kettle从入门到精通 第三十二课 mysql 数据连接集群/分区配置
1、这里的集群实际上是数据分区或者分片的概念,如中国全国的学生,应该不会都存在一张表里面,有可能每个省市一个表进行存储。
2、集群(分区),如下图所示

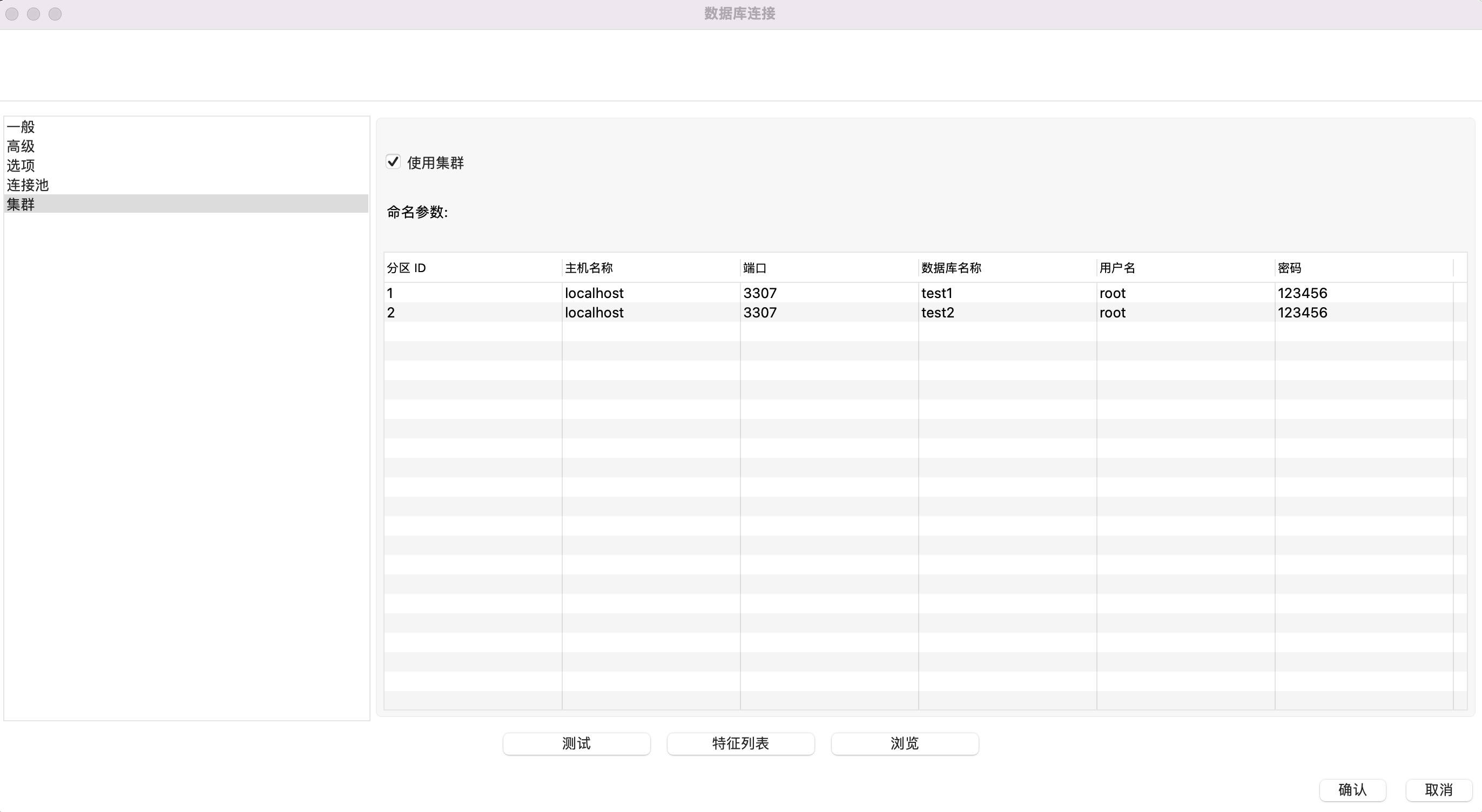
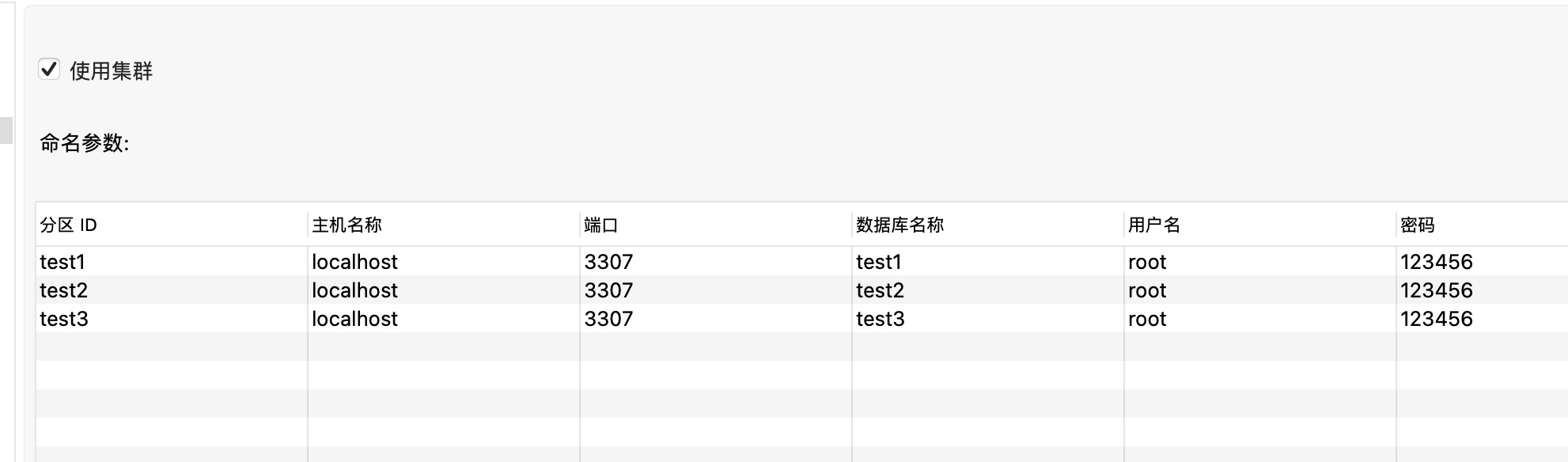
设置在“集群”标签,勾选“使用集群”,然后定义两个分区。