
ETL工具-nifi干货系列 第十五讲 nifi处理器ConsumeKafka实战教程
1、上一节课我们学习了处理器PushKafka,通过该处理器往kafka中间件写数据,今天我们一起学习处理器ConsumeKafka,此处理器从kafka读取数据进行后续处理,如下图所示:
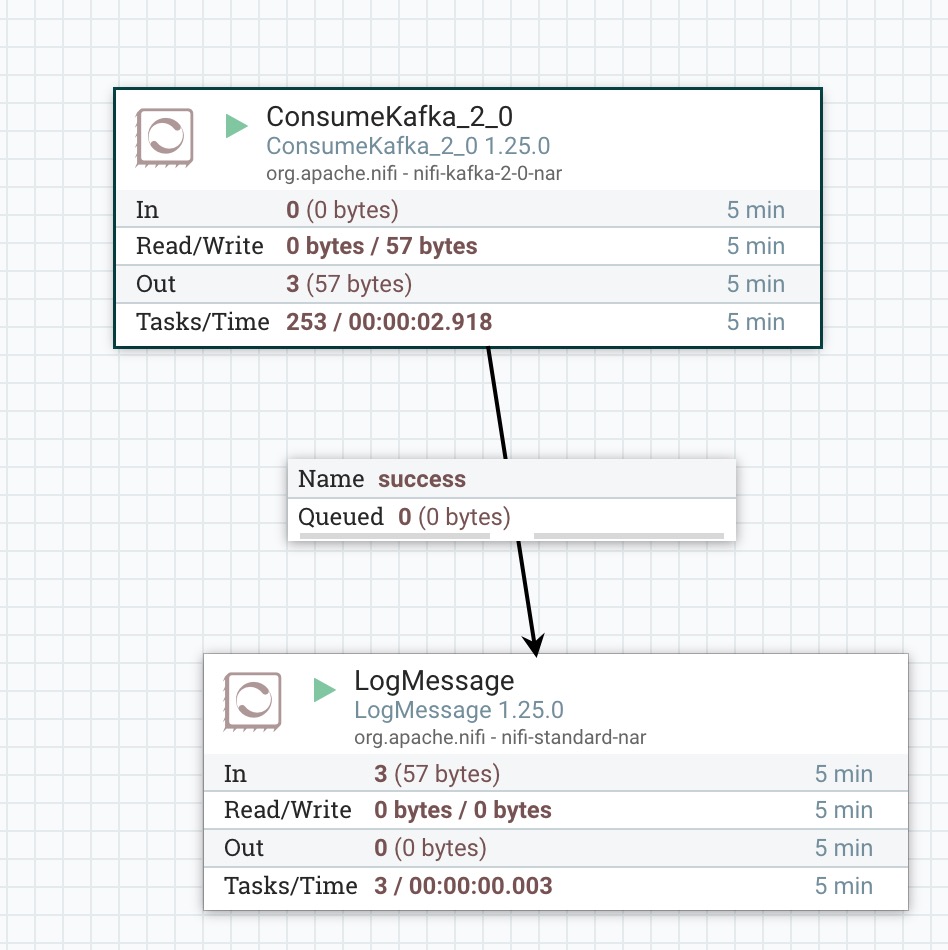
本次示例比较简单:处理器ConsumeKafka 根据topic读取kafka中的数据,然后将数据传递给LogMessage处理器。
2、处理器ConsumeKafka属性配置,如下图所示:

Kafka Brokers:以 host:port 格式表示的 Kafka Broker,集群列表通过逗号,如192.168.101.5:9092,192.168.101.6:9092
Security Protocol: 用于与代理通信的安全协议。对应于 Kafka 客户端的 security.protocol 属性。这里我们使用默认值PLAINTEXT
SASL Mechanism:用于认证的 SASL 机制。对应于 Kafka 客户端的 sasl.mechanism 属性。这里我们使用默认值GSSAPI
Kerberos Service Name:与broker JAAS 配置中配置的 Kafka 服务器的主要名称匹配的服务名称。
Kerberos Credentials Service:支持使用 Kerberos 进行通用凭证认证的服务。
Kerberos Principal:用于与 Kerberos 进行身份验证的主体。
Kerberos Keytab:用于与 Kerberos 进行身份验证的 Keytab 凭据,这个属性需要提供一个文件。
SSL Context Service:支持与 Kafka brokers 进行 SSL 通信的服务。
Topic Name:设置 Kafka 主题的名称,多个主题的话逗号分隔,如xiaojingang,dajingang
Topic Name Format:指定要拉取数据的 Kafka 主题的名称。如果有多个主题,可以使用逗号分隔;如果是单个正则表达式,则指定是否提供的主题名称为逗号分隔列表或单个正则表达式。
Honor Transactions:指定 NiFi 是否应在与 Kafka 通信时遵守事务性保证。如果设置为 false,处理器将使用“隔离级别”为 read_uncommitted。这意味着消息将在写入 Kafka 后立即接收,但即使生产者取消事务,也会被拉取。如果此值设置为 true,则 NiFi 将不会接收任何生产者事务被取消的消息,但这可能会导致一些延迟,因为消费者必须等待生产者完成整个事务,而不是在消息可用时立即拉取。
Group ID:一个群组 ID 用于标识属于同一消费者组的消费者。
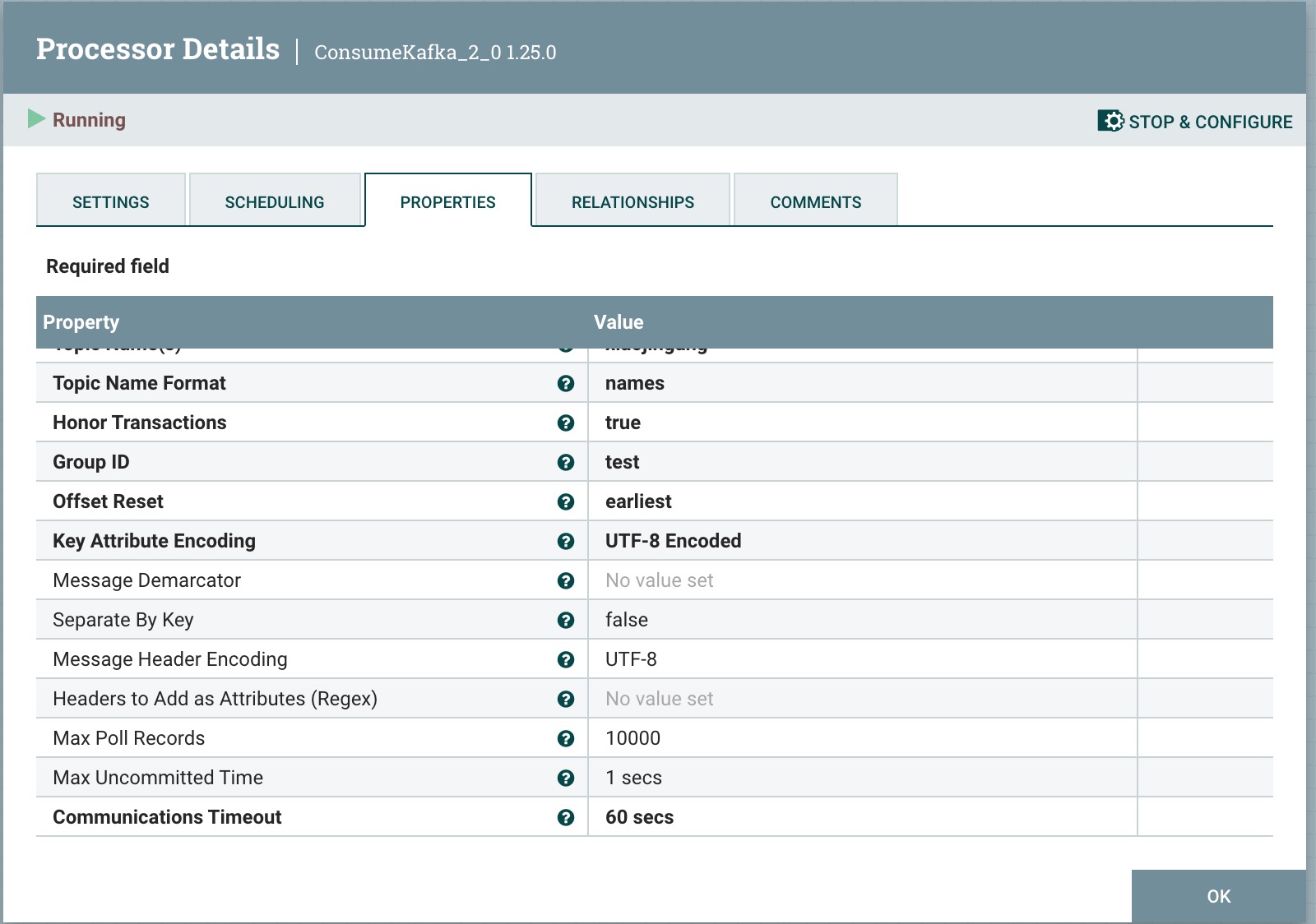
Offset Reset: Kafka 初始偏移量设置,有earliest 、latest 、none 三个选项。
Key Attribute Encoding:发出的FlowFiles具有一个名为'kafka.key'的属性。此属性规定了该属性值应如何编码。这是使用默认值。
Message Demarcator:指定用于在单个FlowFile中分隔多个消息的字符串(解释为UTF-8)。如果未指定,则将整个FlowFile内容用作单个消息。如果指定了分隔符,则将FlowFile内容拆分为此分隔符,并将每个部分作为单独的Kafka消息发送。要输入特殊字符,如'换行符',请使用CTRL+Enter或Shift+Enter,取决于您的操作系统。
Separate By Key:如果设置为 true,并且设置了 <Message Demarcator> 属性,则仅当两个 Kafka 消息具有相同的键时,才会将两个消息添加到同一个 FlowFile 中。
Message Header Encoding:发现在 Kafka 消息上的任何消息头都将作为属性添加到出站 FlowFile 中。此属性指示用于反序列化头的字符编码。
Headers to Add as Attributes (Regex):正则表达式将与所有消息头进行匹配。任何名称与正则表达式匹配的消息头都将作为属性添加到 FlowFile 中。如果未指定,则不会将头值添加为 FlowFile 属性。如果两条消息具有相同标题的不同值,并且该标题由提供的正则表达式选择,则这两条消息必须添加到不同的 FlowFiles 中。因此,如果消息预期具有每个消息唯一的标题值(例如标识符或时间戳),用户在使用类似于 ".*" 的正则表达式时应谨慎,因为它将阻止 NiFi 将消息有效地捆绑在一起。
Max Poll Records:指定 Kafka 在单次轮询中应返回的最大记录数。
Max Uncommitted Time:指定允许的最长时间,直到必须提交偏移量。该值影响偏移量提交的频率。较少频繁地提交偏移量会增加吞吐量,但也会增加在重新平衡或在提交之间的 JVM 重启时潜在数据重复的窗口。此值还与最大轮询记录和使用消息分隔符相关。当使用消息分隔符时,我们可以有远比不使用时更多的未提交消息,因为我们在内存中要跟踪的内容要少得多。
Communications Timeout:指定消费者与 Kafka Broker 通信时应使用的超时时间。
3、运行nifi flow,查看ConsumeKafka处理器的溯源信息,如下图所示:
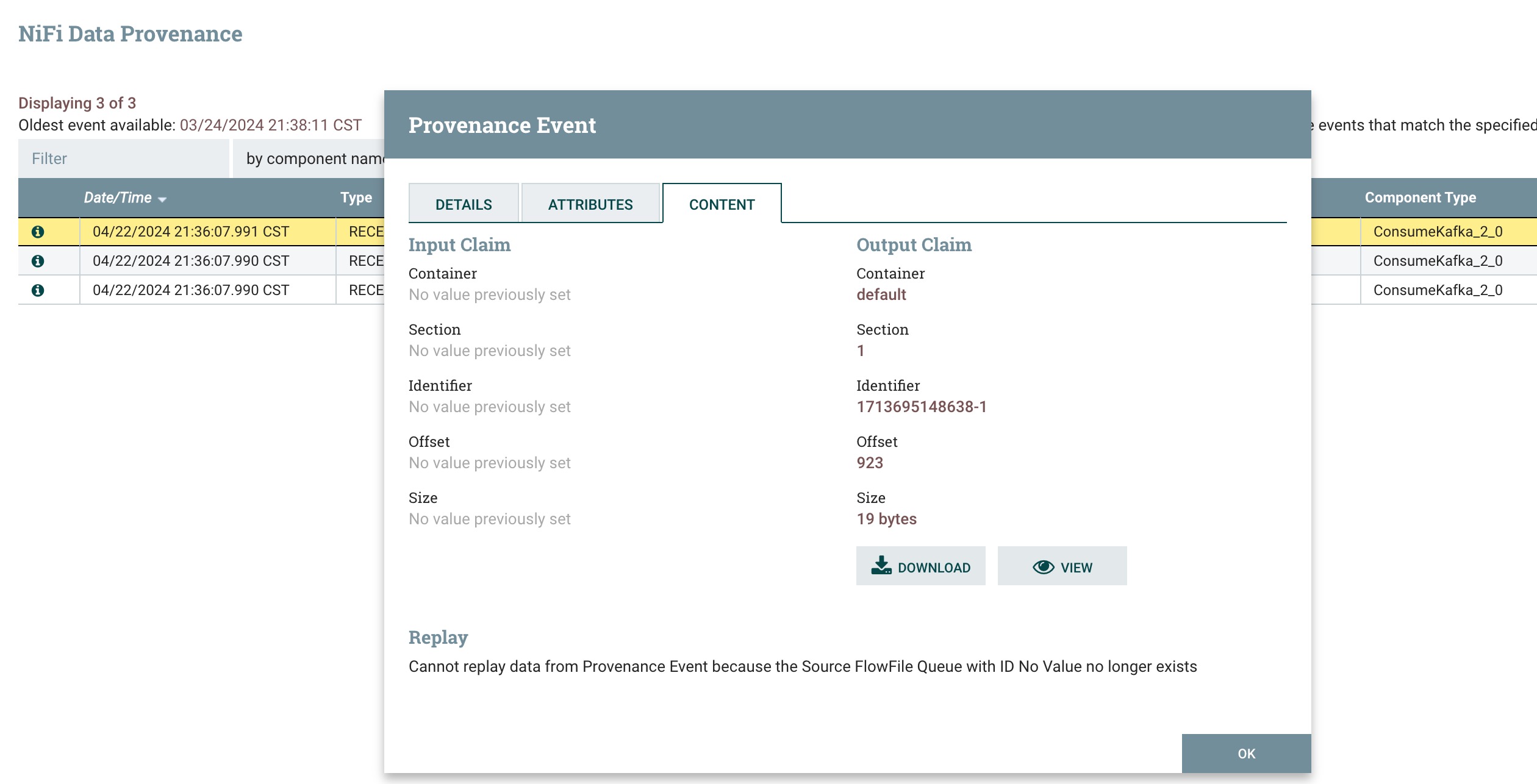
点击view按钮查看数据,如下图所示:


