

Python基础3——内存 深浅拷贝 文件操作
1.内存相关
- 1.== 和 is有什么区别
- == 用于比较值是否相等
- is 用于比较内存地址是否相等
- 2.小数据池/小整数缓存机制/驻留机制
- 为了优化速度和内存使用设计,在一定范围内对整数进行复用,通常是[-5, 256]
- 由数字、字母、下划线组成的简单字符串本身或*1时,符合小数据池
- 由非数字、字母、下划线组成,并且乘以大于1的数,重新开辟内存来存储字符串
v1 = "alex" v2 = "alex" v3 = "alex_*"*5 v4 = "alex_*"*5 v5 = "zhangsan_666"*1 v6 = "zhangsan_666"*1 v7 = "lisi*" v8 = "lisi*" print(id(v1), id(v2)) # 4457566816 4457566816 print(id(v3), id(v4)) # 4457659600 4457659680 print(id(v5), id(v6)) # 4457623024 4457623024 print(id(v7), id(v8)) # 4457569264 4457568832 - 3.哈希
- 列表、字典、集合是可变类型,不能放在集合中且不能作为字典的key(unhashable)
- Python内部会将值进行哈希算法并得到一个数值(对应内存地址),以后用于快速查找
- 存储100万个数的列表,在查找时花费时间较多
- 对于字符串、元组等不可变类型,每一个值(如字典的key)经过hash运算得到一个内存地址,后续直接通过该地址找到数据,速度比列表快得多
- 4.不同数据类型嵌套存储示例
- 1.修改简单列表的元素
v1 = [1, 2, 3] v1[0] = 999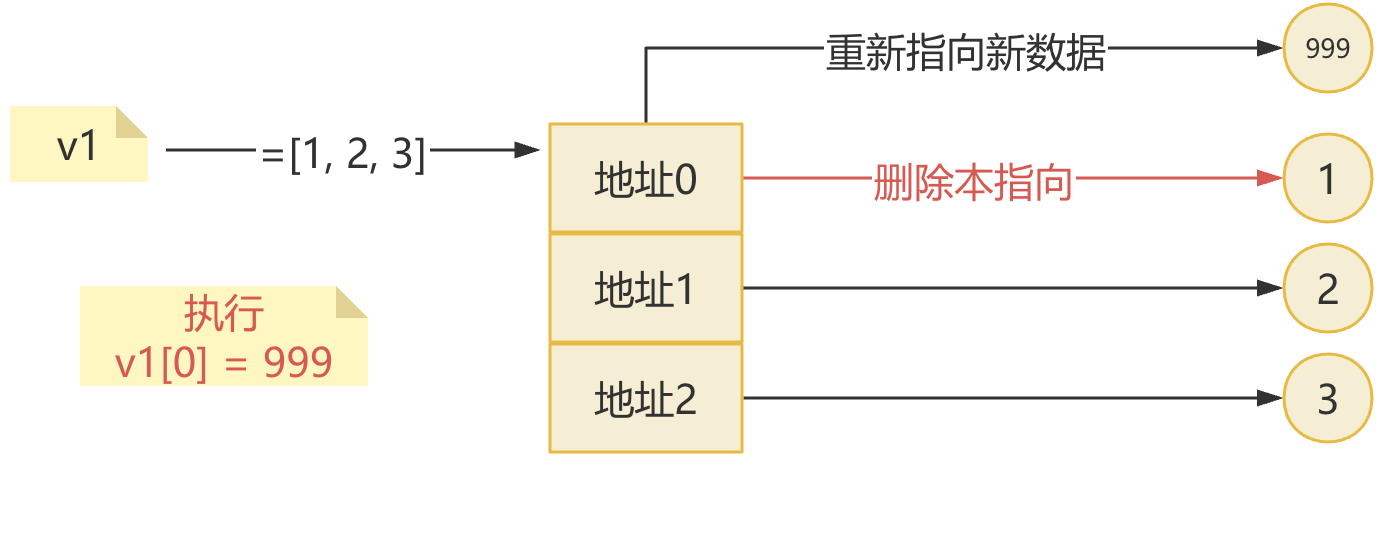