这里的分区实际指的是数据库实例,需要指定自定义的分区ID,数据库实例的主机名(IP)、端口、数据库名、用户名和密码。
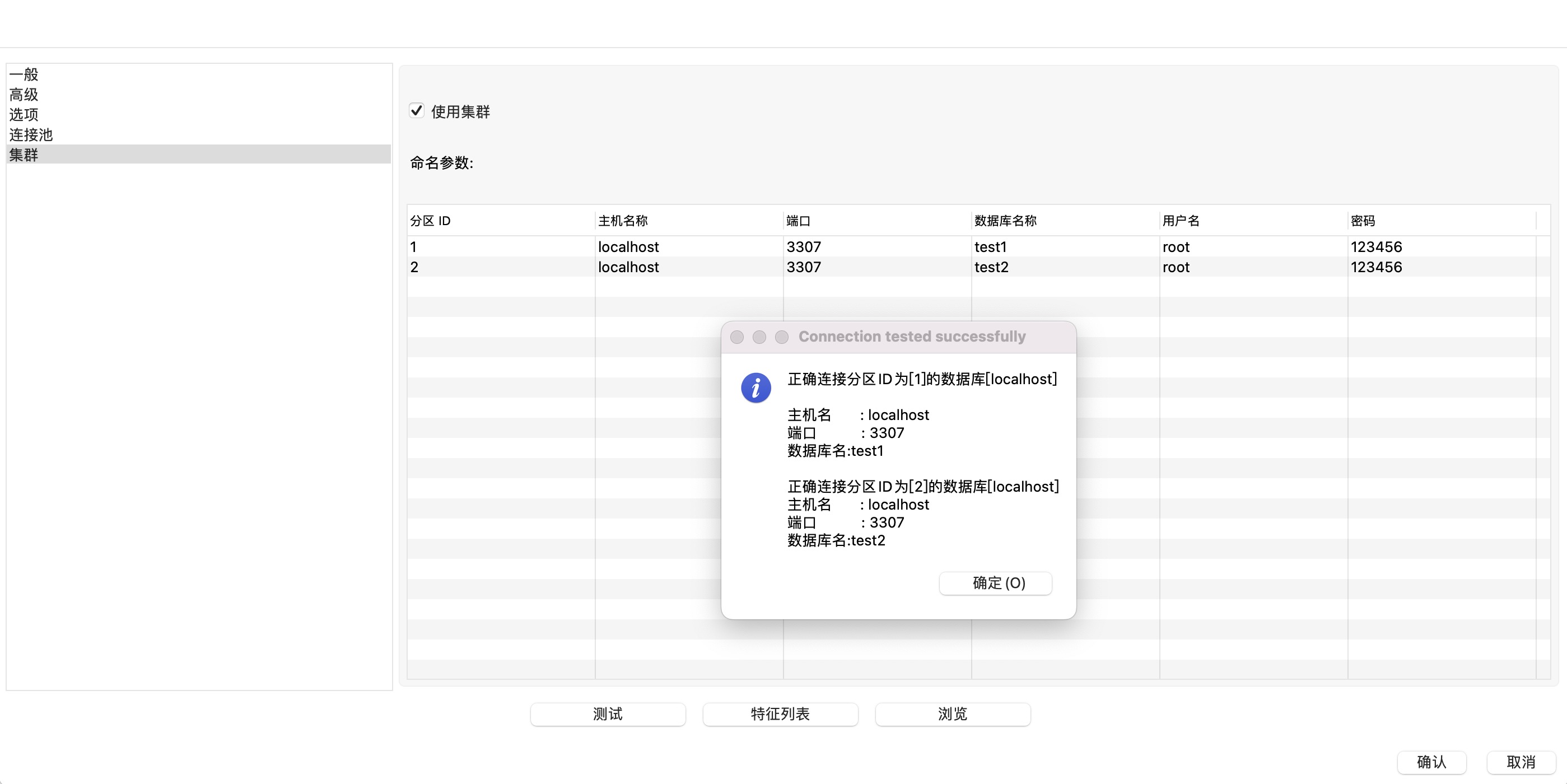
点击测试按钮可以测试数据库是否正常连接,如下图所示
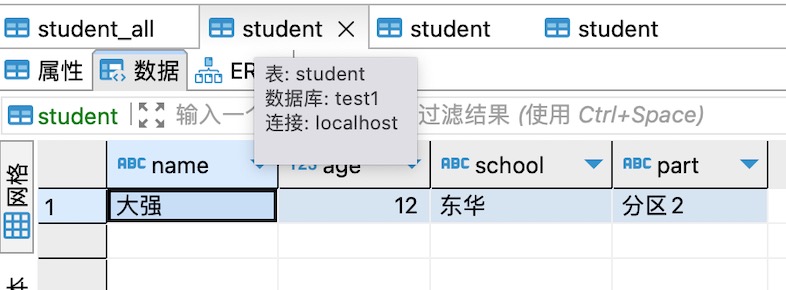
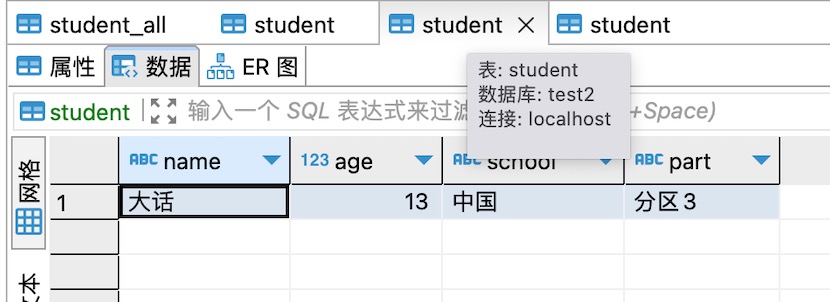
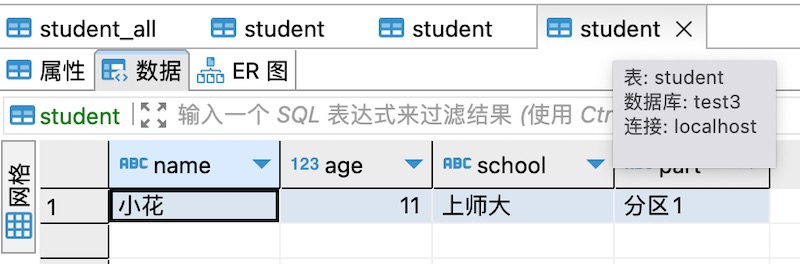
