作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3363
Hadoop综合大作业
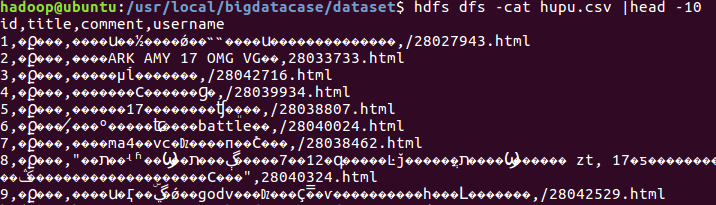
1.将爬虫大作业产生的csv文件
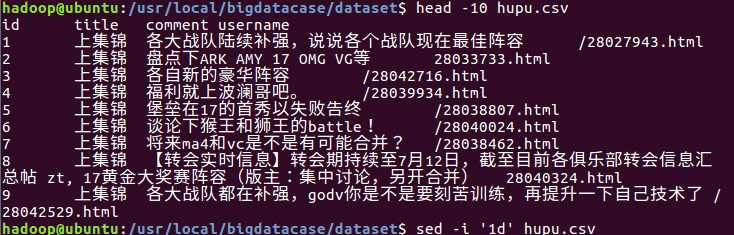
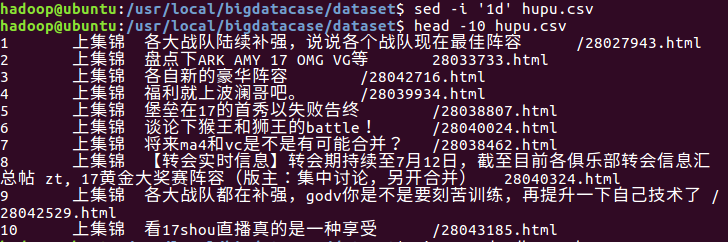
2.对CSV文件进行预处理生成无标题文本文件
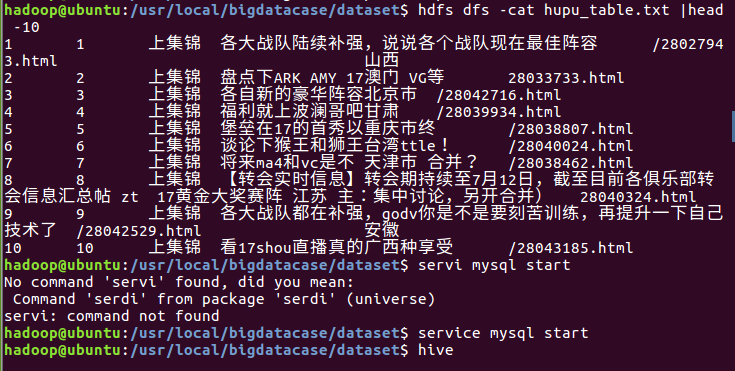
3.把上传到hdfs中的文本文件最终导入到数据仓库Hive中
4.在Hive中查看并分析数据

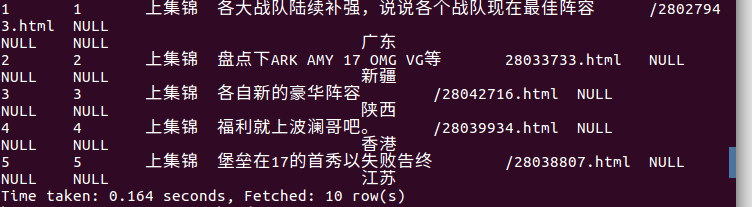
5.用Hive对爬虫大作业产生的进行数据分析,写一篇博客描述你的分析过程和分析结果。(10条以上的查询分析)
(1)查询数据的总数

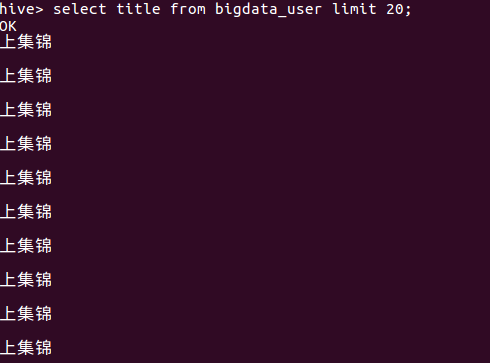
(2)查询前十的标题:
(3)查询前20条用户评论:

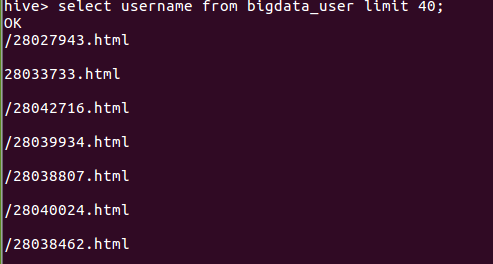
(4)查询前20条用户名:
(5)查询前20的发布省份:(自己添加的)
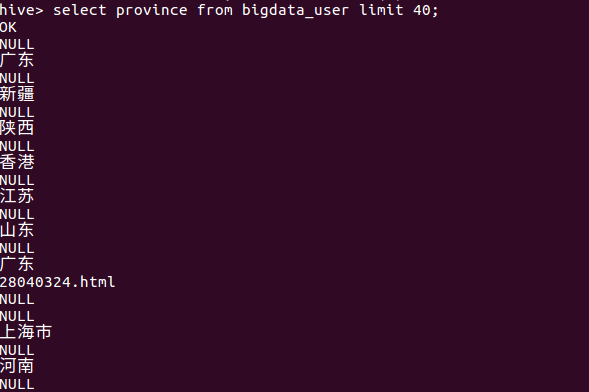
分析:从查询结果可知,其实大部分的内容都是围绕着同一个主题发展,各自的粉丝为各自而战。
总结:在导入这个csv文件和查看过程中是不会出现每一条数据间有空行现象的,但是导入hdfs后就出现了一个null,我觉得应该是数据存储上出了bug,但是不知道怎么用命令行修改,所以就这样了。
这次分析是基于爬取虎扑社区绝地求生吧的信息,经过预处理上传到hdfs,再用hive导入到数据库,最后进行查询分析。遇到的问题为在csv导入到虚拟机时查看数据出现过乱码现象,我把传入的文件弄成txt格式,改编码为utf-8再进行转存为csv文件,上传到虚拟机就无误了。
错误截图: