使用线程池和shardingsphere-jdbc对统计进行分表查询优化
记录之前的一次优化过程,之前发布在wiki上,现摘出发布。
0.前言
主要查询表为还款计划表xx_plan(近4000w,日新增10~20w)、实还记录表xx_actual(2600w+,日新增5~10w)、代偿记录表xx_compensation(近200w,日新增1w)。目前查询超时原因主要是表数据量过千万,且指标很多需要关联查询才能获得(数据查询SQL关键词:left join, count, distinct, sum, group by),数据库为MySQL,项目无换DB及大数据组件查询的计划,可预见的时间内仍使用该套架构,因此需要在当前架构下着手优化。
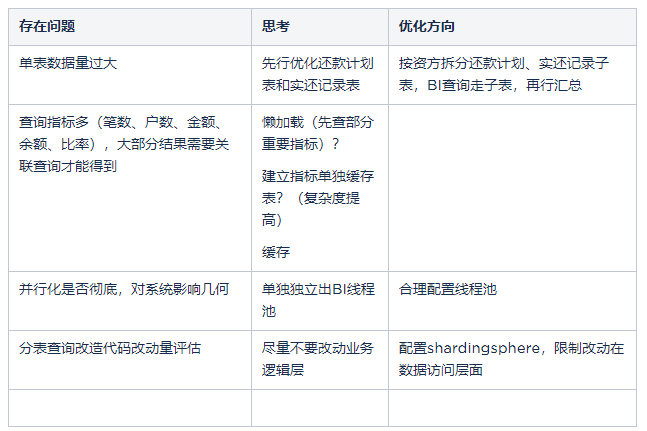
1.问题分析
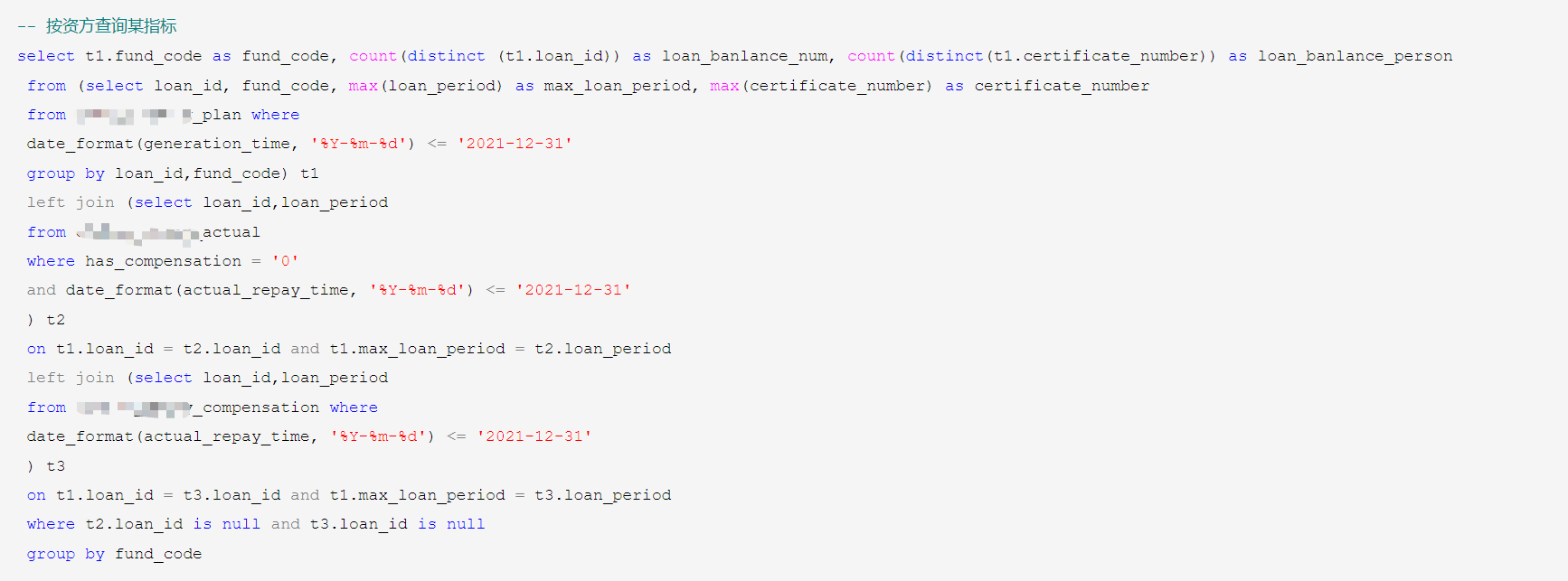
下图为上面SQL的explain分析,通过结果可以发现,获取指标不可避免会扫描commpn_repay_plan全表,因此优化的主要方向在于分表。
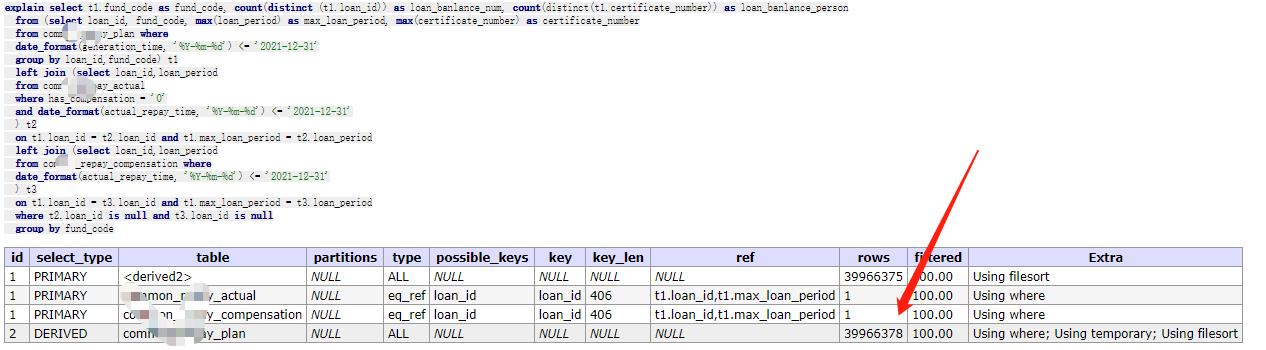
2.改造
2.1物理分表
将xx_plan,xx_actual 表按资方拆分为各个资方的子表,各子表包含对应资方的数据,设置日初任务每日同步数据到子表,保证数据一致。
2.2分表配置
2.2.1数据源配置
@Bean(name = "shardingDataSource") public DataSource shardingDataSource() throws SQLException { ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration(); //还款计划表分表策略 shardingRuleConfig.getTableRuleConfigs().add(getRepayPlanTableRuleConfiguration()); //实还记录表分表策略 shardingRuleConfig.getTableRuleConfigs().add(getRepayActualTableRuleConfiguration()); //关联关系绑定 shardingRuleConfig.getBindingTableGroups().add("xx_plan, xx_actual"); Properties properties = new Properties(); properties.put("sql.show","false"); //数据源 return ShardingDataSourceFactory.createDataSource(createDataSourceMap(), shardingRuleConfig, properties); } @Bean(name = "shardingSqlSessionFactory") public SqlSessionFactory shardingSqlSessionFactory(@Qualifier("shardingDataSource") DataSource dataSource) throws Exception { SqlSessionFactoryBean bean = new SqlSessionFactoryBean(); bean.setDataSource(dataSource); bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mybatis/sharding/*.xml")); return bean.getObject(); }
主要改动有两方面:①引入sharding-jdbc,配置相应的分表策略 ②独立出sharding数据源,使其仅影响分表相应Mapper映射文件(classpath:mybatis/sharding/*.xml)
2.2.2数据访问层
独立出分表单独的接口,所有走分表的SQL都要通过这里执行到。
2.3异步任务改造
2.3.1异步任务并行化改造
@Async(value = "threadPoolBITaskExecutor") public Future<List<GuaranteeSystemBIDataDetailStatistic>> getLoanBanlanceCountStatistics(String endDate) { //异步任务列表,一个查询分为(资金方个数)个异步任务 List<Future<List<GuaranteeSystemBIDataDetailStatistic>>> futures = new ArrayList<>(); for (int i = 0; i < ALL_FUND_CODE_ON_LOAN_SEARCH_LIST.size(); i++) { //传输fund_code,作为路由依据 Future<List<GuaranteeSystemBIDataDetailStatistic>> statisticsFuture = biAsyncProcess.getLoanBanlanceCountStatistics(ALL_FUND_CODE_ON_LOAN_SEARCH_LIST.get(i), endDate); futures.add(statisticsFuture); } return