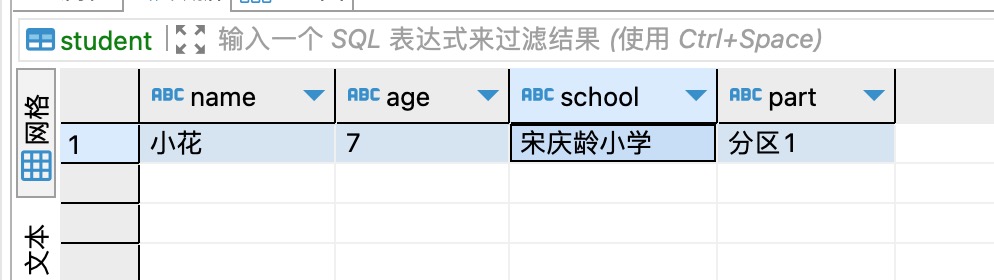
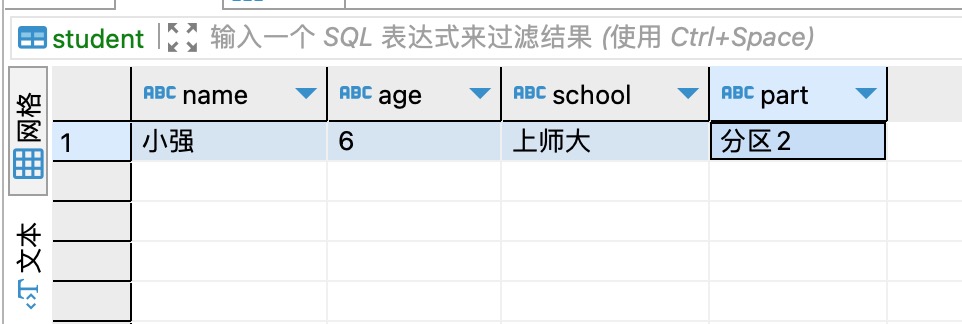
3、有两个数据库test1和test2,两个数据库里面都有一个相同的表,名为student,每个表里有一条数据,如下图所示,后面会用到。
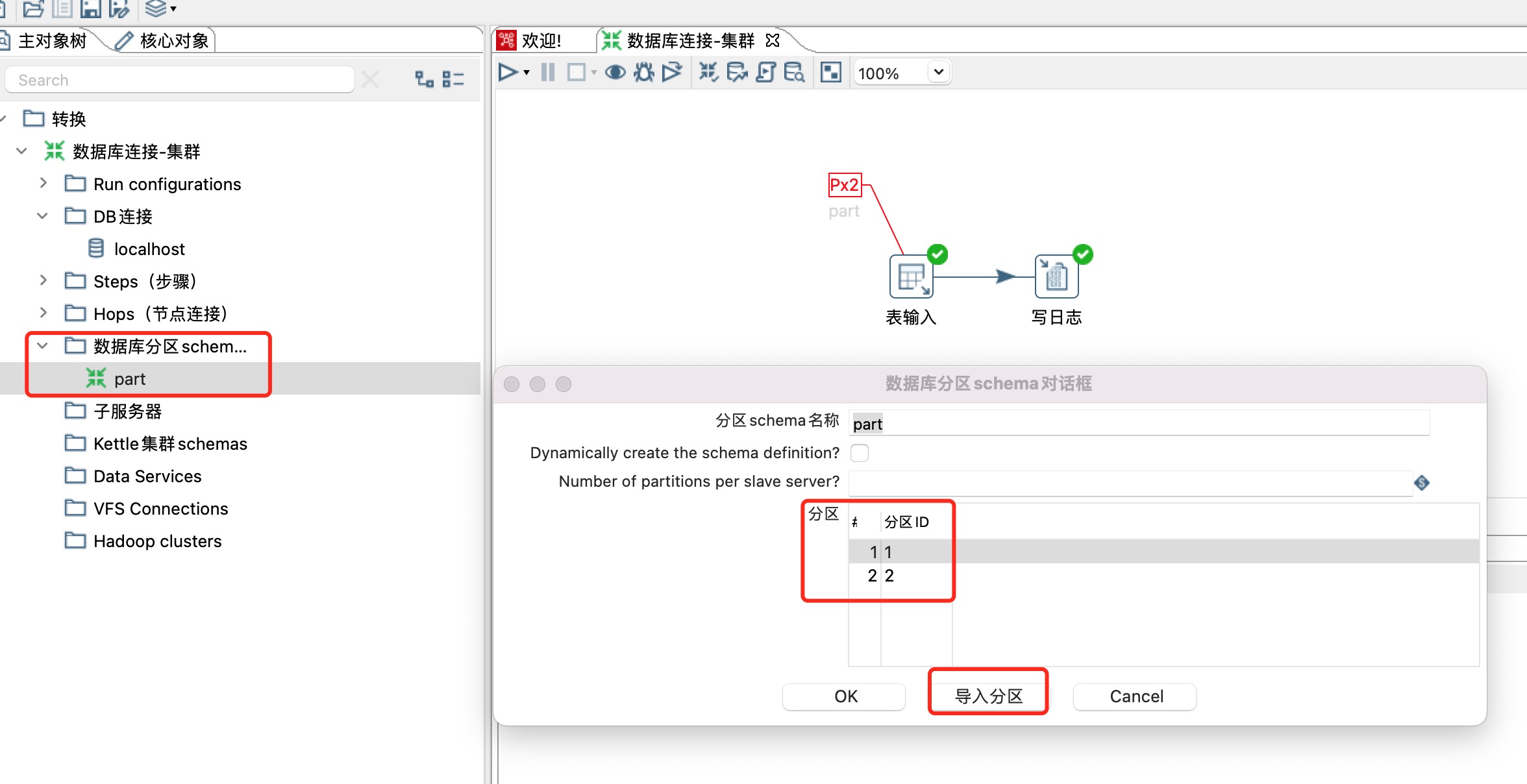
4、创建数据库分区schemas,在“主对象树”的“数据库分区schemas”上点右键“新建”,在弹出窗口中输入“分区schema名称”,然后点击“导入分区”按钮,如下图所示。
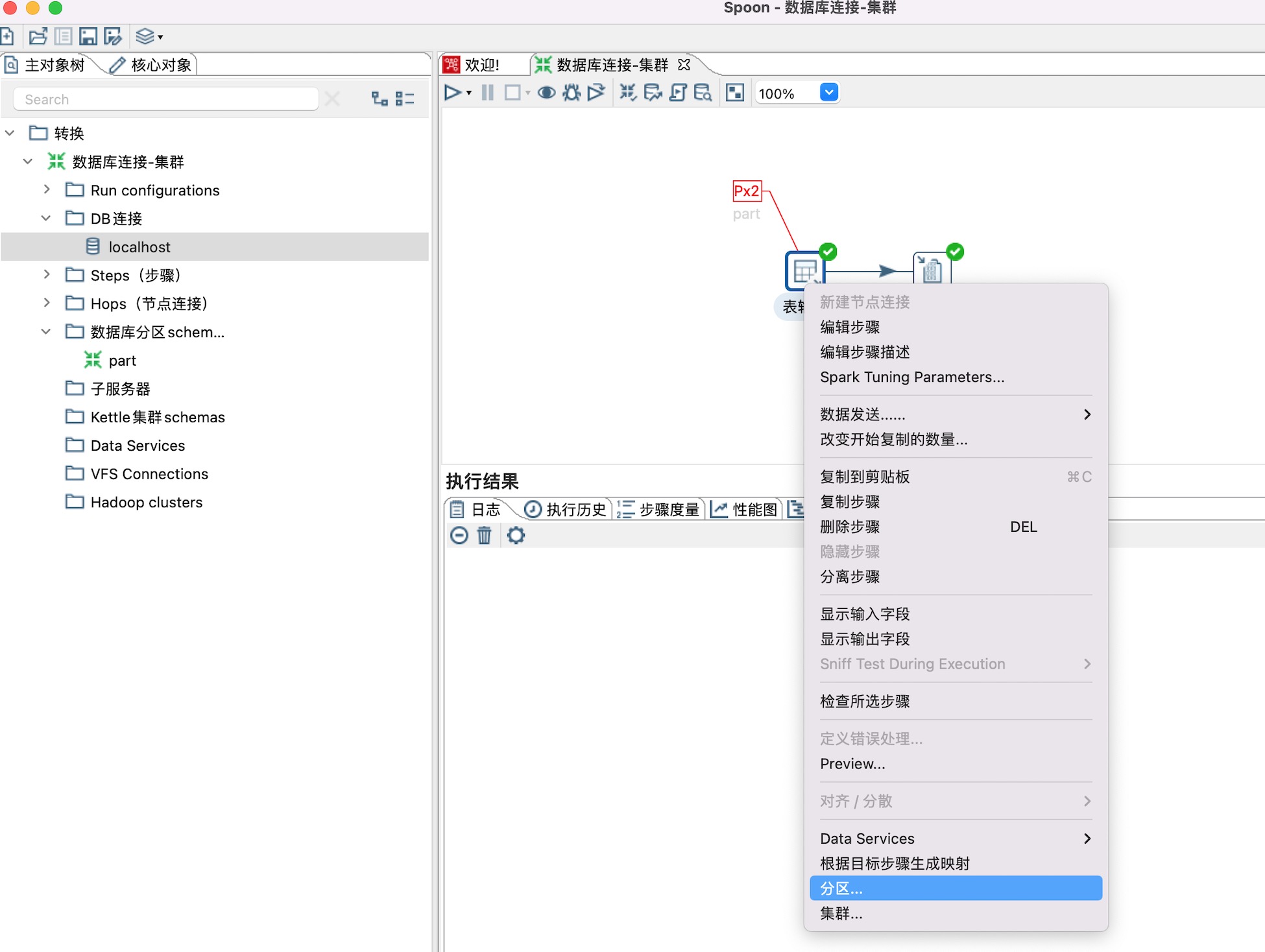
5、为表输入步骤设置分区,右键表输入步骤,设置分区即可,如下图所示
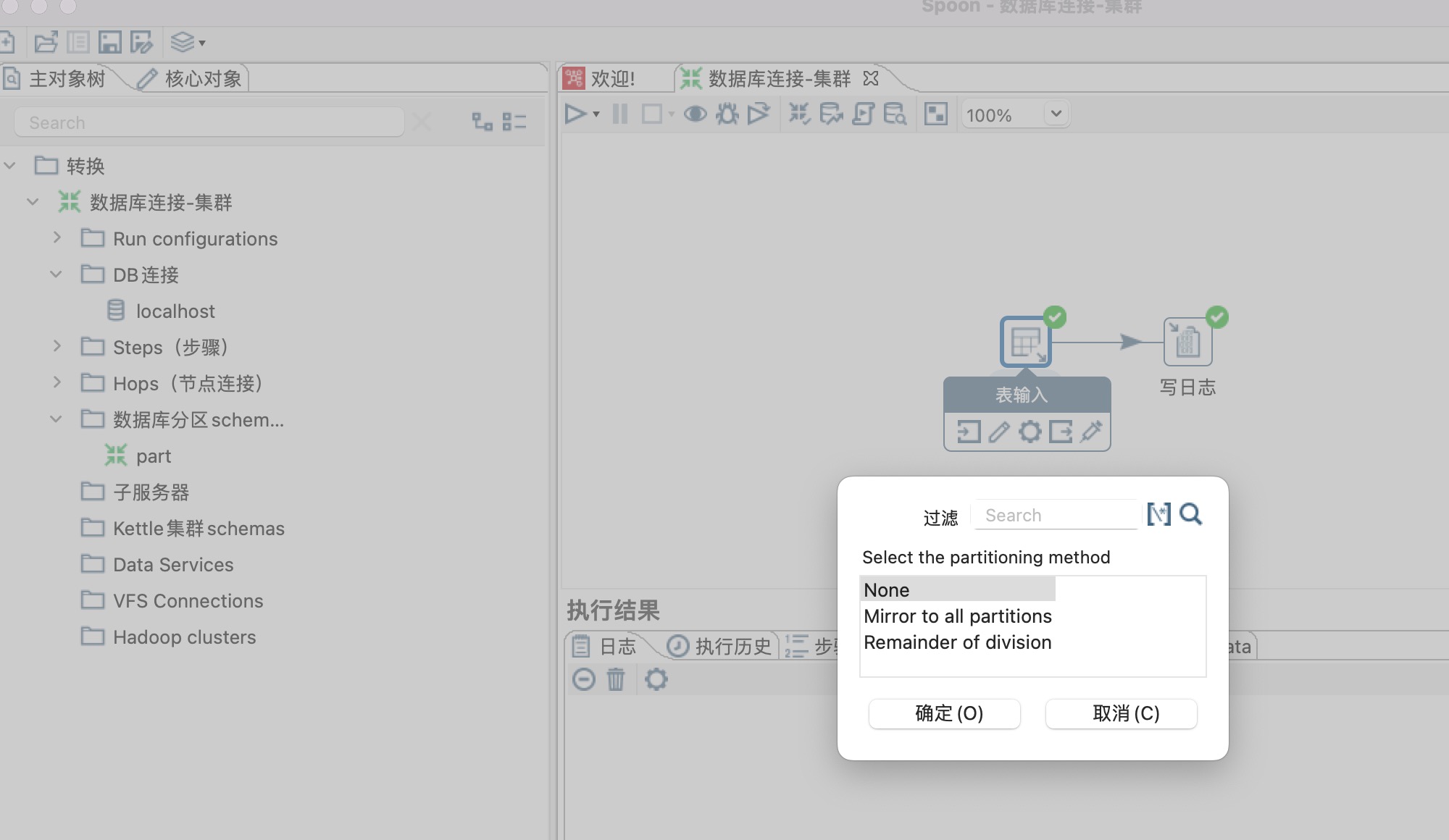
a. None:选择None表示不进行数据分区,即所有数据都将被发送到默认的目标分区中。这意味着不对数据进行分区,将全部数据集中存储在一个分区中。
b. Mirror to all partitions:选择Mirror to all partitions表示将数据镜像复制到所有分区中。