
在win7下的eclipse中实现wordcount以及cascading-wordcount
准备:由于是在win7下的eclipse中运行hadoop程序,我们需要一些能在win7下运行的插件,
1,见上篇博客,我们搭建好hadoop HA机制的集群后,将三台虚拟机均开启,所需进程也开启(见上篇博客)
2,在wind7下的某个文件夹下保存hadoop-2.4.1的文件夹,该文件夹里的内容和centos上搭建的hadoop集群的内容一模一样,我保存在F:\download里面
3,在官网下载eclipse软件,我用的是eclipse-jee-kepler-SR2-win32-x86_64,将其解压放在E:\soft\eclipse-jee-kepler-SR2-win32-x86_64
4,我们需要在eclipse解压包里的E:\soft\eclipse-jee-kepler-SR2-win32-x86_64\eclipse\plugins路径下存放关于eclipse连接hadoop的插件,该插件官网是没有的,需要自己用源码来编译,我是在网上下载的别人的,即hadoop-2.4.1-eclipse-4.4-plugin.jar将其放在上述目录中,这样在重启eclipse的时候
点击菜单栏 windows->preferences会出现Haddop Map/Reduce,点击它,将目录指向我们之前存好的hadoop-2.4.1文件夹,我的为F:\downloads\hadoop-2.4.1
5,经过上述步骤后我们可以连接我们的hadoop集群,在加载一 些需要的jar包之后,我们运行hadoop的wordcount程序是会报错的,原因的我们并没有在win7下配置hadoop的环境变量,并且在hadoop-2.4.1de bin包下还缺少一些文件,hadoop.dll文件和winutils.exe文件,它们是hadoop程序能在wind7下的必要文件,官网下载的hadoop-2.4.1.tar.gz文件中是没有的,这两个文件也需要我们自己编译,所以说编译很重要,声明,这两个文件的下载可以是2.4.1版本以上的,低于2.4.1版本的这两个文件
放到hadoop-2.4.1的bin目录下也会报错
6,将以上配置好后,我们还需要将hadoop.dll文件在win7下的C:\Windows\System32目录下也放一份,同时在win7的环境变量中配置
HADOOP_HOM=F:\downloads\hadoop-2.4.1,同时将 %HADOOP_HOME%\bin放入环境变量Path中
7,经过上述步骤,基本上是可以实现在win7下的eclipse中完完全全运行hadoop程序,声明在运行程序前,比如运行cascading-wordcount前,我们需要将cascading包中的jar文件放到我们当前的map/reduce应用下,core-site.xml,hdfs-site.xml以及log4j.properties需要到当前应用的src下
一,运行wordcount程序
worcount程序有三个类如下,我们以hadoop的方式运行第三个类
上源码:
/** * Mapper类读取输出并且执行map函数,编写Mapper类必须继承org.apache.hadoop.mapreduce.Mapper类,并且根据相应的逻辑实现map函数, Mapreduce计算框架会将键值对作为参数传递给map函数 */ //LongWritable代表行号,Text代表该行的内容,Text代表中间输出结果的关键词,IntWritable代表中间输出结果关键词出现的次数 public class TokenizerMapper extends Mapper<LongWritable, Text, Text,IntWritable > { private final static IntWritable one = new IntWritable(1);//用来计算关键词在这行文本里出现的次数 private Text word = new Text(); public void map(LongWritable ikey, Text ivalue, Context context) throws IOException, InterruptedException { String line = ivalue.toString();//获取文本所有的行 //StringTokenizer类的nextToken()方法将每行文本拆分为单个单词 StringTokenizer itr = new StringTokenizer(line);//获取文本所有的行 while(itr.hasMoreTokens())//遍历每行的文本 { word.set(itr.nextToken());//每行文本拆分为单个单词 context.write(word, one);//将其作为中间结果进行输出,word代表关键词,one代表关键词在这行出现的次数 } }
public class IntSumReducer extends Reducer<Text, IntWritable, Text,IntWritable> { /** * Reducer接收到Mapper输出的中间结果并执行reduce函数,reduce函数接收到的参数形如<key,List<value>>, * 这是因为map函数将key值相同的所有value都发送给reduce函数,在reduce函数中,完成对相同key值得计数并将最后结果输出 * Reduce类的泛型代表了reduce函数输入键值对的键的类,以及值得类,输出键值对键的类以及值的类 */ private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // process values int sum = 0; for (IntWritable val : values) { sum = sum + val.get(); } result.set(sum); context.write(key, result); } }
