
kettle从入门到精通 第三十八课 kettle 分页全量同步(数据量大)
1、上一课我们学习了在数据量小的情况下的全量同步示例,本次我们一起学习下kettle 分页全量同步。
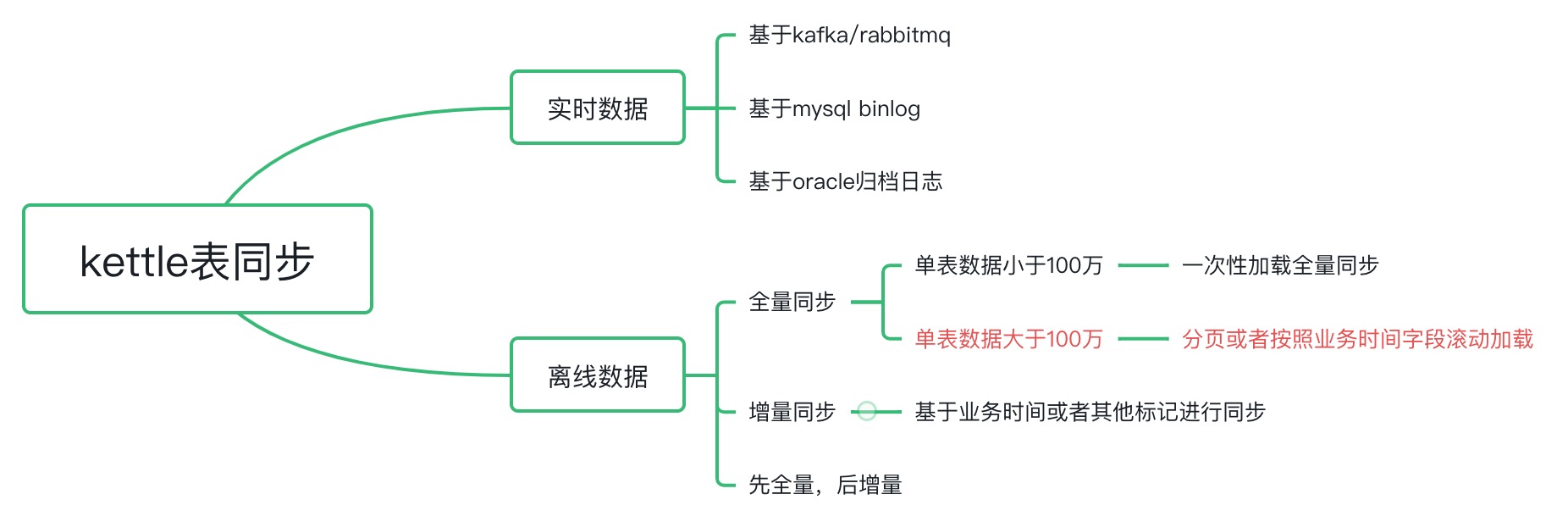
2、kettle分页全量同步示例依然基于test数据库,从t1表全量同步数据到t2表,由于t1表的数据比较大,所以选择分页全量同步策略,如下图所示。
前提:
a、基于mysql 数据库
b、分页查询数据基于select * from t1 limit offset,size
c、假定t1表中有125条记录,每页size=25,offset=(curr_page-1)*size
