
3.Spark设计与运行原理,基本操作
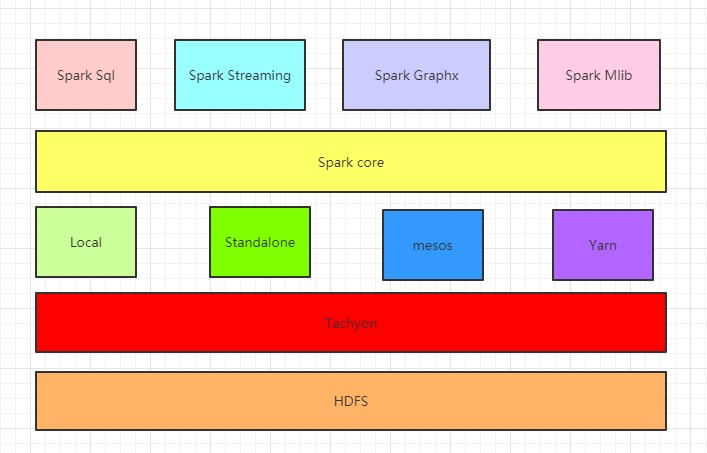
1.Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能。
2.请详细阐述Spark的几个主要概念及相互关系:
Master, Worker; RDD,DAG; Application, job,stage,task; driver,executor,Claster ManagerDAGScheduler, TaskScheduler.
1.Master,Worker
Master是任务控制节点主节点,常驻master守护进程,负责管理worker节点,我们从master节点提交应用
worker节点常驻worker守护进程,与master节点通信,并且管理executor进程。
Master与Worker是主从关系
2.RDD,DAG
RDD是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型
DAG是有向无环图,反应RDD之间的依赖关系
3.Application, job,stage,task
Application用户编写的Spark的应用程序
job:action的触发会生成一个job,Job会提交给DAGScheduler,分解成Stage
stage是作业的基本调度单位,每个作业会因为RDD之间的依赖关系拆分成多组任务集合TaskSet,成为调度阶段。调度阶段的划分是由DAGScheduler来划分的,有Shuffle Map Stage和Result Stage两种
task是被送到executor上的工作单元,task简单的说就是在一个数据partition上的单个数据处理流程。
4.driver,executor,Claster Manager,DAGScheduler, TaskScheduler
