爬虫—Selenium使用
Selenium使用
Selenium是一个自动化测试工具,可以驱动浏览器器执行特定的动作,如点击,下拉等。同时还可以获取浏览器当前呈现页面的源代码,可见即可爬。
1.准备
我们使用谷歌Chrome浏览器为例子,在开始之前需要安装Chrome浏览器并配置ChromeDriver。而且还需要安装Python的Selenium库。
2.基本使用
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait # 声明浏览器对象,将chromedriver驱动放在chrome浏览器安装目录下,指定驱动的绝对路径 browser = webdriver.Chrome(executable_path=r'D:\Google\Chrome\Application\chromedriver') try: browser.get('http://www.baidu.com') keyword = browser.find_element_by_id('kw') keyword.send_keys('Python') keyword.send_keys(Keys.ENTER) wait = WebDriverWait(browser, 10) wait.until(EC.presence_of_element_located((By.ID, 'content_left'))) print(browser.current_url) print(browser.get_cookies()) print(browser.page_source) finally: browser.close()
运行结果:
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=Python&rsv_pq=962442bf0007ea18&rsv_t=753aQptBMQwu82UDxwDFL9MEWvHNLNqjPznV4pNUSDP%2Bimq4HPgY91krrlM&rqlang=cn&rsv_enter=1&rsv_sug3=6&rsv_sug2=0&inputT=125&rsv_sug4=125 [{'domain': '.baidu.com', 'httpOnly': False, 'name': 'H_PS_PSSID', 'path': '/', 'secure': False, 'value': '1465_21104_29135_28518_29098_28831_28585_26350_29133'}, {'domain': '.baidu.com', 'httpOnly': False, 'name': 'delPer', 'path': '/', 'secure': False, 'value': '0'}, {'domain': '.baidu.com', 'expiry': 3707115919.146628, 'httpOnly': False, 'name': 'BAIDUID', 'path': '/', 'secure': False, 'value': '3A3A4CD3F97428EF73BA5E8B09ECB3C3:FG=1'}, {'domain': '.baidu.com', 'expiry': 3707115919.14668, 'httpOnly': False, 'name': 'PSTM', 'path': '/', 'secure': False, 'value': '1559632270'}, {'domain': '.baidu.com', 'expiry': 3707115919.146663, 'httpOnly': False, 'name': 'BIDUPSID', 'path': '/', 'secure': False, 'value': '3A3A4CD3F97428EF73BA5E8B09ECB3C3'}, {'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BD_HOME', 'path': '/', 'secure': False, 'value': '0'}, {'domain': '.baidu.com', 'expiry': 1559718674.348966, 'httpOnly': False, 'name': 'BDORZ', 'path': '/', 'secure': False, 'value': 'B490B5EBF6F3CD402E515D22BCDA1598'}, {'domain': 'www.baidu.com', 'expiry': 1560496273, 'httpOnly': False, 'name': 'BD_UPN', 'path': '/', 'secure': False, 'value': '12314753'}, {'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BD_CK_SAM', 'path': '/', 'secure': False, 'value': '1'}, {'domain': 'www.baidu.com', 'expiry': 1559634866, 'httpOnly': False, 'name': 'H_PS_645EC', 'path': '/', 'secure': False, 'value': '1058c7aSaGElrxQn6SZOATLVXWtCzFAGCMEiW5OevaJTsJ938%2BGyVo1%2B72k'}, {'domain': '.baidu.com', 'httpOnly': False, 'name': 'PSINO', 'path': '/', 'secure': False, 'value': '5'}, {'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BDSVRTM', 'path': '/', 'secure': False, 'value': '173'}] <!DOCTYPE html><!--STATUS OK--><html xmlns="http://www.w3.org/1999/xhtml"><head><script charset="utf-8" async="" src="https://ss0.bdstatic.com/-0U0bnSm1A5BphGlnYG/tam-ogel/5d4e9b24-dcc5-483a-b6da-be1e9e621891.js"></script> <meta http-equiv="content-type" content="text/html;charset=utf-8" /><style data-for="result" id="css_result" type="text/css">body{color:#333;background:#fff;padding:6px 0 0;margin:0;position:relative;min-width:900px}body,th,td,.p1,.p2{font-family:arial}p,form,ol,ul,li,dl,dt,dd,h3{margin:0;padding:0;list-style:none}input{padding-top:0;padding-bottom:0;-moz-box-sizing:border-box;-webkit-box-sizing:border-box;box-sizing:border-box}table,img{border:0}td{font-size:9pt;line-height:18px}em{font-style:normal;color:#c00}a em{text-decoration:underline}cite{font-style:normal;......
运行代码后发现,会自动弹出一个Chrome浏览器,首先跳转到百度,然后输入Python,接着跳转到搜索结果。结果加载出来后,控制台会打印当前url,Cookies和网页源码。可以看到我们得到的都是浏览器中真实显示的内容。这样使用Selenium驱动浏览器加载网页可以直接获取到动态渲染的结果。
3.查找节点
Selenium可以驱动浏览器完成各种操作,比如点击模拟,表单填写。例如,我们如果想要在某一输入框内输入文本,首先需要找到这个输入框的位置,也就是在网页中的所在节点的位置。
♦单个节点
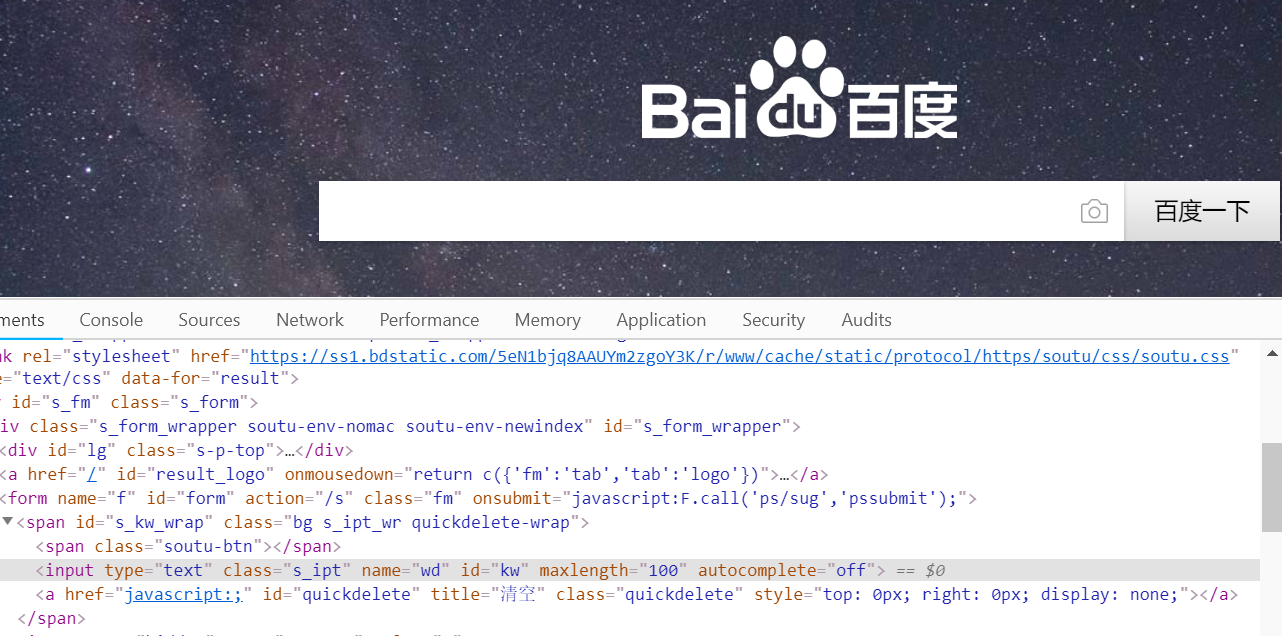
想要在百度搜索框中输入文本,首先观察它的源码。我们可以发它的name属性为wd,id为kw,还有一些其他属性。此时我们可以用多种方式来获取它。
# 单个节点 browser.get('http://www.baidu.com') input1 = browser.find_element_by_id('kw') # 使用属性选择 input2 = browser.find_element_by_css_selector('#kw') # 使用css选择 input3 = browser.find_element_by_xpath('//*[@id="kw"]') # 使用xpath选择 print(input1) print(input2) print(input3) browser.close()
运行结果:
<selenium.webdriver.remote.webelement.WebElement (session="77121972a5b1ff253e30e6912a609acc", element="0.1322124037138812-1")> <selenium.webdriver.remote.webelement.WebElement (session="77121972a5b1ff253e30e6912a609acc", element="0.1322124037138812-1")> <selenium.webdriver.remote.webelement.WebElement (session="77121972a5b1ff253e30e6912a609acc", element="0.1322124037138812-1")>
可以看到三个方式返回的结果是完全一致的。当然还有其他很多方法可以使用。
♦多个节点
如果查找的目标只有一个,那么完全可以使用find_element()方法,如果有个多目标,find_element()方法只能查找到第一个,要想全部查找到,需要使用find_elements()方法。方法名后面多了一个s。
比如,想要查找淘宝网左侧导航栏上面的所有条目:

# 多个节点,淘宝导航栏条目为例 browser.get('https://www.taobao.com') items = browser.find_elements_by_css_selector('.service-bd li') print(items) browser.close()
运行结果:
selenium.webdriver.remote.webelement.WebElement (session="d0d87044954d7497862d2f93b0480667", element="0.5258543885521916-1")>, <selenium.webdriver.remote.webelement.WebElement (session="d0d87044954d7497862d2f93b0480667", element="0.5258543885521916-2")>, <selenium.webdriver.remote.webelement.WebElement (session="d0d87044954d7497862d2f93b0480667", element="0.5258543885521916-3")>, <selenium.webdriver.remote.webelement.WebElement ......
