
Redis 主从复制架构配置及原理
本文为博主原创,未经允许不得转载:
目录:
1. Redis 主从复制架构搭建
2. Redis 主从架构原理
3. Redis 断点续传
4. Jedis 连接
redis 主从架构一般配置一主多从,及读写分离,主负责写,并且将数据复制到其它的 slave 节点,从节点负责读。所有的读请求全部走从节点。这样也可以很轻松实现水平扩容,支撑读高并发。
1. Redis 主从复制架构搭建:
1. 复制一份 redis.conf 配置文件为 redis_slave.conf
2、将相关配置修改为如下值:
port 6380 pidfile /var/run/redis_6380.pid # 把pid进程号写入pidfile配置的文件 logfile "6380.log" dir /usr/local/redis-5.0.3/data/6380 # 指定数据存放目录 # 需要注释掉bind # bind 127.0.0.1(bind绑定的是自己机器网卡的ip,如果有多块网卡可以配多个ip,代表允许客户端通过机器的哪些网卡ip去访问,内网一般可以不配置bind,注释掉即可)
3、配置主从复制
replicaof 192.168.0.60 6379 # 从本机6379的redis实例复制数据
replica-read-only yes # 配置从节点只读
4、启动从节点
redis-server redis_slave.conf
5、连接从节点
redis-cli -p 6380
6、测试在6379实例上写数据,6380实例是否能及时同步新修改数据
7、可以再配置一个6381的从节点测试
2. Redis 主从架构原理
主从架构原理流程图:
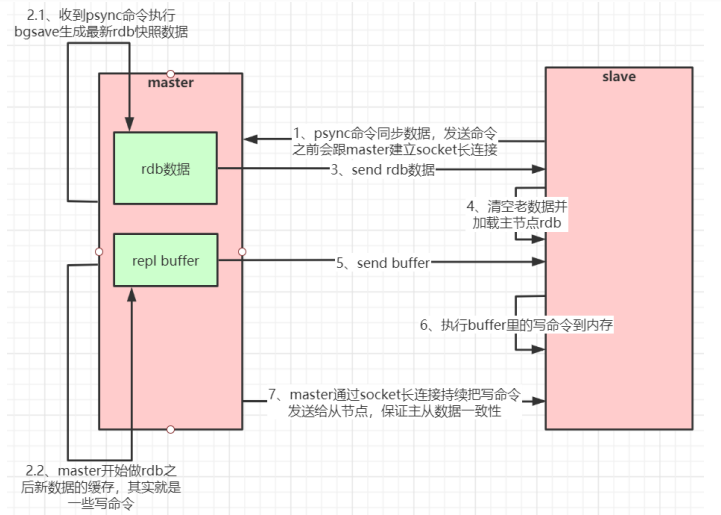
备注:
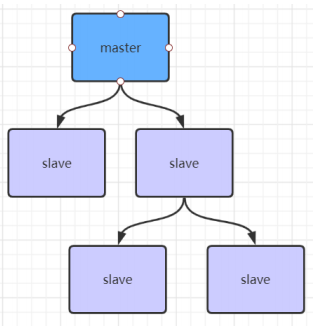
如果主节点有很多从节点,为了缓解主从复制风暴(多个从节点同时复制主节点导致主节点压力过大),可以做成如下架构,让部分从节点与从节点同步数据复制。
3. redis断点续传:
从Redis2.8 开始,就支持主从复制的断点续传,如果主从复制过程中,网络连接断掉了,那么可以接着上次复制的地方,继续复制下去,而不是从头开始复制。master node 会在内存中维护一个 backlog,master 和 slave 都会保存一个 replica offset 还有一个 master run id,offset 就是保存在 backlog 中的。如果 master 和 slave 网络连接断掉了,slave 会让 master 从上次 replica offset 开始继续复制,如果没有找到对应的 offset,那么就会执行一次 resynchronization 。
4. Jedis 连接示例:
1.引入pom 依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
2. 代码连接操作示例
public class JedisSingleTest { public static void main(String[] args) throws IOException { JedisPoolConfig jedisPoolConfig = new JedisPoolConfig(); jedisPoolConfig.setMaxTotal(20); jedisPoolConfig.setMaxIdle(10); jedisPoolConfig.setMinIdle(5); // timeout,这里既是连接超时又是读写超时,从Jedis 2.8开始有区分connectionTimeout和soTimeout的构造函数 JedisPool jedisPool = new JedisPool(jedisPoolConfig, "112.125.26.68", 6379, 3000, null); Jedis jedis = null; try { //从redis连接池里拿出一个连接执行命令 jeis = jedisPool.getResource(); System.out.println(jedis.set("single", "test")); System.out.println(jedis.get("single")); } catch (Exception e) { e.printStackTrace(); } finally { //注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。 if (jedis != null) jedis.close(); } } }

