语音端点检测(Voice Activity Detection,VAD)
原书:《语音信号处理》
0、前言
语音端点检测(VAD)是指从一端语音信号中准确地找出语音信号的起始点和结束点,其常用于语音编/解码、降噪、增益控制、波束形成以及唤醒识别等算法发中。VAD 方法通常包括 特征提取 和 语音/非语音判决 两部分,
目前使用的语音特征主要有时域和频域两种,时域特征包括能量波动、过零率、最大能量和最小能量等,频域特征主要有基频、频谱组成、频谱质心、谱差、普衰减等。用于VAD判决的特征通常分为六大类:(1)能量、(2)频域、(3)倒谱、(4)谱差、(5)谐波、(6)长时信息。基于能量的特征计算简单,如能量过零率,基于谱(频谱、倒谱和谱差)在低SNR可以获得较好的效果,当SNR为0dB时,基于语音谐波和长时语音特征判决方法的鲁棒性更强。
当前的判决准则可以分为三类:(1)基于门限(基于阈值)、(2)基于统计模型 和 (3)基于深度学习。很多开源的语音算法都有基于统计模型的判决方法,如 WebRTC 和 Speex 中基于高斯混合模型的 VAD检测方法,这类检测方法对信噪比较高的音源检测效果良好。
1、基于门限法进行端点检测
- 基于门限(基于阈值):该方法根据语音信号和噪声信号的不同特征,提取每一段语音信号的特征,然后把这些特征值与设定的阈值进行比较,从而道道语音端点检测的目的。
1.1 双门限法
传统的短时能量和短时过零率相结合的语音端点检测算法:利用短时过零率来检测清音,用短时能量来检测浊音,两者相配合便实现了信号信噪比较大情况下的端点检测。算法以短时能量检测为主,短时过零率检测为辅。
根据语音的特性,可以把语音段分为清音、浊音以及静音(包括背景噪声)三种。

双门限法端点检测的二级判决示意图
(1)短时能量
设第n帧语音信号 \(x_n(m)\) 的短时能量用 \(E_n\) 表示,则其计算公式如下:
\(E_n\) 是一个度量语音信号幅度值变化的函数,但它有一个缺陷,即它对高电平非常敏感(因为它计算时用的是信号的平方)。
(2)短时过零率
短时过零率表示一帧语音中语音信号波形穿过横轴(零电平)的次数。对于连续语音信号,过零即意味着时域波形通过时间轴;而对离散信号,如果相邻的取样值改变符号则称为过零。因此,过零率就是样本改变符号的次数。
定义语音信号 \(x_n(m)\) 的短时过零率 \(Z_n\) 为:
式子中,\(sgn[...]\) 是符号函数,即
(3)双门限法
在双门限算法中,短时能量检测可以较好地区分出 浊音和静音。对于清音,由于其能量较小,在短时能量检测中会因为低于能量门限而被误判为静音;短时过零率则可以从语音中区分出 静音和清音。将两种检测结合起来,就可以检测出语音段(清音和浊音)及静音段。
在基于短时能量和过零率的双门限端点检测算法中首先为短时能量和过零率分别确定两个门限,一个为较低的门限,对信号的变化比较敏感;另一个是较高的门限。当低门限被超过时,很有可能是由于很小的噪声引起的,未必是语音的开始,当高门限被超过并且接下来的时间段内一直超过低门限时,则意味着语音段的开始。
双门限法进行端点检测步骤如下:
- 计算信号的短时能量和短时过零率。‘
- 根据语音能量的轮廓选取一个较高的门限 \(T_2\) ,语音信号的能量包络大部分都在此门限之上,这样可以进行一次初判。语音起止点位于该门限与短时能量包络交点 \(N_3\) 和 \(N_4\) 所对应的时间间隔之外。
- 根据背景噪声的能量确定一个较低的门限 \(T_1\) ,并从初判起点往左,从初判终点往右搜索,分别找到 能零比曲线 第一次与门限 \(T_1\) 相交的两个点 \(N_2\) 和 \(N_5\) ,于是 \(N_2 N_5\) 段就是用门限方法所判定的语音段。
- 以短时平均过零率为准,从 \(N_2\) 点往左 和 \(N_5\) 往右搜索,找到短时平均过零率低于某个阈值 \(T_3\) 的两个点 \(N_1\) 和 \(N_6\) ,这便是语音段的起止点。
注意:门限值要通过多次实验来确定,门限都是由背景噪声特性确定的。语音起始段的复杂度特征与结束时的有差异,起始时幅度变化比较大;结束时,幅度变化比较缓慢。在进行起止点判决前,通常都要采集若干帧背景噪声并计算其短时能量和短时平均过零率,作为选择 \(T_1\) 和 \(T_3\) 的依据。
1.2 自相关法
(1)短时自相关
自相关函数具有一些性质,如它是偶函数;假设序列具有周期性,则其自相关函数也是同周期的周期函数等。对于浊音语音可以用自相关函数求出语音波形序列的基音周期。此外,在语音信号的线性预测分析时,也要用到自相关函数。
式中,\(K\) 是最大的延迟点数。
为了避免语音端点检测过程中收到绝对能量带来的影响,把自相关函数进行归一化处理,即用 \(R_n(0)\) 进行归一化,得到
(2)自相关函数最大值法
噪声信号和含噪语音信号的自相关函数存在极大的差异,因此可以利用这种差别来提取语音端点。
根据噪声情况,设置连个阈值 \(T_1\) 和 \(T_2\) ,当相关函数最大值大于 \(T_2\) 时,便判定是语音;当相关函数最大值大于或小于 \(T_1\) 时,则判定为语音信号的端点。