主要步骤:
a、truncate目标DB表t2表
b、计算t1表的总记录数,然后通过javascript步骤生成offset 列表。
c、truncate_test_t2、query_test_t1_totalPage、循环抽数是三个转换步骤,每个转换步骤引用自己的具体实现转换文件。
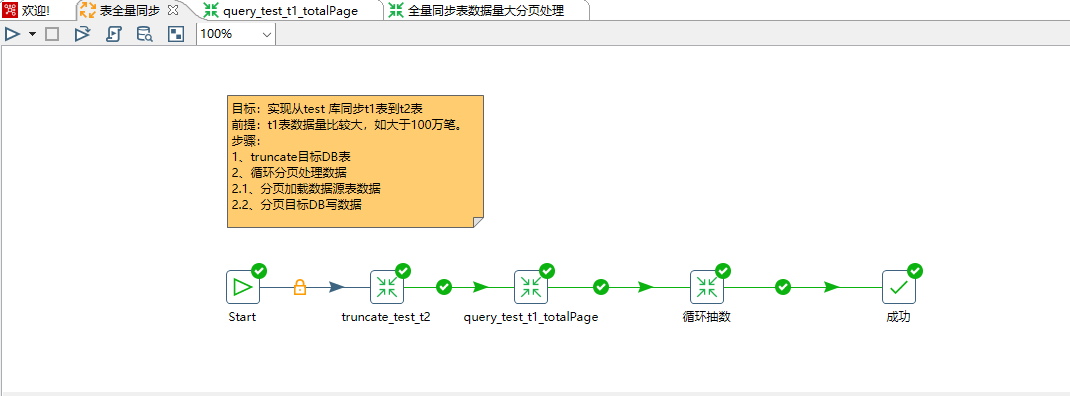
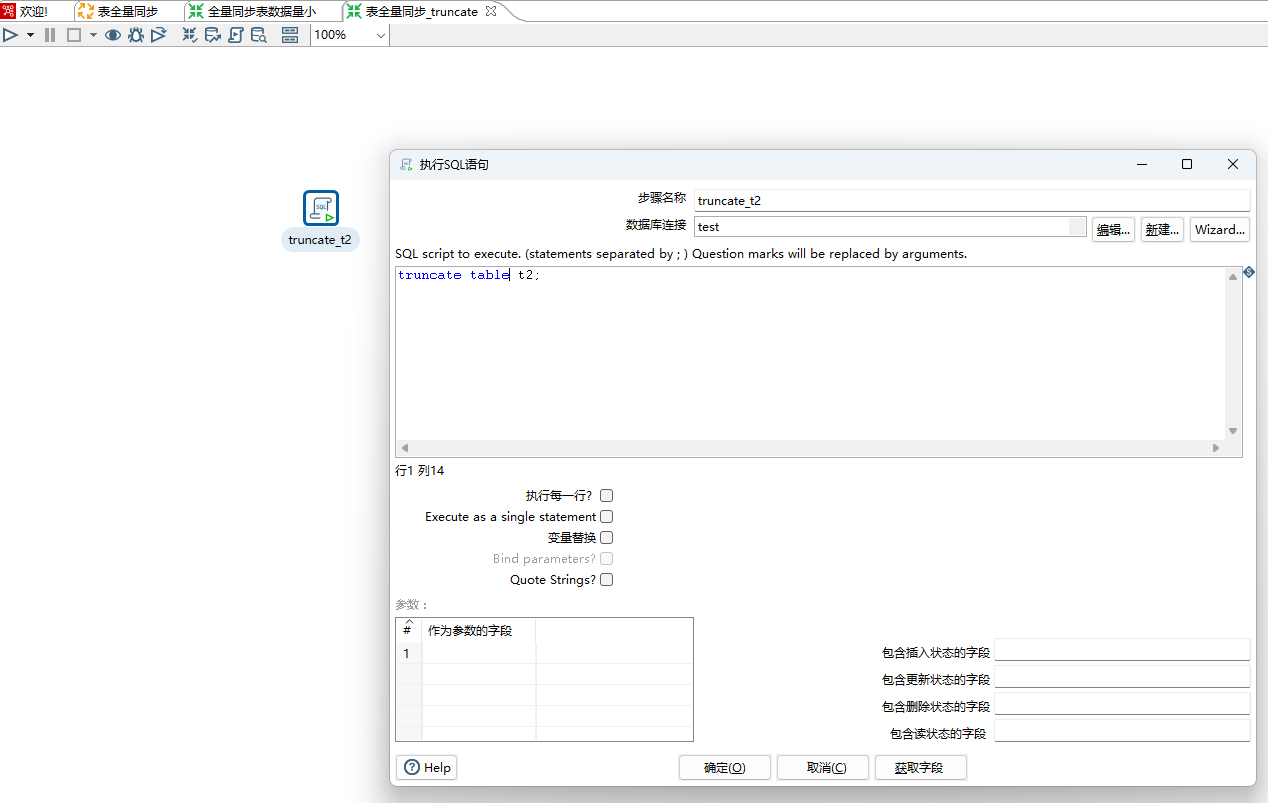
3、truncate_test_t2的转换逻辑比较简单,每次同步数据之前将目标表t2 表数据清空,当然也可以采用delete 语句,不过delete 语句在大数据量的情况下性能比较差。
