day20常用模块
一、正则内容的补充
import re # ret = re.findall(r'www\.baidu\.com|www\.oldboy\.com','www.baidu.com') # # ret = re.findall(r'www\.(baidu|oldboy)\.com',r'www.baidu.com') #findall取组内 ['baidu'] # ret = re.findall(r'www\.(?:baidu|oldboy)\.com',r'www.baidu.com') #findall取组所有匹配的 ?:取消分组优先 #分组优先:优先显示括号内部的内容 #取消分组优先 # ret = re.findall(r'(?P<name><\w\d>)(?P<name2>.*?)(?P=name)','<h1>www.baidu.com<h1><h1>www.baidu.com<h1>') # ret2 = re.finditer(r'(?P<name><\w\d>)(?P<name2>.*?)(?P=name) re.S','<h1>www.baidu.com<h1><h1>www.baidu.com<h1>') #爬虫原理 # for i in ret2: # print(i.group('name2')) # flags有很多可选值: # # re.I(IGNORECASE) # 忽略大小写,括号内是完整的写法 # re.M(MULTILINE) # 多行模式,改变 ^ 和$的行为 # re.S(DOTALL) # 点可以匹配任意字符,包括换行符 # re.L(LOCALE) # 做本地化识别的匹配,表示特殊字符集 \w, \W, \b, \B, \s, \S # 依赖于当前环境,不推荐使用 # re.U(UNICODE) # 使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flag # re.X(VERBOSE) # 冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释 # print(ret) # ret = re.search(r'www\.(?P<web_name>baidu|oldboy)\.com',r'www.baidu.com').group('web_name') #search取组内 # ret = re.search(r'www\.(?P<web_name>baidu|oldboy)\.com',r'www.baidu.com').group() #search取全组 # print(ret) # ret=re.split("\d+","eva3egon4yuan") # print(ret) #结果 : ['eva', 'egon', 'yuan'] # ret=re.split("(a+)","eva3egon4yuan") # print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan'] # ret = re.search("<\w+>\w+</\w+>","<h1>hello</h1>") # ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>") # print(ret.group('tag_name')) #结果 :h1 # print(ret.group()) #结果 :<h1>hello</h1> #分组的命名和组的引用 # ret = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1><h1>hello</h1>") # print(ret.group(1)) # ret = re.finditer(r"<(\w+)>\w+</\1><(span)>\w+</\2>","<h1>hello</h1><span>hello</span>") # for i in ret: # print(i.group(1)) # print(i.group(2)) # h1 # span #如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致 !!!! #获取的匹配结果可以直接用group(序号)拿到对应的值 !!!! # print(ret.group()) #结果 :<h1>hello</h1> # ret = re.findall(r"<(\w+)>\w+</\1>","<h1>hello</h1>") # print(ret) ret=re.findall(r"\d+","1-2*(60+(-40.35/5)-(-4*3))") print(ret) # 40.35 缺点是里边会有小数的整数部分和小数部分也会计算进去 #\d+\.\d+|\d+ [^] # 使用优先级的原理来排除小数 ret=re.findall(r"\d+\.\d+|(\d+)","1-2*(60+(-40.35/5)-(-4*3))") print(ret) ret.remove('') # ret=re.findall(r"\d+\.\d+|(\d+)","1-2*(60+(-40.35/5)-(-4*3))") # print(ret) # ret.remove('') # print(ret)
collections 模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。 1.namedtuple: 生成可以使用名字来访问元素内容的tuple 2.deque: 双端队列,可以快速的从另外一侧追加和推出对象 3.Counter: 计数器,主要用来计数 4.OrderedDict: 有序字典 5.defaultdict: 带有默认值的字典