public class WordCount { public static void main(String args[]) throws IOException, ClassNotFoundException, InterruptedException{ Configuration conf = new Configuration(); if(args.length!=2){ System.err.println("Usage:wordcount <in> <out>"); System.exit(2);} @SuppressWarnings("deprecation") Job job = new Job(conf,"word count"); job.setJarByClass(WordCount.class); //set Mapped class job.setMapperClass(TokenizerMapper.class); // set Reducer class job.setReducerClass(IntSumReducer.class); //set reduce function output key class job.setOutputKeyClass(Text.class); //set reduce function output value class job.setOutputValueClass(IntWritable.class); //set input path FileInputFormat.addInputPath(job, new Path(args[0])); //set output path FileOutputFormat.setOutputPath(job, new Path(args[1])); //submit job System.exit(job.waitForCompletion(true)?0:1); }
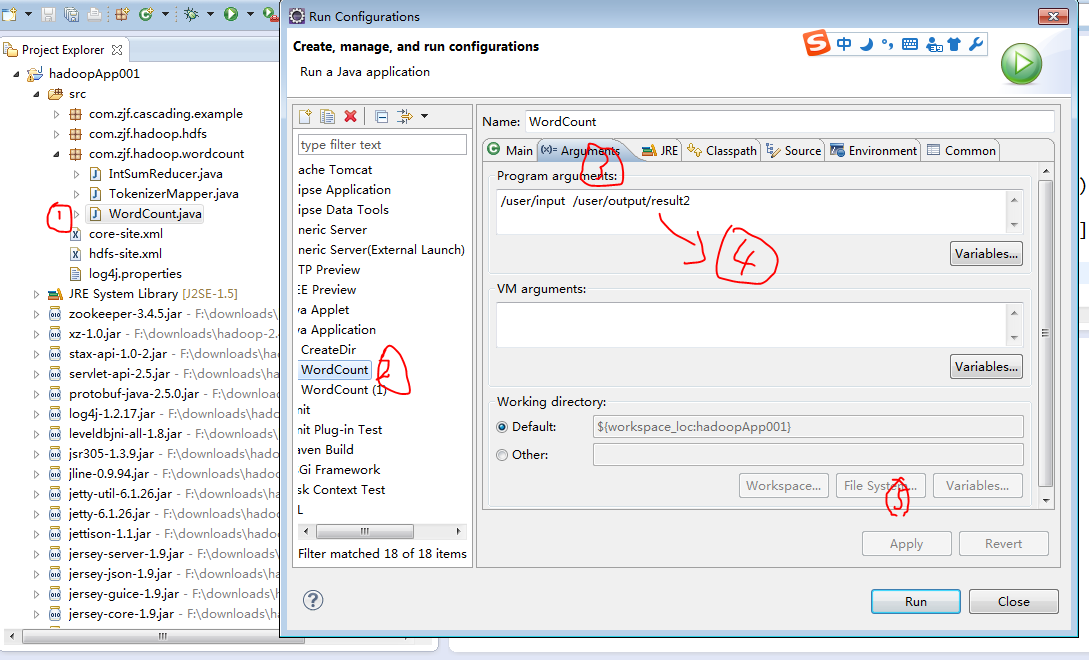
hdfs的目录树下/user/output/下会多出一个文件夹result2,里面就包含每个单词出现的个数的文件
二,cascading-wordcount的运行
它和之前在centos的eclipse中运行有些不一样,不一样在于地址,不说了先上源码,源码上有解析
package com.zjf.cascading.example; /* * WordCount example * zjf-pc * Copyright (c) 2007-2012 Concurrent, Inc. All Rights Reserved. * Project and contact information: http://www.concurrentinc.com/ */ import java.util.Map; import java.util.Properties; import cascading.cascade.Cascade; import cascading.cascade.CascadeConnector; import cascading.cascade.Cascades; import cascading.flow.Flow; import cascading.flow.FlowConnector; import cascading.operation.Identity; import cascading.operation.aggregator.Count; import cascading.operation.regex.RegexFilter; import cascading.operation.regex.RegexGenerator; import cascading.operation.regex.RegexReplace; import cascading.operation.regex.RegexSplitter; import cascading.operation.xml.TagSoupParser; import cascading.operation.xml.XPathGenerator; import cascading.operation.xml.XPathOperation; import cascading.pipe.Each; import cascading.pipe.Every; import cascading.pipe.GroupBy; import cascading.pipe.Pipe; import cascading.pipe.SubAssembly; import cascading.scheme.SequenceFile; import cascading.scheme.TextLine; import cascading.tap.Tap; import cascading.tap.Hfs; import cascading.tap.Lfs; import cascading.tuple.Fields; public class WordCount { @SuppressWarnings("serial") private static class ImportCrawlDataAssembly extends SubAssembly { public ImportCrawlDataAssembly( String name ) { //拆分文本行到url和raw RegexSplitter regexSplitter = new RegexSplitter( new Fields( "url", "raw" ) ); Pipe importPipe = new Each( name, new Fields( "line" ), regexSplitter ); //删除所有pdf文档 importPipe = new Each( importPipe, new Fields( "url" ), new RegexFilter( ".