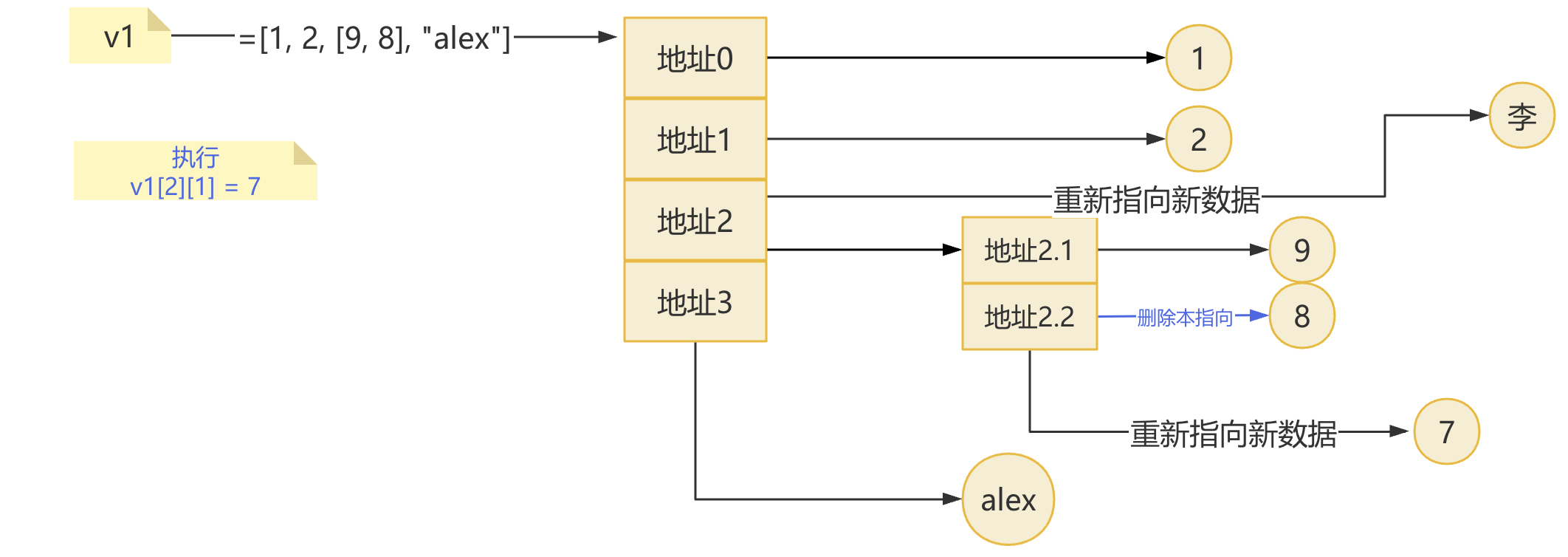
- 2.列表内部嵌套列表
v1 =[1, 2, [9, 8], "alex"]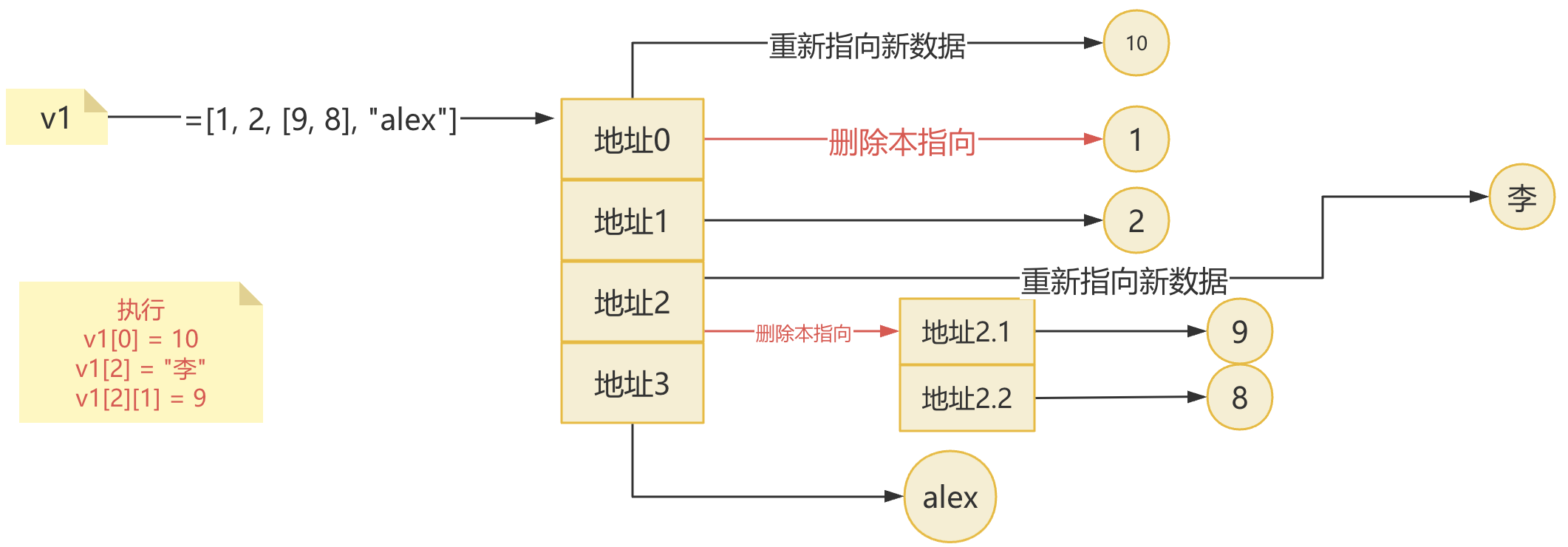
- 3.列表名作为列表元素
v1 = [1, 2] v2 =[1, 2, v1] v1[0] = "奇"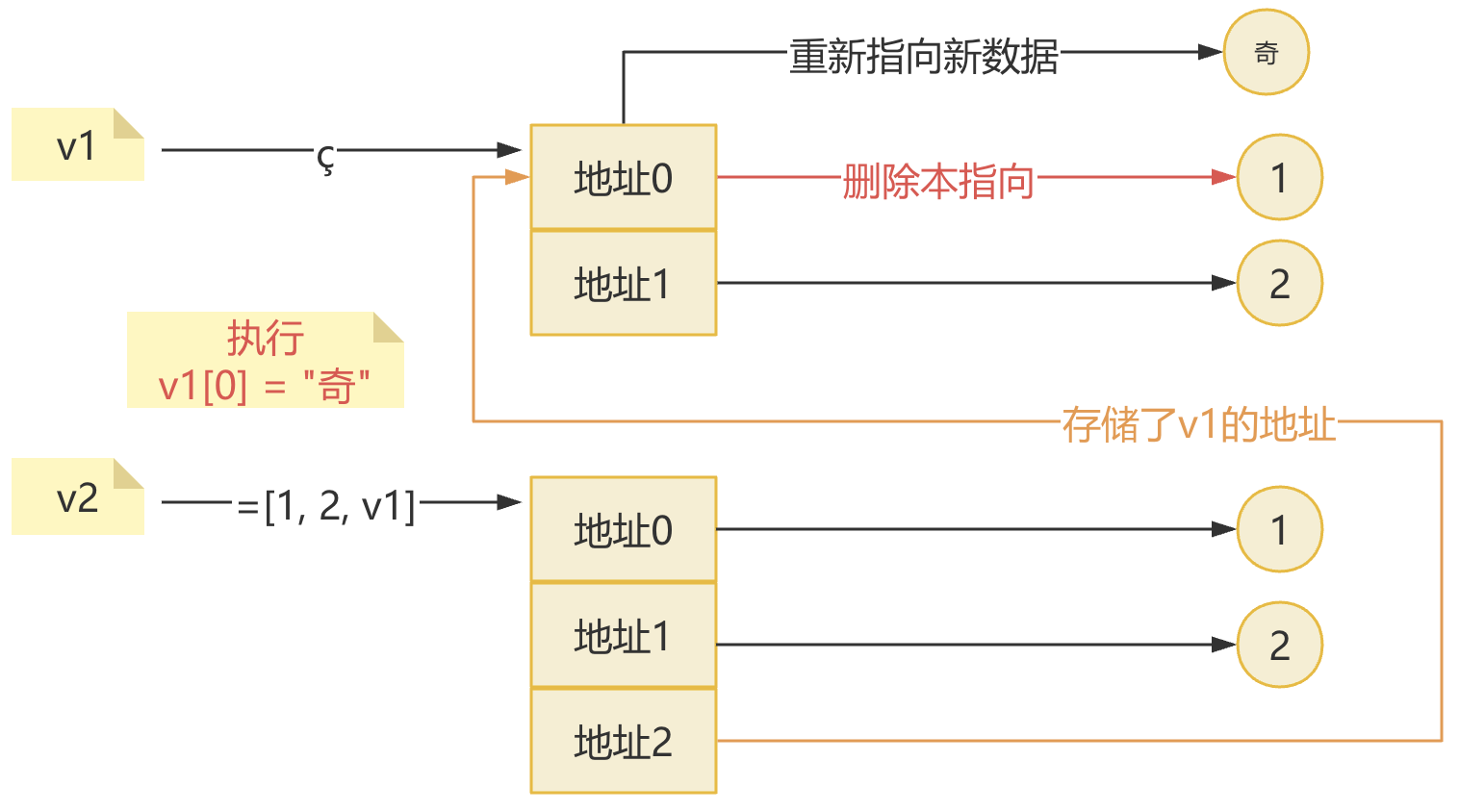
v1 = [1, 2] v2 =[1, 2, v1] v2[2] = 123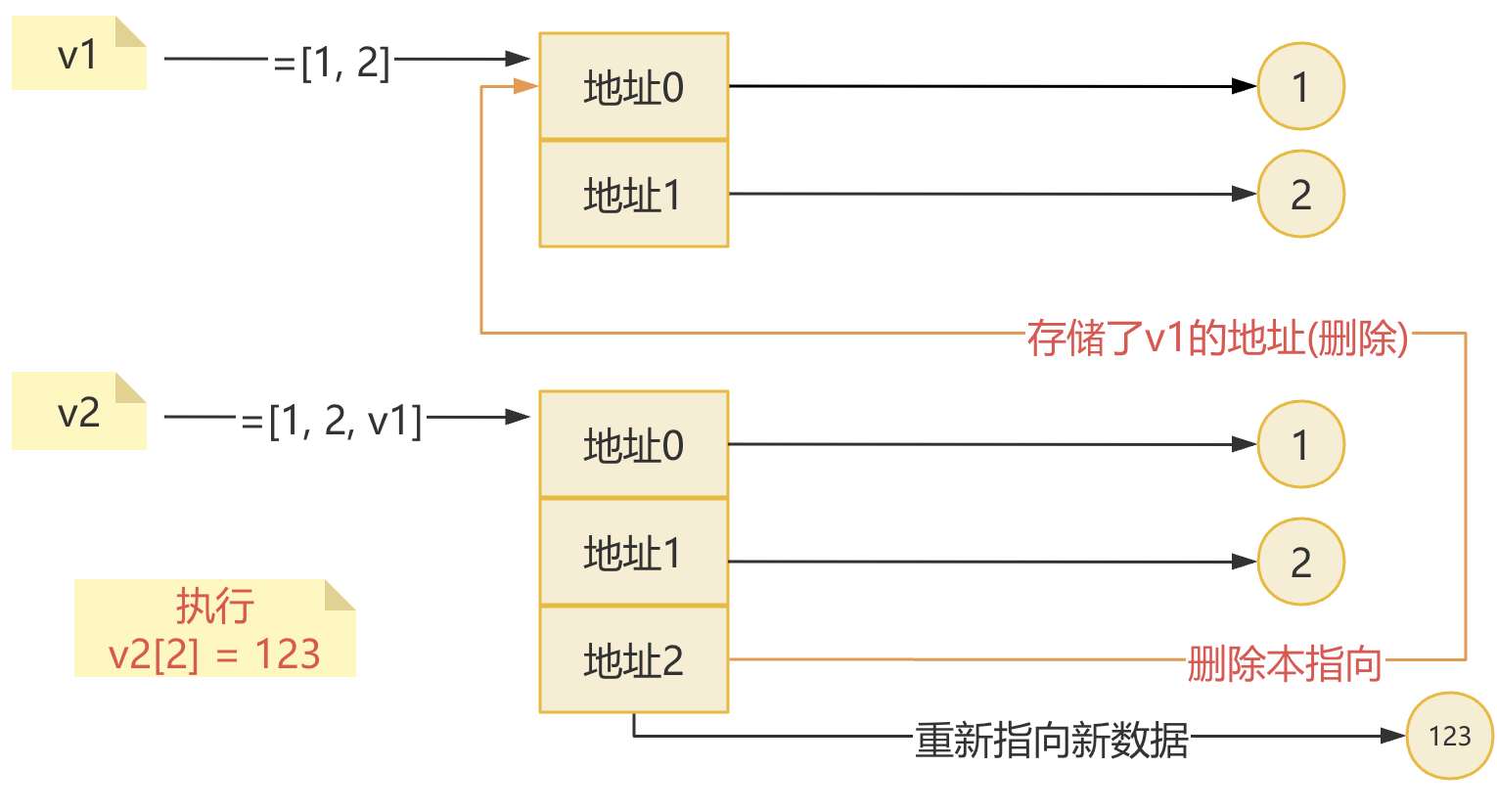
- 4.列表中嵌套字典
data_list = [] for i in range(4): data = {} data['user'] = i data_list.append(data)