# print(r'\n') #表示取消字符串内所有转译符的转译作用 real # print('\n') #'\'转译符,n,加上转译符 \n --> 换行了 # print('\\n') #'\'转译符,n,加上转译符 \n --> 换行了 # #结论就是:在工具里什么样,挪到python里加个r # from collections import Iterator #迭代器 # from collections import Iterable #可迭代对象 from collections import namedtuple # point1 = (1,1) # x = point1[0] # y = point1[1] # P = namedtuple('Point',['x','y']) # p1 = P(1,2) # p2 = P(3,4) # print(p1.x) # print(p1.y) # print(p2.x) # print(p2.y) # yuan = namedtuple('yuan',['x','y','z']) # p = yuan(2,0,4) # print(p.x,type(p.x)) # # 描述一类东西的时候,这一类东西都有相同的特征。 # 想直接用特征的名字就描述这个值的时候,就可以用可命名元祖 # 面向对象的时候还会再讲 # 生日:年月日 (2011,11,11) #练习 #队列 # import queue #队列_多线程多进程 # a = queue.Queue() # a.put(1) # a.put(2) # a.put(3) # print(a.qsize()) # a.get() # a.get() # a.get() # a.get() # q = queue.Queue() # q.put([1]) # q.put(2) #处理任务 # q.put(300) # q.put('aaa') # q.put('wahaha') # # print(q.qsize()) # print(q.get()) # print(q.get()) # print(q.get()) # print(q.get()) # print(q.get()) #hold住的功能 # print(q.qsize()) # print(q.get_nowait()) #如果没有不会hold住,且会报错 # from collections import deque # dq = deque() # dq.append('a') # dq.append('b') # dq.append('c') # dq.append('d') # dq.append('e') # print(dq) # dq.appendleft('y') # dq.append('y') # dq.appendleft('c') # print(dq.popleft()) from collections import OrderedDict od = OrderedDict([('a', [1,2,3,4]), ('b', 2), ('c', 3)]) # for k in od: # print(k,od[k]) print(od) for i in enumerate(od): print(i) # l = [11,22,33,44,55,66,77,88,99,90] # dic = {} # for i in l: # if i > 66: # if 'k1' in dic: # dic['k1'].append(i) # else: # dic['k1'] = [] # dic['k1'].append(i) from collections import defaultdict def func(): return 0 my_dict = defaultdict(func) # my_dict = {} print(my_dict['k'])
Counter Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。 c = Counter('abcdeabcdabcaba') print c 输出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
Eva_J * 博客园 * 首页 * 联系 * 管理 随笔- 29 文章- 61 评论- 63 collections模块—— Counter Counter目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。 创建 下面的代码说明了Counter类创建的四种方法: Counter类的创建 >>> c = Counter() # 创建一个空的Counter类 >>> c = Counter('gallahad') # 从一个可iterable对象(list、tuple、dict、字符串等)创建 >>> c = Counter({'a': 4, 'b': 2}) # 从一个字典对象创建 >>> c = Counter(a=4, b=2) # 从一组键值对创建 计数值的访问与缺失的键 当所访问的键不存在时,返回0,而不是KeyError;否则返回它的计数。 计数值的访问 >>> c = Counter("abcdefgab") >>> c["a"] 2 >>> c["c"] 1 >>> c["h"] 0 计数器的更新(update和subtract) 可以使用一个iterable对象或者另一个Counter对象来更新键值。 计数器的更新包括增加和减少两种。其中,增加使用update()方法: 计数器的更新(update) >>> c = Counter('which') >>> c.update('witch') # 使用另一个iterable对象更新 >>> c['h'] 3 >>> d = Counter('watch') >>> c.update(d) # 使用另一个Counter对象更新 >>> c['h'] 4 减少则使用subtract()方法: 计数器的更新(subtract) >>> c = Counter('which') >>> c.subtract('witch') # 使用另一个iterable对象更新 >>> c['h'] 1 >>> d = Counter('watch') >>> c.subtract(d) # 使用另一个Counter对象更新 >>> c['a'] -1 键的修改和删除 当计数值为0时,并不意味着元素被删除,删除元素应当使用del。 键的删除 >>> c = Counter("abcdcba") >>> c Counter({'a': 2, 'c': 2, 'b': 2, 'd': 1}) >>> c["b"] = 0 >>> c Counter({'a': 2, 'c': 2, 'd': 1, 'b': 0}) >>> del c["a"] >>> c Counter({'c': 2, 'b': 2, 'd': 1}) elements() 返回一个迭代器。元素被重复了多少次,在该迭代器中就包含多少个该元素。元素排列无确定顺序,个数小于1的元素不被包含。 elements()方法 >>> c = Counter(a=4, b=2, c=0, d=-2) >>> list(c.elements()) ['a', 'a', 'a', 'a', 'b', 'b'] most_common([n]) 返回一个TopN列表。如果n没有被指定,则返回所有元素。当多个元素计数值相同时,排列是无确定顺序的。 