这里可以看到,获取的内容为一个列表类型,列表中的每个元素都是WebElement类型。
4.节点操作
Selenium提供了一些方法来模拟浏览器的动作,输入文字使用send_key()方法,清空使用clear()方法,点击按钮方使用click()方法。
# 2.节点交互 import time browser = webdriver.Chrome(executable_path=r'D:\Google\Chrome\Application\chromedriver') browser.get('http://www.baidu.com') input_word = browser.find_element_by_id('kw') input_word.send_keys('apple') time.sleep(2) input_word.clear() input_word.send_keys('cherry') button = browser.find_element_by_id('su') time.sleep(3) button.click() browser.close()
5.动作链操作
鼠标拖拽,键盘按键等等,这些动作是使用动作链操作来完成的。下面以菜鸟教程的网站为例:
# 5.动作链操作 from selenium import webdriver from selenium.webdriver import ActionChains import time browser = webdriver.Chrome(executable_path=r'D:\Google\Chrome\Application\chromedriver') url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable' browser.get(url) browser.switch_to.frame('iframeResult') s1 = browser.find_element_by_css_selector('#draggable') s2 = browser.find_element_by_css_selector('#droppable') actions = ActionChains(browser) actions.drag_and_drop(s1, s2) actions.perform() time.sleep(2) browser.close()
执行代码,会打开网站页面,然后自动拖动其中一个拖拽示例拖拽到目标位置。
6.操作JavaScript
Selenium中模拟操作JavaScript使用execute_script()方法来实现。访问网站,滑动到底部,最后弹出“OK”。
# 6.模拟JavaScript操作 from selenium import webdriver import time browser = webdriver.Chrome(executable_path=r'D:\Google\Chrome\Application\chromedriver') browser.get('https://www.zhihu.com/explore') browser.execute_script('window.scrollTo(0,document.body.scrollHeight)') browser.execute_script('alert("OK")') time.sleep(3) browser.close()
7.获取节点信息
♦获取属性
使用get_attribute()方法来获取节点属性,先选中这个节点:
# 7.1获取属性 browser = webdriver.Chrome(executable_path=r'D:\Google\Chrome\Application\chromedriver') browser.get('https://www.zhihu.com/explore') logo = browser.find_element_by_id('zh-top-link-logo') print(logo) print(logo.get_attribute('class')) browser.close()
运行结果:
<selenium.webdriver.remote.webelement.WebElement (session="13c1e08b7569415b9027cdfec9703a0e", element="0.2490095895940252-1")> zu-top-link-logo
♦获取文本
每个WebElement节点都有其text属性,直接调用这个属性就得到其内部的文本信息。 获取百度首页新闻的文本内容。
# 7.2获取文本信息 browser = webdriver.Chrome(executable_path=r'D:\Google\Chrome\Application\chromedriver') browser.get('http://www.baidu.com') icons = browser.find_element_by_name('tj_trnews') print(icons.text)
运行结果:
新闻
♦获取id,位置,标签名,大小
# 7.3获取id,位置,标签名,大小 browser = webdriver.Chrome(executable_path=r'D:\Google\Chrome\Application\chromedriver') browser.get('http://www.baidu.com') icons = browser.find_element_by_name('tj_trnews') print(icons.id) print(icons.location) print(icons.tag_name) print(icons.size)
运行结果:
0.4808968979713124-1 {'x': 557, 'y': 19} a {'height': 24, 'width': 26}
8.切换Frame
网页中有一种节点叫做iframe,也就是子Frame,相当于页面的子页面,它的结构和外部网页一致。Selenium默认是在父级Frame里面操作,如果页面中还有子Frame,不能直接获取到子页面的数据,需要使用switch_to.frame()切换Frame。
