;对于数字世界:(1)Q:宽带/存储会指数增长;(2)A:数据产生增长更快。2.可以较快地传输各种信源(降低信道占有费用)-时间域的压缩;3.在现有通信干线上开通更多的并行业务-频率域的压缩;4.可以进行能量域的压缩;5.可以进行空间域的压缩。
1-6 数据压缩技术是如何分类的?
答:一般分为可逆压缩和不可逆压缩:建模表达式->二次量化->熵编码(1) 建立一个数学模型,以便能更紧凑或更有效地“重新表达”规律性不那么明显(或本质性不那么突出)的原始数据;(2) 设法更简洁地表达利用该模型对原始数据建模所得到的模型参数(或新的数据表示形式)。由于这些参数可能会具有无限的(或过高的)表示精度,因此可以将其量化为有限的精度-为区别于对原始信号数字化时已进行过的一次量化过程,故称为二次量化;(3) 对模型参数的量化或消息流进行码字分配,以得到尽可能紧凑的压缩码流。此时的编码要求能“忠实地”再现模型参数的量化符号,故称为“熵编码”。
参考书《数据压缩导论(第4版)》Page 8
1.4 1)、用你的计算机上的压缩工具来压缩不同文件,研究原文件的大小和类型对于压缩文件与原文件大小之比的影响。
答:实验后发现压缩文件类型不一样结果也会有很大差别,压缩前的大小不一样,,结果也会不一样。对于doc、txt、sql数据库等文件,压缩比例非常大,而jpg、mp3等压缩的比例不大。所以对于压缩比例大的文件有很多好处,可以节省空间,这样在传输的过程中就会少费时,而对于压缩比例较小的文件也可以起到打包的作用,这样可以节约工序。
1.4 2)、从一本通俗杂志中摘录几段文字,并删除所有不会影响理解的文字,实现压缩。例如在“This is the dog that belongs to my friend”中,删除“is”“the”“that”和“to”之后,仍然能传递相同意思。用被删除的单词数与原本的总单词数之比来衡量文本中的冗余度。用一本技术期刊中的文字来重复这一次实验,对于摘自不同来源的文字,我们能否就其冗余度做出定量论述?
答:冗余度它表征源信息率的多于程度,是描述信源客观统计特性的一个物理量。也可以说是从多余的一个量,它不影响数据的完整,也正是因为这一个多余量的存在,才能对其信源进行压缩,压缩后不会影响传递信息。信源=信息+冗余度。所以对于摘自不同来源的文字我们不能就冗余度做出定量论述,因为对于不同的文字信息室不一样的。
参考书《数据压缩导论(第4版)》Page 30
3.给定符号集A={a1,a2,a3,a4},求以下条件下的一阶熵:
(1)p(a1)=p(a2)=p(a3)=p(a4)=1/4;
解:一阶熵为:
H= - 1/4 * 4 * log2 1/4
=2(bits)
(2)p(a1)=1/2,p(a2)=1/4,p(a3)=p(a4)=1/8;
解:一阶熵为:
H= - 1/2 * log2 1/2 - 1/4 * log2 1/4 - 2 * 1/8 * log2 1/8
=1.75(bits)
(3)p(a1)=0.505,p(a2)=1/4,p(a3)=1/8,p(a4)=0.12.
解:一阶熵为:
H= - 0.505 * log2 0.505 - 1/4 * log2 1/4 - 1/4 * log2 1/4 - 0.12 * log2 0.12
=1.74(bits)
5、考虑以下序列:
ATGCTTAACGTGCTTAACCTGAAGCTTCCGCTGAAGAACCTG
CTGAACCCGCTTAAGCTTAAGCTGAACCTTCTGAACCTGCTT
(a)根据此序列估计各概率值,并计算这一序列的一阶、二阶、三阶和四阶熵.
解:(a) 依题意得:
P(A)=21/84=1/4 、P(G)=16/84=4/21 、P(C)=24/84=2/7、P(T)=23/84
所以一阶熵为:
H= - 1/4 * log2(1/4) - 2/7 * log2(2/7) - 4/21 * log2(4/21) - 23/84 * log2(23/84)
=1/2+ 0.52+0.46+0.52
=2(bits)
7、做一个实验,看看一个模型能够多么准确地描述一个信源。
(a)编写一段程序,从包括26个字母的符号集{a,b,...,z}中随机选择字母,组成100个四字母单词,这些单词中有多少是有意义的?
解:

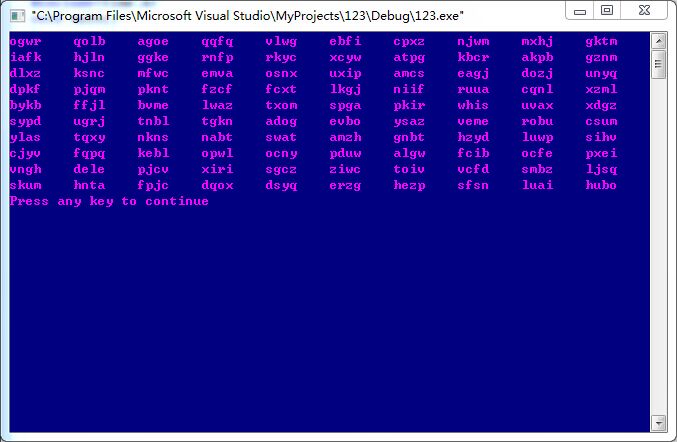
根据程序可知,这些单词大多都是无意义的。
