LAS、CTC、RNA、RNN-T 等
这些都是大名鼎鼎的 seq2seq model。
本文可看作是台大李宏毅教授 DLHLP 课程的学习笔记,学习传送门:https://www.bilibili.com/video/BV12T411X7Nz/
1 Listen,Attend and Spell(LAS)
这是 speech recognition 在深度学习时代非常经典的一篇论文,也将是本文介绍最详细的一篇,后面的论文(CTC 等)其实大体还是沿着 LAS 的思路,所以看懂 LAS,后面的内容其实就是举一反三的过程。
先上李宏毅 ppt 中的说明:

1.1 模型架构
这是 paper 中的整体架构:

其中 Listener 部分就是 Encoder,Speller 部分是 Attention + Decoder。
1.2 Listener(Encoder)
Encoder 会把输入的一串声学特征,转换为高维隐层嵌入。
它的主要目标是提取出内容信息,过滤掉说话者的嗓音变化和环境噪音。
Encoder
Encoder 可以用 CNN 和 RNN,也可以是 CNN+RNN,也可以用 self-attention:
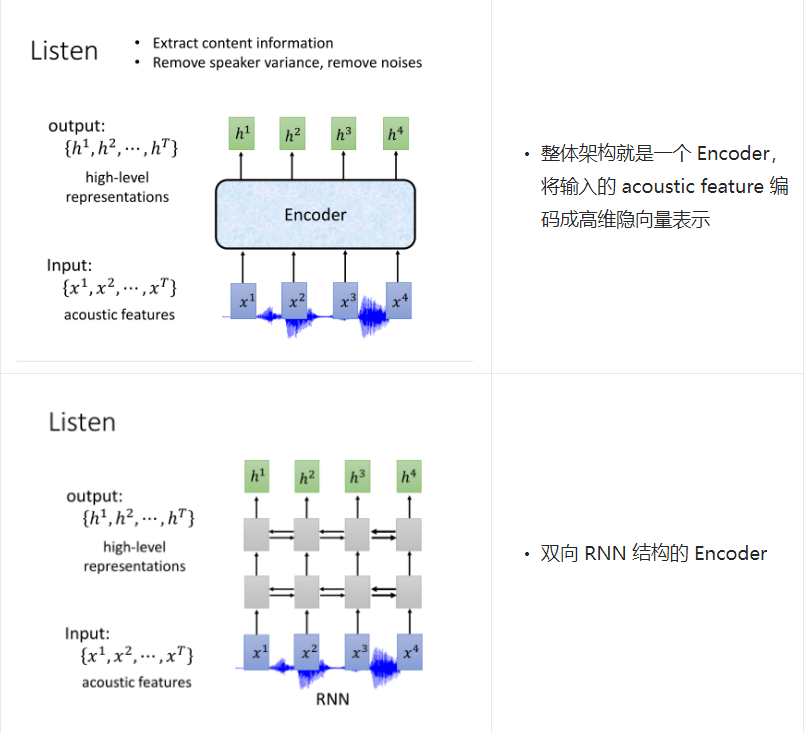
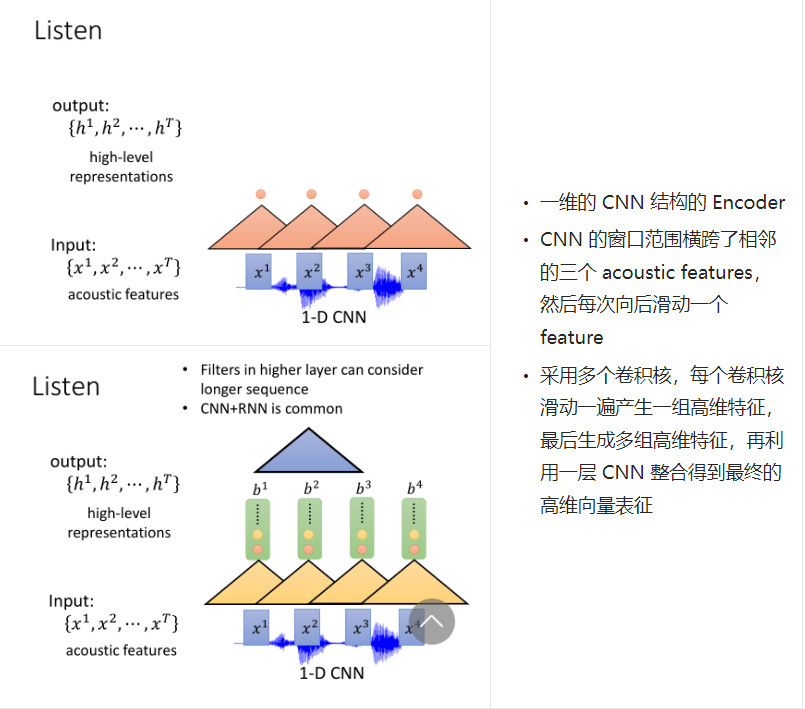
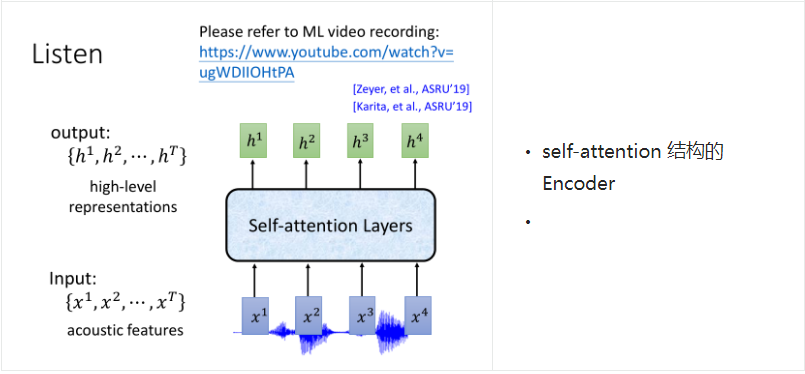
尽管介绍了这么多 Encoder 的方式,但是原论文中使用的是双向 LSTM(BLSTM)结构来做 Encoder。
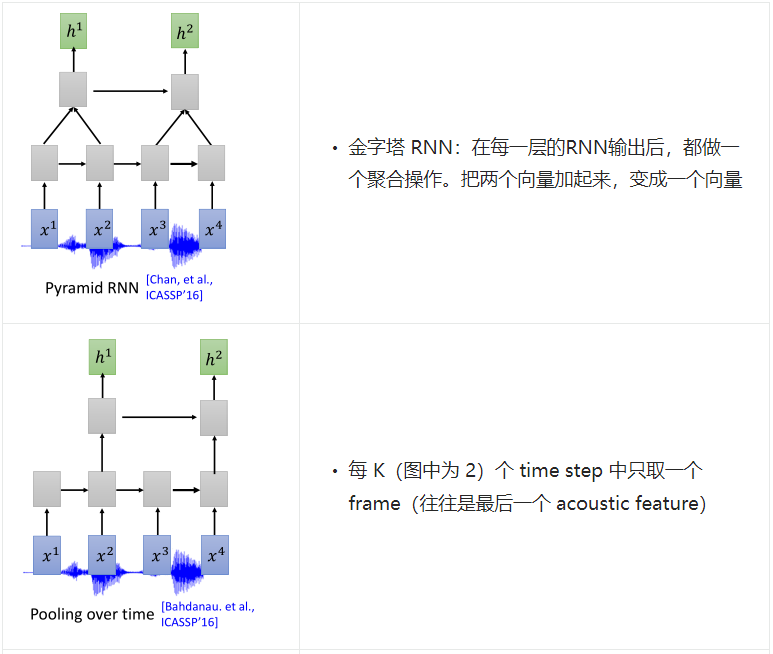
Down Sampling
了解声学特征采样过程的应该了解,一段声音信号的采样间隔是很小的,这会导致采集的声学特征非常密集,这不可避免的会导致相邻特征向量间带有重复的信息。为了节省计算量 ,通常采用下采用(down sampling)对原始特征做进一步的压缩,常见的下采样方式有:
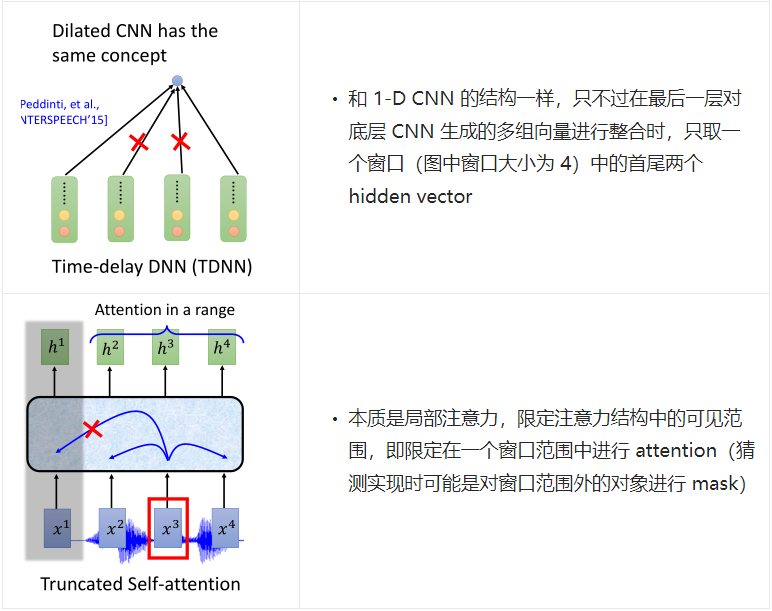
1.3 Attention & Decoder
这块儿 PPT 中讲的有欠缺的地方,有些点无法很好理解,去翻了下原论文。
从宏观来看 Attention
先看下 PPT 中的图:
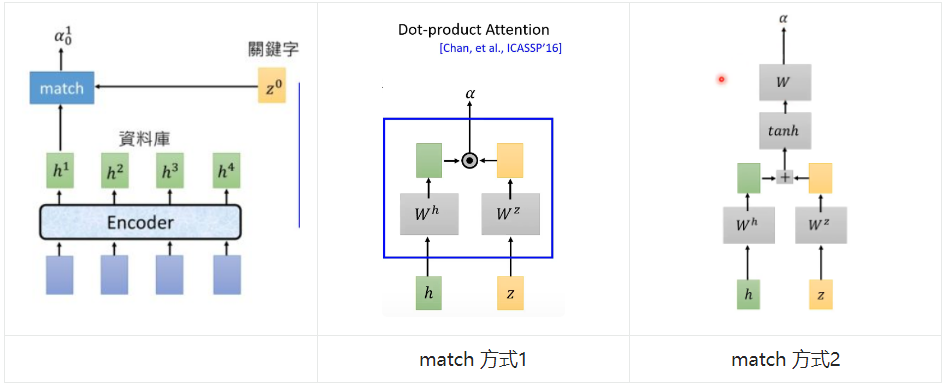
在 Attention 部分中,主要是对前面 Encoder 部分产出的 acoustic feature 的高维向量表示(\(\{h_1,h_2,h_3,h_4\}\))做 attention。