driver负责控制一个应用的执行,运行Application的main函数和初始化SparkContext,Driver将Task和Task所依赖的file和jar(序列化后)传递给对应的Worker机器运行
executor进程宿主在worker节点上,一个worker可以有多个executor。每个executor持有一个线程池,每个线程可以执行一个task,executor执行完task以后将结果返回给driver,每个executor执行的task都属于同一个应用
Claster Manager:在集群上获取资源的外部服务
DAGScheduler是面向调度阶段的任务调度器,负责接收spark应用提交的作业,根据RDD的依赖关系划分调度阶段,并提交调度阶段给TaskScheduler
TaskScheduler是面向任务的调度器,它接受DAGScheduler提交过来的调度阶段,然后把任务分发到work节点运行,由worker节点的Executor来运行该任务
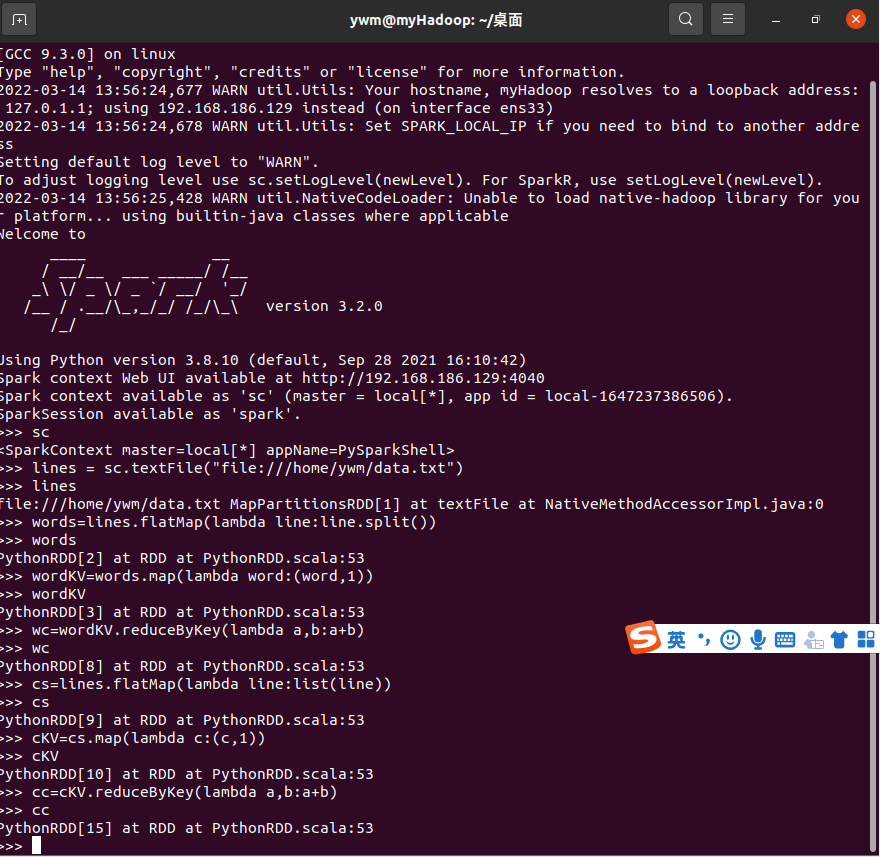
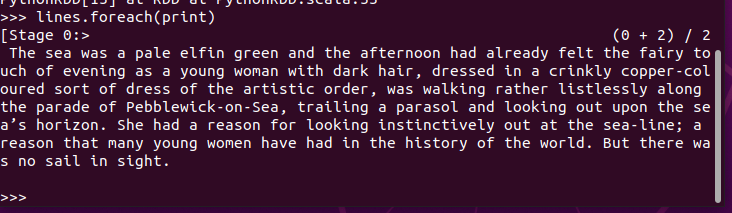
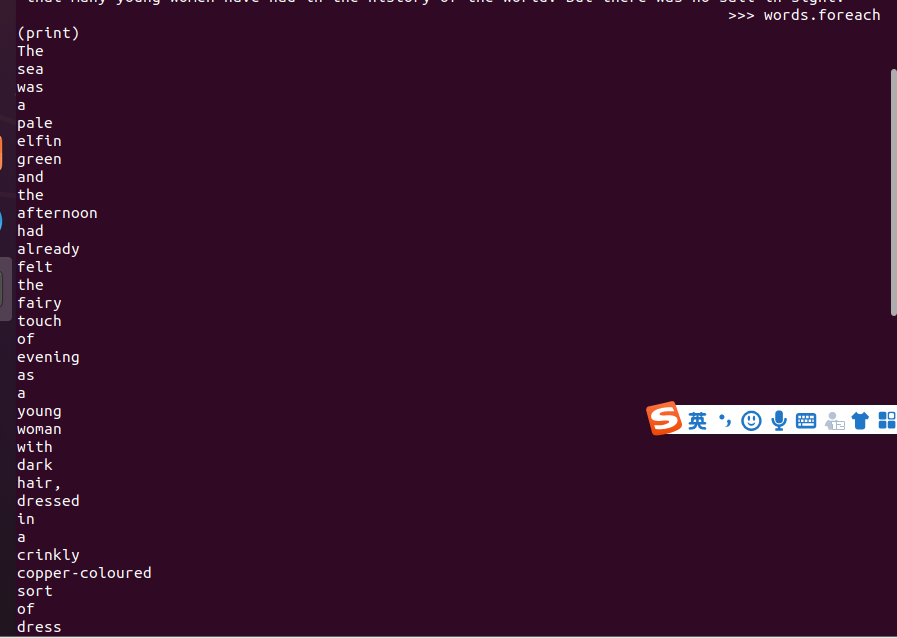
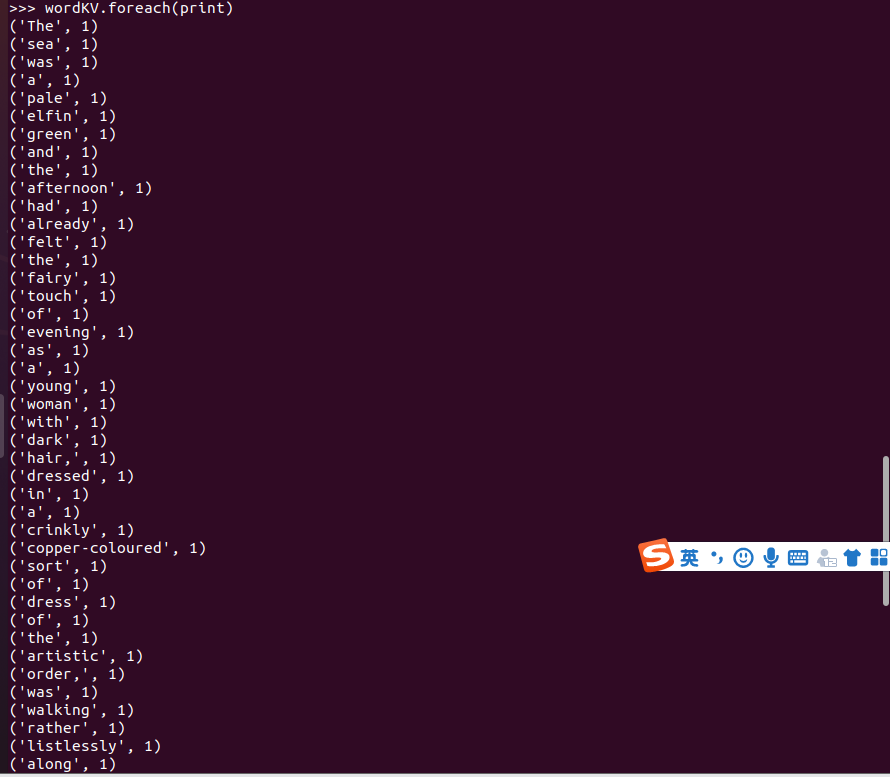
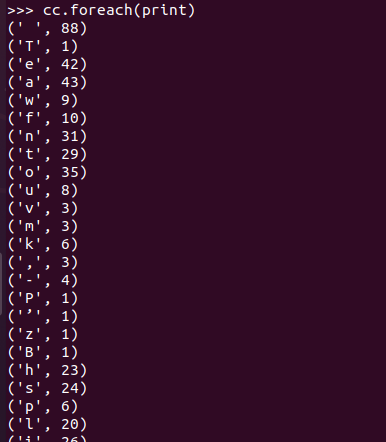
3.在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Ollama——大语言模型本地部署的极速利器
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· Windows编程----内核对象竟然如此简单?
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用