无论输入数据来自哪个分区,都会被同时复制到所有可用的分区中,使得每个分区都含有完整的数据集。
c. Remainder of division:选择Remainder of division表示根据某个字段的取余结果将数据分发到不同的分区中。通常情况下,我们会选择一个字段进行取余操作,然后将取余的结果作为分区的标识,这样可以将数据均匀地分布到不同的分区中。
Kettle标准的分区方法。通过分区编号除以分区数目,产生的余数被用来决定记录行将发往哪个分区。例如在一个记录行里,如果有 “3” 标识的用户身份,而且有2个分区定义,这样这个记录行属于分区1
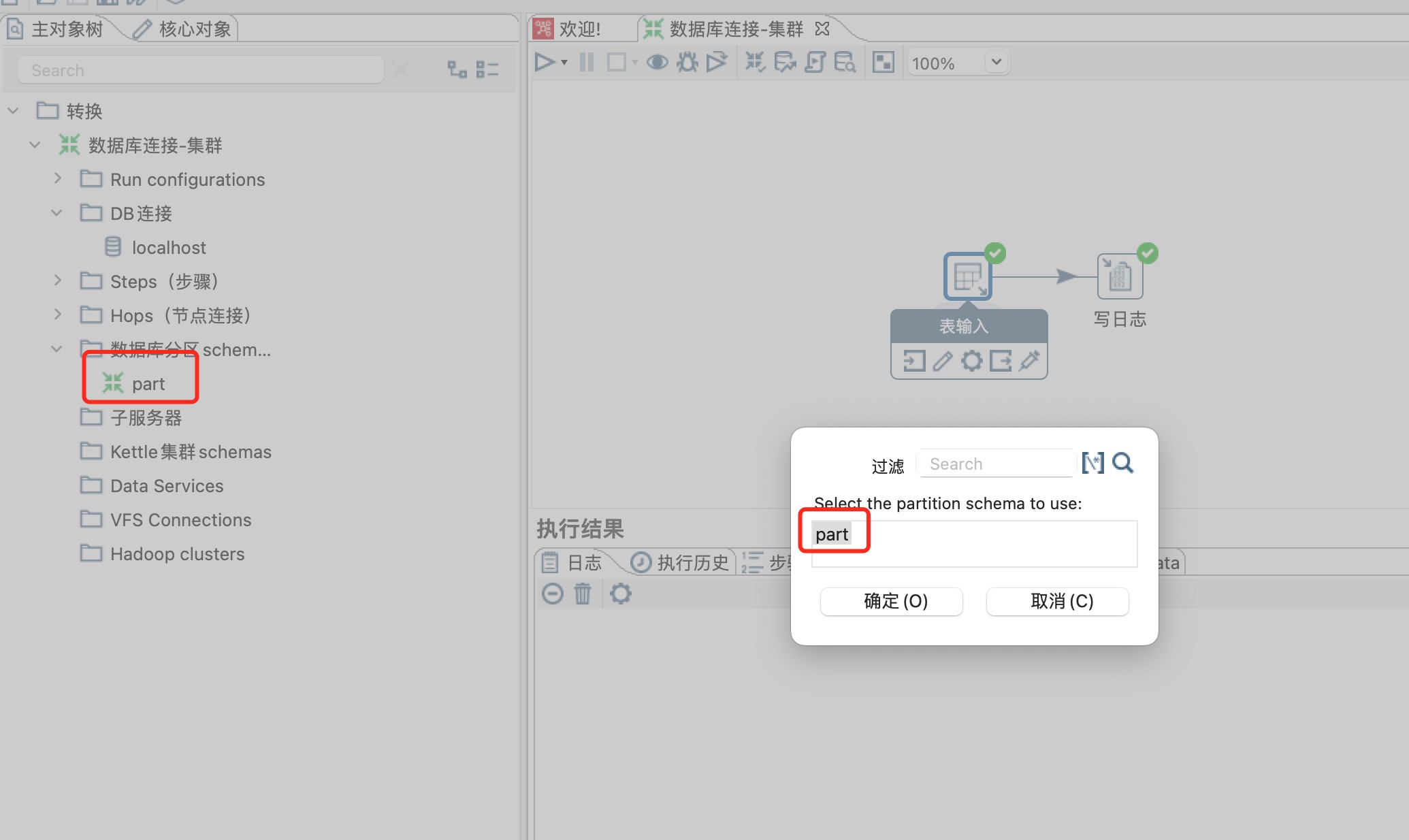
选择设置好的part分区即可,这里的part名字可以根据需要自行定义。
6、设置表输入步骤,如下图所示
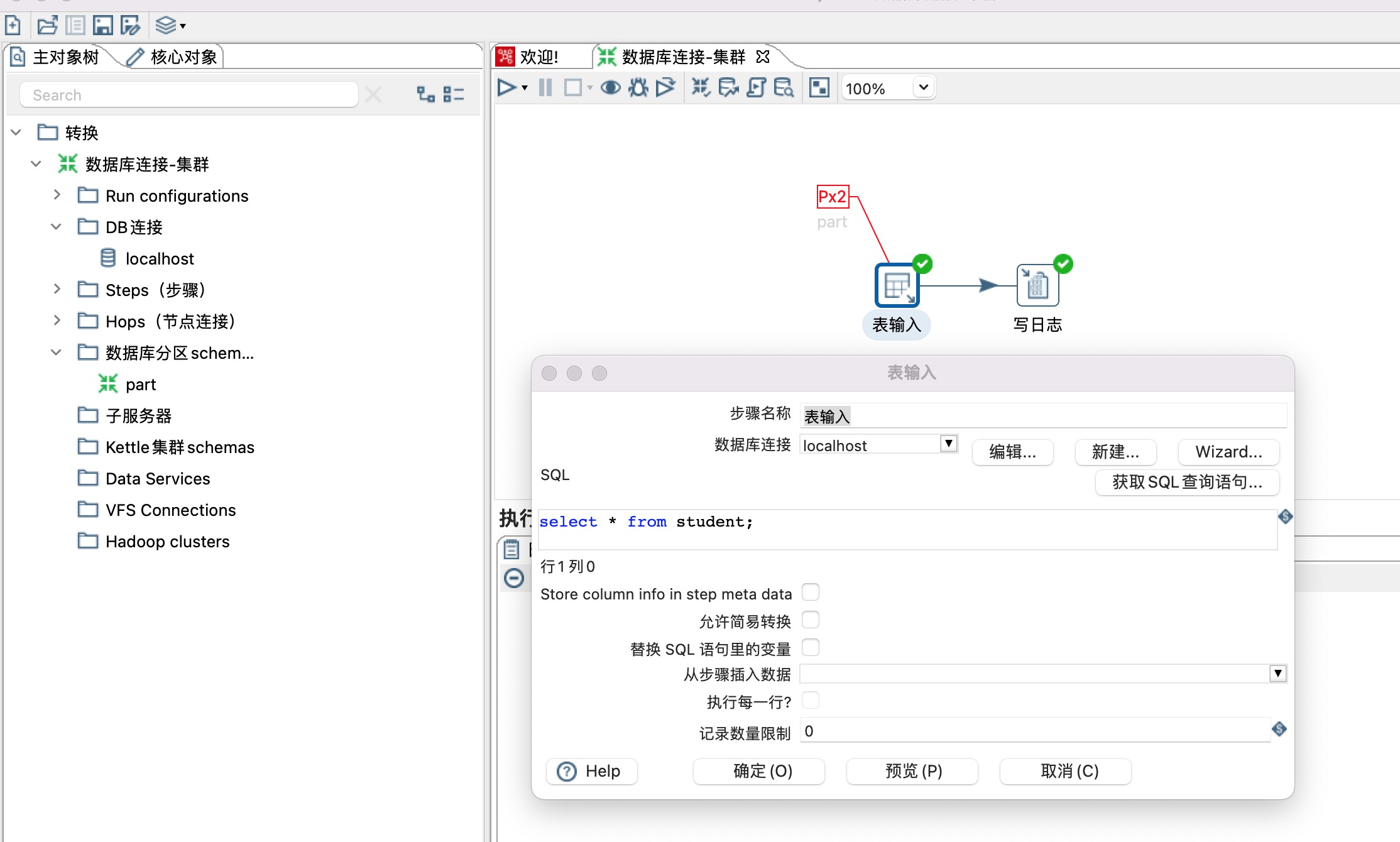
7、分区方式为Mirror to all partitions的情况下,表输入读取两个分区的数据,如下图所示
