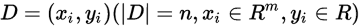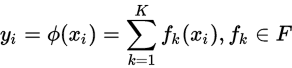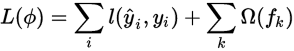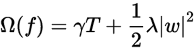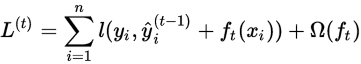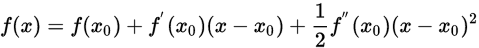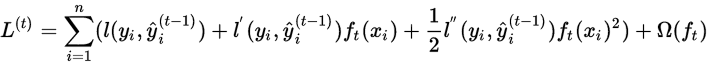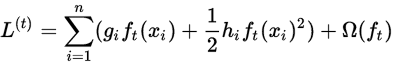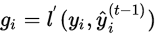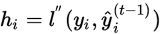xgboost
基本概念
Given dataset
a tree ensemble model uses K additive functions to predict the output
where,
是CART的集合
优化目标
其中,
为正则项
when train the model in additive manner, minimize the objective 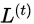 for
for 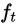
也即,
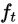
拟合的是

和
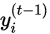
的差值
基于二阶泰勒展开
这是一条过
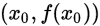
点的二次曲线,是
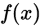
在
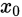
附近的近似
则可以针对
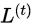
进行二次近似
进一步化解
其中