*\\.pdf$", true ) ); //把":n1"替换为"\n",丢弃无用的字段 RegexReplace regexReplace = new RegexReplace( new Fields( "page" ), ":nl:", "\n" ); importPipe = new Each( importPipe, new Fields( "raw" ), regexReplace, new Fields( "url", "page" ) ); //此句强制调用 setTails( importPipe ); } } @SuppressWarnings("serial") private static class WordCountSplitAssembly extends SubAssembly { public WordCountSplitAssembly( String sourceName, String sinkUrlName, String sinkWordName ) { //创建一个新的组件,计算所有页面中字数,和一个页面中的字数 Pipe pipe = new Pipe(sourceName); //利用TagSoup将HTML转成XHTML,只保留"url"和"xml"去掉其它多余的 pipe = new Each( pipe, new Fields( "page" ), new TagSoupParser( new Fields( "xml" ) ), new Fields( "url", "xml" ) ); //对"xml"字段运用XPath(XML Path Language)表达式,提取"body"元素 XPathGenerator bodyExtractor = new XPathGenerator( new Fields( "body" ), XPathOperation.NAMESPACE_XHTML, "//xhtml:body" ); pipe = new Each( pipe, new Fields( "xml" ), bodyExtractor, new Fields( "url", "body" ) ); //运用另一个XPath表达式删除所有元素,只保留文本节点,删除在"script"元素中的文本节点 String elementXPath = "//text()[ name(parent::node()) != 'script']"; XPathGenerator elementRemover = new XPathGenerator( new Fields( "words" ), XPathOperation.NAMESPACE_XHTML, elementXPath ); pipe = new Each( pipe, new Fields( "body" ), elementRemover, new Fields( "url", "words" ) ); //用正则表达式将文档打乱成一个个独立的单词,和填充每个单词(新元组)到当前流使用"url"和"word"字段 RegexGenerator wordGenerator = new RegexGenerator( new Fields( "word" ), "(?<!\\pL)(?=\\pL)[^ ]*(?<=\\pL)(?!\\pL)" ); pipe = new Each( pipe, new Fields( "words" ), wordGenerator, new Fields( "url", "word" ) ); //按"url"分组 Pipe urlCountPipe = new GroupBy( sinkUrlName, pipe, new Fields( "url", "word" ) ); urlCountPipe = new Every( urlCountPipe, new Fields( "url", "word" ), new Count(), new Fields( "url", "word", "count" ) ); //按"word"分组 Pipe wordCountPipe = new GroupBy( sinkWordName, pipe, new Fields( "word" ) ); wordCountPipe = new Every( wordCountPipe, new Fields( "word" ), new Count(), new Fields( "word", "count" ) ); //此句强制调用 setTails( urlCountPipe, wordCountPipe ); } } public static void main( String[] args ) { //设置当前工作jar Properties properties = new Properties(); FlowConnector.setApplicationJarClass(properties, WordCount.class); FlowConnector flowConnector = new FlowConnector(properties); /** * 在运行设置的参数里设置如下代码: * 右击Main.java,选择run as>run confugrations>java application>Main>Agruments->Program arguments框内写入如下代码 * E:/workspace/java-eclipse/hadoopApp001/data/url+page_200.txt output local * 分析: * args[0]代表E:/workspace/java-eclipse/hadoopApp001/data/url+page_200.txt,它位于当前应用所在的目录下面,且路径必须是本地文件系统里的路径 * 我的所在目录是E:/workspace/java-eclipse/hadoopApp001/data/url+page_200.txt * 且该路径需要自己创建,url+page.200.txt文件也必须要有,可以在官网下下载 * * args[1]代表output文件夹,第二个参数,它位于分布式文件系统hdfs中 * 我的路径是:hdfs://s104:9000/user/Adminstrator/output,该路径需要自己创建 * 在程序运行成功后,output目录下会自动生成三个文件夹pages,urls,words * 里面分别包含所有的page,所有的url,所有的word * * args[2]代表local,第三个参数,它位于本地文件系统中 * 我的所在目录是E:/workspace/java-eclipse/hadoopApp001/local * 该文件夹不需要自己创建,在程序运行成功后会自动生成在我的上述目录中, * 且在该local文件夹下会自动生成两个文件夹urls和words,里面分别是url个数和word个数 */ String inputPath = args[ 0 ]; String pagesPath = args[ 1 ] + "/pages/"; String urlsPath = args[ 1 ] + "/urls/"; String wordsPath = args[ 1 ] + "/words/"; String localUrlsPath = args[ 2 ] + "/urls/"; String localWordsPath = args[ 2 ] + "/words/"; //初始化Pipe管道处理爬虫数据装配,返回字段url和page Pipe importPipe = new ImportCrawlDataAssembly( "import pipe" ); //创建tap实例 Tap localPagesSource = new Lfs( new TextLine(), inputPath ); Tap importedPages = new Hfs( new SequenceFile( new Fields( "url", "page" ) ), pagesPath ); //链接pipe装配到tap实例 Flow importPagesFlow = flowConnector.connect( "import pages", localPagesSource, importedPages, importPipe ); //拆分之前定义的wordcount管道到新的两个管道url和word // these pipes could be retrieved via the getTails() method and added to new pipe instances SubAssembly wordCountPipe = new WordCountSplitAssembly( "wordcount pipe", "url pipe", "word pipe" ); //创建hadoop SequenceFile文件存储计数后的结果 Tap sinkUrl = new Hfs( new SequenceFile( new Fields( "url", "word", "count" ) ), urlsPath ); Tap sinkWord = new Hfs( new SequenceFile( new Fields( "word", "count" ) ), wordsPath ); //绑定多个pipe和tap,此处指定的是pipe名称 Map<String, Tap> sinks = Cascades.tapsMap( new String[]{"url pipe", "word pipe"}, Tap.taps( sinkUrl, sinkWord ) ); //wordCountPipe指的是一个装配 Flow count = flowConnector.connect( importedPages, sinks, wordCountPipe ); //创建一个装配,导出hadoop sequenceFile 到本地文本文件 Pipe exportPipe = new Each( "export pipe", new Identity() ); Tap localSinkUrl = new Lfs( new TextLine(), localUrlsPath ); Tap localSinkWord = new Lfs( new TextLine(), localWordsPath ); // 使用上面的装配来连接两个sink Flow exportFromUrl = flowConnector.connect( "export url", sinkUrl, localSinkUrl, exportPipe ); Flow exportFromWord = flowConnector.connect( "export word", sinkWord, localSinkWord, exportPipe ); ////装载flow,顺序随意,并执行 Cascade cascade = new CascadeConnector().connect( importPagesFlow, count, exportFromUrl, exportFromWord ); cascade.complete(); } }
运行时的截图如下: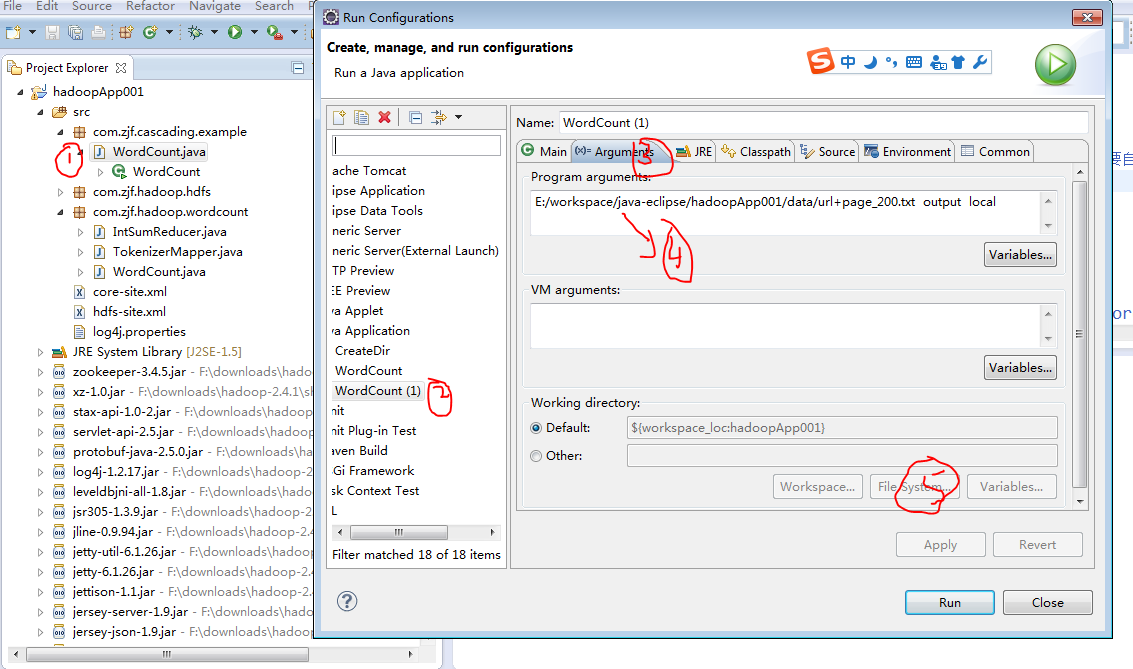
运行完后,在、user/Adminstrator/output/下会多出三个文件夹,在本地的当前应用下会多出一个local的文件夹,这样就运行成功

