

上文发了之后,有人说要和SSAS对比,还有人说要在SQLServer建一个列数据库来对比
SQL2012 之后开始有列存储, 但要在2016SP1之后才在Express版开放, 之前都是在Enterprise版才有, 我在win10安装了最新SQLServer 2019 Express版, 把订单日期字段加上列存储索引
--建立列索引用时42秒
create nonclustered columnstore index PK_tblSale_ColumnStore on [taobao].[dbo].[tblSale](date)
执行分组查询语句没有改善
SELECT Convert(varchar(8) , date, 112) as date,count(*) as dayCnt FROM [taobao].[dbo].[tblSale] group by Convert(varchar(8) , date, 112) order by Convert(varchar(8) , date, 112)
难道是因为datetime用convert转成字符,不能用索引??? 新建一列纯粹用字符的, 用时7分09秒更新2亿条数据
alter table tblSale add dateYMD varchar(10) update tblSale set dateYMD= (select Convert(varchar(8) , date, 112)) from tblSale
用新字段做groupby,用时44秒
SELECT dateYMD as date,count(*) as dayCnt FROM [taobao].[dbo].[tblSale] group by dateYMD order by dateYMD
重新建立列索引, 一个数据库只能有一个列存储索引
drop index PK_tblSale_ColumnStore on [taobao].[dbo].[tblSale] --建立列索引用时1分22秒 create nonclustered columnstore index PK_tblSale_dateYMD on [taobao].[dbo].[tblSale](dateYMD)
重新查询, 用时16秒, 还是很慢. 这个还是比不上ClickHouse, 有知道怎么样提高SQLServer的,请@我....