getCommonStatistics(futures); } public static Future<List<GuaranteeSystemBIDataDetailStatistic>> getCommonStatistics(List<Future<List<GuaranteeSystemBIDataDetailStatistic>>> futures){ List<GuaranteeSystemBIDataDetailStatistic> biDataDetailStatistics = new ArrayList<>(); Set<Integer> countSet = new HashSet<>(); while(true){ for (int i = 0; i < futures.size(); i++) { if(futures.get(i).isDone()){ countSet.add(i); } } //中断条件 if(countSet.size()==futures.size()){ break; } try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } } for (int i = 0; i < futures.size(); i++) { List<GuaranteeSystemBIDataDetailStatistic> statistics = null; try { statistics = futures.get(i).get(); } catch (Exception e) { logger.error("############## getCommonStatistics Error ###############",e); e.printStackTrace(); } //结果合并 if(CollectionUtils.isNotEmpty(statistics)){ biDataDetailStatistics.addAll(statistics); } } return new AsyncResult<>(biDataDetailStatistics); }
//某个指标查询 @Async(value = "threadPoolBITaskExecutor") public Future<List<GuaranteeSystemBIDataDetailStatistic>> getLoanBanlanceCountStatistics(String fundCode,String endDate) { String redisCacheKey = REDIS_KEY_PRE+"getLoanBanlanceCountStatistics/"+fundCode+"/"+endDate; String cacheContent = (String) redisTemplate.opsForValue().get(redisCacheKey); if (StringUtils.isNotBlank(cacheContent)) { List<GuaranteeSystemBIDataDetailStatistic> loanBanlanceCountStatistics = new Gson().fromJson(cacheContent,new TypeToken<List<GuaranteeSystemBIDataDetailStatistic>>(){}.getType()); return new AsyncResult<>(loanBanlanceCountStatistics); } List<GuaranteeSystemBIDataDetailStatistic> loanBanlanceCountStatistics = biSearchShardingMapper.selectLoanBanlanceCountStatisticByFundCodeAndRepayTime(fundCode,endDate); redisTemplate.opsForValue().set(redisCacheKey, JacksonUtil.bean2Json(loanBanlanceCountStatistics), REDIS_CACHE_HOURS, TimeUnit.HOURS); return new AsyncResult<>(loanBanlanceCountStatistics); }
涉及分表的查询都按如上改造。
2.3.2线程池配置
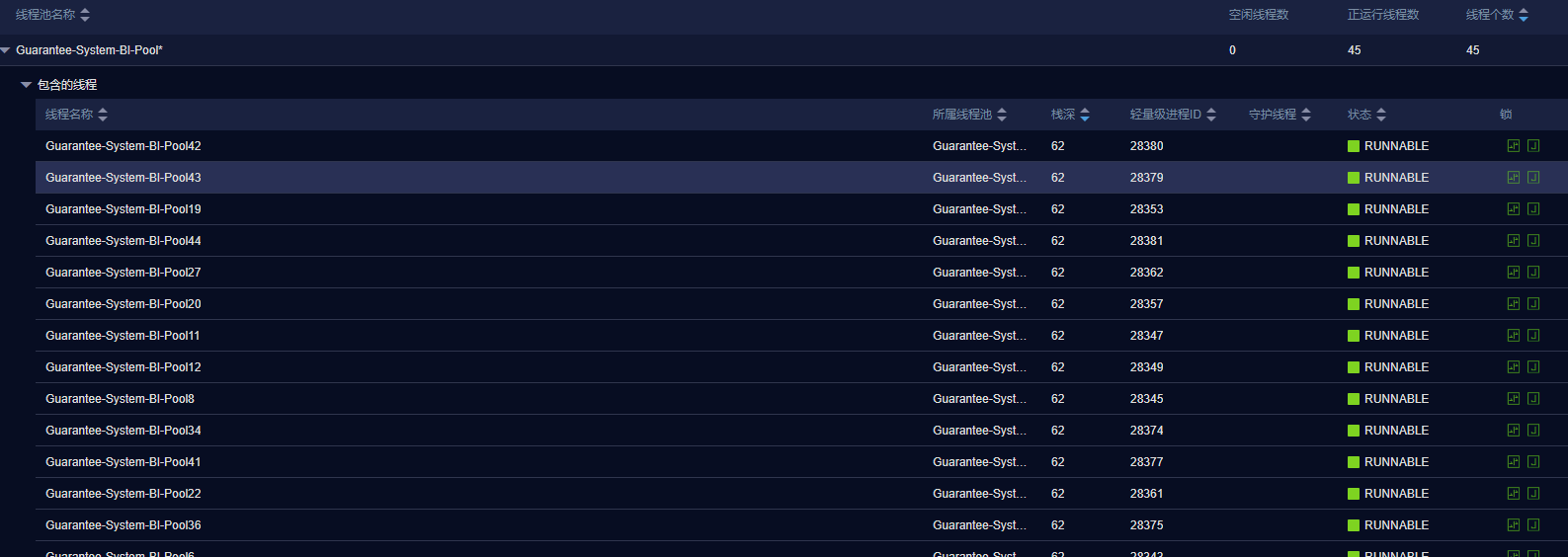
以BI XX查询为例,分表查询后有141条SQL要并发执行(后续新增资方还会增加执行条数),妥妥的IO密集型任务,线程数 = CPU核心数/(1-阻塞系数) 依照此公式得出预估最大线程数,结合线程监控,合理设置线程数。
继承ThreadPoolTaskExecutor ,重写submit方法,对其增加监控,查看线程池状态,帮助获得配置。
