


经典损失函数:交叉熵(附tensorflow)
每次都是看了就忘,看了就忘,从今天开始,细节开始,推一遍交叉熵。
我的第一篇CSDN,献给你们(有错欢迎指出啊)。
一.什么是交叉熵
交叉熵是一个信息论中的概念,它原来是用来估算平均编码长度的。给定两个概率分布p和q,通过q来表示p的交叉熵为:
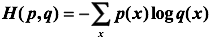
注意,交叉熵刻画的是两个概率分布之间的距离,或可以说它刻画的是通过概率分布q来表达概率分布p的困难程度,p代表正确答案,q代表的是预测值,交叉熵越小,两个概率的分布约接近。
那么,在神经网络中怎样把前向传播得到的结果也变成概率分布呢?Softmax回归就是一个非常有用的方法。(所以面试官会经常问你,为什么交叉熵经常要个softmax一起使用?)
假设原始的神经网络的输出为,那么经过Softmax回归处理之后的输出为: 
这样就把神经网络的输出也变成了一个概率分布,从而可以通过交叉熵来计算预测的概率分布和真实答案的概率分布之间的距离了。
举个例子,假设有一个3分类问题,某个样例的正确答案是(1,0,0),这个模型经过softmax回归之后的预测答案是(0.5,0.4,0.1),那么预测和正确答案之间的交叉熵为: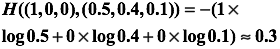
如果另一个模型的预测是(0.8,0.1,0.1),那么这个预测值和真实值之间的交叉熵是:

显然我们看到第二个预测要优于第一个。这里的(1,0,0)就是正确答案p,(0.5,0.4,0.1)和(0.8,0.1,0.1)就是预测值q,显然用(0.8,0.1,0.1)表达(1,0,0)的困难程度更小。