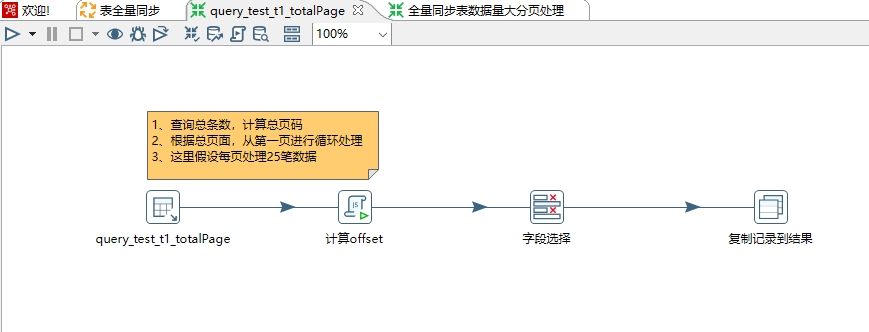
5、计算offset步骤是javascript 步骤,这里通过一个for循环,将一条数据转换为多条数据,输出offset和currPage,最后通过SKIP_TRANSFORMATION 跳过for外层的进程。
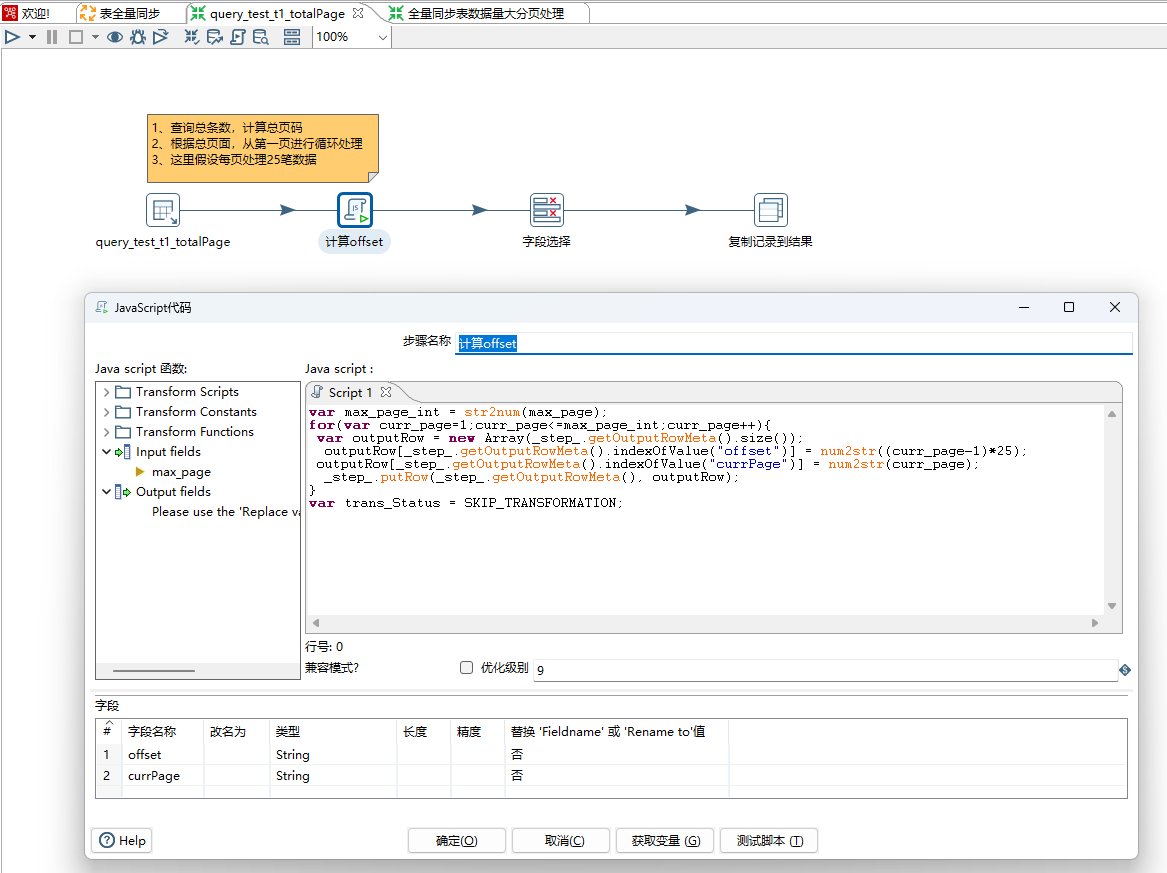
6、 下图是循环抽数步骤具体实现,通过从结果获取记录步骤获取offset,然后offset传递给表输入步骤进行加载数据,最后通过表输出写入目标表t2.
