

ES 分词器简单应用
本文为博主原创,未经允许不得转载:
1. ES 分词器
1.1 elasticsearch 默认分词器: standard
standard 分词器会将每个英文单词及每个汉字进行单独拆分进行索引
使用示例:
POST _analyze { "analyzer":"standard", "text":"我爱你中国" }
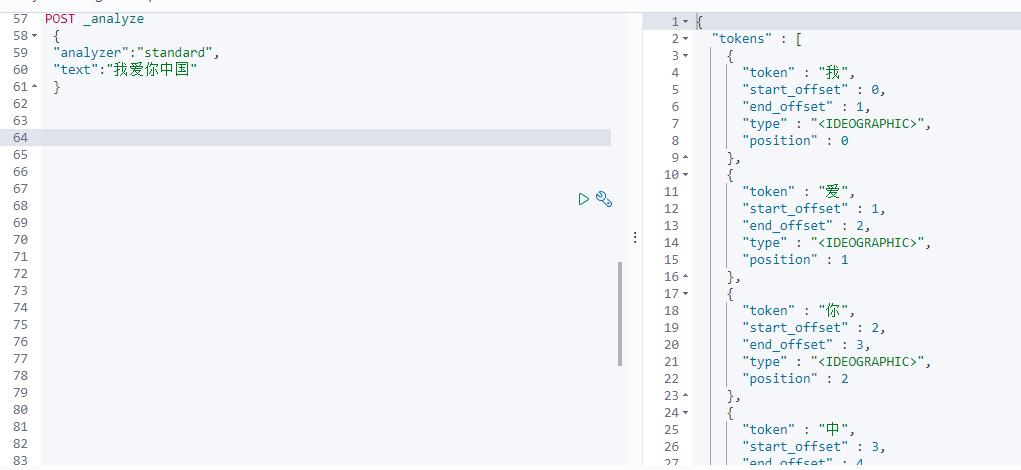
2. ik 中文分词器
ik 中文分词器会根据具体的语义进行拆分,比如南京市,如果使用standard 分词设置,则会形成 南,京, 市三个索引,明显不合理,使用 ik 中文分词器,则会拆分成 南京市进行索引。ik 中文分词器有两种模式: ik_smart和ik_max_word 。 ik_smart 智能化拆分:比如清华大学,则会拆分为 清华大学,而 ik_max_word 则会拆分为清华大学,清华,大学等索引。
POST _analyze { "analyzer": "ik_smart", "text": "江苏省南京市江宁区" } POST _analyze { "analyzer": "ik_smart", "text": "南京市" }
修改索引的默认分词方法:
PUT /test_es_db { "settings" : { "index" : { "analysis.analyzer.default.type": "ik_max_word" } } }