我们先用 match 表示 attention 模块,该模块接收高维声学特征和一个 z 作为输入(这个 z 可以理解为 self-attention 中的 key,\(h_i\) 可以理解为 query),输出一个标量 \(\alpha_i\),表示当前 \(h_i\) 的注意力权重。
那么 match 之中是怎么做 attention 中的呢?
第一种方式是采用点乘(dot product),输入 h 和 z 分别过一个 Embedding 矩阵,得到两个 size 一致的 vector,然后点乘得到标量输出 \(\alpha\)。
第二种方式是将 h 和 z 分别过一个 embedding 矩阵,得到两个 size 一致的 vector,然后相加,之后再过 tanh 激活函数,最后用一个 embedding 矩阵(也可以理解为一个简单的线性层,输出维度是 1)做转换得到一个标量 \(\alpha\)。
细节:Z 的来源
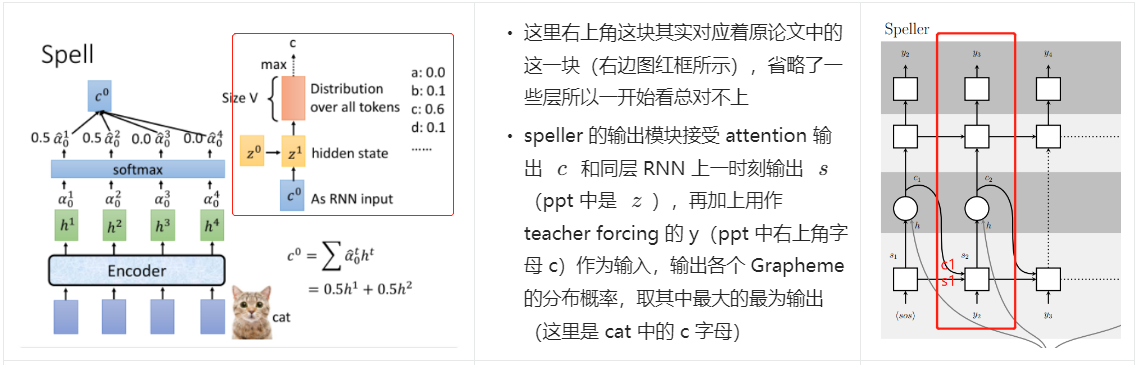
说到这里,其实有个问题,这个 z 向量是什么?视频中说这是 RNN 中的一层隐层的向量表征,还是不得甚解。这时候先看下原论文中图:

都标注在图中说明了,这里我理解 ppt 中的 z 应该就是论文图中底层 RNN 的输出 \(s_i\),因为这里 \(s_i\) 也是作为 attention 模块的输入,attention 细节见下文。
具体的 Attention
下图是 attention 计算的示例:

- key 矩阵 z(论文中的 s)与每个 h 相乘得到每个 h 的权重参数,然后将权重参数乘到各自的 h 上,求和得到 c;
- 这里的 c 论文中称为 context vector;
预测过程
得到 decoder 输出后,就可以做输出判断,先介绍预测过程。
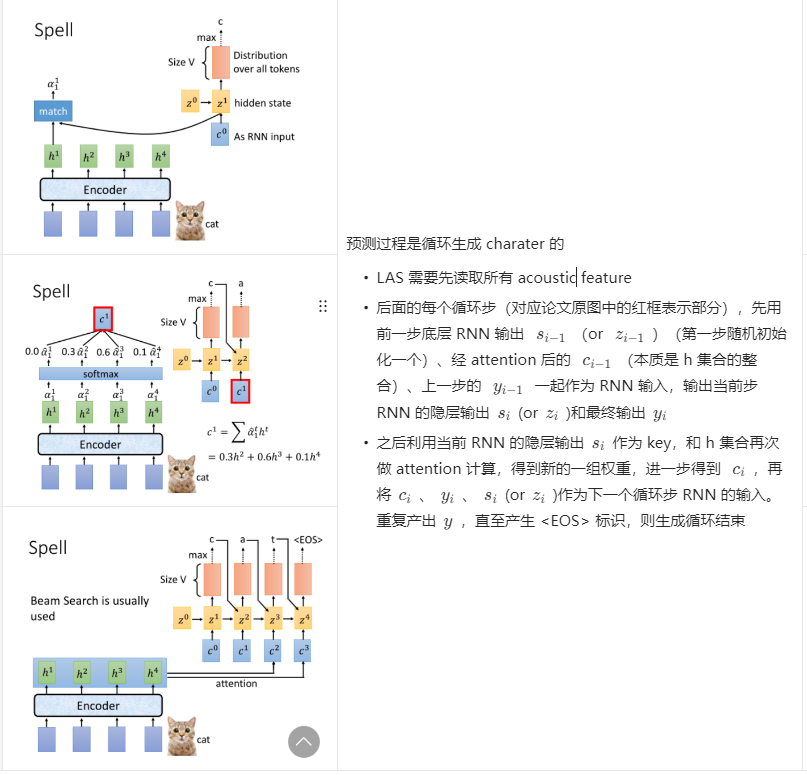
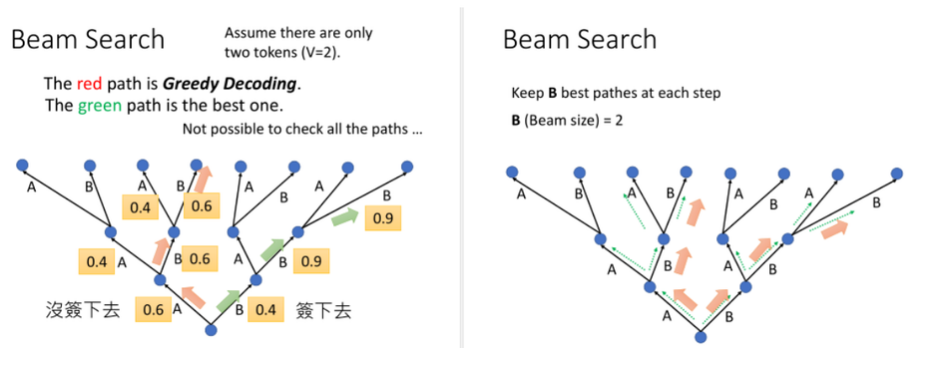
Beam Search
每次搜索最优解是贪心的,会因为局部最优导致最终产生次优解,beam search 设置搜索窗口 K,保持搜索 K 条路径,最后再选择一条累计收益最大的路径。
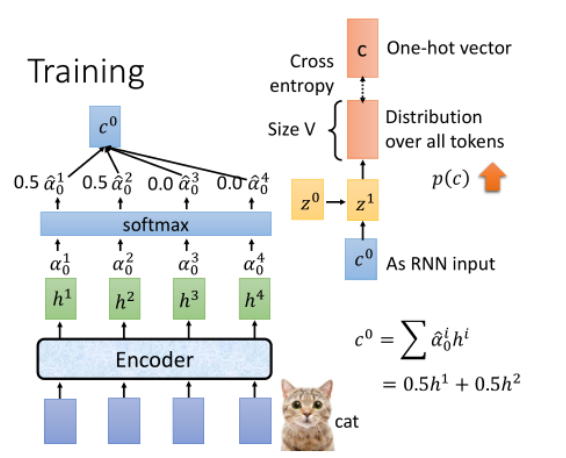
训练过程
训练过程和预测过程类似,只是会在 Speller 的输出部分,将预测结果与真实标签做一次 cross entropy loss 计算,反传梯度更新网络。
