
Kettle调优教程(推荐收藏)
1、调整JVM大小
linux文件路径:data-integration/spoon.sh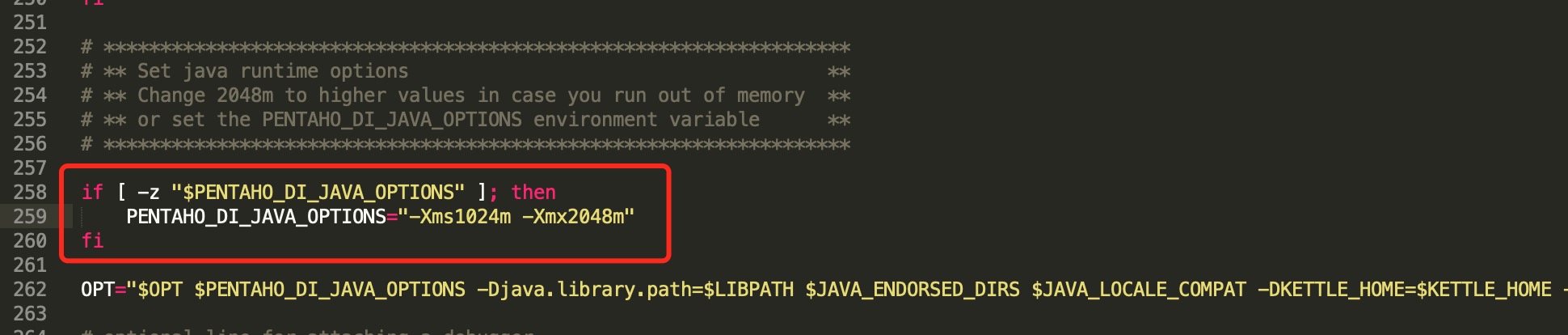
windows路径:

-Xms1024m:设置JVM初始内存为1024m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-Xmx2048m:设置JVM最大可用内存为2048M。
-Xmn2g:设置年轻代大小为2G。整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小。持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
-Xss128k:设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
垃圾回收器:如使用G1垃圾回收器
export PENTAHO_DI_JAVA_OPTIONS="-Xms512m -Xmx1024m -XX:+UseG1GC -Dfile.encoding=UTF-8"
2、 调整提交(Commit)记录数大小
Kettle默认Commit数量为:1000,可以根据具体场景数据量大小来设置Commitsize:1000~50000
可以单个步骤进行设置,也可以通过kettle.properties 属性文件进行自定义参数设置。
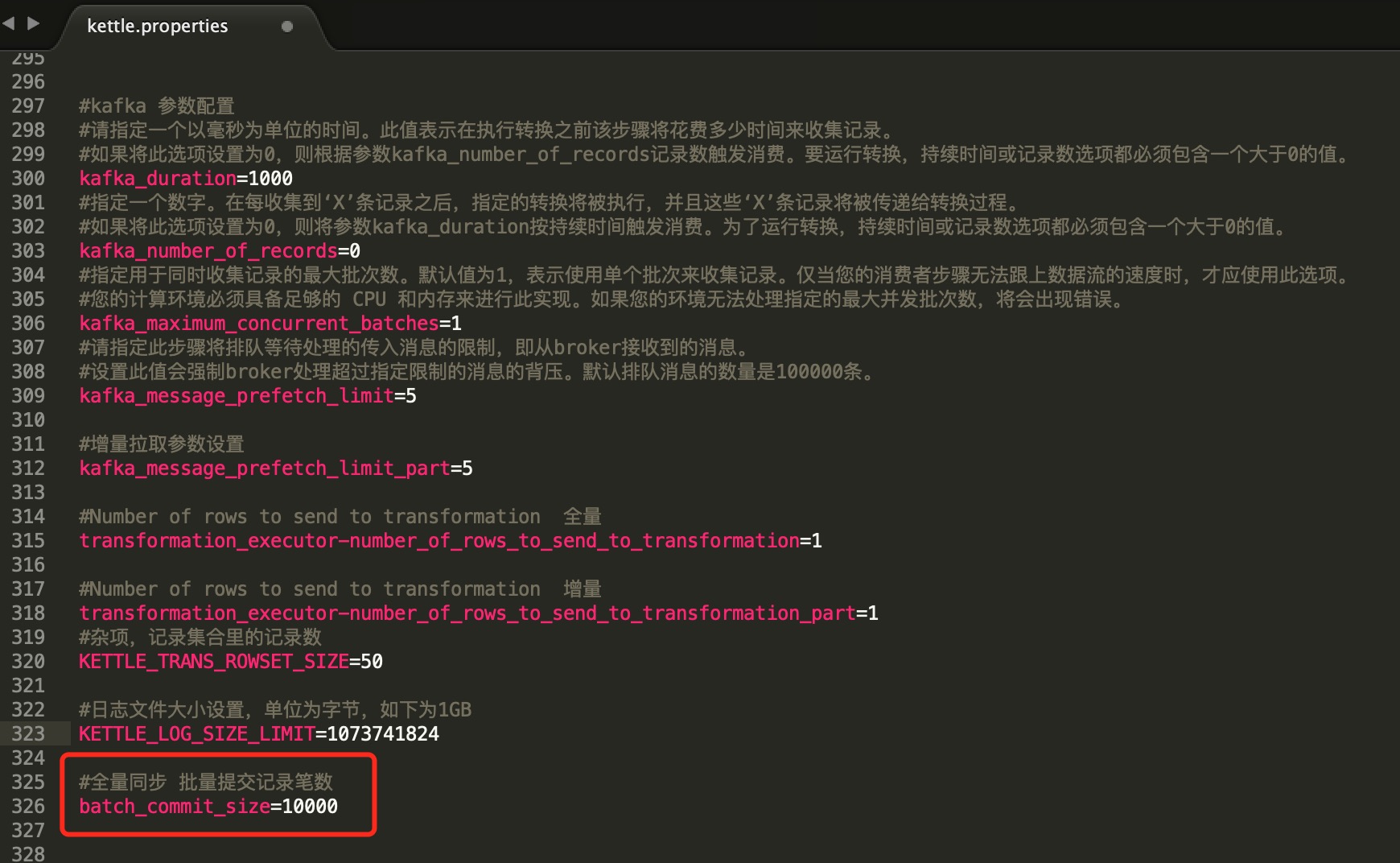
批量提交的步骤中可以${batch_commit_size} 进行引用。
3、使用数据库连接池
尽量使用数据库连接池,因为频繁建立&断开连接比较耗费时间。
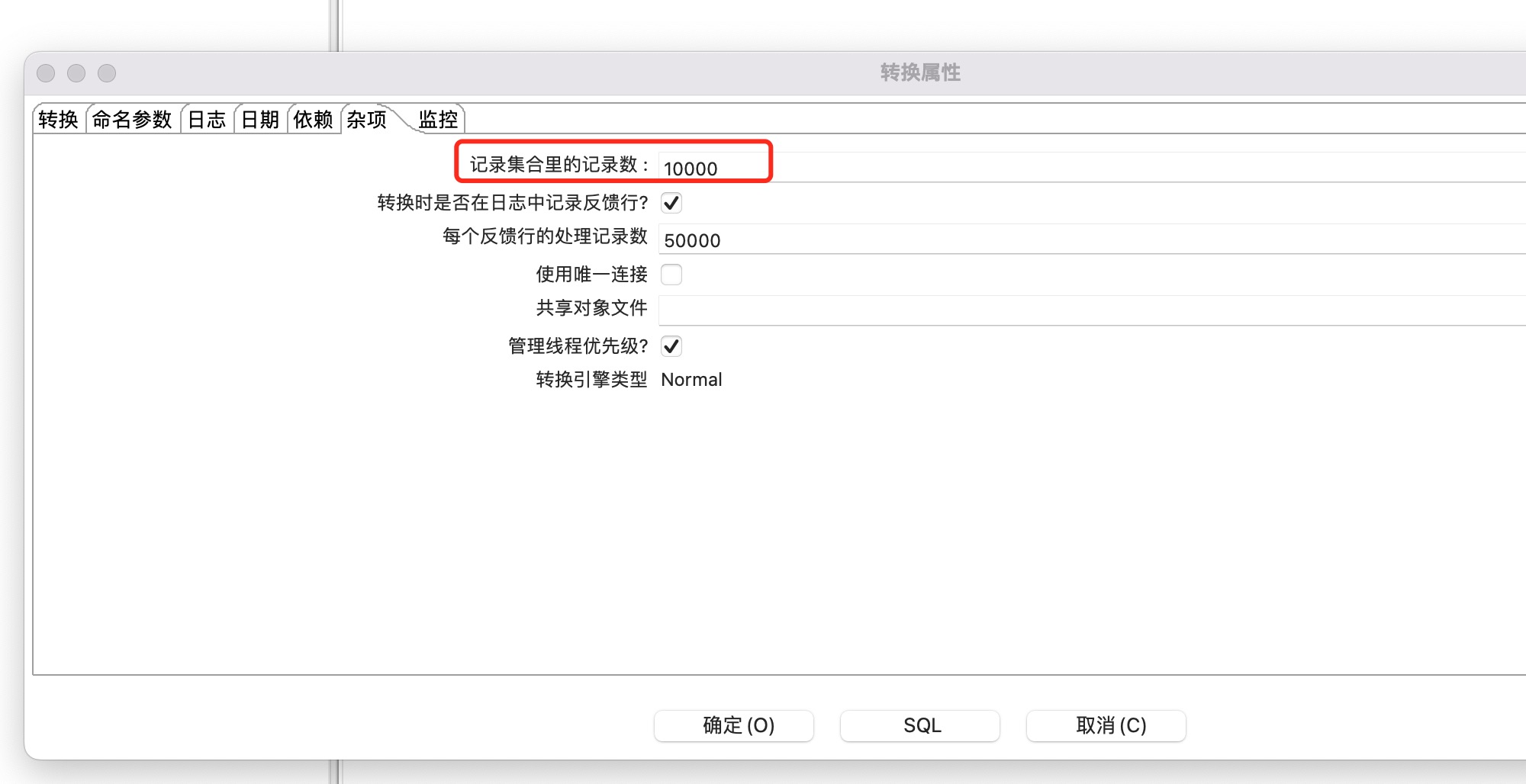
4、合理设置行集大小
行集在Kettle中的作用包括:传递数据、缓存数据、临时存储数据、分批处理数据等。通过合理使用行集,可以实现数据的有效管理和处理,提高数据处理的效率和质量。
双击画布-》杂项-〉记录集合里的记录数进行设置,也可以在kettle.properties属性文件中添加全局参数KETTLE_TRANS_ROWSET_SIZE进行设置。
5、设计kettle流程时尽可能少的使用Kettle步骤,因为kettle步骤之间是有行集缓存的,步骤使用的越多,缓存也就越多,步骤间复制拷贝的次数也就越多。
6、根据业务场景,尽可能采用增量同步,而不是全量同步。全量同步时清空数据时采用truncate方式而不是delete方式。
7、可以使用sql来做的一些操作尽量用sql;Group , merge , stream lookup,split field这些操作都是比较慢的,想办法避免他们,能用sql就用sql。
8、插入大量数据的时候尽量把索引删掉,这个具体要根据业务场景,有的是不能删索引的,会影响业务系统使用。
9、尽量避免使用update , delete操作,尤其是update,如果可以把update变成先delete, 后insert。
11、合理使用数据库索引。
10、合理设置日志级别
行集日志的性能会严重下降,通常情况下可以设置为基本日志,生产环境推荐设置错误日志。
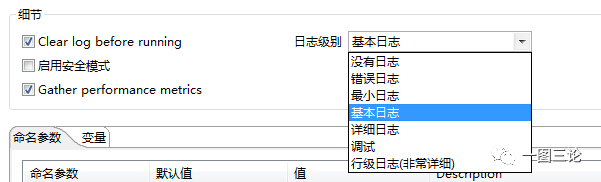
也可以通过如下方式进行设置:
cd /xxx/data-integration && sh kitchen.sh -rep=local -job=xxx_job -dir=/ -level=Error -carte=http://ip:port/cart -exec
或者
curl -X POST -H "Authorization: Basic YWRtaW46UEBzc3cwcmQyMDIz" -H "Content-Type: application/x-www-form-urlencoded" --data "rep=local&job=xxx_job&level=Basic" http://ip:port/kettle/executeJob/ &
11、设置改变开始复制的数量
此配置可以提高性能,类似于java等语言中的多线程,如下图所示:
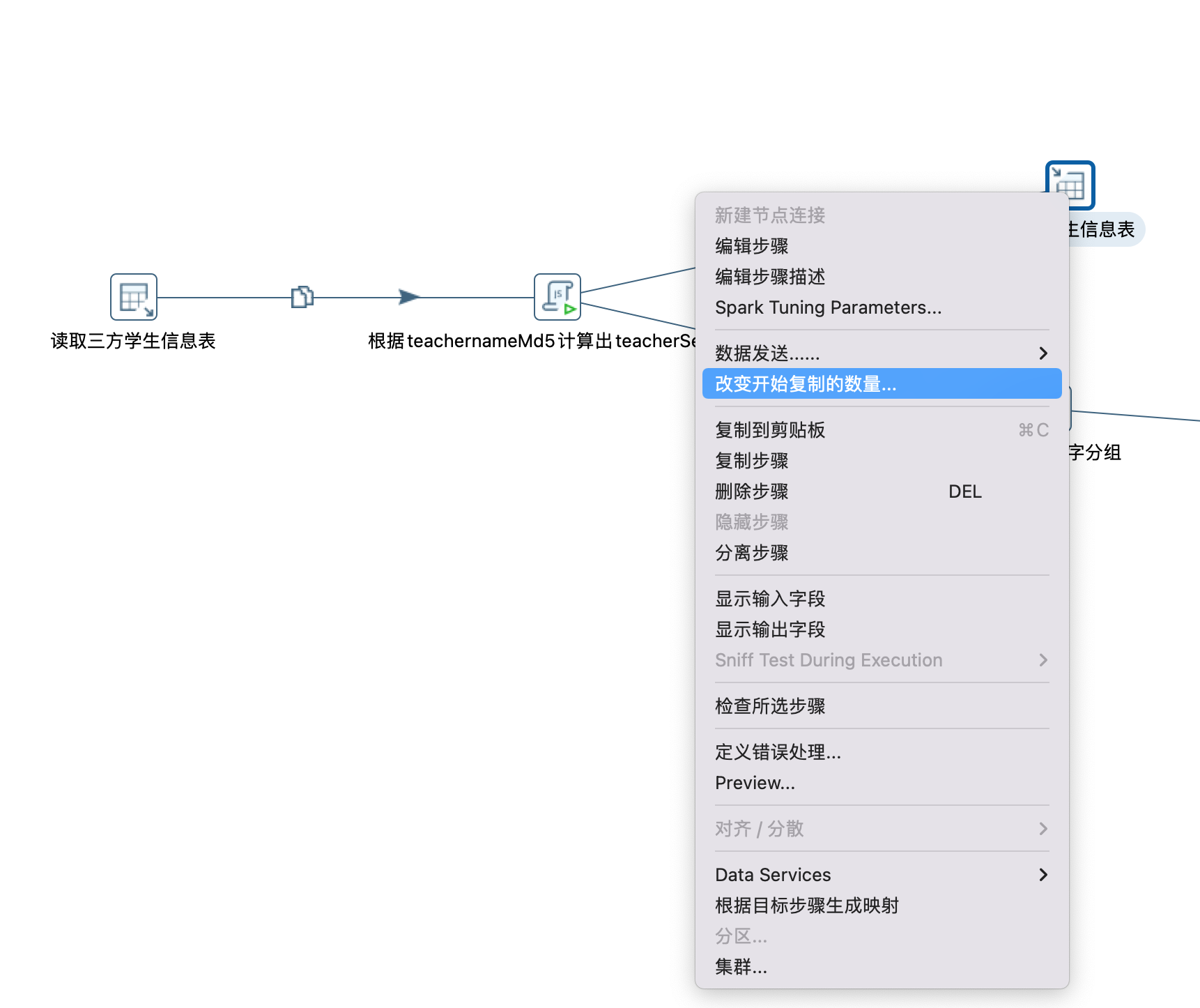
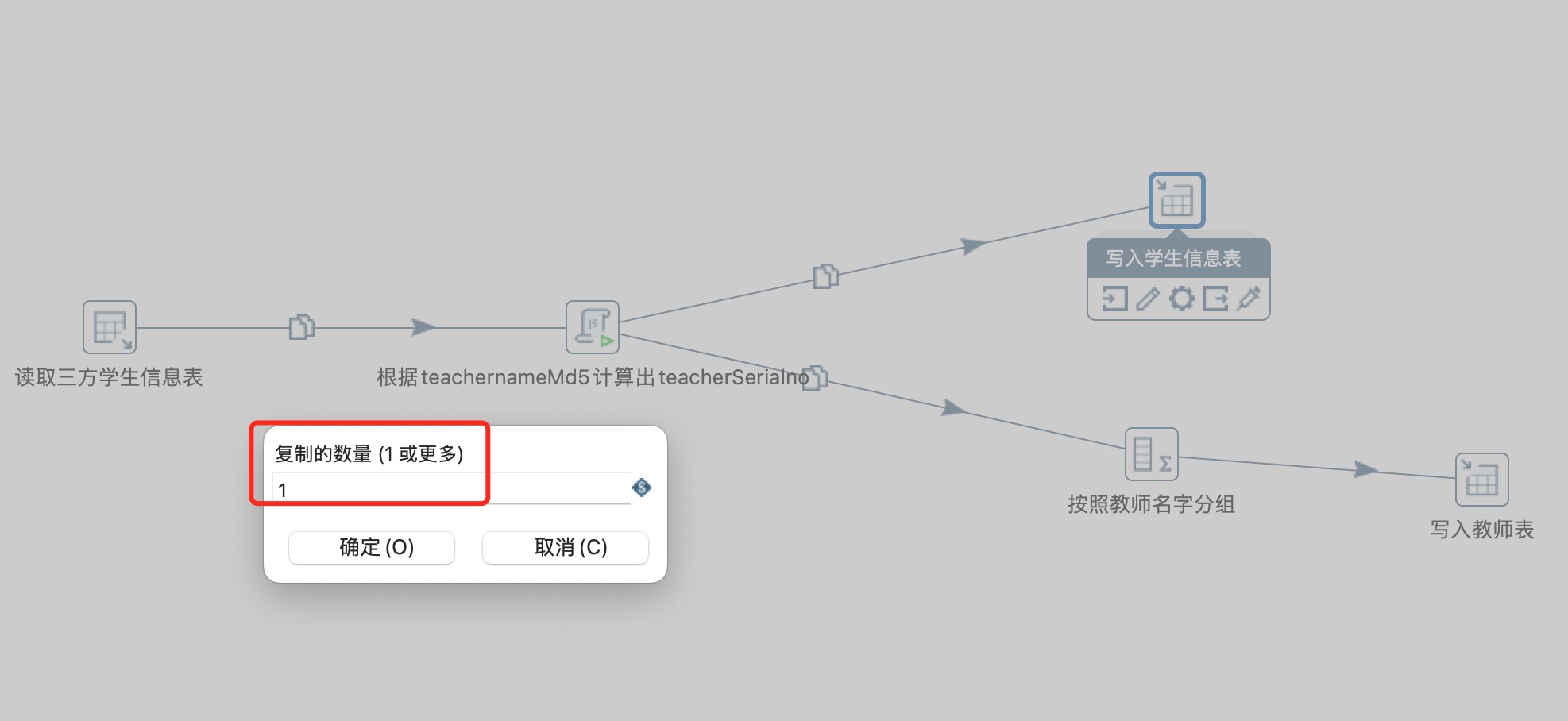
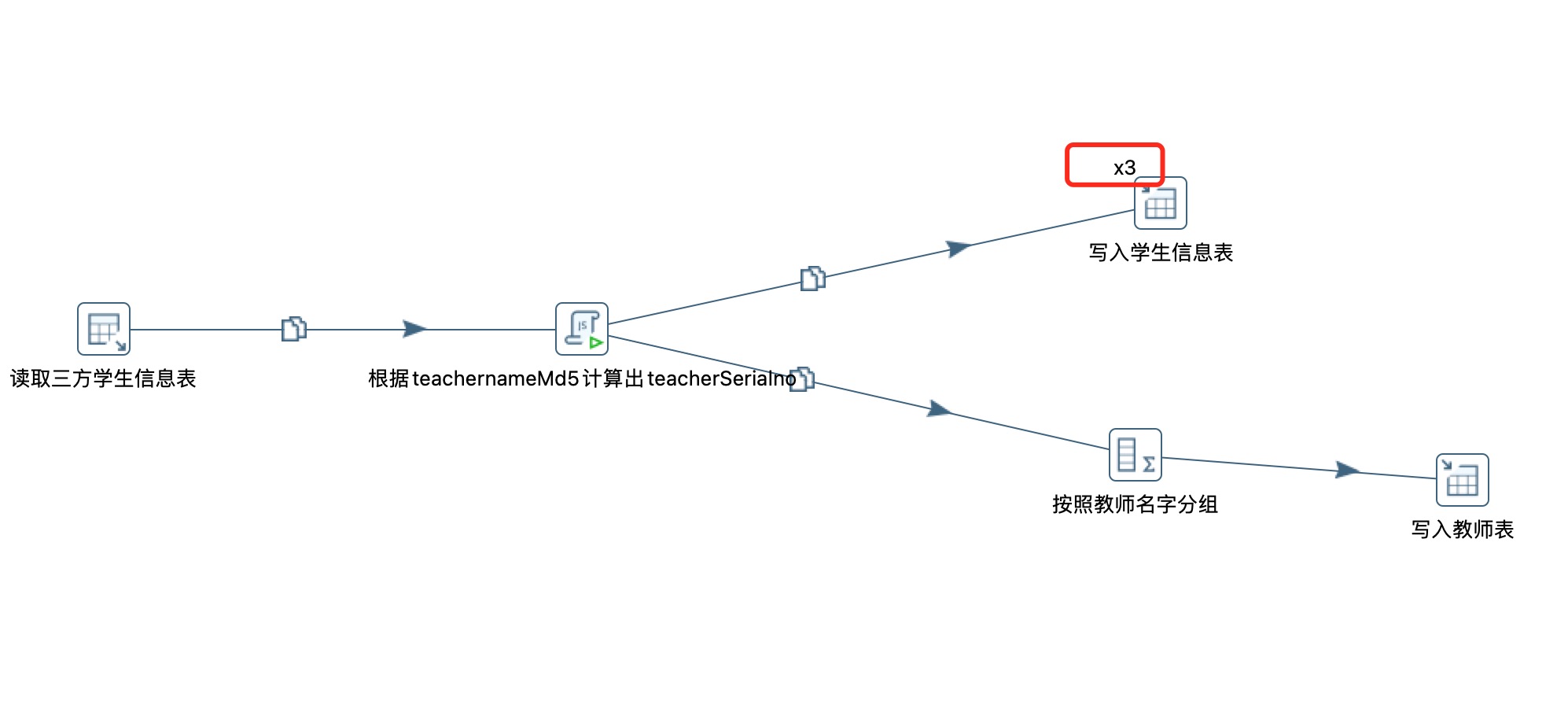
填写3,点击确定如下图:
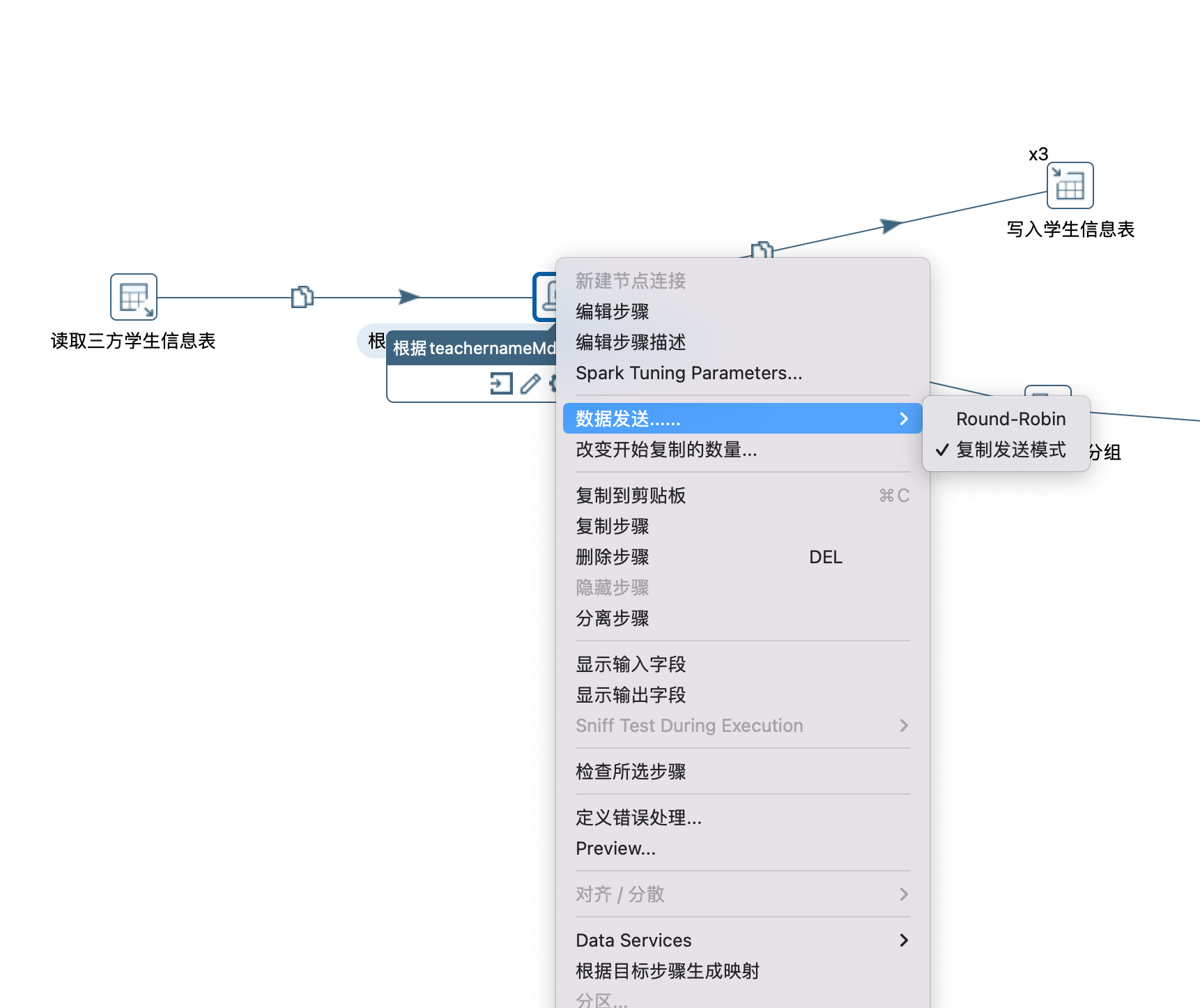
注意:前置步骤一定要调整数据发送策略(有Round-Robin和复制发送模式两种,自己根据自己业务场景进行选择),如下图
12、可以通过spoon客户端和carte服务器排查kettle哪些步骤存在性能问题,如下图所示
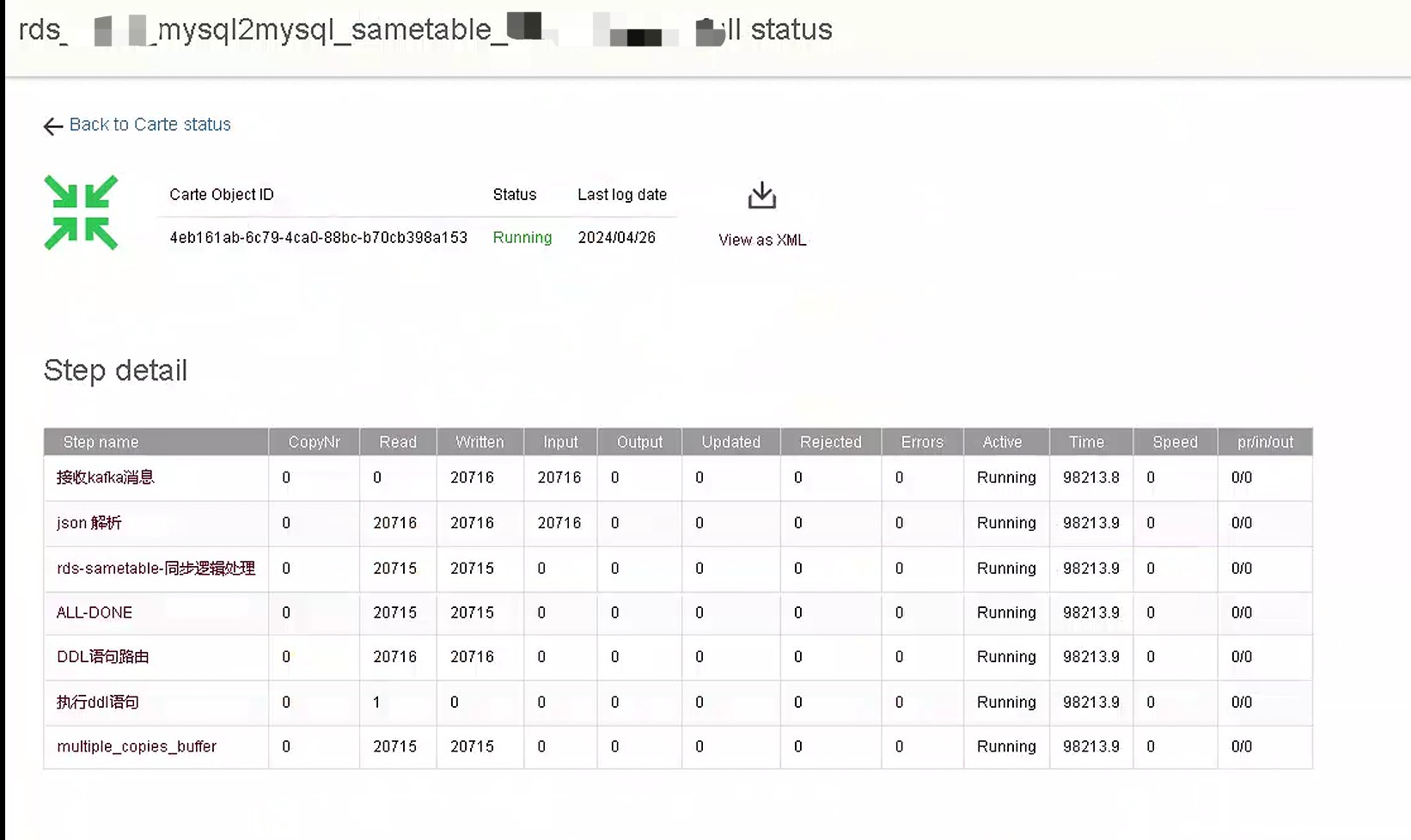
重点观察每个步骤的input和output以及处理的speed找出性能瓶颈,然后进行调优。
小伙伴们还有哪种调优方式,欢迎留言讨论

