
kettle从入门到精通 第三十课 mysql 数据连接常用配置
1、我们平常用的最多的数据库就是mysql了,这里我以mysql为例说下数据库连接池配置。为啥要用连接池,因为数据库建立连接很费性能,所以就建立连接池(提前建立好一批连接)缓存起来提高性能。下图中mysql的设置参数,提前是需要把mysql的jar(如mysql-connector-java-8.0.20.jar) 放到kettle 文件夹中的lib目录里面。
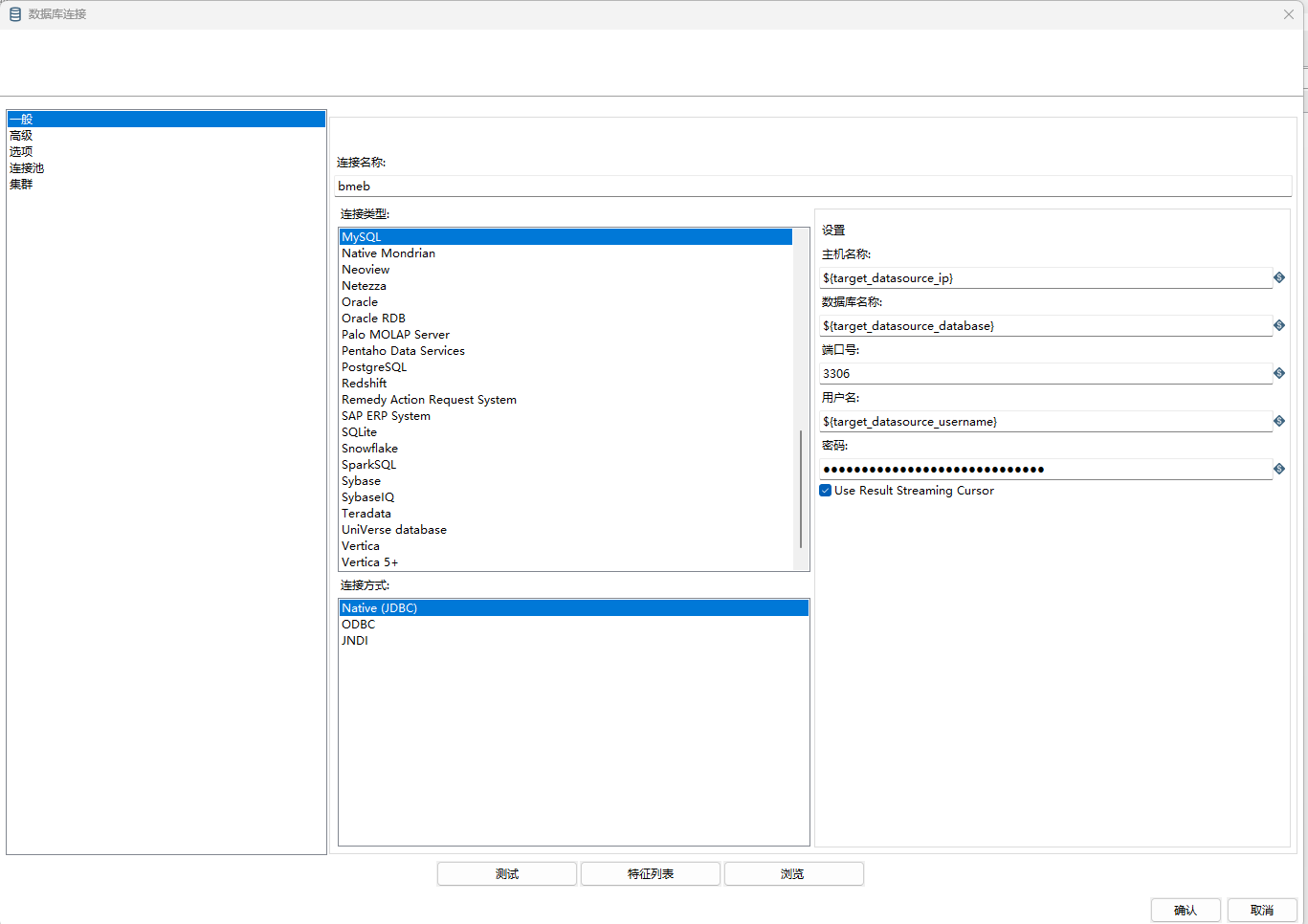
连接名称:自定义名称
连接类型:MySQL
连接方式:Native(JDBC)
主机名称:msyql ip地址
数据库名称:database schema
端口号:数据库端口号,mysql默认是3306
用户名:数据库用户名
密码:数据库密码
Use Result Stream Cursor: USE RESULT 是一种在数据库和客户端之间处理结果集的特性。它通过使用游标(cursor)来将查询结果分块返回给客户端,而不是一次性加载整个结果集到内存中。这对于处理大量数据或结果集很大的情况非常有效,可以减少内存消耗,并允许按需处理结果集的每个分块。建议勾选。
2、高级配置,如下图所示。
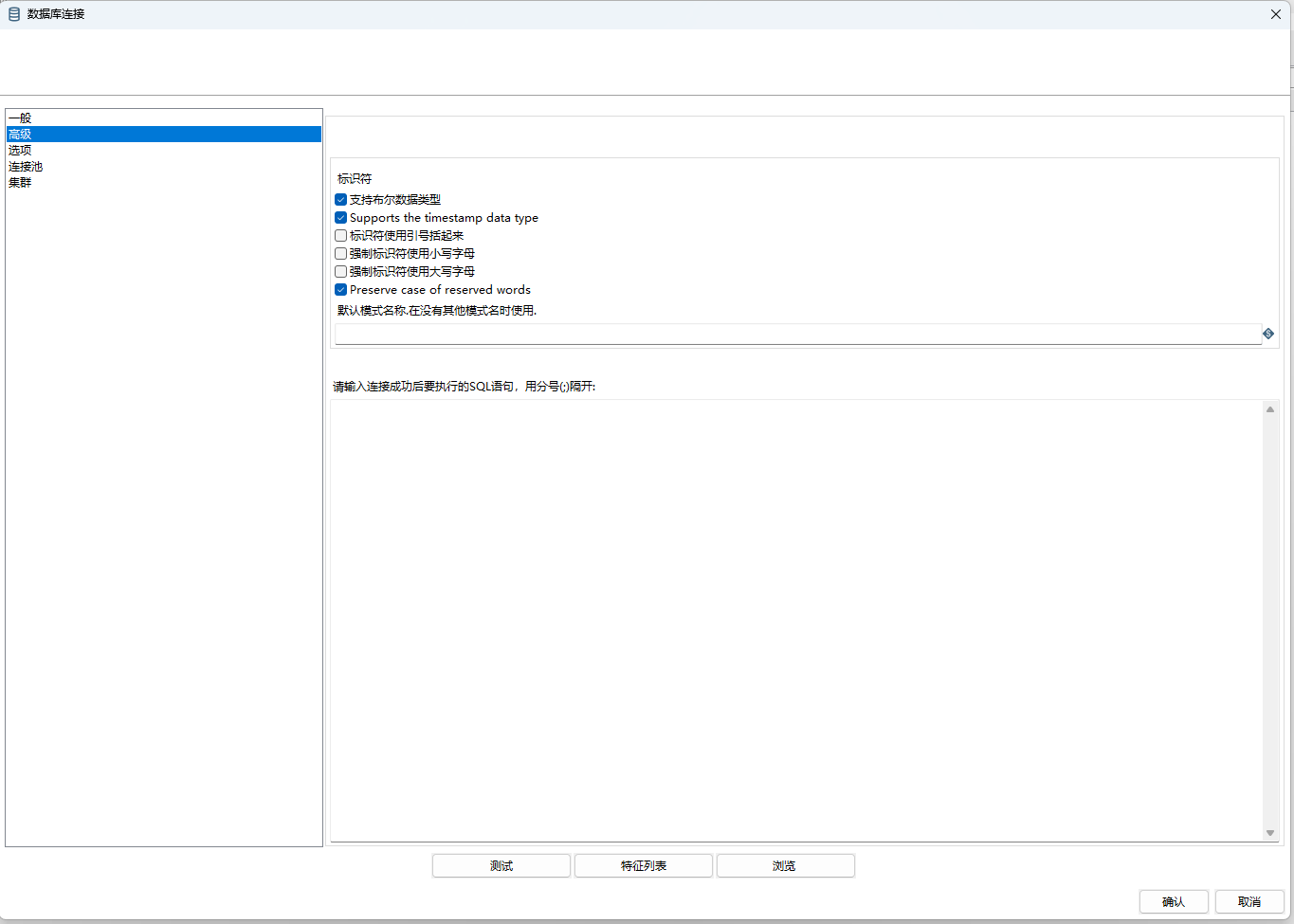
支持布尔数据类型
关系型数据库不直接支持布尔数据类型,而是使用特定的数据类型来表示布尔值,比如在 MySQL 中使用的是 TINYINT(1)。当使用 Kettle 进行数据处理时,需要将布尔值从 Kettle 传递给数据库中的相关列,此时就需要确保数据库连接池能够正确地将布尔类型的值传递给数据库。如果选择了 “支持布尔数据类型”,那么在配置中插入布尔值,连接池会将布尔值转换为数据库支持的数据类型。比如,将布尔值 true 转换为 1,将布尔值 false 转换为 0,以便正确地与数据库进行交互。但如果选择了 “不支持布尔数据类型”,连接池会抛出错误或警告。
Supports the timestamp data type
时间戳数据类型用于存储日期和时间信息,并且在许多数据库中都有特定的数据类型来表示时间戳,例如 MySQL 中的 TIMESTAMP。
如果选择了 “支持时间戳数据类型”,那么在配置中插入的时间戳值会被连接池直接传递给数据库,并且可以正确处理和存储时间戳类型的数据。
标识符使用引号括起来
该选项用于指定在查询和操作数据库对象时,标识符(例如表名、列名等)是否需要使用引号来括起来。
标识符使用引号括起来是一种数据库特定的语法规则,它可以用来处理具有特殊字符或与数据库关键字相同的标识符。当标识符被括在引号中时,数据库会将其视为一个整体,而不是将其解释为关键字或其他特殊含义。
强制标识符使用小写字母
在进行数据库查询和操作时,是否强制将所有的标识符(比如表名、列名等)转换为小写字母进行处理。
在进行数据库查询和操作时,是否强制将所有的标识符(比如表名、列名等)转换为大写字母进行处理。
Preserve case of reserved words
执行数据库操作时,是否保留SQL语句中保留字的大小写。
如果选择了 “Preserve case of reserved words”,那么在执行查询和操作时,Kettle 将保留SQL语句中保留字(如SELECT、FROM、WHERE等)的大小写,不进行额外的转换。这样做可以确保在SQL语句中使用的保留字与数据库系统的预期大小写一致,避免由于大小写不一致而导致的语法错误。
默认模式名称,在没有其他模式名时使用
当执行数据库操作时,如果没有指定模式(也称为数据库架构)的名称,将会使用该选项指定的默认模式名称。
数据库系统中,模式是用于组织和管理数据库对象(如表、视图、存储过程等)的一种方式。不同的数据库系统在模式的实现和规范上可能会有所不同。
请输入连接成功后要执行的sql语句,用分号(;)隔开
这个选项允许你在成功建立数据库连接之后,自动执行一系列的 SQL 语句。这些 SQL 语句可以是任何合法的数据库操作语句,比如查询、更新、插入等。
这个功能通常用于在建立数据库连接后,需要进行一些初始化或准备工作的场景。例如,你可能希望在每次建立连接时都自动进行一些特定的查询或设置一些会话参数。通过配置这个选项,你可以在连接成功后自动执行这些 SQL 语句,而不需要在每次连接后手动执行。
3、选项配置,这里有一些常见的参数可供设置,可根据自己的要求进行设置,如下图所示。
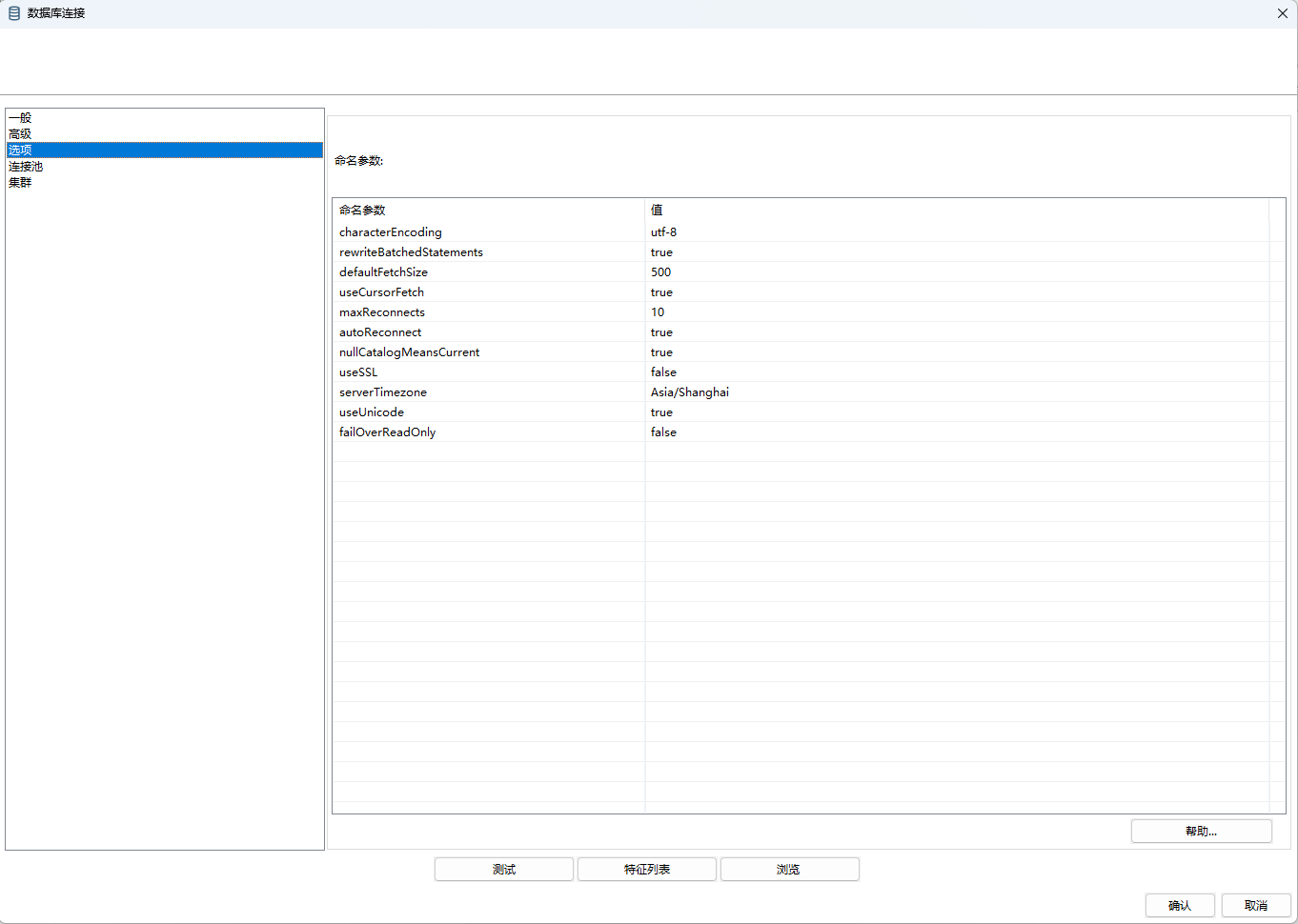
characterEncoding
指定与数据库连接相关联的字符编码的选项,通过配置 “characterEncoding” 选项,你可以指定数据库连接所使用的字符编码。这对于确保正确地读取和写入包含非英文字符的数据非常重要。例如,如果你的数据库中存储了中文字符,那么应该选择相应的字符编码,比如 UTF-8,以确保正确地处理和存储这些字符。
rewriteBatchedStatements
用于指定是否启用批处理写入的选项。批处理写入是一种优化技术,用于在一次数据库操作中批量插入多条记录,从而减少与数据库的交互次数,提高写入性能。当启用 “rewriteBatchedStatements” 选项时,Kettle 在向数据库提交批处理写入时,会尝试重写相应的 SQL 语句,把多条插入操作合并成一条批量插入的语句,以减少通信开销和提升性能。
defaultFetchSize
用于指定默认的数据获取大小的选项。数据获取大小指的是每次从数据库中读取的记录数。当你执行查询操作时,数据库将会返回一个结果集,其中包含满足查询条件的所有记录。“defaultFetchSize” 选项允许你设置每次从结果集中获取的记录数,以控制内存和网络资源的使用。
useCursorFetch
用于指定是否启用游标获取的选项。当启用 “useCursorFetch” 选项时,Kettle 将会使用数据库游标来获取查询结果集,而不是一次性将整个结果集加载到内存中。这种方式可以减少内存的占用,特别是在处理大型结果集时,同时还可以提高查询性能,因为数据库不需要一次性返回所有结果,而是可以按需获取数据。
maxReconnects
maxReconnects 属性定义了最大重新连接的尝试次数。默认情况下,该属性的值为0,表示不进行重新连接尝试。如果将 maxReconnects 设置为正整数值(例如,maxReconnects=3),则当数据库连接断开时,Kettle将尝试重新连接数据库的次数,当达到最大尝试次数后仍然无法重新连接时,Kettle会放弃尝试并抛出错误。
autoReconnect
数据库连接池的 autoReconnect 属性用于指示是否在连接断开时自动尝试重新建立连接。当数据库连接断开时,设置 autoReconnect 为 true 会告诉连接池自动尝试重新建立连接,而不需要用户手动介入
nullCatalogMeansCurrent
该参数用于指示是否将连接的目录设置为当前目录。当该参数设置为true时,表示连接的目录将被视为当前目录,而当设置为false时,将不会将连接的目录视为当前目录。
"当前目录"是指在数据库中执行操作时所处的默认目录或架构。数据库中的表、视图等对象可以根据不同的目录进行组织和管理。当连接到数据库时,如果将连接的目录设置为当前目录,那么执行的操作将默认在当前目录下进行。
useSSL
该参数用于指示是否使用SSL(Secure Sockets Layer)加密协议来加密数据库连接。当该参数设置为true时,表示数据库连接将使用SSL进行加密,而当设置为false时,则表示不使用SSL加密。
serverTimezone
该参数用于指定数据库服务器所在的时区,作用是确保在数据库操作中正确处理和转换时间,以与数据库服务器所在的时区保持一致。如"Asia/Shanghai"。
useUnicode
Unicode是一种国际标准,它定义了字符的编码方式,包括了各种语言中的字符集。使用Unicode编码可以支持全球范围内的多种语言和字符集,包括非拉丁字母、特殊符号和表情符号等。
通过设置"useUnicode"参数为true,Kettle 9.3会使用Unicode编码来处理数据库连接中的字符数据。这意味着无论数据库中存储的是哪种语言的字符,都可以正确地进行存储、检索和处理,避免出现乱码或字符转换错误的问题。
failOverReadOnly
当数据库服务器发生故障或不可用时,连接池需要有相应的应对措施来继续提供服务。通过设置"failOverReadOnly"参数,可以控制连接池在故障发生时对只读操作的处理方式。
如果将"failOverReadOnly"参数设置为true,那么连接池在发生故障时只会将只读操作(如SELECT查询)重定向到备用节点或其他可用的数据库服务器上,而对写操作(如UPDATE、INSERT、DELETE)则会直接抛出异常或其他错误提示。这样可以在一定程度上保证只读操作的连续性,同时避免对写入操作造成的数据不一致性。
反之,如果将"failOverReadOnly"参数设置为false,那么连接池在发生故障时会将所有的操作都重定向到备用节点或其他可用的数据库服务器上,无论是只读操作还是写入操作。这样虽然可以在故障期间继续提供服务,但可能会对故障恢复后的数据一致性产生影响。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端