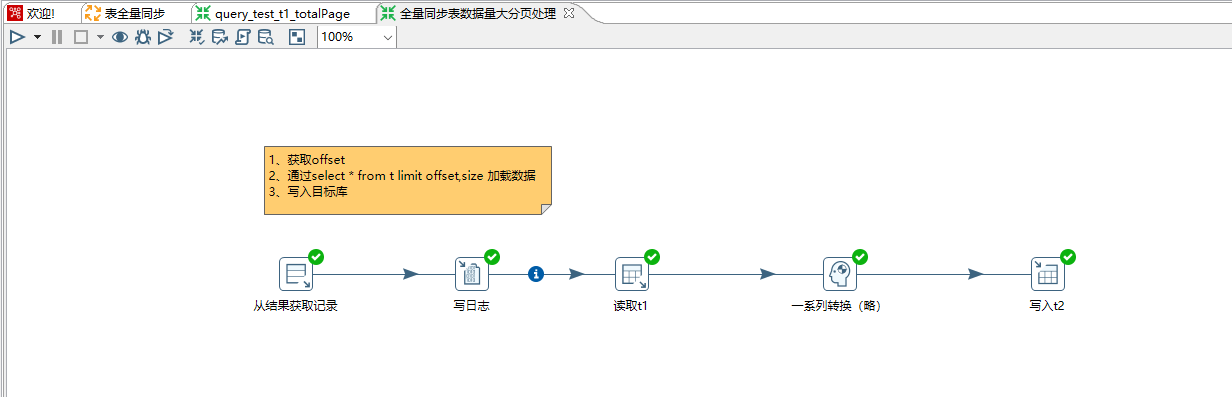
7、这里要注意勾选执行每一行选项。
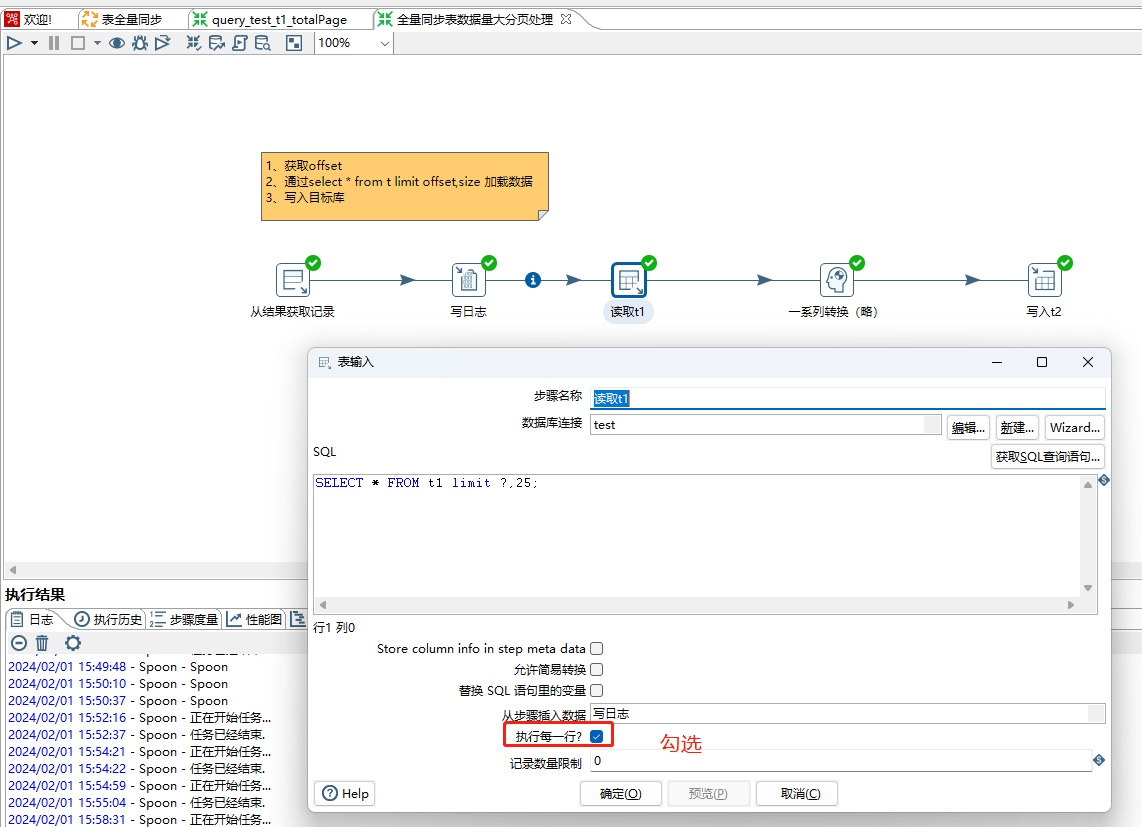
8、循环抽数步骤要注意勾选执行每一个输入选项,这样才可以实现每个offset 