mysql的binlog
Binlog概述
Binlog用途:
结构解析
索引文件
Binlog 文件
文件头
事件
Binlog 事件类型
事件类型
事件的结构
事件头
事件体
格式描述事件
跳转事件ROTATE_EVENT
各种不同的事件体
什么时候记录BinLog
BinLog记录的三种模式
BinLog处理事务和非事务性语句区别
操作
BinLog文件操作
BinLong文件创建/刷新
BinLong文件删除
方法一:设置参数自动删除binlog
方法二:按照时间删除binlog日志
BinLog内容查询操作
使用shell命令mysqlbinlog
BinLog常见的时间选项
使用mysql命令
binlog日志恢复命令
案例:利用binlog日志恢复mysql数据
对ops库的member表进行操作,并且再创建一个库ops1
进行场景模拟
破坏操作查询
上次全备份数据恢复
从binlog日志恢复数据
方法1:完全恢复(此方法测试未通过)
指定pos结束点恢复(部分恢复)
定时间节点区间恢复(部分恢复)
总结
MySQL的Binlog
参考:
- https://segmentfault.com/a/1190000003072963
- http://www.linuxidc.com/Linux/2014-09/107095.htm
- https://blog.csdn.net/lzhcoder/article/details/88814364
- https://blog.csdn.net/lzh_00/article/details/90299354
- https://baijiahao.baidu.com/s?id=1613946893411582653&wfr=spider&for=pc
- https://blog.csdn.net/wwwdc1012/article/details/88373440
Binlog概述
- binlog是记录所有数据库表结构变更(例如CREATE、ALTER TABLE…)以及表数据修改(INSERT、UPDATE、DELETE…)的二进制日志。
- binlog不会记录SELECT和SHOW这类操作,因为这类操作对数据本身并没有修改,但你可以通过查询通用日志来查看MySQL执行过的所有语句。
- 二进制日志包括两类文件:
- 二进制日志索引文件(文件名后缀为
.index)用于记录所有的二进制文件, - 二进制日志文件(文件名后缀为
.00000*)记录数据库所有的DDL和DML(除了数据查询语句)语句事件。
- 二进制日志索引文件(文件名后缀为
binlog基本定义:二进制日志,记录对数据发生或潜在发生更改的SQL语句,并以二进制的形式保存在磁盘中;
一般来说开启binlog日志大概会有1%的性能损耗。
MySQL Server有四种类型的日志:
| 日志类型 | 写入日志的信息 |
|---|---|
错误日志Error Log |
当数据库启动、运行、停止时出现问题产生该日志 |
通用查询日志General Query Log |
记录建立的客户端连接和执行的语句 |
二进制日志Binary Log |
记录更改数据的语句,数据库内容发生改变时产生该日志,也被用来实现主从复制功能 |
中继日志relay log |
主从复制时,从库上收到主库的数据更新时产生该日志 |
慢查询日志Slow Query Log |
记录所有执行时间超过 long_query_time 秒的所有查询或不使用索引的查询 |
DDL日志(元数据日志)metadata log |
执行DDL语句操作元数据时产生该日志 |
Binlog用途:
MySQL的作用类似于Oracle的归档日志,可以用来查看数据库的变更历史(具体的时间点所有的SQL操作)、数据库增量备份和恢复(增量备份和基于时间点的恢复)、Mysql的复制(主主数据库的复制、主从数据库的复制)
最重要的使用场景
- MySQL主从复制:MySQL Replication在Master端开启binlog,Master把它的二进制日志传递给slaves来达到master-slave数据一致的目的
- 数据恢复:通过使用 mysqlbinlog工具来使恢复数据
结构解析
索引文件
索引文件就是上文中的 master-bin.index 文件,是一个普通的文本文件,以换行为间隔,一行一个文件名。比如它可能是:
master-bin.000001master-bin.000002master-bin.000003
对应的每行文件就是一个 Binlog 实体文件了。
Binlog 文件
Binlog 的文件结构大致由如下几个方面组成:
文件头
文件头由一个四字节Magic Number,其值为 1852400382,在内存中就是 "\xfe\x62\x69\x6e",参考 MySQL 源码的 log_event.h,也就是 '\0xfe' 'b' 'i' 'n'。
与平常二进制一样,通常都有一个 Magic Number 进行文件识别,如果 Magic Number 不吻合上述的值那么这个文件就不是一个正常的 Binlog。
事件
Binlog 事件类型
- v1,用于 MySQL 3.2.3
- v3,用于 MySQL 4.0.2 以及 4.1.0
- v4,用于 MySQL 5.0 以及更高版本
实际上还有一个 v2 版本,不过只在早期 4.0.x 的 MySQL 版本中使用过,但是 v2 已经过于陈旧并且不再被 MySQL 官方支持了。
通常我们现在用的 MySQL 都是在 5.0 以上的了,所以就略过 v1 ~ v3 版本的 Binlog,如果需要了解 v1 ~ v3 版本的 Binlog 可以自行前往上述的《High-level...》文章查看。
事件类型
| 事件类型 | 说明 |
|---|---|
| UNKNOWN_EVENT | 此事件从不会被触发,也不会被写入binlog中;发生在当读取binlog时,不能被识别其他任何事件,那被视为UNKNOWN_EVENT |
| START_EVENT_V3 | 每个binlog文件开始的时候写入的事件,此事件被用在MySQL3.23 – 4.1,MYSQL5.0以后已经被 FORMAT_DESCRIPTION_EVENT 取代 |
| QUERY_EVENT | 执行更新语句时会生成此事件,包括:create,insert,update,delete; |
| STOP_EVENT | 当mysqld停止时生成此事件 |