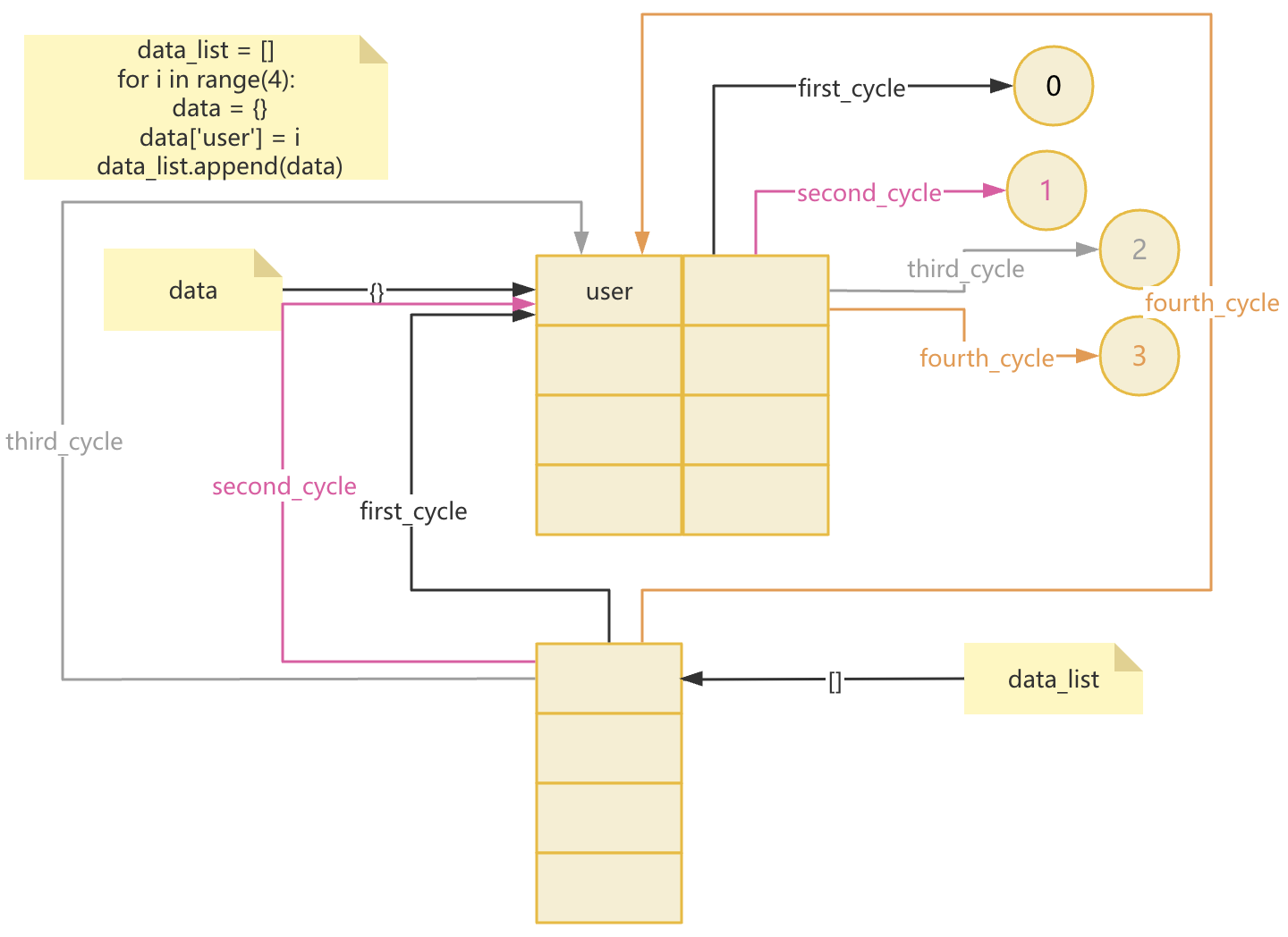
- 5.深拷贝与浅拷贝
- 1.普通列表
v1 = [1, 2, 3] v2 = copy.copy(v1) # 只拷贝了v1指向的三个内存空间的地址,存储的内容依然是v1指向的1 2 3 v3 = copy.deepcopy(v1) # 找到内部所有可变部分(列表的空壳子)拷贝一份,由于小数据池,所以和浅拷贝得到的结果一致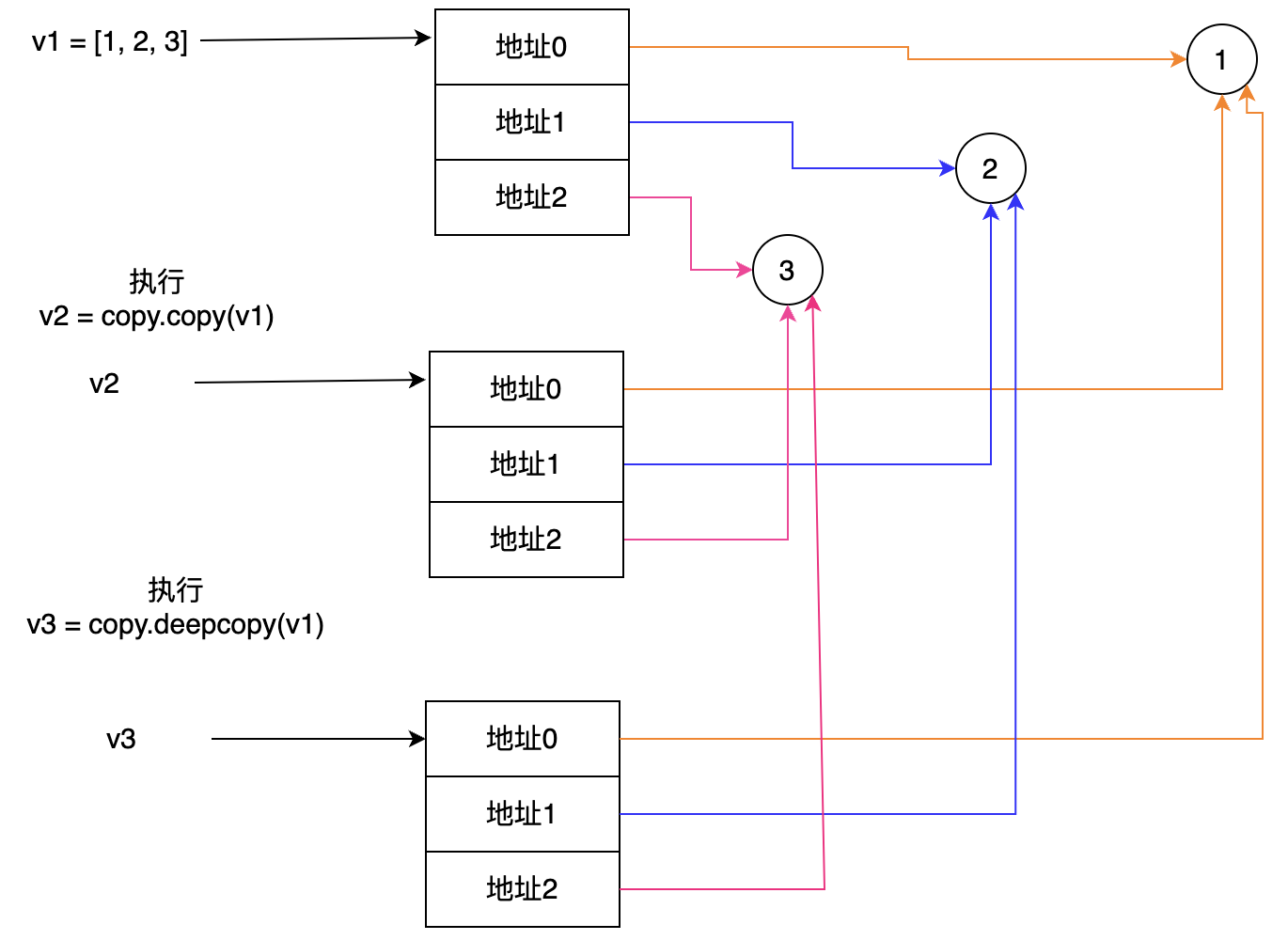
- 2.嵌套列表
v1 = [1, 2, [33, 99]] v2 = copy.copy(v1) # 把最外层的3元素列表空壳拷贝一份 v3 = copy.deepcopy(v1) # 把第1层和第2层的可变类型(列表)都拷贝一份,由于小数据池,数据没有重新拷贝 # 