1.3 谱熵法
(1)所谓熵就是表示信息的有序程度。在信息论中,熵描述了随机事件结局的不确定性,即一个信息源发出的信号以信息熵来作为信息选择和不确定性的度量,是由 Shannon 引用到信息理论中来的。1998年,Shne JL 首次提出基于熵的语音端点检测算法,Shne 在实验中发现语音的熵和噪声的熵存在较大的差异,谱熵这一特征具有一定的可选性,它体现了语音和噪声在整个信号段中的分布概率。
谱熵语音端点检测方法是通过检测谱的平坦程度,从而达到语音端点检测的目的,经实验研究可知谱熵具有如下特征:
- 语音信号的谱熵不同于噪声信号的谱熵。
- 理论上,如果谱的分布保持不变,语音信号幅值的大小不会影响归一化。但实际上,语音谱熵随语音随机性而变化,与能量特征相比,谱熵的变化是很小的。
- 在某种程度上讲,谱熵对噪声具有一定的稳健性,相同的语音信号当信噪比较低时,语音信号的谱熵值的形状大体保持不变,这说明谱熵是一个比较稳健型的特征参数。
- 语音谱熵只与语音信号的随机性有关,而与语音信号的幅度无关,理论上认为只要语音信号的分布不发生变化,那么语音谱熵不会受到语音幅度的影响。另外,由于每个频率分量在求其概率密度函数的时候都经过了归一化处理,所以从这一方面也证明了语音信号的谱熵只会与语音分布有关,而不会与幅度大小有关。
(2)谱熵的定义
设语音信号的时域波形为 \(x(i)\) ,加窗分帧处理后得到的第 \(n\) 帧语音信号为 \(x_n(m)\) ,其 FFT 表示为 \(X_n(k)\) ,其中下标 \(n\) 表示为第 \(n\) 帧,而 \(k\) 表示为第 \(k\) 条谱线。该语音帧在频域中的短时能量为
式中,\(N\) 为 FFT 的长度,只取正频率部分。
而对于某一谱线 \(k\) 的能量谱为 \(Y_n(k) = X_n(k)X_n^{\ast}(k)\) ,则每个频率分量的归一化谱概率密度函数定义为
该语音帧的 短时谱熵 定义为:
(3)基于谱熵的端点检测
由于谱熵语音端点检测方法是通过检测谱的平坦程度,来进行语音端点检测的,为了更好地进行语音端点检测,本文采用语音信号的短时功率谱构造语音信息的谱熵,从而更好地对语音段和噪声段进行区分。
其大概检测思路如下:
- 首先对语音信号进行加窗分帧、取 FFT 的点数。
- 计算出每一帧的谱的能量。
- 计算出每一帧中每个样本点的概率密度函数。
- 计算出每一帧的谱熵值。
- 设置判断门限。