前天看到群里面有个查询优化的讨论,通过索引或组合索引达到 IndexSeek 的目的来提高查找速度, 但是像我上面这种查询是把全表所有记录在按日期分组查询总数, 这样避免不了全表数据的查询, 索引起的用处不大, OLTP处理的是某个用户或者某个产品,订单等的处理, 处理的数据量通常不会过百条, 所以要求的能力是在GB/TB级数据里查询修改若干条数据的能力. 而OLAP处理的要求则是GB/TB级的数据都进行分析,按维度统计数据和趋势.
反骨仔:
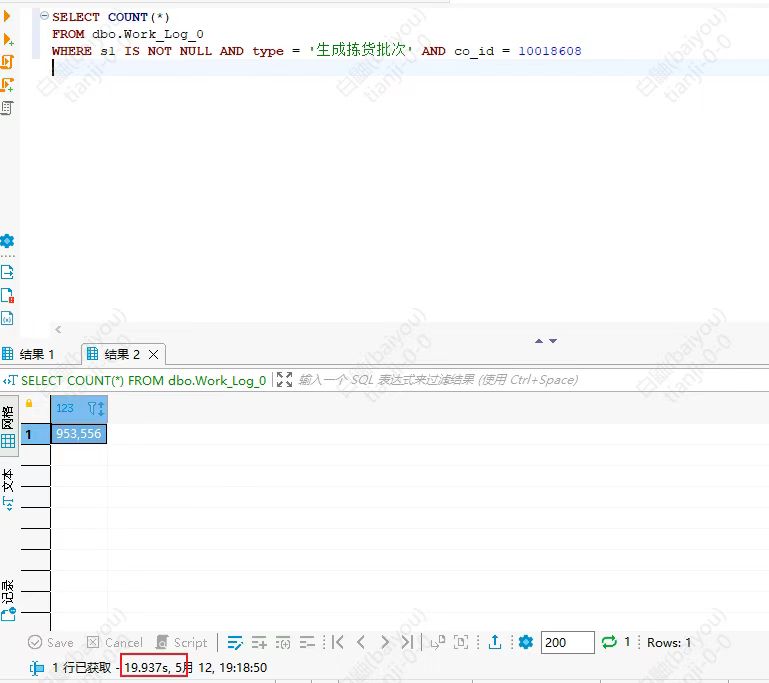
sqlserver 执行一下 count(*) 要 20s,能优化吗雄:
count(1)@反骨仔反骨仔:
不是一样吗?雄:
你查查就知道区别了雄:
索引建了啥?反骨仔:
不会更慢吗反骨仔:
表有索引的老白 石崖茶.银藤茶🐐:
有多少数据量?七阵:
条件换一下,先查询数字,再查询字符串,还有is not null效率很差。反骨仔:
这里的执行效果是90w+反骨仔:
数据量反骨仔:
索引是这样的反骨仔:
[图片]雄:
这个sl你可以建个过滤索引雄:
[图片]雄:
建个复合索引雄:
[图片]雄:
另外count(*)是会算整行吧雄:
你count(主键)不行吗雄:
复合索引,where顺序也要对雄:
列数也要一致雄:
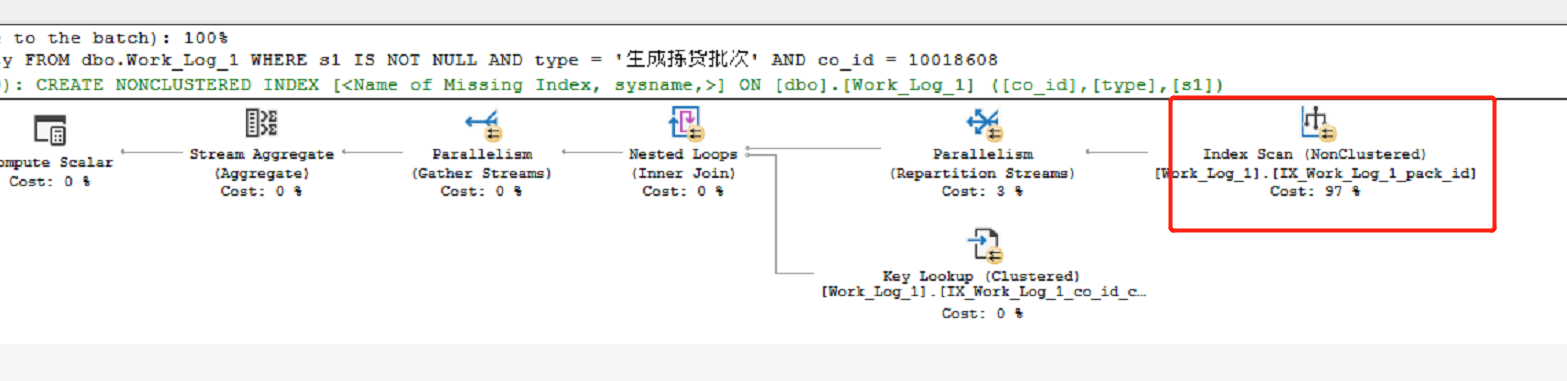
@反骨仔 看看你的执行计划雄:
消耗最大的是第几块霍尔顿:
过滤性强的条件放前面雄:
他这张表估计数据有上亿反骨仔:
[图片]反骨仔:
这个行吗
雄:
反骨仔:
雄:
你如果都是搜not null,你修改下索引,只统计not null的,过滤索引,性能可以提高一些雄:
[图片]层楼:
如果在s1上建立了索引,直接count(s1)就行了,不用再where s1 is not null。层楼:
count(字段)是不会把null值统计进去的反骨仔:
3.4 亿+ 的数据又搞下索引,会卡住的吧雄:
当然会卡雄:
不要在用的时候建雄:
如果不需要新增数据,当做是日志数据查询,sqlserver还有一个索引的大杀器雄:
列存储反骨仔:
雄:
不过要看你的版本以及这东西有一定局限性雄:
最好sqlserver 2014以上使用沙漠尽头的狼:
不用时序?雄:
3.4亿,本身还是要再继续分表吧反骨仔:
clickhouse 吗反骨仔:
列存储樊:
他这个就是三列条件,而索引上都是单键索引的缘故,按查询需求加个索引就行了樊:
然后查一下不必要的索引删除几个雄:
他这个消耗最大的是这个雄:
[图片]雄:
应该是*的缘故樊:
对啊,他现在用的索引在那个单键id的索引樊:
也就是要先ID的搜出来然后去lookup雄:
他这个复合没起作用雄:
[图片]gz88:
列存储索引没啥用雄:
你要看什么应用场景了樊:
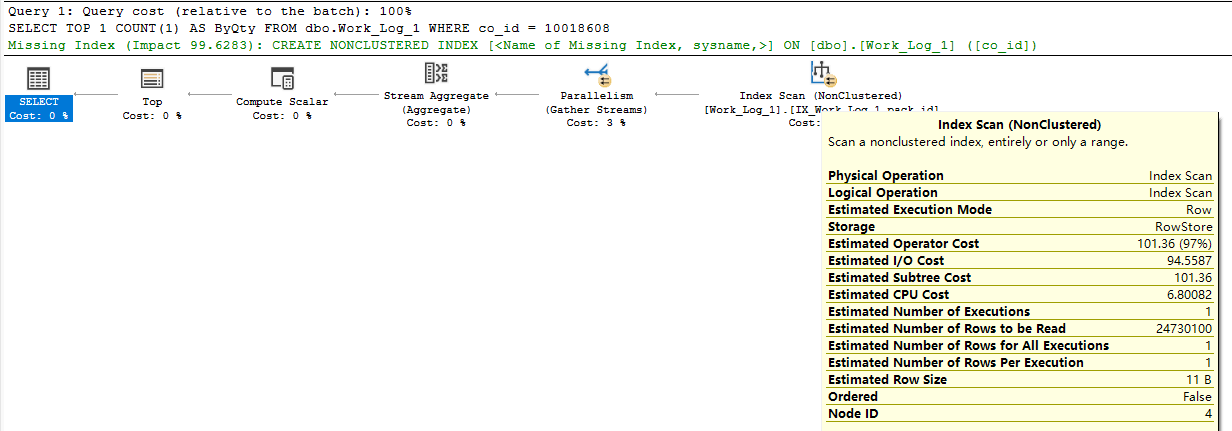
因为优化有8引擎认为这个成本比单列ID的索引高雄:
适合那些日志数据反骨仔:
[图片]樊:
他这个列存储索引合适樊:
如果可以,你试试先删掉单键索引,然后再建组合索引,用两列ID和那个type樊:
看看执行计划再决定樊:
顺便更新一下统计信息樊:
我知道你问题了雄:
[图片]樊:
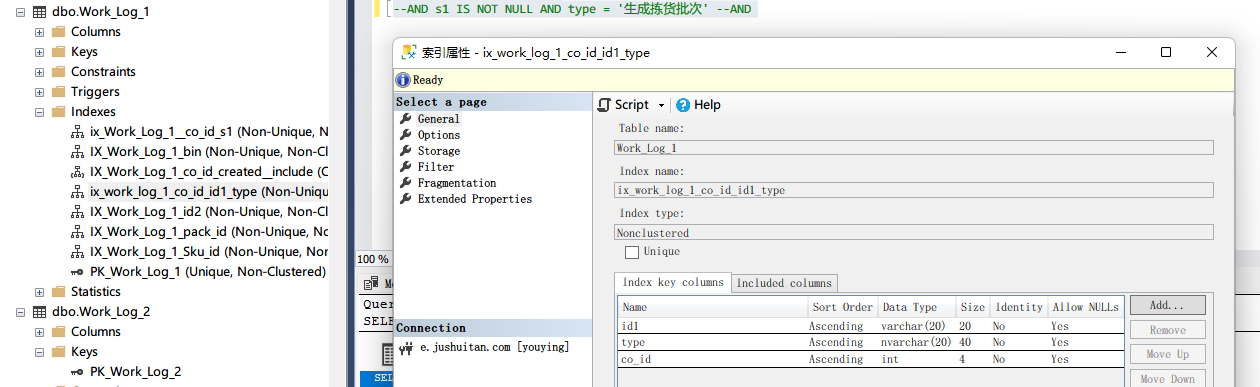
你把这个索引定义发出来看一下樊:
[图片]樊:
你co_id列上没索引樊:
上面的索引是另外一列ID反骨仔:
樊:
你把这个索引的创建语句发一下反骨仔:
[图片]反骨仔:
测试不了,没有权限樊:
不是让你创建。。你点右键把这个索引的定义给出来樊:
我想知道你这个索引定义的列的情况樊:
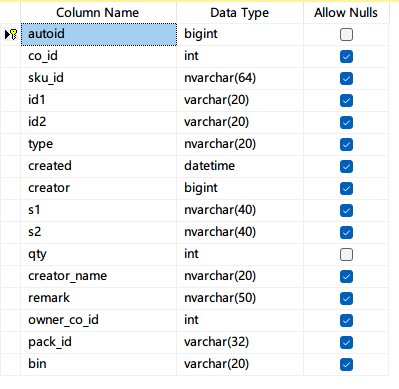
如果没猜错的话那个索引在pack_id上,而你使用的常用场景是co_id加type反骨仔:
反骨仔:
是这个吗樊:
你应该定义一个新的索引以coid加上type,然后include那个s1反骨仔:
感觉搞这个有点累,暂时不想研究这个了樊:
哦是要这个,那个id1是啥反骨仔:
字符串反骨仔:
樊:
如果没有其他场景用这个ID1,删掉这个索引,按我上面的建就解决了反骨仔:
好的樊:
简单的说就是索引建的不是很适用场景,太多列了,去掉ID1,优化索引,减小IO,什么时候你看执行计划变成了index seek就对了反骨仔:
可以霍尔顿:
这么大数据量要分表了,折腾索引意义不大了,数据库性能又不是无限的雄:
其实他这种统计类的,还可以用空间换时间的思路樊:
这点还不算啥特大数据量,况且这已经分表了,这个对sql server 不是大问题,凡是都是根据实际来,索引不是万能,但这个是一个常见的索引使用不当的情况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号