谱减法(二)使用自适应增益的谱减法
- 原书:语音增强--理论与实践
前言
谱减法中导致音乐噪声(信号帧频谱的随机位置上出现小的,独立的峰值,称为音乐噪声)的两个因素在于:(1)谱估计的大范围变化、(2)增益函数的不同。
为了解决第一个问题,Gustafsson 等人【5】建议将目前的分析帧分为更小的子帧以得到更低分辨率的频谱。子帧频谱通过连续平均以减小频谱的波动。
为了解决第二个问题,Gustafsson 等人【5】提出可以通过使用自适应指数平均,在时间上对增益函数做平滑。此外,为了避免因使用零相位增益函数导致的非因果滤波问题,Gustafsson 等人建议在增益函数中引入线性相位。这样谱减算法可以将总体的处理时延减小到分析帧时长的几分之一。
算法原理
自适应增益平均的谱减算法结构如下图所示:
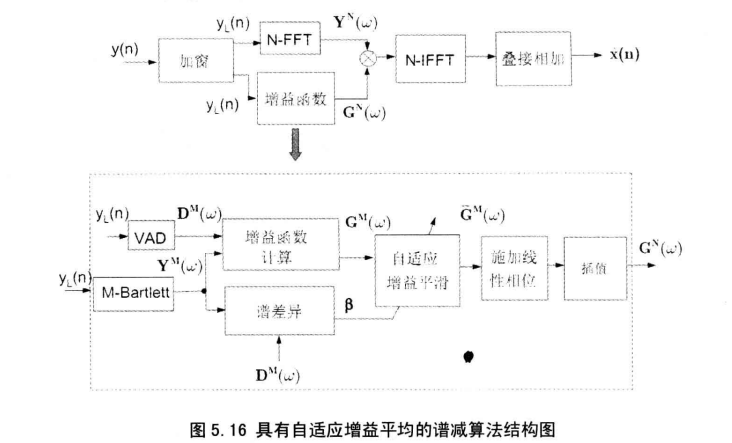
输入信号被划分为样本长度为 \(L\) 的帧,然后进一步划分为样本长度为 \(M(M<L)\) 的的子帧。每个子帧所计算得到的频谱通过计算平均已得到较小波动的幅度谱估计,表示为 \(\lvert \bar{Y}_i^{(M)}(\omega) \rvert\) (即经过图中 M-Bartlett),其上标 \(M\) 表示频谱分量的数量(例如FFT的长度),下标 \(i\) 表示帧号。由 \(\bar{Y}_i^{(M)}(\omega)\) 可以得到具有较低分辨率的增益函数形式如下:
其中 \(k\) 为减法因子(【5】中 \(k=0.7\)),\(\lvert \hat{D}_i^{(M)}(\omega) \rvert\) 通过无语音段所估计得到的噪声幅度谱。为了减小增益函数的波动,\(G_i^{(M)}(\omega)\) 按照下式做时间平均:
其中 \(\bar{G}_i^{(M)}(\omega)\) 表示平滑后的第 \(i\) 帧增益函数,\(a_i\) 是自适应平滑参数。自适应平滑参数 \(a_i\) 通过自谱差异测度 \(\beta_i\) 推导:
以上差异测度可以粗略评估信号谱相对于背景噪声的变化。较小的差异值表示相对平稳的背景环境噪声,大的差异值则表示有语音存在或者背景噪声正迅速变化。通过 \(\beta_i\) 计算得到 自适应平滑参数 \(a_i\):
其中 \(\gamma\) 是平滑参数(【5】中 \(\gamma = 0.8\))。自适应参数 \(a_i\) 可以被快速见效,这样就可以使增益函数快速适应于新的输入信号,但是\(a_i\) 只能较慢的增加。
上述求完平滑后的增益函数之后,线性相位将被施加于增益函数以产生一个因果滤波器。这样将导致一个具有如下时域对称性的滤波器:
其中 \(g_M(n)\) 表示增益函数 \(\bar{G}_i^{M}(\omega)\) 的逆傅里叶变换。得到的滤波器延迟为 \((M-1)/2\) ,其为原来帧长 \((L)\) 的一小部分。
最后,在对增益函数应用了线性相位之后, \(\bar{G}_i^{(M)}(\omega)\) 通过插值从 \(M\) 点的函数得到一个 \(N\) 点的函数,\(N\) 为FFT长度。注意 \(N\) 的选择需要满足 \(N > L + M\),以避免圆周卷积效应。对下式进行逆傅里叶变换可以得到输出信号:
其中 \(\hat{X}_i^{(N)}(\omega)\) 为增强后的复数谱, \(\bar{G}_i^{(N)}(\omega)\) 为 \(N\) 点插值增益函数(目前为复数值),\(Y_i^{(N)}(\omega)\) 为带噪语音的复数谱,通过对 \(L\) 个样本的输入信号补零后计算得到。注意对上式中 \(\hat{X}_i^{(N)}(\omega)\) 进行逆傅里叶变换会得到增益函数 \(g_M(n)\) 与带噪信号 \(y(n), n=0,1,...,L-1\) 的线性卷积。
在文献【5】,以下参数被证明对以8kHz采样的语音具有较好的性能: \(L=160, M=32, N=256\)
matlab实现
点击查看代码
function ss_rdc( filename,outfile)
% 自适应增益平均谱减法
% Implements the spectral subtraction algorithm with reduced-delay
% convolution and adaptive averaging [1].
