

Shell 脚本循环遍历日志文件中的值进行求和并计算平均值,最大值和最小值
本文为博主原创,转载请注明出处:
最近在进行压测,为了观察并定位服务性能的瓶颈,所以在代码中很多地方加了执行耗时的日志,但这种方式只能观察,却在压测的时候,不太能准确的把握代码中某些方法的性能,所以想到写一个脚本,用来统计所加的日志中的平均耗时,最大耗时,最小耗时等等,这需要保证每行日志都是唯一的,代码中添加日志的方式如下:
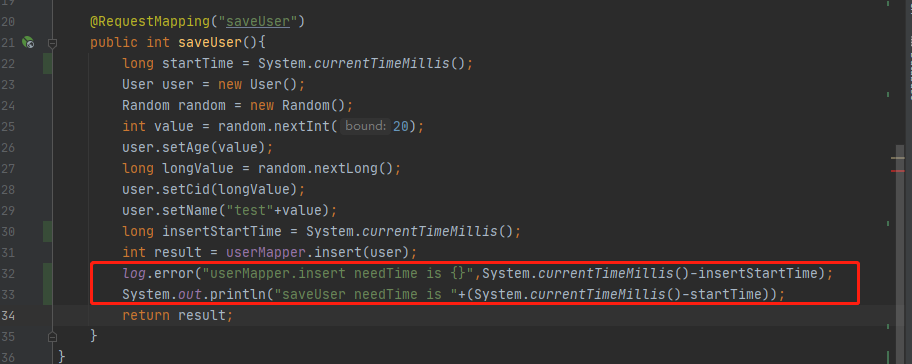
为了便于验证,写了一个简单的日志文件 console.log ,内容如下:

[root@iZ2ze10u5v2hhw1ezi52suZ shell]# cat console.log
filterStr 23
filterStr 56
filterStr 89
filterStr 1
filterStr 10
filterStr 2
requireTime 3
requireTime 4
requireTime 3
requireTime 10
1.先编写一个计算 含 filterStr 日志行的所有平均时间,最大时间,最小时间,脚本示例如下:
#!/bin/bash
sum=0
min=`cat console.log|grep "filterStr"|awk '{print $2}'|head -n 1`
max=0
for value in `cat console.log|grep 'filterStr'|awk '{print $2}'`
do
sum=$(($sum+$value))
if [ $value -le $min ];then
min=$value
fi
if [ $value -ge $max ];then
max=$value
fi
done
echo "总共耗时:"$sum
totalCount=`cat console.log|grep 'filterStr'|awk '{print $2}'|wc -l`
echo "总共请求次数为:"$totalCount
#计算请求的平均时间
avageTime=$(($sum/$totalCount))
echo "平均请求响应时间为: "$avageTime
#打印最大值与最小值
echo "最大值为:"$max
echo "最小值为:"$min
最小值的初始定义命令为: min=`cat console.log|grep "filterStr"|awk '{print $2}'|head -n 1` ; 这行命令过滤出日志的所有行,并取第一行中过滤出的第二个值(awk '{print $2}')。所以需要提前预定好 该耗时计算在日志中的位置,我这边示例中位于第二个位置,所以取第二个$2 的 值
该脚本执行效果如下:

2. 通过动态传参过滤内容的方式执行执行脚本
由于服务中加了很多位于不同代码处的耗时日志,所以想到通过动态传参的方式执行脚本,shell 脚本示例如下:
#!/bin/bash sum=0 min=`cat console.log|grep "$filterStr"|awk '{print $2}'|head -n 1` max=0 filterStr=$1 for value in `cat console.log|grep "$filterStr"|awk '{print $2}'` do sum=$(($sum+$value)) if [ $value -le $min ];then min=$value fi if [ $value -ge $max ];then max=$value fi done echo "总共耗时:"$sum totalCount=`cat console.log|grep "$filterStr"|awk '{print $2}'|wc -l` echo "总共请求行数为:"$totalCount #计算请求的平均时间 avageTime=$(($sum/$totalCount)) echo "平均请求响应时间为: "$avageTime #打印最大值与最小值 echo "最大值为:"$max echo "最小值为:"$min
用该脚本计算 console.log 中的 requireTime 相关行的耗时统计:

标签:
linux


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!