在可变类型的数据中,如果存在嵌套的结构类型,浅拷贝只复制最外层的数据,导致内存地址发生变化,里面数据的内存地址不会变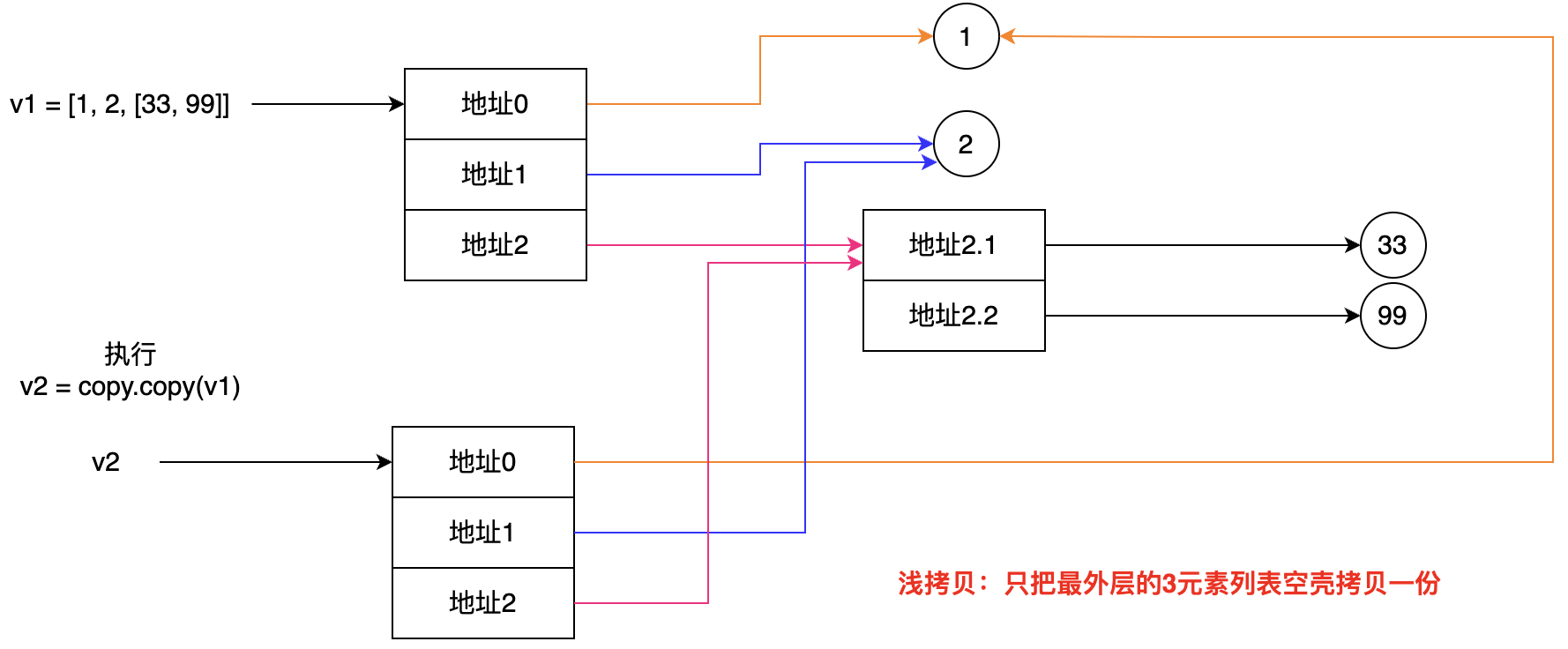
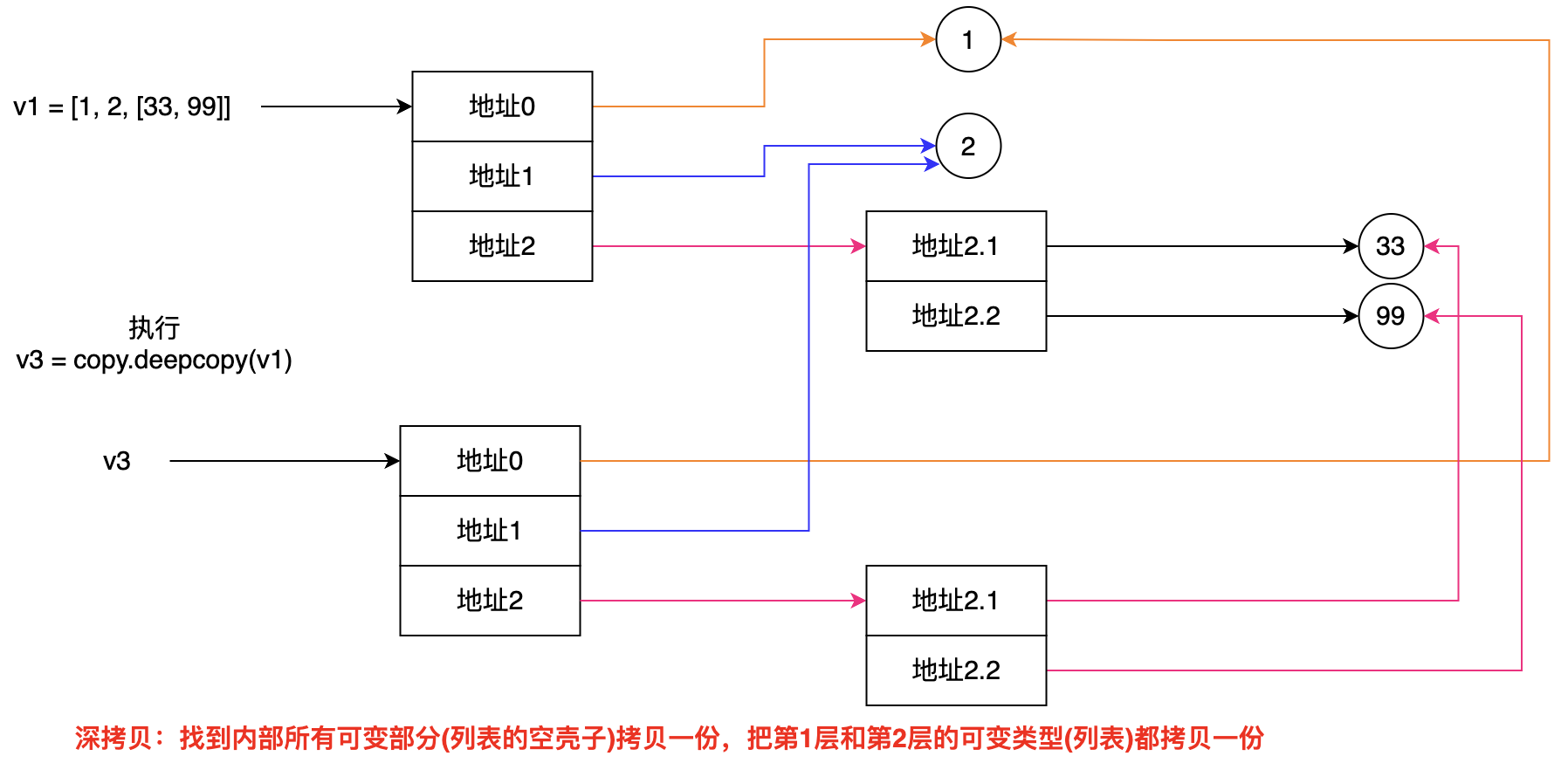
- 3.特殊情况:元组
- 当元组中不存在嵌套结构的时候,元组的深浅拷贝是相同的效果。
- 当元组的数据中存在嵌套的可变类型,比如列表等,深拷贝会重新开辟地址,将元组重新生成一份。
- 4.总结
- 浅拷贝
- 只拷贝数据的第1层(变量的指向) ,不会拷贝子对象
- 列表本身浅拷贝对象的地址和原对象的地址是不同的,因为列表是可变数据类型;如果元素本身是数值型,列表中的元素(第1个元素为例)和浅拷贝对象中的第一个元素的地址相同,是不可变的。
- 深拷贝
- 拷贝所有的可变数据类型,包含嵌套的数据中的可变数据。