%
% Usage: mband(infile, outputfile,Nband,Freq_spacing)
%
% infile - noisy speech file in .wav format
% outputFile - enhanced output file in .wav format
% Nband - Number of frequency bands (recommended 4-8)
% Freq_spacing - Type of frequency spacing for the bands, choices:
% 'linear', 'log' and 'mel'
%
% Example call: ss_rdc('sp04_babble_sn10.wav','out_rdc.wav');
%
% References:
% [1] Gustafsson, H., Nordholm, S., and Claesson, I. (2001). Spectral sub-
% traction using reduced delay convolution and adaptive averaging. IEEE
% Trans. on Speech and Audio Processing, 9(8), 799-807.
%
% Authors: Yi Hu and Philipos C. Loizou
%
% Copyright (c) 2006 by Philipos C. Loizou
% $Revision: 0.0 $ $Date: 10/09/2006 $
%-------------------------------------------------------------------------
if nargin<2
fprintf('Usage: ss_rdc noisyfile.wav outFile.wav \n\n');
return;
end
[noisy_speech, fs]= audioread( filename);
ainfo=audioinfo(filename);
nbits=ainfo.BitsPerSample;
noisy_speech= noisy_speech'; % change to row vector
if fs== 8000
L= 160; M= 32; N= 256;
elseif fs== 16000
L= 320; M= 64; N= 512;
else
exit( 'incorrect sampling rate!\n');
end
% set parameter values
mu= 0.98; % smoothing factor in noise spectrum update
a= 0.98; % smoothing factor in priori update
eta= 0.15; % VAD threshold
gamma_c= 0.8; % smoothing factor in G_M update
beta= 0.7; % oversubtraction factor
k= L/ M; % number of segments of M
hann_win= hamming( L); % hanning window
hann_win= hann_win'; % change to row vector
% first 120 ms is noise only
len_120ms= fs/ 1000* 120;
% first_120ms= noisy_speech( 1: len_120ms).* ...
% (hann( len_120ms, 'periodic'))';
first_120ms= noisy_speech( 1: len_120ms);
nsubframes= len_120ms/ M; % L is 20ms
% now use Bartlett method to estimate power spectrum
noise_ps= zeros( 1, M);
for j= 1: nsubframes
noise= first_120ms( (j- 1)* M+ 1: j* M);
noise_fft= fft( noise, M);
noise_ps= noise_ps+ ( abs( noise_fft).^ 2)/ M;
end
noise_ps= noise_ps/ nsubframes;
P_w= sqrt( noise_ps);
% plot( P_w);
% number of noisy speech frames
nframes= floor( length( noisy_speech)/ L); % noisy_speech( nframes* L)= 0;
enhanced_speech= zeros( 1, (nframes- 1)* L+ N);
for j= 1: nframes
%noisy= noisy_speech( (j-1)* L+ 1: j* L).* hann_win;
noisy= noisy_speech( (j-1)* L+ 1: j* L);
x_ps= zeros( 1, M);
for n= 1: k
x= noisy( (n-1)* M+ 1: n* M);
x_fft= fft( x, M);
x_ps= x_ps+ (abs( x_fft).^ 2)/ M;
end
x_ps= x_ps/ k;
P_x= sqrt( x_ps); % magnitude spectrum for noisy
% voice activity detection
if (j== 1) % initialize posteri
posteri= (P_x.^ 2)./ (P_w.^ 2);
posteri_prime= posteri- 1;
posteri_prime( find( posteri_prime< 0))= 0;
priori= a+ (1-a)* posteri_prime;
else
posteri_old= posteri;
posteri= (P_x.^ 2)./ (P_w.^ 2);;
posteri_prime= posteri- 1;
posteri_prime( find( posteri_prime< 0))= 0;
priori= a* (G_M2.^ 2).* posteri_old+ (1-a)* posteri_prime;
end
log_sigma_k= posteri.* priori./ (1+ priori)- log(1+ priori);
vad_decision(j)= sum( log_sigma_k)/ M;
if (vad_decision(j)< eta) % noise only frame found
P_w= mu* P_w+ (1- mu)* P_x;
vad( (j-1)*L+1: j*L)= 0;
else
vad( (j-1)*L+1: j*L)= 1;
end
% ===end of vad===
G_M= 1- beta* (P_w./ P_x); % gain function
G_M( find( G_M< 0))= 0;
% spectrum discrepancy
beta_i= min( 1, sum( abs( P_x- P_w))/ sum( P_w));
alpha_1= 1- beta_i;
if (j== 1) % initialize alpha_2
alpha_2= alpha_1;
end
if (alpha_2< alpha_1)
alpha_2= gamma_c* alpha_2+ (1- gamma_c)* alpha_1;
else
alpha_2= alpha_1;
end
if (j== 1)
G_M2= (1- alpha_2)* G_M;
else
G_M2= alpha_2* G_M2+ (1- alpha_2)* G_M;
end
% impulse response of G_M2
G_M2_ir= firls(M, (0: M-1)/M, G_M2);
G_M2_intpl= fft( G_M2_ir, N);
noisy_freq= fft( noisy, N);
enhanced= ifft( noisy_freq.* G_M2_intpl, N);
if (j== 1)
enhanced_speech( 1: N)= enhanced;
else
overlap= enhanced( 1: N- L)+ enhanced_speech( (j-1)* ...
L+ 1: (j-1)*L+ N- L);
enhanced_speech( (j-1)*L+ 1: (j-1)*L+ N- L)= overlap;
enhanced_speech( (j-1)*L+ N- L+ 1: (j-1)*L+ N)= ...
enhanced( N- L+ 1: N);
end
end
audiowrite( outfile, enhanced_speech, fs);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号