执行一个次抽数逻辑,也就是每个批次25笔数据处理一次。
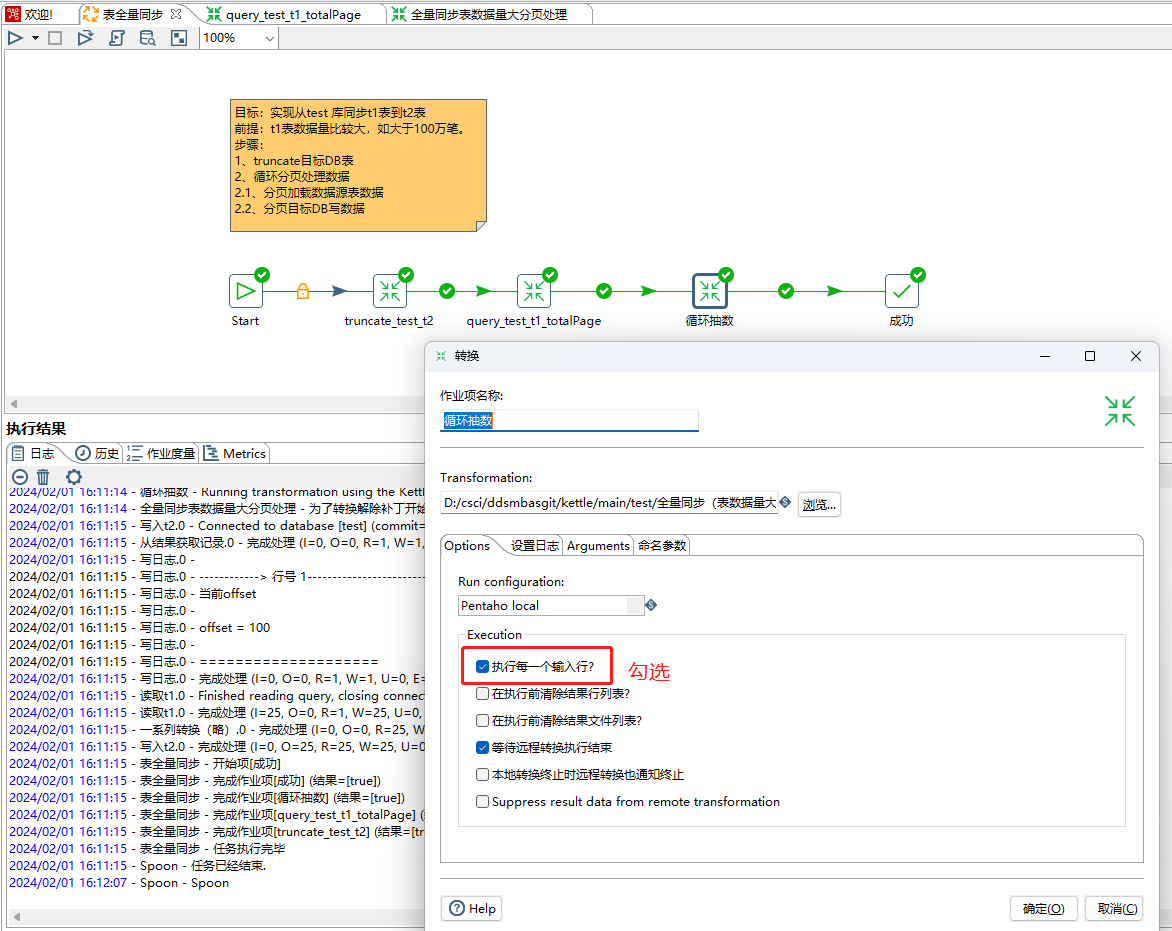
如有小伙伴对图片中用到的步骤不太熟悉的话,可以参考我以前的文章。

