kubernetes系列-部署prometheus + grafana(k8s)
采集方案

通过prometheus-node-exporter采集主机的性能指标数据,并通过暴露的 /metrics 接口用prometheus抓取 通过kube-apiserver、kube-controller-manager、kube-scheduler、etcd、kubelet、kube-proxy自身暴露的 /metrics 获取节点上与k8s集群相关的一些指标数据 通过cadvisor采集容器、Pod相关的性能指标数据,并通过暴露的 /metrics 接口用prometheus抓取 通过blackbox-exporter采集应用的网络性能(http、tcp、icmp等)数据,并通过暴露的 /metrics 接口用prometheus抓取 通过kube-state-metrics采集k8s资源对象的状态指标数据,并通过暴露的 /metrics 接口用prometheus抓取 应用自己采集容器中进程主动暴露的指标数据(暴露指标的功能由应用自己实现,并添加约定的annotation,prometheus负责根据annotation实现抓取
- 抓取介绍:
Kubernetes可以约定好带哪些annotation前缀的服务是自主暴露监控指标的服务。应用添加约定的这些annotations,Prometheus可以根据annotation实现抓取。例如:
prometheus.io/scrape: 'true' 获知对应的endpoint是需要被scrape的 prometheus.io/app-metrics: 'true' 获知对应的endpoint中有应用进程暴露的metrics prometheus.io/app-metrics-port: '8080' 获知进程暴露的metrics的端口 prometheus.io/app-metrics-path: '/metrics' 获知进程暴露的metrics的具体路径
应用可以在service中指定约定的annotation,实现Prometheus对该应用的网络服务进行探测:
http探测: prometheus.io/scrape: 'true' prometheus.io/http-probe: 'true' prometheus.io/http-probe-port: '8080' prometheus.io/http-probe-path: '/healthz' tcp探测: prometheus.io/scrape: 'true' prometheus.io/tcp-probe: 'true' prometheus.io/tcp-probe-port: '80'
Prometheus根据这些annotations可以获知相应service是需要被探测的,探测的网络协议可以是http、tcp或其他,以及具体的探测端口。http探测需要知道探测的具体url。
2、blackbox-exporter 无需修改配置
下载prometheus的yaml文件
https://github.com/Tobewont/kubernetes
1、修改alertmanager-cm.yaml
主要修改发送邮箱和接受邮件
2、blackbox-exporter 无需修改配置
注意:
blackbox-exporter的配置文件为 /etc/blackbox_exporter/blackbox.yml, 运行时可以动态重载配置文件,当重新加载配置文件失败时,不影响运行中的配置。
重载方式:curl -XPOST http://ip:9115/-/reload
3、修改dingtalk
主要修改dingtalk-cm.yaml 钉钉机器人地址
4、无需修改grafana
5、无需修改k8s-components
6、无需修改kube-state-metrics
7、无需修改prometheus
8、一键部署
kubectl apply -f public-service-ns.yaml kubectl apply -f node-exporter/ kubectl apply -f k8s-components/ kubectl apply -f kube-state-metrics/ kubectl apply -f blackbox-exporter/ kubectl apply -f dingtalk/ kubectl apply -f alertmanager/ kubectl apply -f prometheus/ kubectl apply -f grafana/ 查看结果 kubectl get all -n public-service NAME READY STATUS RESTARTS AGE pod/alertmanager-9c4bf8565-z9mp9 1/1 Running 0 2m54s pod/blackbox-exporter-57d847fc4c-mq8mx 1/1 Running 0 2m58s pod/dingtalk-957f5896-9bd9b 1/1 Running 0 2m56s pod/grafana-76779dc8cf-2fk4x 1/1 Running 0 2m46s pod/kube-state-metrics-5d5f7cd774-tw4sw 1/1 Running 0 2m58s pod/node-exporter-29bkg 1/1 Running 0 3m5s pod/node-exporter-45k2d 1/1 Running 0 3m5s pod/node-exporter-8dbts 1/1 Running 0 3m5s pod/node-exporter-9kwwt 1/1 Running 0 3m5s pod/node-exporter-bxhcf 1/1 Running 0 3m5s pod/prometheus-65848cf9b4-m5kcf 1/1 Running 0 2m49s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/alertmanager ClusterIP 10.98.52.72 <none> 9093/TCP 2m55s service/blackbox-exporter NodePort 10.106.73.127 <none> 9115:30115/TCP 2m58s service/dingtalk ClusterIP 10.103.205.136 <none> 8060/TCP 2m57s service/grafana ClusterIP 10.103.12.113 <none> 3000/TCP 2m47s service/kube-state-metrics ClusterIP 10.98.99.215 <none> 8080/TCP 3m1s service/node-exporter ClusterIP None <none> 9100/TCP 3m6s service/prometheus ClusterIP 10.99.50.109 <none> 9090/TCP 2m51s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/node-exporter 5 5 5 5 5 <none> 3m5s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/alertmanager 1/1 1 1 2m55s deployment.apps/blackbox-exporter 1/1 1 1 2m58s deployment.apps/dingtalk 1/1 1 1 2m57s deployment.apps/grafana 1/1 1 1 2m46s deployment.apps/kube-state-metrics 1/1 1 1 3m deployment.apps/prometheus 1/1 1 1 2m51s NAME DESIRED CURRENT READY AGE replicaset.apps/alertmanager-9c4bf8565 1 1 1 2m55s replicaset.apps/blackbox-exporter-57d847fc4c 1 1 1 2m58s replicaset.apps/dingtalk-957f5896 1 1 1 2m56s replicaset.apps/grafana-76779dc8cf 1 1 1 2m46s replicaset.apps/kube-state-metrics-5d5f7cd774 1 1 1 3m replicaset.apps/prometheus-65848cf9b4 1 1 1 2m51s
登录prometheus 有两种方式登录一时改svc 改成nodeport的方式使用IP加端口登录,二是通过部署ingress可以查看我的其他文章部署。然后通过域名访问

如果上面看到kube-proxy报错则修改kubectl edit cm/kube-proxy -n kube-system

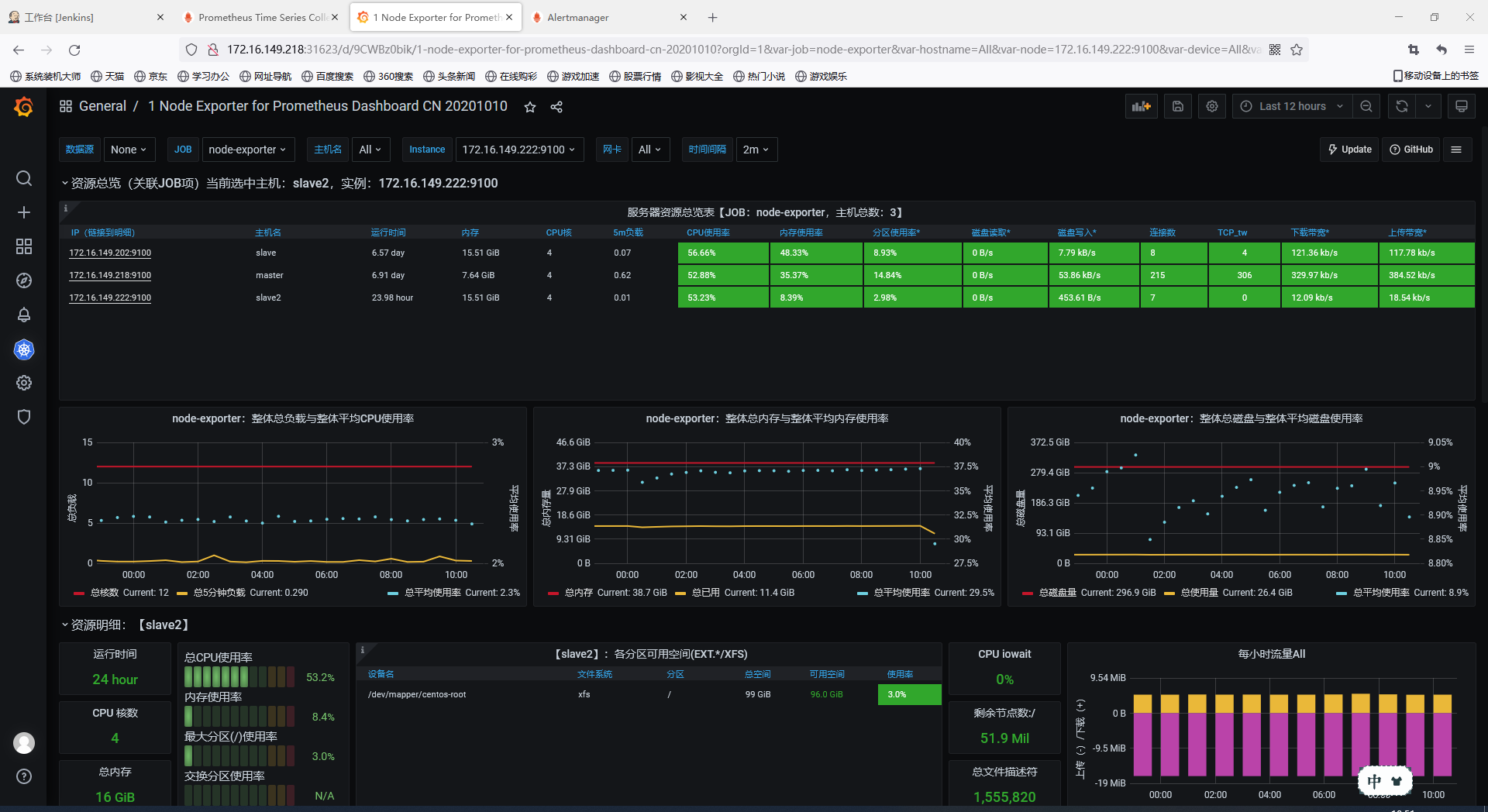
访问grafana.lzxlinux.cn,数据源是http://prometheus:9090,导入主机详情模板8919,
导入需要的k8s模板按需求进行调试监控
告警测试
- 宕机测试:
模拟node-exporter宕机,测试钉钉告警(critical)是否正常。这里选择node3作为测试机器。
vim kill_node-exporter.sh #!/bin/bash nodepid=`netstat -lntp | grep 9100 | awk '{print $NF}' | awk -F '/' '{print $1}'` nodenum=`netstat -lntp | grep 9100 | grep -v pause | wc -l` if [ $nodenum -eq 0 ];then exit else kill -9 $nodepid exit fi while :; do sh kill_node-exporter.sh; sleep 3; done
等待3m,收到钉钉故障告警和恢复告警
模拟CPU使用率为80%,测试邮件告警(warning)是否正常。这里选择node3作为测试机器。
CPU测试:
yum install -y stress-ng stress-ng -c 0 -l 80
查看邮件是否收到
以上部署是通过Gitlub上面已有的yaml文件进行部署大家也可以参考自己写yaml文件部署


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端