压测引起的 nginx报错 502 no live upstreams while connecting to upstream解决
对系统的某个接口进行极限压测,随着并发量上升,nginx开始出现502 no live upstreams while connecting to upstream的报错,维持最大并发量一段时间,发现调用接口一直返回502,即nginx已经发现不了存活的后端了。

通过跟踪端口,发现nginx 跟后端创建了大量的连接。这很明显是没有使用http1.1长连接导致的。因此在upstream中添加keepalive配置。
upstream yyy.xxx.web{ server 36.10.xx.107:9001; server 36.10.xx.108:9001; keepalive 256; } server { ··· location /zzz/ { proxy_pass http://yyy.xxx.web; ··· } }
根据官方文档的说明:该参数开启与上游服务器之间的连接池,其数值为每个nginx worker可以保持的最大连接数,默认不设置,即nginx作为客户端时keepalive未生效。
默认情况下 Nginx 访问后端都是用的短连接(HTTP1.0),一个请求来了,Nginx 新开一个端口和后端建立连接,请求结束连接回收。如果配置了http 1.1长连接,那么Nginx会以长连接保持后端的连接,如果并发请求超过了 keepalive 指定的最大连接数,Nginx 会启动新的连接来转发请求,新连接在请求完毕后关闭,而且新建立的连接是长连接。
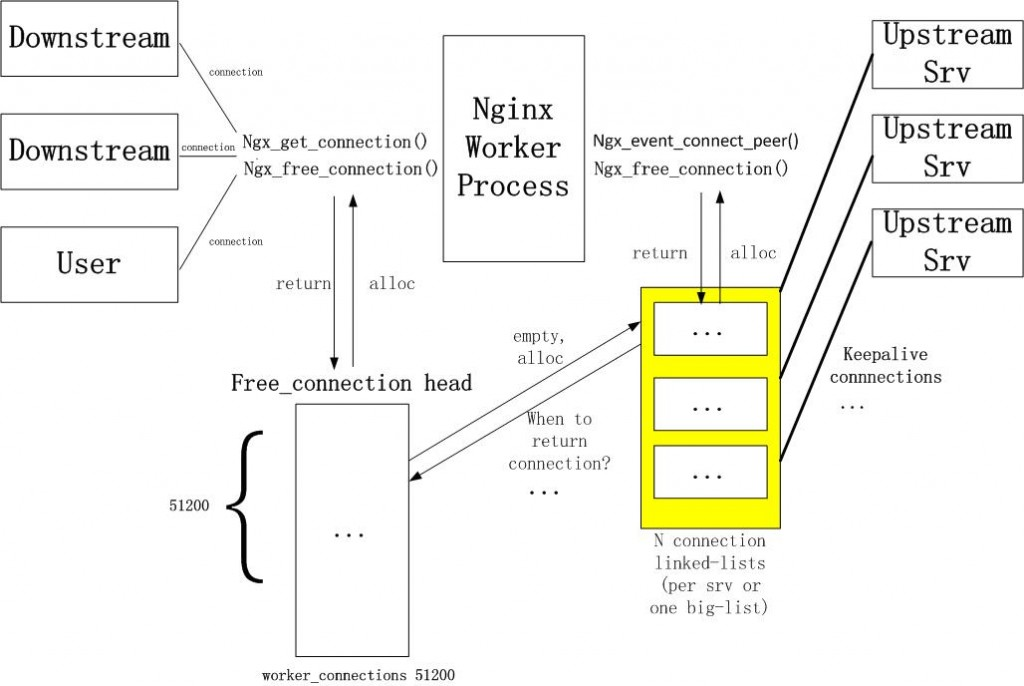
上图是nginx upstream keepalive长连接的实现原理。
首先每个进程需要一个connection pool,里面都是长连接,多进程之间是不需要共享这个连接池的。 一旦与后端服务器建立连接,则在当前请求连接结束之后不会立即关闭连接,而是把用完的连接保存在一个keepalive connection pool里面,以后每次需要建立向后连接的时候,只需要从这个连接池里面找,如果找到合适的连接的话,就可以直接来用这个连接,不需要重新创建socket或者发起connect()。这样既省下建立连接时在握手的时间消耗,又可以避免TCP连接的slow start。如果在keepalive连接池找不到合适的连接,那就按照原来的步骤重新建立连接。 我没有看过nginx在连接池中查找可用连接的代码,但是我自己写过redis,mysqldb的连接池代码,逻辑应该都是一样的。谁用谁pop,用完了再push进去,这样时间才O(1)。
需要注意的是:我在我的nginx1.12.0版本中新增该配置之后,再次压测,502问题依然存在,升级到1.16.0版本之后,502问题解决。原因是nginx1.12.0版本不支持长连接配置。
另外,如果nginx所在服务器和建立连接后端服务所在服务器不在同一网段时(即两台机器之间存在防火墙),还需要注意防火墙对长连接的影响。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号