

selenium+unittest实现po模型
1.PO模型简介:
PO模型是Page Object Model的简写, 页面对象模型。
PO模型又叫PO设计模式,是selenium自动化测试中最佳的设计模式之一,主要体现在对界面交互细节的封装,将页面定位和业务操作分开,也就是把对象的定位和测试脚本分开,在实际测试中只需要关注业务流程,从而提高可维护性。
PO模型简单来说:就是通过面向对象的方式,封装页面定位和页面动作操作。与测试的逻辑分开。
通俗解释一下就是每个页面当成一个对象,给这些页面写一个类,每一个page class维护着该web页的标签元素集和操作这些元素的方法;至于测试脚本则单独写,需要什么就去这些页面类去调用即可。这样的好处就是如果页面元素发生变化,你去维护页面类即可,测试类你基本不用管。
po 是一种设计思想,不同的人根据这个思想写出来的代码是不一样的。(重点看如何封装)
总结:PO模型实现过程是:通过面向对象的方式,对页面定位和页面操作进行分离封装(解耦合,方便后续维护)。
优点:
提高代码的可读性
减少了代码的重复
提高代码的可维护性, 特别是针对UI界面频繁变动的项目.
(也就是面向对象的优点)
缺点:
造成项目结构比较复杂(因为是根据流程进行了模块化处理)
2.如何实现 PO 模型
PO模型一般首先抽象封装一个BasePage类,这个基类拥有一些指向Webdriver实例的属性,然后每一个Page继承基类BasePage,可以通过driver管理每一个Page中的元素,而且在Page中将这些操作封装为一个一个的方法。在测试用例中使用这些page类,进行组织测试步骤的工作。
这样做的好处,就是有元素变化,只需要维护每一个Page就行了,测试步骤变化,只需要维护TestCase即可。
PO实现案例:
点击百度,输入123,点击搜索,找到好123的官网,进入,在官网找到百度地图,点击查看。
案例分析
page为3,第一页为百度搜索页,第二页为好123搜索页,第三页为百度地图展示页。根据PO模型的设计理念,基类的封装一般包括,定位,点击,输入发送请求等。因为是多页,所以unittest应该使用@classmethod实现,所以如下:
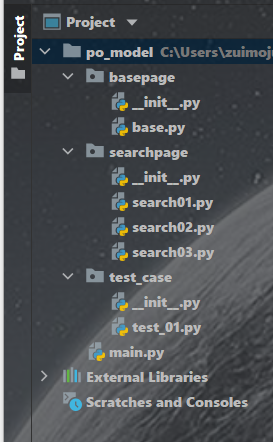
basepage:基类 searchpage:页数 test_case:测试用例
# base.py
# 基类,实际上也就是封装-------把公共的方法封装起来,用的时候直接调用即可
from selenium.webdriver.common.action_chains import ActionChains # 鼠标操作
class BasePageClass(object):
def __init__(self, driver, url):
self.driver = driver
self.base_url = url
# 进入网址
def get(self):
self.driver.get(self.base_url)
# 元素定位,替代八大定位
def get_element(self, *locator):
return self.driver.find_element(*locator)
# 点击
def left_click(self, *locator):
ActionChains(self.driver).click(self.get_element(*locator)).perform()
# 输入
def send_text(self, text, *locator):
self.driver.find_element(*locator).send_keys(text)
# 清除
def clear_text(self, *locator):
self.driver.find_element(*locator).clear()
# search01.py
# 继承基类。业务逻辑的实现。如果有多页,则有多个该文件
from basepage.base import BasePageClass
from selenium.webdriver.common.by import By
class SearchPageClass01(BasePageClass):
def __init__(self, driver, url):
BasePageClass.__init__(self, driver, url)
# 1.进入百度
def go_baidu(self):
self.get()
# 2.定位百度输入框并清空发送文本
def input(self, text):
self.get_element(By.ID, "kw").click()
self.send_text(text, By.ID, "kw")
# 3.点击搜索按钮
def click(self):
self.left_click(By.ID, "su")
# 4.定位好123点击
def hao123(self):
self.get_element(By.XPATH, ".//*[@id='1']/h3/a[1]").click()
# search02.py
# 继承基类。业务逻辑的实现。如果有多页,则有多个该文件
from basepage.base import BasePageClass
from selenium.webdriver.common.by import By
class SearchPageClass02(BasePageClass):
def __init__(self, driver, url):
BasePageClass.__init__(self, driver, url)
# 定位百度地图并点击
def biumap(self):
self.get_element(By.XPATH, ".//*[@id='userCommonSites']/ul/li[6]/div/a").click()
# search03.py
# 继承基类。业务逻辑的实现。如果有多页,则有多个该文件
from basepage.base import BasePageClass
class SearchPageClass03(BasePageClass):
def __init__(self, driver, url):
BasePageClass.__init__(self, driver, url)
# test_01.py
# 继承基类。业务逻辑的实现。如果有多页,则有多个该文件
from basepage.base import BasePageClass
class SearchPageClass03(BasePageClass):
def __init__(self, driver, url):
BasePageClass.__init__(self, driver, url)
以上就是最简单的实现PO模型的全部内容
如果要导入日志,报告,数据等其他的内容,可以参考博客:https://www.cnblogs.com/helenMemery/p/6687669.html