- 根据各帧的谱熵值进行端点检测。
每一帧的谱熵值采用如下公式进行计算:
\(H(i)\) 是第 \(i\) 帧的谱熵,\(H(i)\) 计算是基于谱的能量变化而不是谱的能量,所以在不同水平噪声环境下谱熵参数具有一定稳健性,但每一谱点的幅值易受噪声的污染进而影响端点检测的稳健性。
1.4 比例法
(1)能零比的端点检测
在噪声情况下,信号的短时能量和短时过零率会发生一定变化,严重时会影响端点检测性能。下图5-4是含噪情况下的短时能量和短时过零率显示图。
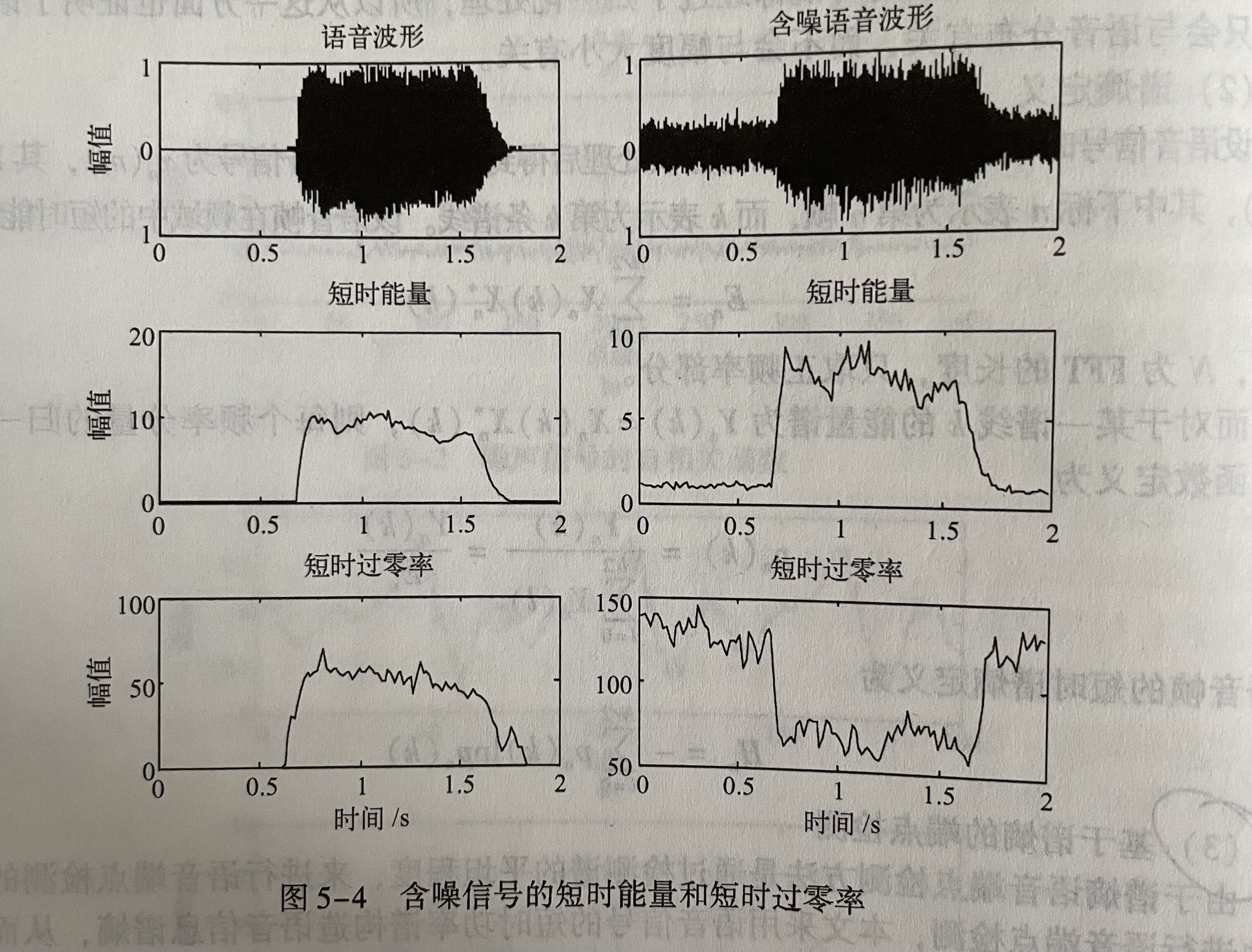
从图中可知,在语音中的说话区间 能量是向上凸起的,而过零率相反,在说话期间向下凹陷。这表明,说话区间能量的数值大,而过零率数值小;在噪声区间能量数值小,而过零率数值大。所以把能量值除以过零率的值,则可以更突出说话区间,从而更容易检测出语音端点。
设第n帧语音信号 \(x_n(m)\) 的短时能量用 \(E_n\) 表示,则其计算公式如下:
改进能量表示为:
式子中, \(a\) 为常数,适当的数值有助于区分噪声和清音。
过零率的计算基本同 1.1 双门限法 中相同。不过这里 \(x_n(m)\) 需要先进行限幅处理,即:
此时,能零比可以表示为:
此处,b为一较小的常数,用于防止 \(ZCR_n\) 为零溢出。
(2)能熵比的端点检测
谱熵值很类似于过零率值,在说话区间内谱熵值 小于 噪声段的谱熵值,所以同 能零比类似,能熵比的表示为
1.5 对数频谱距离法
设含噪语音信号为 \(x(n)\) ,加窗分帧处理后得到第 \(i\) 帧语音信号为 \(x_i(m)\) ,帧长为 N。任何一帧语音信号 \(x_i(m)\) 做 FFT 后为:
对频谱 \(X_i(k)\) 取模值后再取对数,得:
两个信号 \(x_1(n)\) 和 \(x_2(n)\) 的对数频谱距离定义为:
式子中,\(N_2\) 表示只取正频率部分,即 \(N_2 = N/2 -1\)
当采用对数谱距离进行端点检测时,对数谱距离的两个信号的分别是语音信号和噪声信号。其中噪声信号的平均频谱由下式获得:
这里,NIS 表示前导的无语帧。
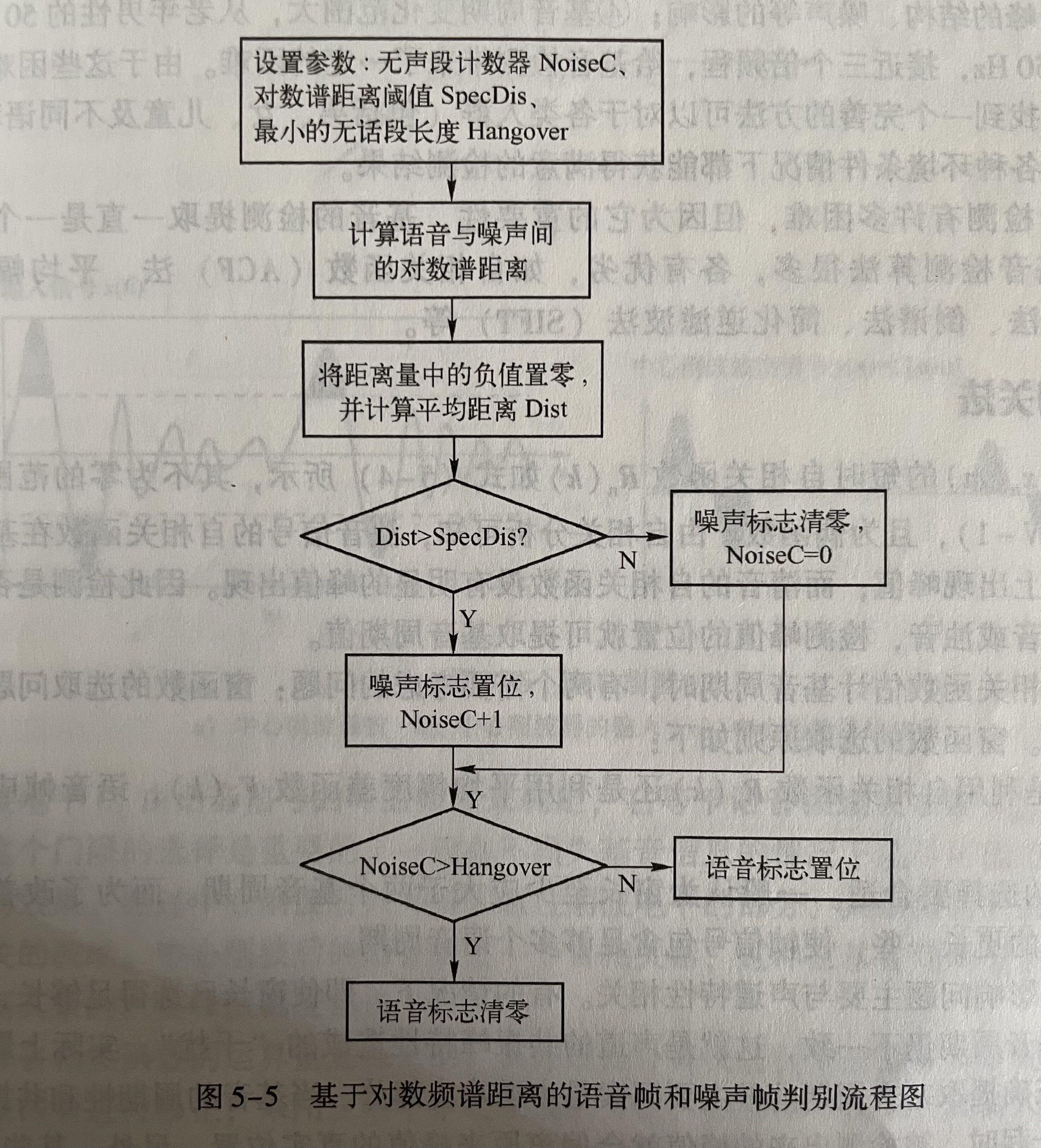
基于对数谱距离的语音帧和噪声帧判别流程如下图所示。通过判断一段语音中的语音帧和噪声帧,即可实现基于对数谱距离的端点检测。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号