
爬取李子柒微博评论并分析
爬取李子柒微博评论并分析
微博主要分为网页端、手机端和移动端。微博网页版反爬太厉害,因此选择爬取手机端。
微博手机端地址:https://m.weibo.cn
1 需求
爬取李子柒微博中视频的评论信息,并做词频分析。
词频分析:http://cloud.niucodata.com/
2 方法
2.1 运行环境
- 运行平台: Windows
- Python版本: Python3.7
- IDE: PyCharm
2.2 爬取数据
首先要先找到自己的cookie,认识手机微博端的数据是如何进行加载的。手机微博是使用Ajax动态加载数据。这里以李子柒置顶视频为例,地址为:https://m.weibo.cn/detail/4206005635846050
在开发者工具下,network-xdr下找到以下信息:
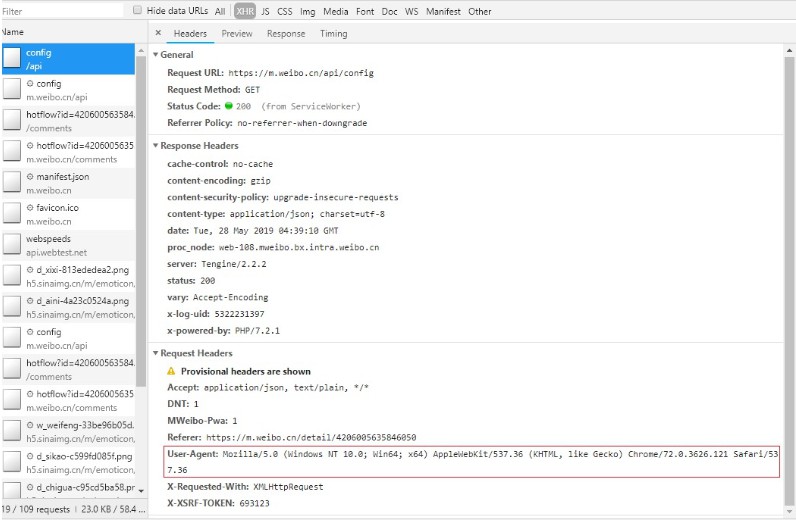
此外,还需要对比request url的组成,找出翻页规律:
Request URL: https://m.weibo.cn/comments/hotflow?id=4206005635846050&mid=4206005635846050&max_id_type=0``Request URL: https://m.weibo.cn/comments/hotflow?id=4206005635846050&mid=4206005635846050&max_id=849522136223909&max_id_type=0 https://m.weibo.cn/comments/hotflow?id=4206005635846050&mid=4206005635846050&max_id=168099804860905&max_id_type=0
经过对比发现,翻页时的两个关键信息为max_id和max_id_type,只要找到这两个信息,就可以对url进行拼接,从而实现多次爬取。这两个信息可以在之前返回的json文件中的preview找到。
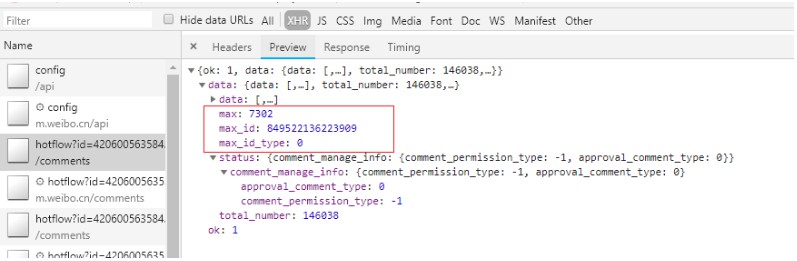
接下来是爬虫程序的设计:
``
# -*- coding: utf-8 -*-
import requests
import time
import os
import csv
import sys
import json
from bs4 import BeautifulSoup
import importlib
importlib.reload(sys)
# 要爬取热评的起始url
url = 'https://m.weibo.cn/comments/hotflow?id=4206005635846050&mid=4206005635846050&max_id='
# cookie UA要换成自己的
headers = {
'Cookie': '',
'Referer': 'https://m.weibo.cn/detail/4206005635846050',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
def get_page(max_id, id_type):
params = {
'max_id': max_id,
'max_id_type': id_type
}
try:
r = requests.get(url, params=params, headers=headers)
if r.status_code == 200:
return r.json()
except requests.ConnectionError as e:
print('error', e.args)
def parse_page(jsondata):
if jsondata:
items = jsondata.get('data')
item_max_id = {}
item_max_id['max_id'] = items['max_id']
item_max_id['max_id_type'] = items['max_id_type']
return item_max_id
def write_csv(jsondata):
datas = jsondata.get('data').get('data')
for data in datas:
created_at = data.get("created_at")
like_count = data.get("like_count")
source = data.get("source")
floor_number = data.get("floor_number")
username = data.get("user").get("screen_name")
comment = data.get("text")
comment = BeautifulSoup(comment, 'lxml').get_text()
writer.writerow([username, created_at, like_count, floor_number, source,
json.dumps(comment, ensure_ascii=False)])
# 存为csv
path = os.getcwd() + "/weiboComments.csv"
csvfile = open(path, 'w',encoding = 'utf-8')
writer = csv.writer(csvfile)
writer.writerow(['Usename', 'Time', 'Like_count', 'Floor_number', 'Sourse', 'Comments'])
maxpage = 50 #爬取的数量
m_id = 0
id_type = 0
for page in range(0, maxpage):
print(page)
jsondata = get_page(m_id, id_type)
write_csv(jsondata)
results = parse_page(jsondata)
time.sleep(1)
m_id = results['max_id']
id_type = results['max_id_type']
2.3 数据清洗与处理
按照上述代码分别得到五个数据集,但是得到的数据集充满噪声,要对该数据进行清洗,由于本文得到的评论数据已经较为干净,因此主要处理stop word、标点符号和表情符即可。为了简化工作,先用文本整理器软件对空值进行删除。
停词表采用的是哈工大停词表。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号