| ROTATE_EVENT | 当mysqld切换到新的binlog文件生成此事件,切换到新的binlog文件可以通过执行flush logs命令或者binlog文件大于 max_binlog_size 参数配置的大小; |
| INTVAR_EVENT | 当sql语句中使用了AUTO_INCREMENT的字段或者LAST_INSERT_ID()函数;此事件没有被用在binlog_format为ROW模式的情况下 |
| LOAD_EVENT | 执行LOAD DATA INFILE 语句时产生此事件,在MySQL 3.23版本中使用 |
| SLAVE_EVENT | 未使用 |
| CREATE_FILE_EVENT | 执行LOAD DATA INFILE 语句时产生此事件,在MySQL4.0和4.1版本中使用 |
| APPEND_BLOCK_EVENT | 执行LOAD DATA INFILE 语句时产生此事件,在MySQL4.0版本中使用 |
| EXEC_LOAD_EVENT | 执行LOAD DATA INFILE 语句时产生此事件,在MySQL4.0和4.1版本中使用 |
| DELETE_FILE_EVENT | 执行LOAD DATA INFILE 语句时产生此事件,在MySQL4.0版本中使用 |
| NEW_LOAD_EVENT | 执行LOAD DATA INFILE 语句时产生此事件,在MySQL4.0和4.1版本中使用 |
| RAND_EVENT | 执行包含RAND()函数的语句产生此事件,此事件没有被用在binlog_format为ROW模式的情况下 |
| USER_VAR_EVENT | 执行包含了用户变量的语句产生此事件,此事件没有被用在binlog_format为ROW模式的情况下 |
| FORMAT_DESCRIPTION_EVENT | 描述事件,被写在每个binlog文件的开始位置,用在MySQL5.0以后的版本中,代替了START_EVENT_V3 |
| XID_EVENT | 支持XA的存储引擎才有,本地测试的数据库存储引擎是innodb,所有上面出现了XID_EVENT;innodb事务提交产生了QUERY_EVENT的BEGIN声明,QUERY_EVENT以及COMMIT声明,如果是myIsam存储引擎也会有BEGIN和COMMIT声明,只是COMMIT类型不是XID_EVENT |
| BEGIN_LOAD_QUERY_EVENT | 执行LOAD DATA INFILE 语句时产生此事件,在MySQL5.0版本中使用 |
| EXECUTE_LOAD_QUERY_EVENT | 执行LOAD DATA INFILE 语句时产生此事件,在MySQL5.0版本中使用 |
| TABLE_MAP_EVENT | 用在binlog_format为ROW模式下,将表的定义映射到一个数字,在行操作事件之前记录(包括:WRITE_ROWS_EVENT,UPDATE_ROWS_EVENT,DELETE_ROWS_EVENT) |
| PRE_GA_WRITE_ROWS_EVENT | 已过期,被 WRITE_ROWS_EVENT 代替 |
| PRE_GA_UPDATE_ROWS_EVENT | 已过期,被 UPDATE_ROWS_EVENT 代替 |
| PRE_GA_DELETE_ROWS_EVENT | 已过期,被 DELETE_ROWS_EVENT 代替 |
| WRITE_ROWS_EVENT | 用在binlog_format为ROW模式下,对应 insert 操作 |
| UPDATE_ROWS_EVENT | 用在binlog_format为ROW模式下,对应 update 操作 |
| DELETE_ROWS_EVENT | 用在binlog_format为ROW模式下,对应 delete 操作 |
| INCIDENT_EVENT | 主服务器发生了不正常的事件,通知从服务器并告知可能会导致数据处于不一致的状态 |
| HEARTBEAT_LOG_EVENT | 主服务器告诉从服务器,主服务器还活着,不写入到日志文件中 |
事件的结构
在文件头之后,跟随的是一个一个事件依次排列。每个事件都由一个事件头和事件体组成。
事件头:里面的内容包含了这个事件的类型(如新增、删除等)、事件执行时间以及是哪个服务器执行的事件等信息。
第一个事件是一个事件描述符,描述了这个 Binlog 文件格式的版本。接下去的一堆事件将会按照第一个事件描述符所描述的结构版本进行解读。最后一个事件是一个衔接事件,指定了下一个 Binlog 文件名——有点类似于链表里面的 next 指针。
根据《[High-Level Binary Log Structure and Contents](High-Level Binary Log Structure and Contents)》所述,不同版本的 Binlog 格式不一定一样,所以也没有一个定性。在我写这篇文章的时候,目前有三种版本的格式。
+=====================================+| event | timestamp 0 : 4 || header +----------------------------+| | type_code 4 : 1 || +----------------------------+| | server_id 5 : 4 || +----------------------------+| | event_length 9 : 4 || +----------------------------+| | next_position 13 : 4 || +----------------------------+| | flags 17 : 2 || +----------------------------+| | extra_headers 19 : x-19 |+=====================================+| event | fixed part x : y || data +----------------------------+| | variable part |+=====================================+
如果事件头的长度是 x 字节,那么事件体的长度为 (event_length - x) 字节;设事件体中 fixed part 的长度为 y 字节,那么 variable part 的长度为 (event_length - (x + y)) 字节
事件头
一个事件头有 19 字节,依次排列为
- 四字节的时间戳、
- 一字节的当前事件类型、
- 四字节的服务端 ID、
- 四字节的当前事件长度描述、
- 四字节的下个事件位置(方便跳转)
- 两字节的标识
用 ASCII Diagram 表示如下:
+---------+---------+---------+------------+-------------+-------+|timestamp|type code|server_id|event_length|next_position|flags ||4 bytes |1 byte |4 bytes |4 bytes |4 bytes |2 bytes|+---------+---------+---------+------------+-------------+-------+
也可以字节编造一个结构体来解读这个头:
struct BinlogEventHeader{int timestamp;char type_code;int server_id;int event_length;int next_position;char flags[2];};
如果你要直接用这个结构体来读取数据的话,需要加点手脚。
因为默认情况下 GCC 或者 G++ 编译器会对结构体进行字节对齐,这样读进来的数据就不对了,因为 Binlog 并不是对齐的。为了统一我们需要取消这个结构体的字节对齐,一个方法是使用
#pragma pack(n),一个方法是使用__attribute__((__packed__)),还有一种情况是在编译器编译的时候强制把所有的结构体对齐取消,即在编译的时候使用fpack-struct参数,如:
$ g++ temp.cpp -o a -fpack-struct=1
根据上述的结构我们可以明确得到各变量在结构体里面的偏移量,所以在 MySQL 源码里面(libbinlogevents/include/binlog_event.h)有下面几个常量以快速标记偏移:
#define EVENT_TYPE_OFFSET 4#define SERVER_ID_OFFSET 5#define EVENT_LEN_OFFSET 9#define LOG_POS_OFFSET 13#define FLAGS_OFFSET 17
而具体有哪些事件则在 libbinlogevents/include/binlog_event.h#L245 里面被定义。如有个 FORMAT_DESCRIPTION_EVENT 事件的 type_code 是 15、UPDATE_ROWS_EVENT 的 type_code 是 31。
还有那个 next_position,在 v4 版本中代表从 Binlog 一开始到下一个事件开始的偏移量,比如到第一个事件的 next_position 就是 4,因为文件头有一个字节的长度。然后接下去对于事件 n 和事件 n + 1 来说,他们有这样的关系:
next_position(n + 1) = next_position(n) + event_length(n)
关于 flags 暂时不需要了解太多,如果真的想了解的话可以看看 MySQL 的相关官方文档。
事件体
事实上在 Binlog 事件中应该是有三个部分组成,header、post-header 和 payload,不过通常情况下我们把 post-header 和 payload 都归结为事件体,实际上这个 post-header 里面放的是一些定长的数据,只不过有时候我们不需要特别地关心。想要深入了解可以去查看 MySQL 的官方文档。
所以实际上一个真正的事件体由两部分组成,用 ASCII Diagram 表示就像这样:
+=====================================+| event | fixed part (post-header) || data +----------------------------+| | variable part (payload) |+=====================================+
而这个 post-header 对于不同类型的事件来说长度是不一样的,同种类型来说是一样的,而这个长度的预先规定将会在一个“格式描述事件”中定好。
从一个最简单的实例来分析Event,包括创建表,插入数据,更新数据,删除数据;
CREATE TABLE `test` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`age` int(11) DEFAULT NULL,`name` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;insert into test values(1,22,"小旋锋");update test set name='whirly' where id=1;delete from test where id=1;
格式描述事件
在上文我们有提到过,在 Magic Number 之后跟着的是一个格式描述事件(Format Description Event),其实这只是在 v4 版本中的称呼,在以前的版本里面叫起始事件(Start Event)。
在 v4 版本中这个事件的结构如下面的 ASCII Diagram 所示。
+=====================================+| event | timestamp 0 : 4 || header +----------------------------+| | type_code 4 : 1 | = FORMAT_DESCRIPTION_EVENT = 15| +----------------------------+| | server_id 5 : 4 || +----------------------------+| | event_length 9 : 4 | >= 91| +----------------------------+| | next_position 13 : 4 || +----------------------------+| | flags 17 : 2 |+=====================================+| event | binlog_version 19 : 2 | = 4| data +----------------------------+| | server_version 21 : 50 || +----------------------------+| | create_timestamp 71 : 4 || +----------------------------+| | header_length 75 : 1 || +----------------------------+| | post-header 76 : n | = array of n bytes, one byte per event| | lengths for all | type that the server knows about| | event types |+=====================================+
这个事件的 type_code 是 15,然后 event_length 是大于等于 91 的值的,这个主要取决于所有事件类型数。
因为从第 76 字节开始后面的二进制就代表一个字节类型的数组了,一个字节代表一个事件类型的 post-header 长度,即每个事件类型固定数据的长度。
那么按照上述的一些线索来看,我们能非常快地写出一个简单的解读 Binlog 格式描述事件的代码。
如上文所述,如果需要正常解读 Binlog 文件的话,下面的代码编译时候需要加上
-fpack-struct=1这个参数。
#include <cstdio>#include <cstdlib>struct BinlogEventHeader{int timestamp;unsigned char type_code;int server_id;int event_length;int next_position;short flags;};int main(){FILE* fp = fopen("/usr/local/var/mysql/master-bin.000001", "rb");int magic_number;fread(&magic_number, 4, 1, fp);printf("%d - %s\n", magic_number, (char*)(&magic_number));struct BinlogEventHeader format_description_event_header;fread(&format_description_event_header, 19, 1, fp);printf("BinlogEventHeader\n{\n");printf(" timestamp: %d\n", format_description_event_header.timestamp);printf(" type_code: %d\n", format_description_event_header.type_code);printf(" server_id: %d\n", format_description_event_header.server_id);printf(" event_length: %d\n", format_description_event_header.event_length);printf(" next_position: %d\n", format_description_event_header.next_position);printf(" flags[]: %d\n}\n", format_description_event_header.flags);short binlog_version;fread(&binlog_version, 2, 1, fp);printf("binlog_version: %d\n", binlog_version);char server_version[51];fread(server_version, 50, 1, fp);server_version[50] = '\0';printf("server_version: %s\n", server_version);int create_timestamp;fread(&create_timestamp, 4, 1, fp);printf("create_timestamp: %d\n", create_timestamp);char header_length;fread(&header_length, 1, 1, fp);printf("header_length: %d\n", header_length);int type_count = format_description_event_header.event_length - 76;unsigned char post_header_length[type_count];fread(post_header_length, 1, type_count, fp);for(int i = 0; i < type_count; i++){printf(" - type %d: %d\n", i + 1, post_header_length[i]);}return 0;}
这个时候你得到的结果有可能就是这样的了:
1852400382 - �binpz�BinlogEventHeader{timestamp: 1439186734type_code: 15server_id: 1event_length: 116next_position: 120flags[]: 1}binlog_version: 4server_version: 5.6.24-logcreate_timestamp: 1439186734header_length: 19- type 1: 56- type 2: 13- type 3: 0- type 4: 8- type 5: 0- type 6: 18- ...
一共会输出 40 种类型(从 1 到 40),如官方文档所说,这个数组从 START_EVENT_V3 事件开始(type_code 是 1)。
跳转事件ROTATE_EVENT
跳转事件即 ROTATE_EVENT,其 type_code 是 4,其 post-header 长度为 8。
当一个 Binlog 文件大小已经差不多要分割了,它就会在末尾被写入一个 ROTATE_EVENT——用于指出这个 Binlog 的下一个文件。
它的 post-header 是 8 字节的一个东西,内容通常就是一个整数 4,用于表示下一个 Binlog 文件中的第一个事件起始偏移量。我们从上文就能得出在一般情况下这个数字只可能是四,就偏移了一个魔法数字。当然我们讲的是在 v4 这个 Binlog 版本下的情况。
然后在 payload 位置是一个字符串,即下一个 Binlog 文件的文件名。
各种不同的事件体
由于篇幅原因这里就不详细举例其它普通的不同事件体了,具体的详解在 MySQL 文档中一样有介绍,用到什么类型的事件体就可以自己去查询。
什么时候记录BinLog
对支持事务的引擎如InnoDB而言,必须要提交了事务才会记录binlog。binlog 什么时候刷新到磁盘跟参数 sync_binlog 相关。
- 如果设置为0,则表示MySQL不控制binlog的刷新,由文件系统去控制它缓存的刷新;
- 如果设置为不为0的值,则表示每
sync_binlog次事务,MySQL调用文件系统的刷新操作刷新binlog到磁盘中。 - 设为1是最安全的,在系统故障时最多丢失一个事务的更新,但是会对性能有所影响。
如果 sync_binlog=0 或 sync_binlog大于1,当发生电源故障或操作系统崩溃时,可能有一部分已提交但其binlog未被同步到磁盘的事务会被丢失,恢复程序将无法恢复这部分事务。
在MySQL 5.7.7之前,默认值 sync_binlog 是0,MySQL 5.7.7和更高版本使用默认值1,这是最安全的选择。一般情况下会设置为100或者0,牺牲一定的一致性来获取更好的性能。
BinLog记录的三种模式
- 语句模式(STATMENT)
语句模式是MySQL5.6版本默认的模式,简单地说,就是每一条被修改的数据的SQL语句都会记录到master的binlog中,- 优点:不需要记录细到每一行数据的更改变化,可以大量减少binlog日志量,节约磁盘I/O,提高了系统性能。
- 缺点:在某些情况下会导致master-slave中的数据不一致(如sleep()函数, last_insert_id(),以及user-defined functions(udf)等会出现问题)
- 行级模式(ROW)
行级模式就是将数据被修改的每一行的情况记录为一条语句- 优点:binlog中可以不记录执行的SQL语句的上下文相关信息,仅仅记录哪一条记录被修改成什么样,所以row level的日志内容会非常清楚地记录下每一行数据修改的细节,非常容易理解。不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题。
- 缺点:会产生大量的日志,尤其是alter table的时候会让日志暴涨。
- 混合模式(MBR)
混合模式默认采用语句模式记录日志,在一些特定的情况下会将记录模式切换为行级模式记录,这些特殊情况包含但不限于以下情况:
①:当函数中包含UUID()时
②:当表中有自增列(AUTO_INCREMENT)被更新时
③:当执行触发器(trigger)或者存储过程(stored function)等特殊功能时
④:当FOUND_ROWS()、ROW_COUNT()、USER()、CURRENT_USER()、CURRENT_USER等执行时
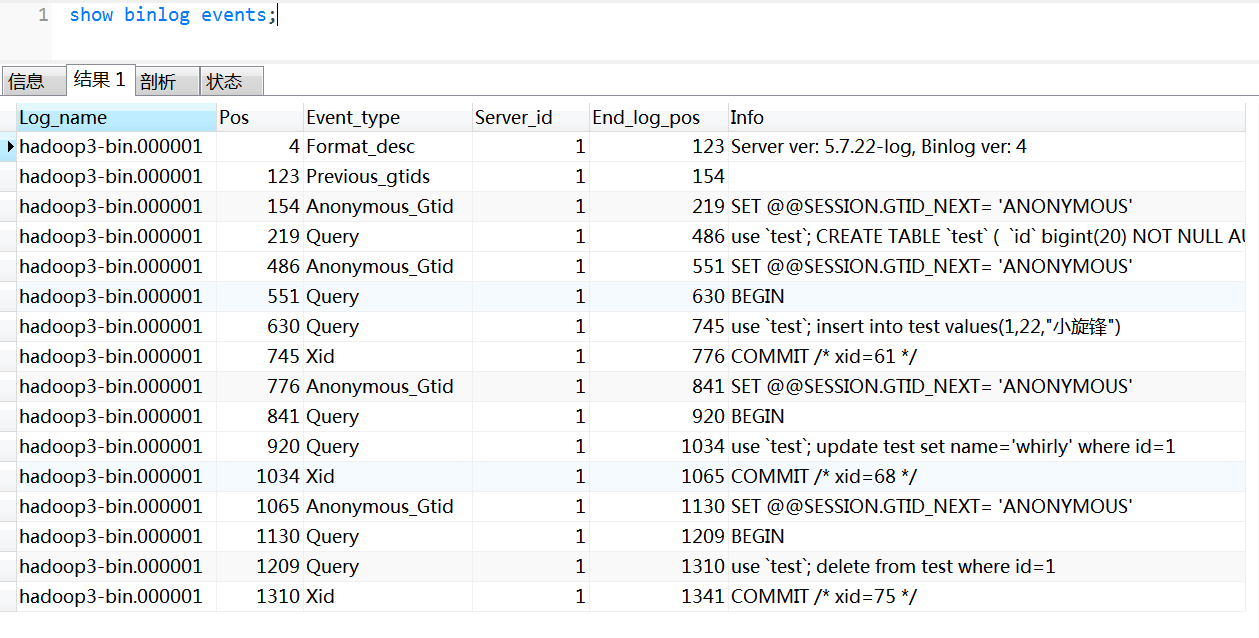
日志格式为STATEMENT,查看所有的Event
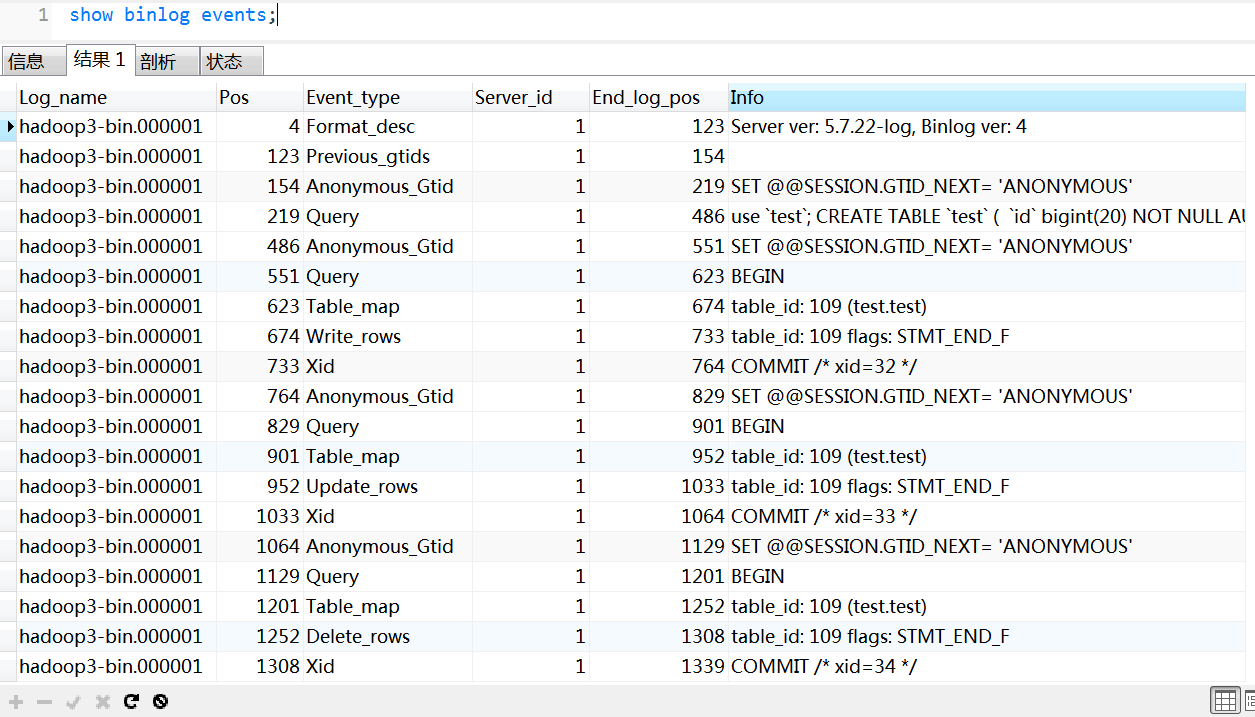
日志格式为ROW时是下面这样,可以发现又有一些不同
BinLog处理事务和非事务性语句区别
- 事务性语句(update)
- 非事务性语句(insert,delete)
在事务性语句(update)执行过程中,服务器将会进行额外的处理,在服务器执行时多个事务是并行执行的,为了把他们的记录在一起,需要引入事务日志的概念。在事务完成被提交的时候一同刷新到二进制日志。对于非事务性语句(insert,delete)的处理。遵循以下3条规则:
1)如果非事务性语句被标记为事务性,那么将被写入重做日志。
2)如果没有标记为事务性语句,而且重做日志中没有,那么直接写入二进制日志。
3)如果没有标记为事务性的,但是重做日志中有,那么写入重做日志。
注意如果在一个事务中有非事务性语句,那么将会利用规则2,优先将该影响非事务表语句直接写入二进制日志。
操作
BinLog文件操作
这是MySQL的操作,需要登录MySQL才能操作
- 是否启用binlog日志
show variables like 'log_bin';
- 查看详细的日志配置信息
show global variables like '%log%';
- mysql数据存储目录
show variables like '%dir%';
- 查看binlog的目录
show global variables like "%log_bin%";
- 查看当前服务器使用的biglog文件及大小
show binary logs;show master logs;
- 查看最新一个binlog日志文件名称和Position
show master status;
- 查看 binlog 内容
show binlog events;
- 查看具体一个binlog文件的内容 (in 后面为binlog的文件名)
show binlog events in 'master.000003';
- 设置binlog文件保存事件,过期删除,单位天
set global expire_log_days=3;
- 删除当前的binlog文件
reset master;
- 删除slave的中继日志
reset slave;
- 删除指定日期前的日志索引中binlog日志文件
purge master logs before '2019-03-09 14:00:00';
- 删除指定日志文件
purge master logs to 'master.000003';
- flush 刷新log日志,自此刻开始产生一个新编号的binlog日志文件;
flush logs;#注意:每当mysqld服务重启时,会自动执行此命令,刷新binlog日志;# 在mysqlddump备份数据时加-F选项也会刷新binlog日志;
BinLong文件创建/刷新
- 数据库重启会自动刷新binlog为新文件
- 执行
mysqldump -F或mysqladmin flush-logs会将binlog刷新为新文件 - binlog文件达到1GB左右时,会自动刷新binlog为新文件
- 人为配置切割及调整
注:binlog最大值参数和默认大小查看方式:show variables like ‘max_binlog_size’
BinLong文件删除
binlog日志很重要,不能随意清除,有的人会直接删除binlog物理文件,这样的操作是错误的,应避免,我们要确定什么时候可以删除binlog
方法一:设置参数自动删除binlog
我们假设参数为一个固定值,比如:
expire_logs_days = 7 # 此指令是删除7天前的日志;
然后可以设置默认的值为我们想用的时间,如下:
set global expire_logs_days=7;
方法二:按照时间删除binlog日志
这种删除方法适用于临时需求。
[root@lzh data]# ls -l --time-style=long-iso lzh-bin*
BinLog内容查询操作
注意:
- binlog是二进制文件,普通文件查看器cat、more、vim等都无法打开,必须使用自带的binlog命令查看。
- binlog日志与数据库文件在同目录中。
- 在Mysql5.5以下版本使用binlog命令时如果报错,就加上
--no-defaults选项
使用shell命令mysqlbinlog
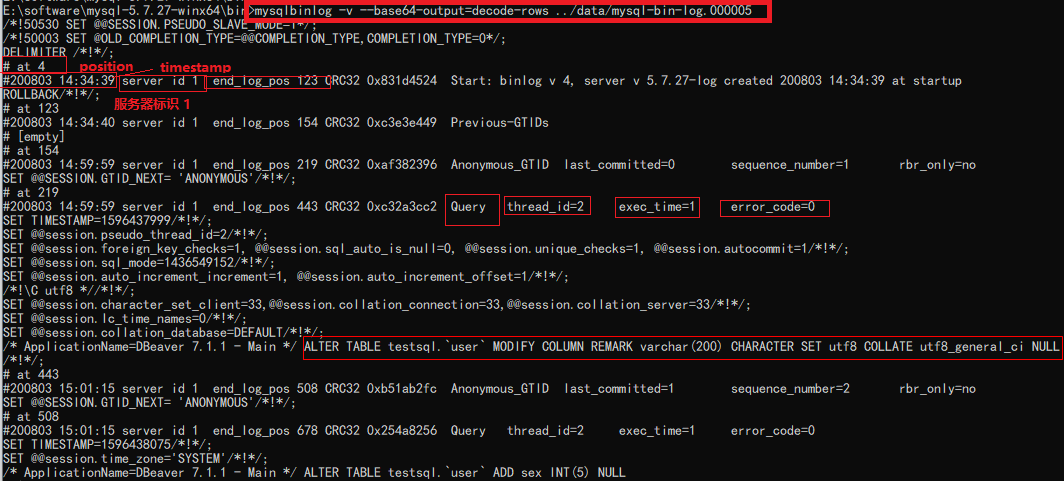
- 查看一个binlog文件
注意这是shell命令
mysqlbinlog [options] binlog文件;
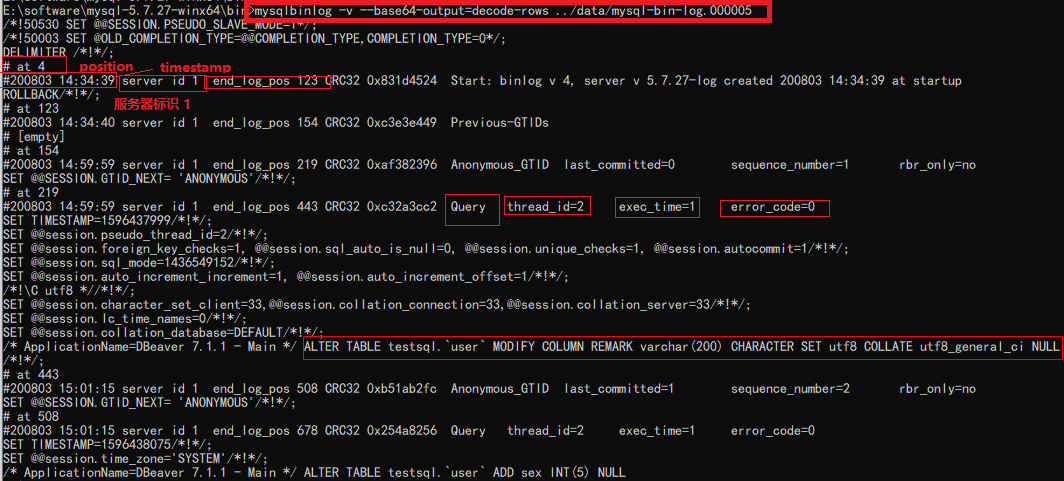
- position: 位于文件中的位置,即第一行的(# at 4),说明该事件记录从文件第4个字节开始
- thread_id=2:线程号
- timestamp: 事件发生的时间戳,即第二行的(#190308 10:10:09)
- server id: 服务器标识(1)
- end_log_pos 表示下一个事件开始的位置(即当前事件的结束位置+1)
- thread_id: 执行该事件的线程id (thread_id=113)
- exec_time: 事件执行的花费时间
- error_code: 错误码,0意味着没有发生错误
- type:事件类型Query
- 根据时间点查看binlog
/home/software/mysql-5.1.72-linux-x86_64-glibc23/bin/mysqlbinlog --no-defaults ../data/mysql-bin.000720 --start-datetime="2018-09-12 18:45:00" --stop-datetime="2018-09-12:18:47:00"
BinLog常见的时间选项
--start-datetime:从二进制日志中读取指定等于时间戳或者晚于本地计算机的时间--stop-datetime:从二进制日志中读取指定小于时间戳或者等于本地计算机的时间 取值和上述一样--start-position:从二进制日志中读取指定position 事件位置作为开始。--stop-position:从二进制日志中读取指定position 事件位置作为事件截至
使用mysql命令
上面这种办法读取出binlog日志的全文内容比较多,不容易分辨查看到pos点信息,下面介绍一种更为方便的查询命令:
mysql> show binlog events [IN 'log_name'] [FROM pos] [LIMIT [offset,] row_count];# 事件查询命令# IN 'log_name' :指定要查询的binlog文件名(不指定就是第一个binlog文件)# FROM pos :指定从哪个pos起始点开始查起(不指定就是从整个文件首个pos点开始算)# LIMIT [offset,] :偏移量(不指定就是0)# row_count :查询总条数(不指定就是所有行)
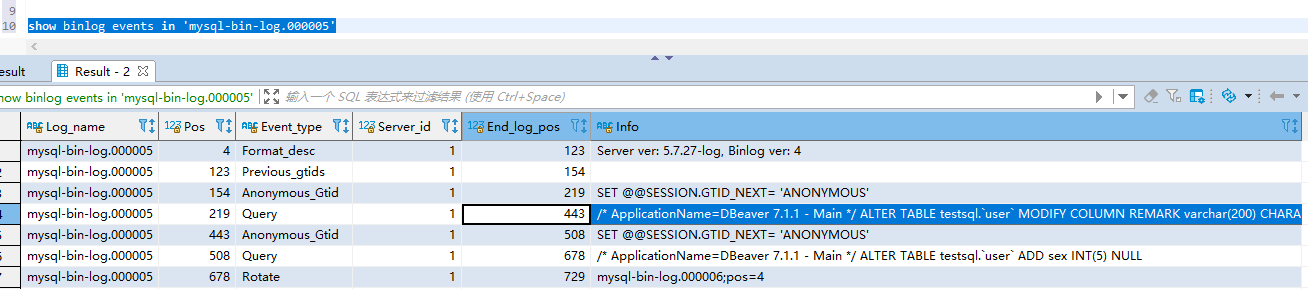
上面这条语句可以将指定的binlog日志文件,分成有效事件行的方式返回,并可使用limit指定pos点的起始偏移,查询条数!
- 查询第一个最早的binlog日志
show binlog events;
- 指定查询mysql-bin.000002这个文件
show binlog events in 'mysql-bin.000002';
- 指定查询mysql-bin.000002这个文件,从pos点:624开始查起:
show binlog events in 'mysql-bin.000002' from 624;
- 指定查询mysql-bin.000002这个文件,从pos点:624开始查起,查询10条(即10条语句)
show binlog events in 'mysql-bin.000002' from 624 limit 10;
- 指定查询 mysql-bin.000002这个文件,从pos点:624开始查起,偏移2行(即中间跳过2个)查询10条(即10条语句)。
show binlog events in 'mysql-bin.000002' from 624 limit 2,10;
binlog日志恢复命令
恢复命令的语法格式:
mysqlbinlog mysql-bin.0000xx | mysql -u用户名 -p密码 数据库名
常用参数选项解释:
- --start-position=875 起始pos点
- --stop-position=954 结束pos点
- --start-datetime="2016-9-25 22:01:08" 起始时间点
- --stop-datetime="2019-9-25 22:09:46" 结束时间点
- --database=ops指定只恢复ops数据库(一台主机上往往有多个数据库,只限本地log日志)
不常用选项:
- -u --user=name 连接到远程主机的用户名
- -p --password[=name]连接到远程主机的密码
- -h --host=name 从远程主机上获取binlog日志
- --read-from-remote-server从某个Mysql服务器上读取binlog日志
小结:实际是将读出的binlog日志内容,通过管道符传递给myslq命令。这些命令,文件尽量写成绝对路径;
案例:利用binlog日志恢复mysql数据
对ops库的member表进行操作,并且再创建一个库ops1
create database ops;create database ops1;use ops;CREATE TABLE IF NOT EXISTS `member` (`id` int(10) unsigned NOT NULL AUTO_INCREMENT,`name` varchar(16) NOT NULL,`sex` enum('m','w') NOT NULL DEFAULT 'm',`age` tinyint(3) unsigned NOT NULL,`classid` char(6) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;show tables;use ops1;CREATE TABLE IF NOT EXISTS `member` (`id` int(10) unsigned NOT NULL AUTO_INCREMENT,`name` varchar(16) NOT NULL,`sex` enum('m','w') NOT NULL DEFAULT 'm',`age` tinyint(3) unsigned NOT NULL,`classid` char(6) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;show tables;# 事先插入两条数据:use ops;insert into member(`name`,`sex`,`age`,`classid`) values('wangshibo','m',27,'cls1'),('guohuihui','w',27,'cls2');use ops1;insert into member(`name`,`sex`,`age`,`classid`) values('wangshibo','m',27,'cls1'),('guohuihui','w',27,'cls2');
进行场景模拟
- ops库会在每天凌晨四点进行一次完全备份的定时计划任务,如下:
0 4 * * * /application/mysql3306/bin/mysqldump -uroot -S /application/mysql3306/logs/mysql.sock -p123456 -B -F -R -x --master-data=2 ops ops1|gzip >/application/data/backup/ops_$(date +%F).sql.gz#这里我们可以手动执行一下# 备份文件,放在了/application/data/backup/文件夹下
参数说明:
-B:指定数据库-F:刷新日志-R:备份存储过程等-x:锁表--master-data:在备份语句里添加CHANGE MASTER语句以及binlog文件及位置点信息。
待到数据库备份完成,就不用担心数据丢失了,因为有完全备份数据在,由于上面在全备份的时候使用了
-F选项,那么当数据备份操作刚开始的时候系统就会自动刷新log,这样就会自动产生一个新的binlog日志,这个新的binlog日志就会用来记录备份之后的数据库'增删改操作'。
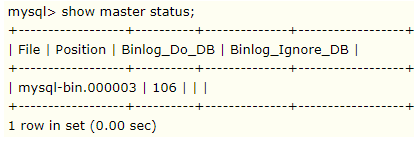
也就是说,mysql-bin.000003是用来记录4:00之后对数据库的所有'增删改操作'。
- 备份之后进行数据库操作
#在ops库下和ops1库下member表内插入、修改了数据等等:# 插入数据insert into ops.member(`name`,`sex`,`age`,`classid`) values('yiyi','w',20,'cls1'),('xiaoer','m',22,'cls3'),('zhangsan','w',21,'cls5'),('lisi','m',20,'cls4'),('wangwu','w',26,'cls6');insert into ops1.member(`name`,`sex`,`age`,`classid`) values('yiyi','w',20,'cls1'),('xiaoer','m',22,'cls3'),('zhangsan','w',21,'cls5'),('lisi','m',20,'cls4'),('wangwu','w',26,'cls6');# 修改数据库update ops.member set name='李四' where id=4;update ops1.member set name='李四' where id=4;update ops.member set name='小二' where id=2;update ops1.member set name='小二' where id=2;
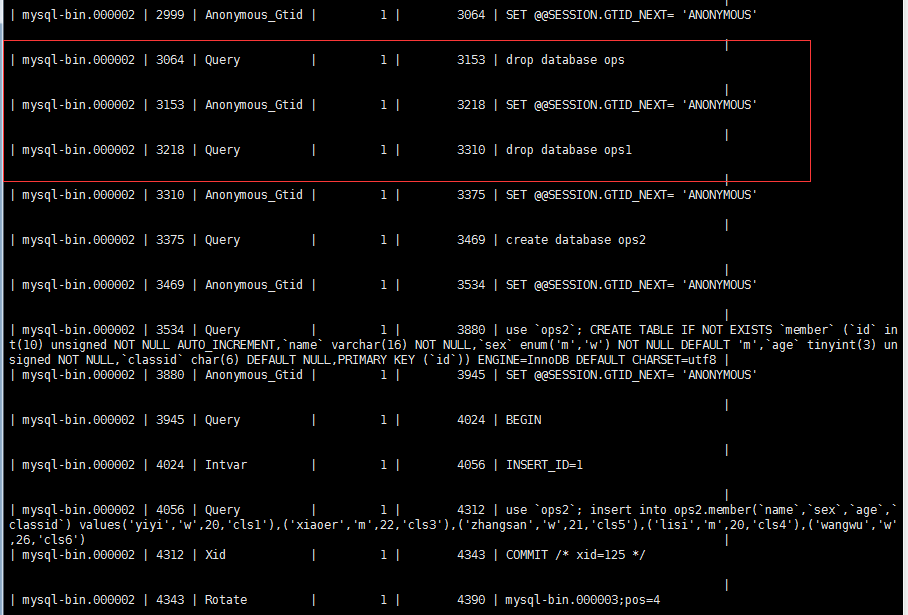
- 删除了ops和ops1库
drop database ops;drop database ops1;
- 创建了ops2库并插入数据
create database ops2;use ops2;CREATE TABLE IF NOT EXISTS `member` (`id` int(10) unsigned NOT NULL AUTO_INCREMENT,`name` varchar(16) NOT NULL,`sex` enum('m','w') NOT NULL DEFAULT 'm',`age` tinyint(3) unsigned NOT NULL,`classid` char(6) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;insert into ops2.member(`name`,`sex`,`age`,`classid`) values('yiyi','w',20,'cls1'),('xiaoer','m',22,'cls3'),('zhangsan','w',21,'cls5'),('lisi','m',20,'cls4'),('wangwu','w',26,'cls6');
破坏操作查询
- 先仔细查看最后一个binlog日志,并记录下关键的pos点,到底是哪个pos点的操作导致了数据库的破坏(通常在最后几步);
- 先备份一下最后一个binlog日志文件
cp -v mysql-bin.000004 /application/data/backup/

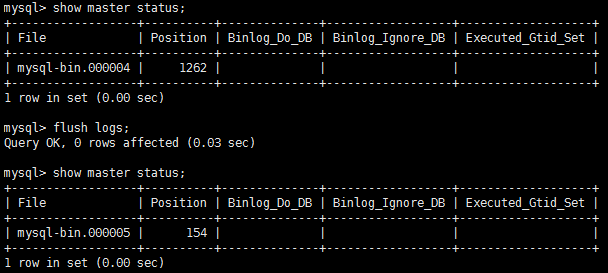
- 接着执行一次刷新日志索引操作,重新开始新的binlog日志记录文件。