most_common()方法 >>> c = Counter('abracadabra') >>> c.most_common() [('a', 5), ('r', 2), ('b', 2), ('c', 1), ('d', 1)] >>> c.most_common(3) [('a', 5), ('r', 2), ('b', 2)] 浅拷贝copy 浅拷贝copy >>> c = Counter("abcdcba") >>> c Counter({'a': 2, 'c': 2, 'b': 2, 'd': 1}) >>> d = c.copy() >>> d Counter({'a': 2, 'c': 2, 'b': 2, 'd': 1}) 算术和集合操作 +、-、&、|操作也可以用于Counter。其中&和|操作分别返回两个Counter对象各元素的最小值和最大值。需要注意的是,得到的Counter对象将删除小于1的元素。 Counter对象的算术和集合操作 >>> c = Counter(a=3, b=1) >>> d = Counter(a=1, b=2) >>> c + d # c[x] + d[x] Counter({'a': 4, 'b': 3}) >>> c - d # subtract(只保留正数计数的元素) Counter({'a': 2}) >>> c & d # 交集: min(c[x], d[x]) Counter({'a': 1, 'b': 1}) >>> c | d # 并集: max(c[x], d[x]) Counter({'a': 3, 'b': 2}) 其他常用操作 下面是一些Counter类的常用操作,来源于Python官方文档 Counter类常用操作 sum(c.values()) # 所有计数的总数 c.clear() # 重置Counter对象,注意不是删除 list(c) # 将c中的键转为列表 set(c) # 将c中的键转为set dict(c) # 将c中的键值对转为字典 c.items() # 转为(elem, cnt)格式的列表 Counter(dict(list_of_pairs)) # 从(elem, cnt)格式的列表转换为Counter类对象 c.most_common()[:-n:-1] # 取出计数最少的n个元素 c += Counter() # 移除0和负值
时间模块
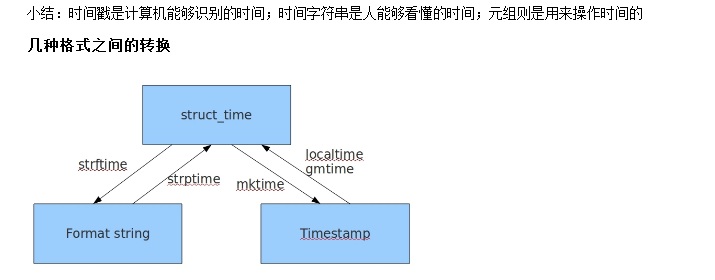
在Python中,通常有这三种方式来表示时间:时间戳、元组(struct_time)、格式化的时间字符串:
(1)时间戳(timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
(2)格式化的时间字符串(Format String): ‘1999-12-06’
%y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地简化星期名称 %A 本地完整星期名称 %b 本地简化的月份名称 %B 本地完整的月份名称 %c 本地相应的日期表示和时间表示 %j 年内的一天(001-366) %p 本地A.M.或P.M.的等价符 %U 一年中的星期数(00-53)星期天为星期的开始 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %% %号本身 python中时间日期格式化符号:
#结构化时间 --> %a %b %d %H:%M:%S %Y串 #time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串 >>>time.asctime(time.localtime(1500000000)) 'Fri Jul 14 10:40:00 2017' >>>time.asctime() 'Mon Jul 24 15:18:33 2017' #%a %d %d %H:%M:%S %Y串 --> 结构化时间 #time.ctime(时间戳) 如果不传参数,直接返回当前时间的格式化串 >>>time.ctime() 'Mon Jul 24 15:19:07 2017' >>>time.ctime(1500000000) 'Fri Jul 14 10:40:00 2017'
import time true_time=time.mktime(time.strptime('2017-09-11 08:30:00','%Y-%m-%d %H:%M:%S')) time_now=time.mktime(time.strptime('2017-09-12 11:00:00','%Y-%m-%d %H:%M:%S')) dif_time=time_now-true_time struct_time=time.gmtime(dif_time) print('过去了%d年%d月%d天%d小时%d分钟%d秒'%(struct_time.tm_year-1970,struct_time.tm_mon-1, struct_time.tm_mday-1,struct_time.tm_hour, struct_time.tm_min,struct_time.tm_sec))
sys 模块
sys模块是与python解释器交互的一个接口
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1) sys.version 获取Python解释程序的版本信息 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称
import sys # print(sys.platform) # print(sys.version) # sys.exit(0) # sys.exit(1) # print(sys.path) # 就是模块导入的时候从这个列表中的路径依次去寻找模块 # 找到了就停止 # sys.path的第一位元素是当前被执行的python文件所在的地址 # 之后的地址依次是python内部的库 print(sys.argv) #python 6sys.py #python 6sys.py alex 3714 # args_lst = sys.argv #['6sys.py', 'alex', '3714'] # if len(args_lst) ==3 and args_lst[1] == 'alex' and args_lst[2] == '3714': # print('执行程序了') # else: # sys.exit() #sys.argv的第一个值是固定的的,就是这个文件的名字 #之后的参数 是在控制台执行py文件的时候传入的参数 python 6sys.py alex 3714 #我们可以用这些参数来直接完成一些校验类的工作 a = sys.argv if a[1] == 'zjc'and a[2] =='123': print('开始执行') else: sys.exit(0)