- 对最外层数据是只拷贝数据,会开辟新的内存地址来存放数据;对里面的不可变数据类型直接复制数据和地址,和可变类型的浅拷贝是相同的效果。
- 对整个存在嵌套类型的数据进行深浅拷贝都会发生内存的变化,因为数据本身是可变的。
- 查看嵌套列表中的数值型元素的内存地址,发现它们是相同的,因为数值型不可变,不受拷贝的影响。
- 针对不可变类型的浅拷贝,只是换了一个名字,对象在内存中的地址其实是不变的,结果都相同
- 浅拷贝
- 6.文件操作
- 1.操作模式
- r read,只能读不能写,当文件不存在时会报错
- w write,只能写不能读,写前先清空文件;当文件不存在时会新建
- a append,只对文件内容进行追加,不能读,当文件不存在时会新建
- r+
- 读:默认从光标0开始读,也可以通过seek调整光标位置。
- 写:从光标所在的位置开始写(可能会将后续文字覆盖),也可以通过seek调整光标的位置。
- w+
- 读:默认光标永远在写入的最后或0,也可以通过 seek 调整光标的位置。
- 写:写入时会将文件清空。
- a+
- 读:默认光标在最后,也可以通过seek调整光标的位置后再去读取。
- 写:永远写到最后。
- 2.打开文件
- f = open("要打开的文件路径", mode="r/w/a", encoding="文件原来写入时定义的编码")
- 3.操作
- f.read() 读取文件的内容到内存(全部)
- f.read(2) 读取2个字符
- f.readlines() 按行读取
- f.write("要写入的内容")
- 4.关闭文件
- f.close()
- 示例1:f = open("a.txt", mode="w", encoding="utf-8")
- 一般用于文字写入
- 步骤 f.write("你好") f.close()
- a.将文件中的内容根据encoding指定的编码转换成01代码
- b.将二进制写入到文件中
- 示例2:f = open("a.txt", mode="wb")
- 一般用于图片/音频/视频/未知编码
- 步骤
- a.把要写入的字符串转换成二进制
- b.再将二进制写入到文件中
data = "我好困" content = data.enconde("utf-8") # 将字符串按照utf-8编码转换成二进制 f.write(content) # wb打开文件,则write传入的是二进制 f.close()
- 5.补充:大文件如何读取内容【50GB的日志文件】
- 不要一次性读取,内存容不下这么大的数据,会导致机器卡死
- 打开文件后,按行读取
- for line in open(filename, mode, enconding)
- 1.操作模式


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」