# 8.切换Frame from selenium import webdriver from selenium.common.exceptions import NoSuchElementException browser = webdriver.Chrome(executable_path=r'D:\Google\Chrome\Application\chromedriver') url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable' browser.get(url) browser.switch_to.frame('iframeResult') try: logo_first = browser.find_element_by_class_name('logo') except NoSuchElementException: print("Failed") browser.switch_to.parent_frame() # 切换到父级Frame logo = browser.find_element_by_class_name('logo') print(logo) print(logo.text)
运行结果:
Failed <selenium.webdriver.remote.webelement.WebElement (session="497ccfe660416ed053ba4b08b5c7351f", element="0.03506166807633293-2")> RUNOOB.COM
9.延时等待
在Selenium中,get()方法会在网页加载结束后执行,此时获取page_source可能并不是浏览器完全加载的数据。如果有额外的Ajax请求,不一定能获取成功。所有需要延时等待一定时间,确保数据已经加载出来。
♦隐式等待
如果Selenium没有在DOM中找到节点,将继续等待,超出设定时间后就会抛出没有节点的异常。
# 9.延时等待 # 9.1隐式等待:没有找到继续等待,超时抛出异常 browser = webdriver.Chrome(executable_path=r'D:\Google\Chrome\Application\chromedriver') browser.implicitly_wait(10) browser.get('https://www.zhihu.com/explore') que = browser.find_element_by_class_name('zu-top-add-question') print(que)
♦显式等待
指定一个节点,设置最长等待时间。如果规定的时间内加载出来了,就返回要查找的节点;超出时间则抛出异常。
# 9.2显式等待 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait browser = webdriver.Chrome(executable_path=r'D:\Google\Chrome\Application\chromedriver') browser.get('https://www.taobao.com/') wait = WebDriverWait(browser, 10) su = wait.until(EC.presence_of_element_located((By.ID, 'q'))) # 等待条件,节点出现 button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search'))) # 等待条件,按钮可以点击 print(su, button)
运行结果:
<selenium.webdriver.remote.webelement.WebElement (session="69f58b354be01e63e367e29756e64f18", element="0.005030458042517338-1")> <selenium.webdriver.remote.webelement.WebElement (session="69f58b354be01e63e367e29756e64f18", element="0.005030458042517338-2")>
如果10秒内没有加载成功,就会抛出TimeoutException异常。
10.窗口管理
浏览器访问网页时会开启一个个窗口,我们也可以使用Selenium对多个窗口进行操作。
# 10.窗口管理 import time from selenium import webdriver browser = webdriver.Chrome(executable_path=r'D:\Google\Chrome\Application\chromedriver') browser.get('http://www.baidu.com') browser.execute_script('window.open()') print(browser.window_handles) browser.switch_to.window(browser.window_handles[1]) browser.get('https://www.taobao.com') time.sleep(2) browser.switch_to.window(browser.window_handles[0]) browser.get('https://www.zhihu.com/explore')
window.open()开启新窗口,windo_handlers获取当前开启的所有窗口,返回的是窗口代号的列表。使用switch_to.window()切换窗口。
先访问百度,然后打开新窗口,再访问淘宝,最后切换回正在访问百度的第一个窗口,接着访问知乎。
11.异常处理
使用Selenium过程难免会出现异常,例如超时,节点为找到等。一旦出现异常,程序便不会运行了。使用try except语句来捕获异常:
# 11.异常处理 from selenium import webdriver from selenium.common.exceptions import TimeoutException, NoSuchElementException browser = webdriver.Chrome(executable_path=r'D:\Google\Chrome\Application\chromedriver') browser.get('http://www.baidu.com') try: browser.find_element_by_class_name('hello') except TimeoutException: print('Time out') try: browser.find_element_by_class_name('hello') except NoSuchElementException: print('No Element') finally: browser.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号