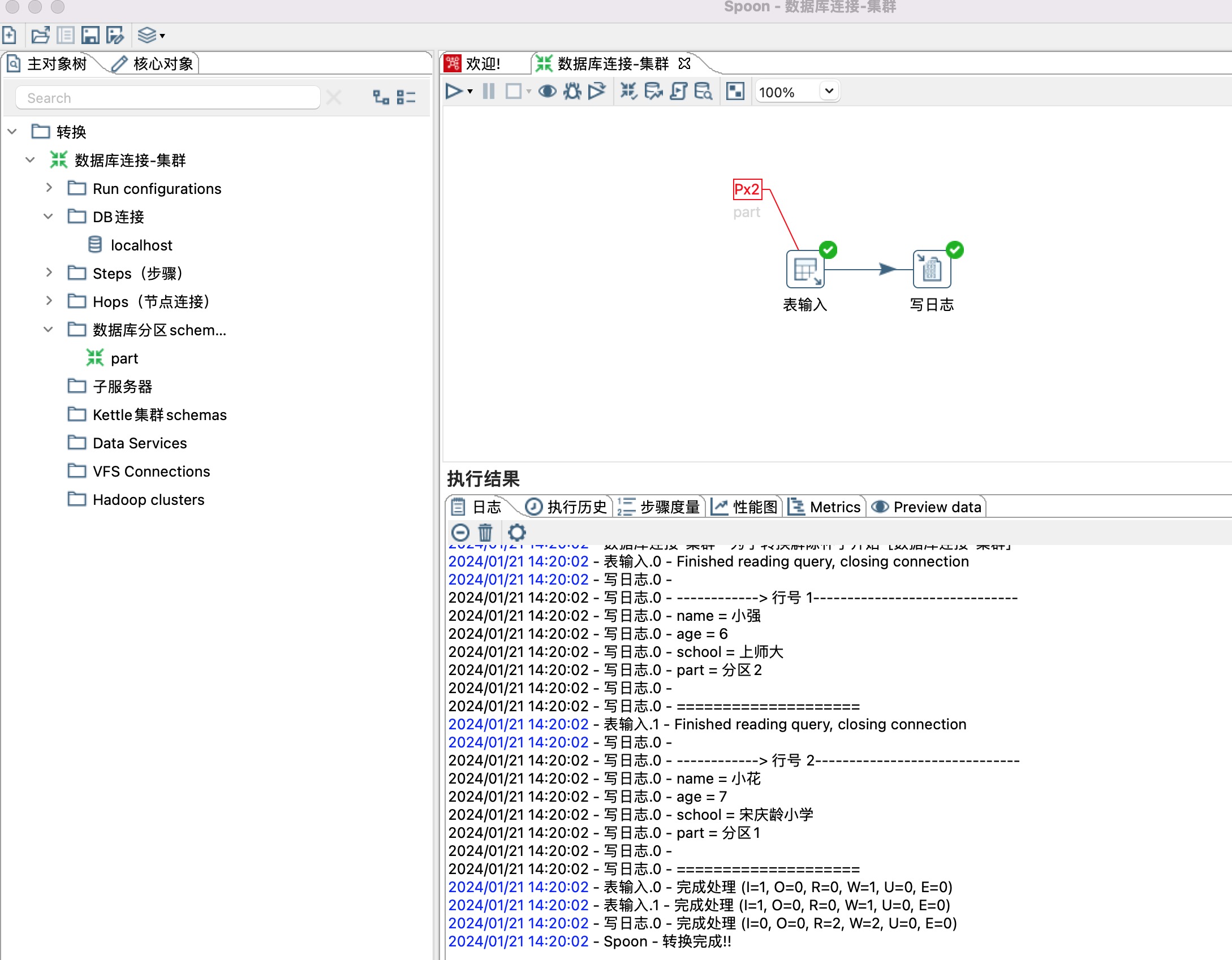
8、两个分区数据转移到一张表里面,如下图所示
另外表输入和输出步骤不熟悉的话,可以查看我之前的文章,里面有详细介绍。
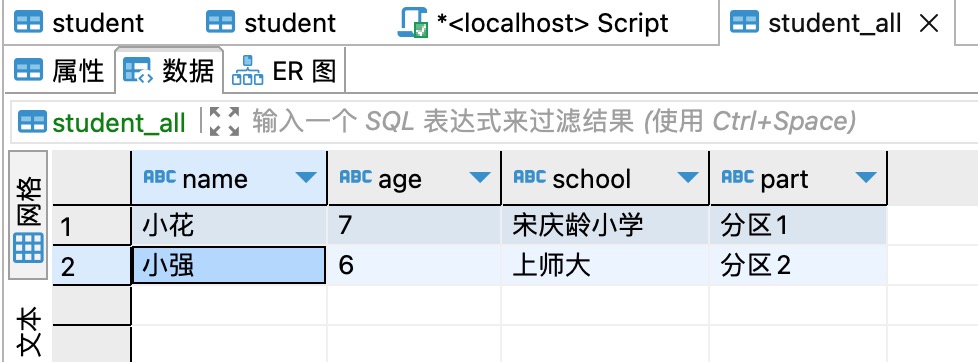
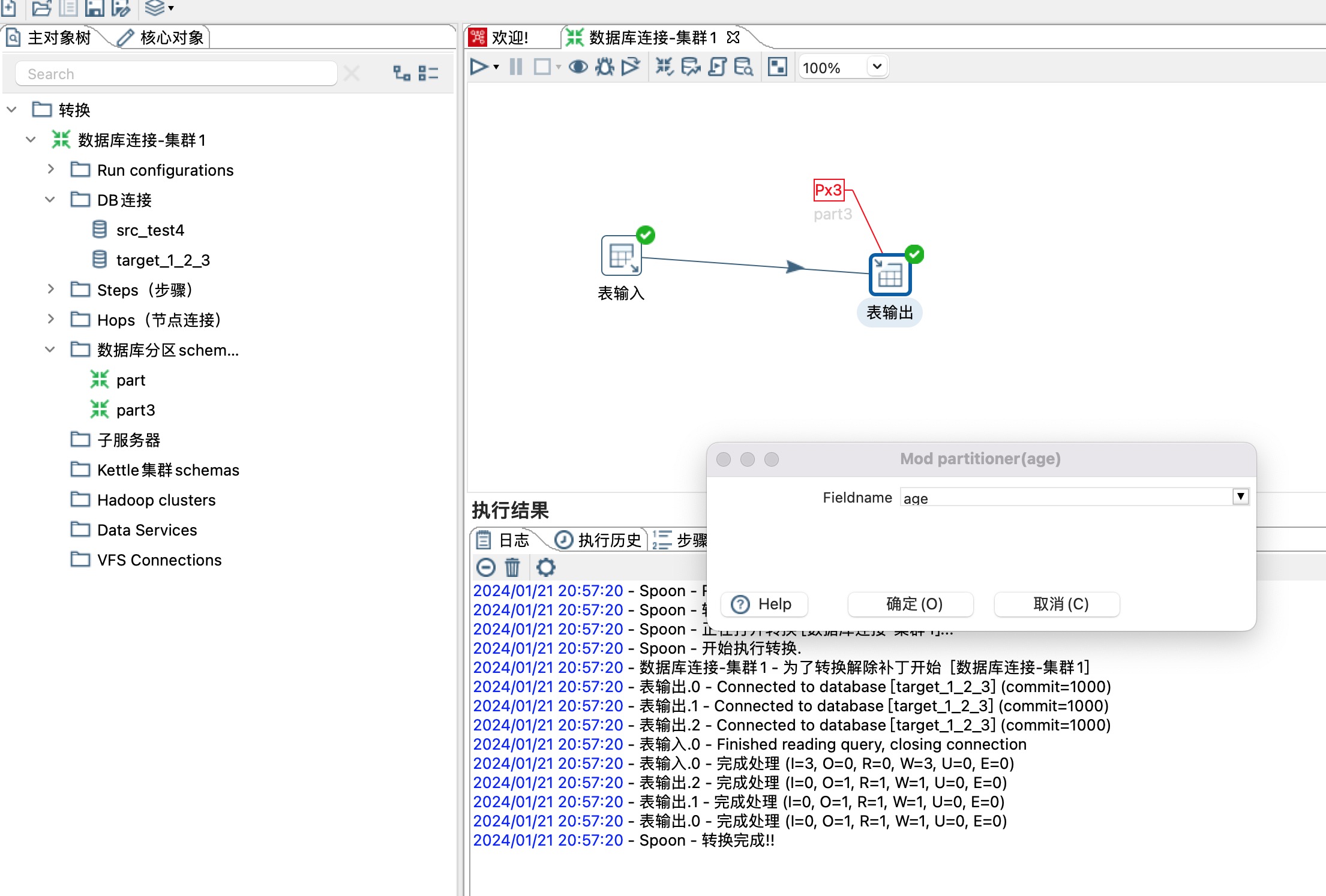
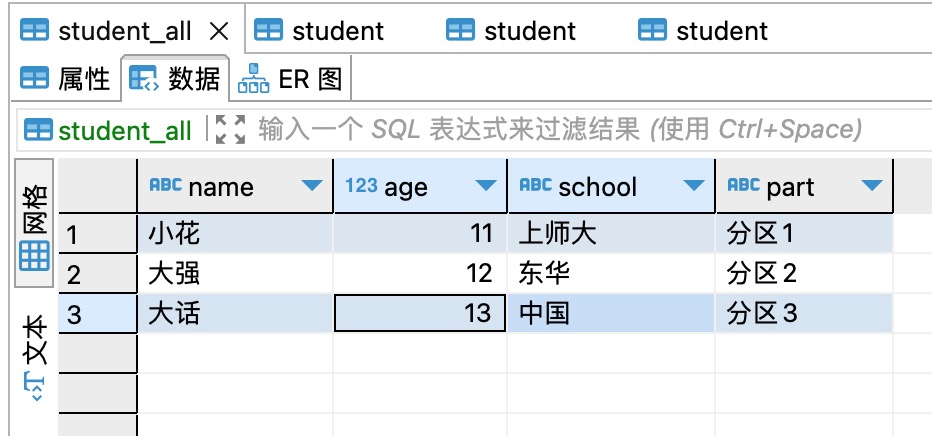
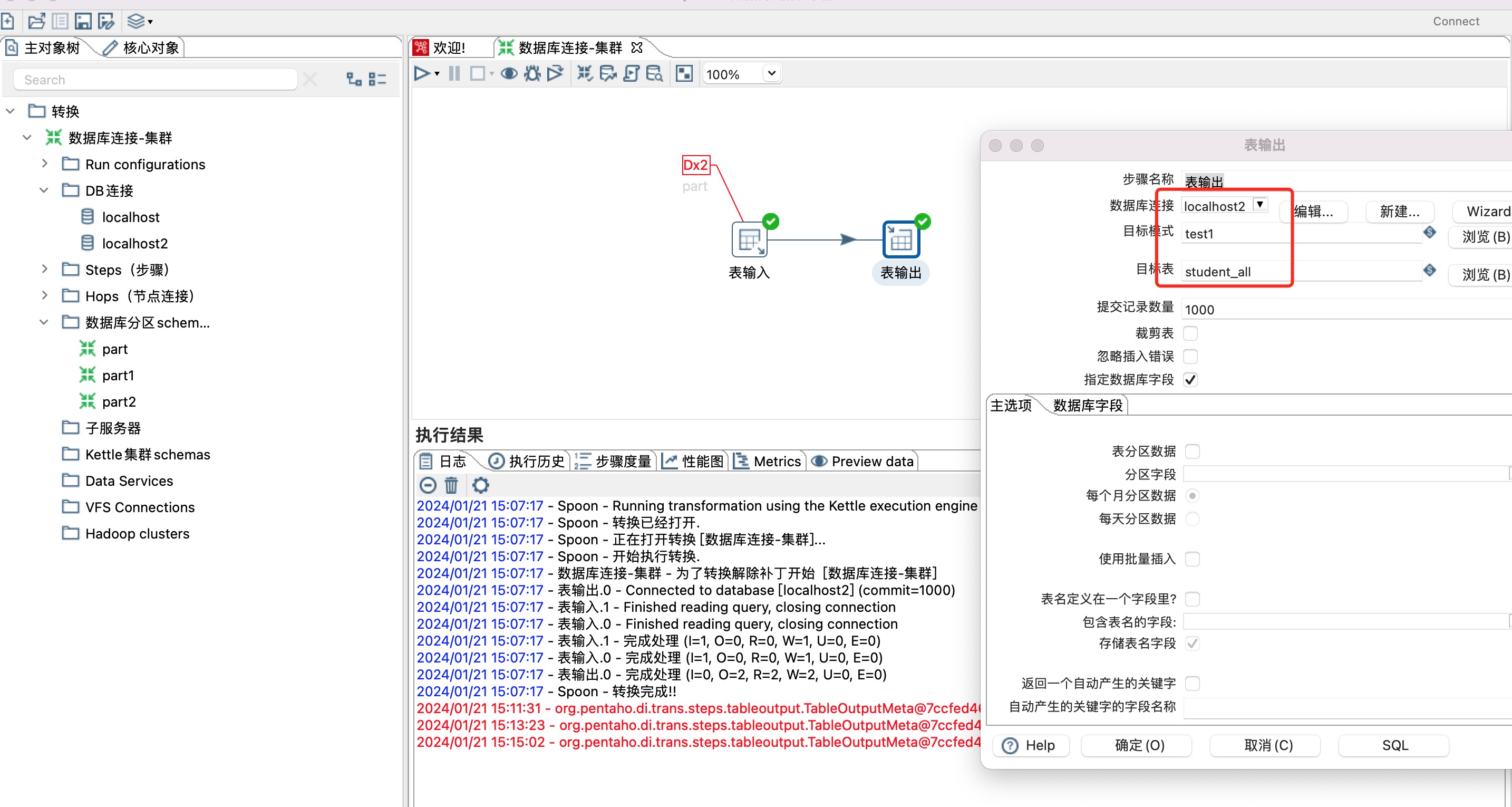
9、一个全量表student_all 中的数据,同步到三个分区的三个student表,如下图所示
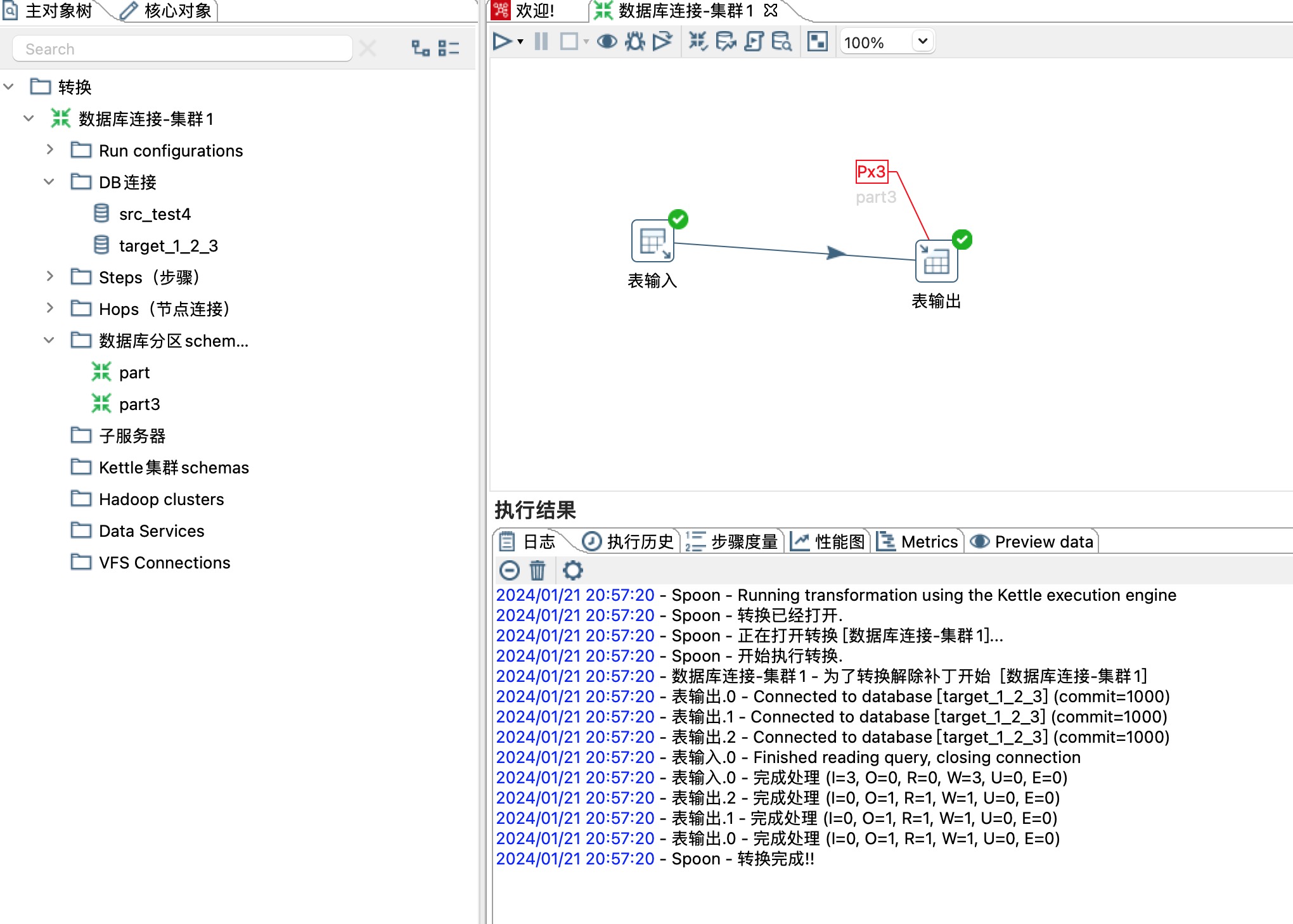
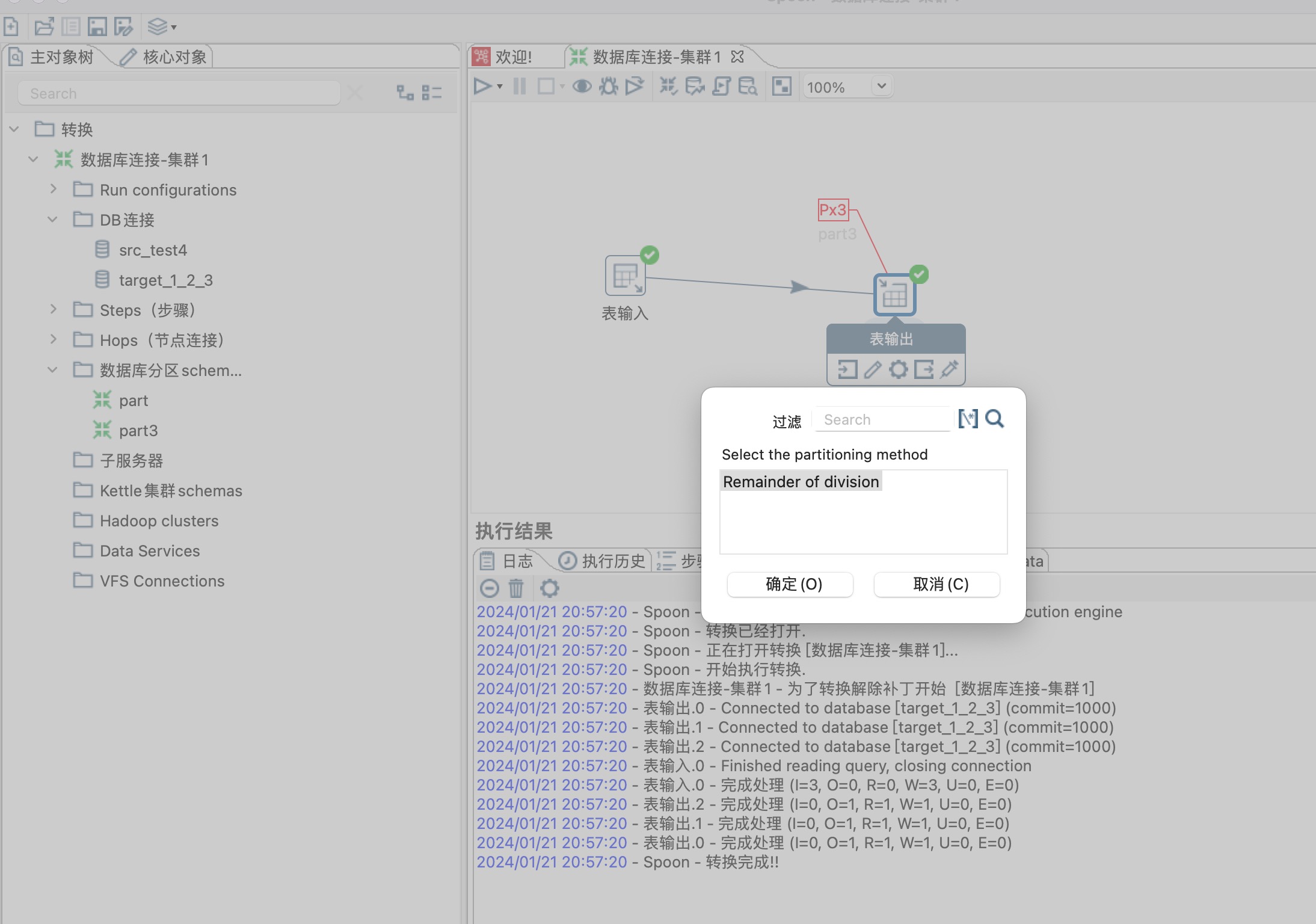
这里分区策略选择Remainder of division,同时选择一个分区路由字段,这里选择age字段,age/分区总数3剩余的商就是数据同步到哪个分区,分区编号从0开始,如下图所示