按理说mysql-bin.000004这个文件不会再有后续写入了,因为便于我们分析原因及查找ops节点,以后所有数据库操作都会写入到下一个日志文件。
flush logs;show master status;
- 读取binlog日志
show binlog events in 'mysql-bin.000003';
或者
show binlog events in 'mysql-bin.000004'\G;
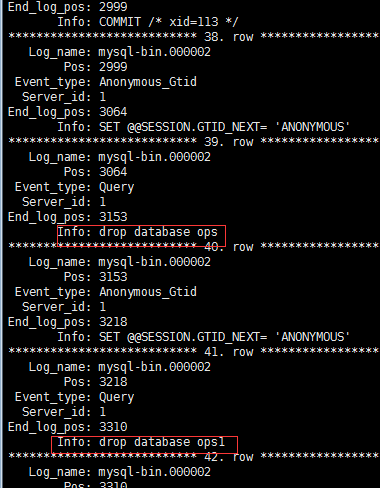
通过分析,造成库ops数据破坏的pos点区间是介于3064-3153之间(这是按照日志区间的pos节点算的),造成库ops1库破坏的pos区间是介于3218-3310之间,只要恢复到相应pos点之前就可以了。
上次全备份数据恢复
- 先把全备的数据恢复(建议另起一个库,等恢复成功后再替换掉当前库即可)
cd /application/data/backup/ # 进入数据全备份文件文件夹gzip -d ops_2018-09-11.sql.gz # 解压备份文件/application/mysql3307/bin/mysql -uroot -S /application/mysql3307/logs/mysql.sock -p123456 <ops_2018-09-11.sql # 这样就恢复了的备份数据了

从binlog日志恢复数据
方法1:完全恢复(此方法测试未通过)
- 手动vim编辑mysql-bin.000003,将那条drop语句剔除掉
- 直接恢复
/application/mysql3306/bin/mysqlbinlog /application/mysql3306/mysql_data/mysql-bin.000004 | /application/mysql3307/bin/mysql -uroot -S /application/mysql3307/logs/mysql.sock -p123456 -v ops
指定pos结束点恢复(部分恢复)
恢复ops数据库
/application/mysql3306/bin/mysqlbinlog --stop-position=3064 --database=ops /application/mysql3306/mysql_data/mysql-bin.000002 | /application/mysql3307/bin/mysql -uroot -S /application/mysql3307/logs/mysql.sock -p123456 -v# (因为加了--database=ops因此不会恢复二进制日志中关于ops1库的相应操作,若也需要恢复ops1库的相应操作,则再加上--database=ops1即可)
上面我们已经恢复到了删库之前的时刻,在删库后我们还做了创建ops2库并创建了member表和增加了数据的操作,此时我们要跳过删库并且恢复到创建ops2库和创建member表的时刻可以采用区间pos点恢复:
/application/mysql3306/bin/mysqlbinlog --start-position=3153 --stop-position=3880 /application/mysql3306/mysql_data/mysql-bin.000002 | /application/mysql3307/bin/mysql -uroot -S /application/mysql3307/logs/mysql.sock -p123456 -v
此时后面创建的表member恢复回来了但是库ops1被删除了,因为在这中间有删除ops1库的操作,若想继续恢复后面表中插入的数据只需要以建表后的pos点为开始点即可恢复除删库之外的所有数据。
#/application/mysql3306/bin/mysqlbinlog --start-position=3880 /application/mysql3306/mysql_data/mysql-bin.000002 | /application/mysql3307/bin/mysql -uroot -S /application/mysql3307/logs/mysql.sock -p123456 -v
定时间节点区间恢复(部分恢复)
另外:也可指定时间节点区间恢复(部分恢复):按时间恢复需要mysqlbinlog命令读binlog日志内容,找时间节点。
/application/mysql3306/bin/mysqlbinlog /application/mysql3306/mysql_data/mysql-bin.000002
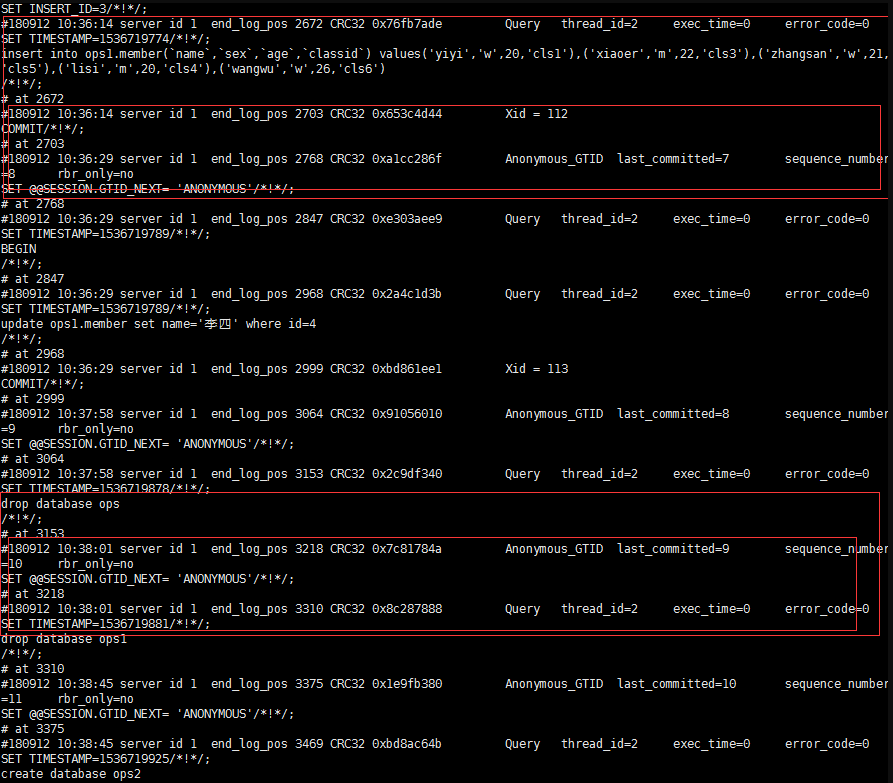
可以看到图中每个红框下的时间两个时间点都分别为事件的开始事件和结束时间
/application/mysql3306/bin/mysqlbinlog --stop-datetime="2018-09-12 10:37:58" /application/data/backup/mysql-bin.000002 | /application/mysql3307/bin/mysql -uroot -S /application/mysql3307/logs/mysql.sock -p123456 -v#此时stopdatetime不能写到2018-09-12 10:38:01否则会更新到drop database ops这个操作,其它时间点同此步骤# 使用的是上个命令的时间
跳过删库环节恢复后面数据,可以从2018-09-12 10:38:45时间开始恢复,因为删除ops1库的时间不足一秒因此可以这样干,这样干的话库ops1不会被删,不过建议最好还是从下一个时间节点为开始进行恢复,即2018-09-12 11:11:22
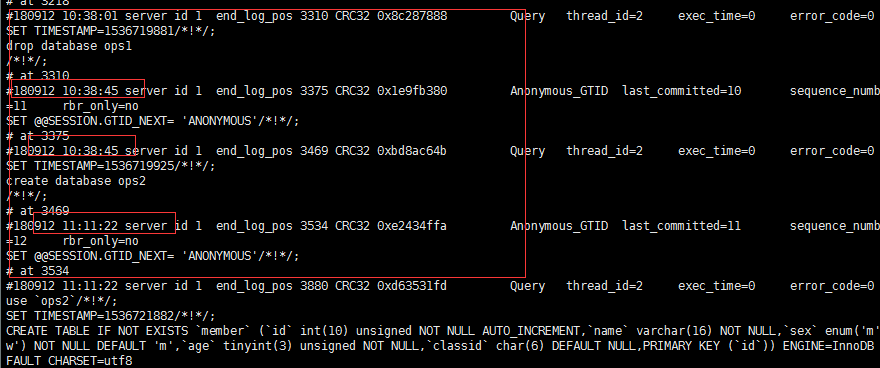
/application/mysql3306/bin/mysqlbinlog --start-datetime="2018-09-12 10:38:45" /application/data/backup/mysql-bin.000002 | /application/mysql3307/bin/mysql -uroot -S /application/mysql3307/logs/mysql.sock -p123456 -v
基本原理和通过pos点恢复差不多。
总结
所谓恢复,就是让mysql将保存在binlog日志中指定段落区间的sql语句逐个重新执行一次而已。