public class MonitorThreadPoolExecutor extends ThreadPoolTaskExecutor { private static final Logger logger = LoggerFactory.getLogger(MonitorThreadPoolExecutor.class); public void monitor(){ logger.info("**** getActiveCount=={},getPoolSize=={},getLargestPoolSize=={},getTaskCount=={},getCompletedTaskCount=={},getQueue=={} ***",this.getThreadPoolExecutor().getActiveCount(),this.getThreadPoolExecutor().getPoolSize(),this.getThreadPoolExecutor().getLargestPoolSize(),this.getThreadPoolExecutor().getTaskCount(),this.getThreadPoolExecutor().getCompletedTaskCount(),this.getThreadPoolExecutor().getQueue().size()); } @Override public <T> Future<T> submit(Callable<T> task) { monitor(); return super.submit(task); } } @Bean(name = "threadPoolBITaskExecutor") public Executor threadPoolBITaskExecutor() { ThreadPoolTaskExecutor executor = new MonitorThreadPoolExecutor(); *** }
并发执行
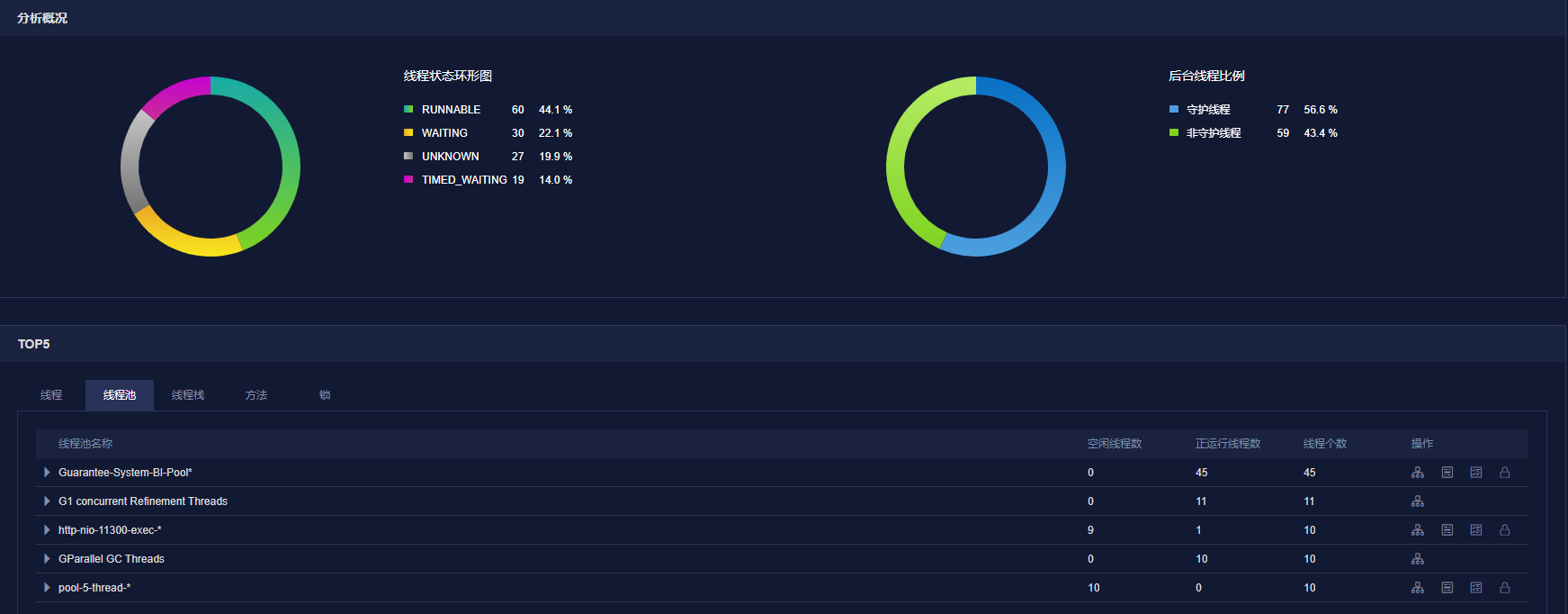
2.3.3方法改造
以贷前贷中报表为例,分析涉及哪些指标需要可以分表查询:
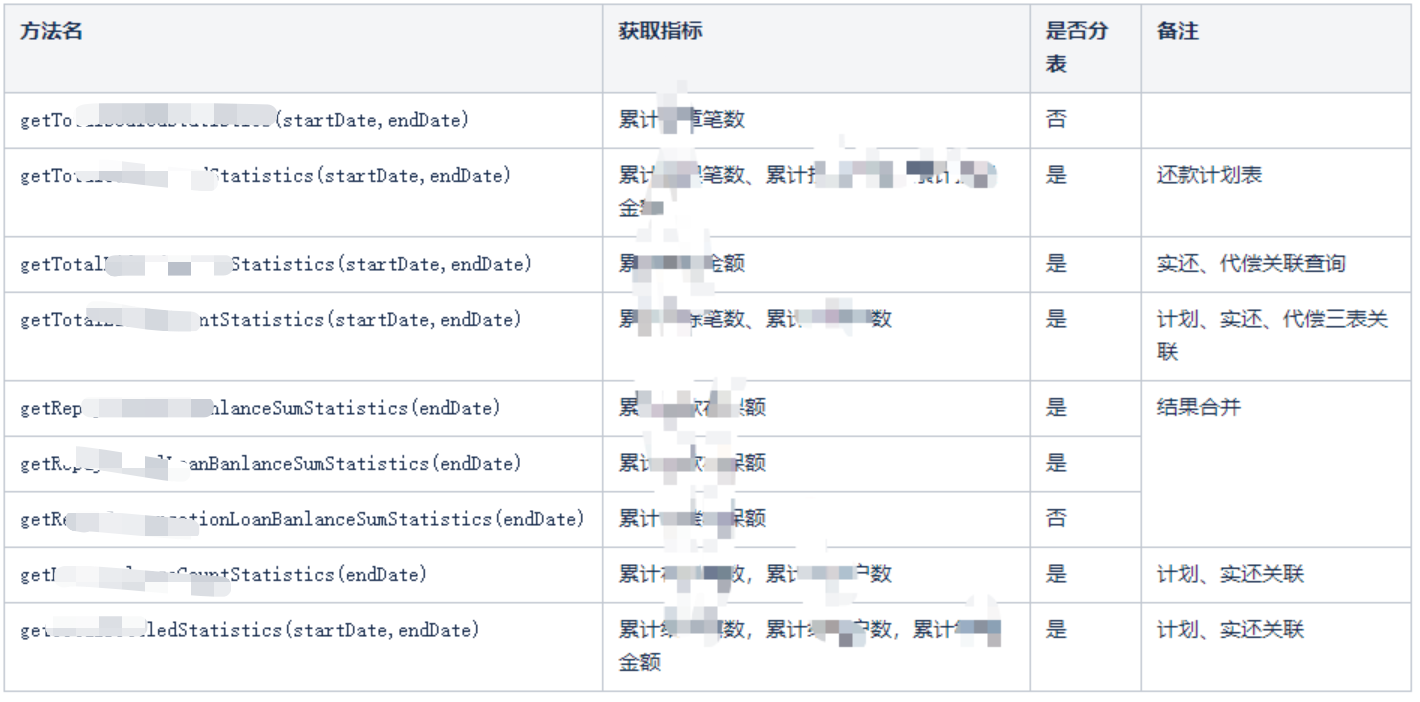
其他报表查询分析略。
3.思考
采用并发+分表模式,整体缩短了查询时间,后面变量主要有两块:
①新增资方后,并发查询数会增加 10+/资方
目前设置的核心线程数足够支持,此外适当延长阻塞队列长度,新增资方对整体查询效率影响不大。
②短板效应,目前整体查询时间约等于执行时间最长的一条SQL
并发模式下,查询瓶颈在于执行时间最长的SQL(受限于单个资方(aa、bb)子表数据量依然较为庞大,汇总查询不可避免扫描全部数据),后续如果影响使用,解决方法一为继续对该表拆分,新增路由策略;方法二为提前缓存该资方的数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号