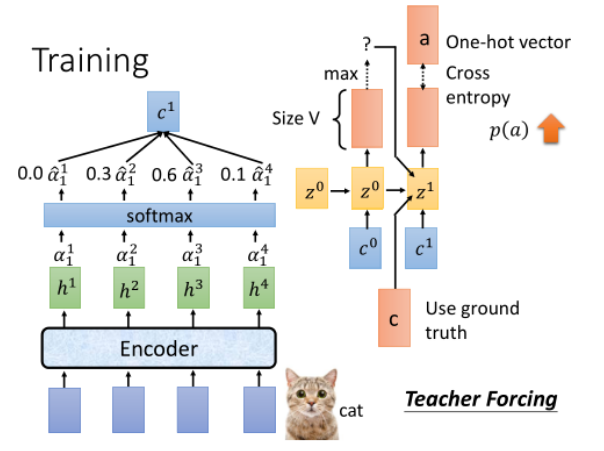
训练时还使用了 Teach Forcing,这个前面的过程其实间接的都介绍完了,就是将上一步的产出(训练过程是 GT)也作为这一步 RNN 的输入。
再说 Attention
之前的注意力阶段,每次是用 Decoder 的输出隐层去与 Encoder 的输出做 attention。
除此以外,还有另外两种方式:
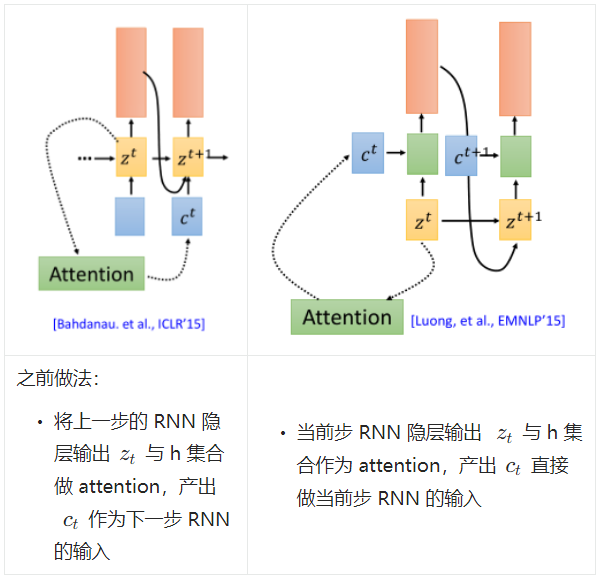
其实 LAS 中是这两种方式同时使用:
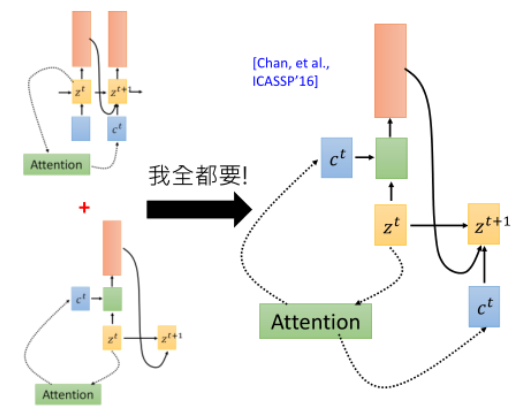
Attention 优化
self-attention 的特性是,注意力区间内任意 token 之间的注意力计算权重是距离无关的(因为都是1),但是语音识别任务中,序列 h 显然是有序的,不能随便跳,所以想出了 location-aware attention。
即把 t 之前的注意力权重 \(\alpha_0\) 到 \(\alpha_{t-1}\) 的向量,做一个线性映射后再输入给解码 RNN。这样模型就能学到,每解码出一个token,注意力就要往右移动一点。
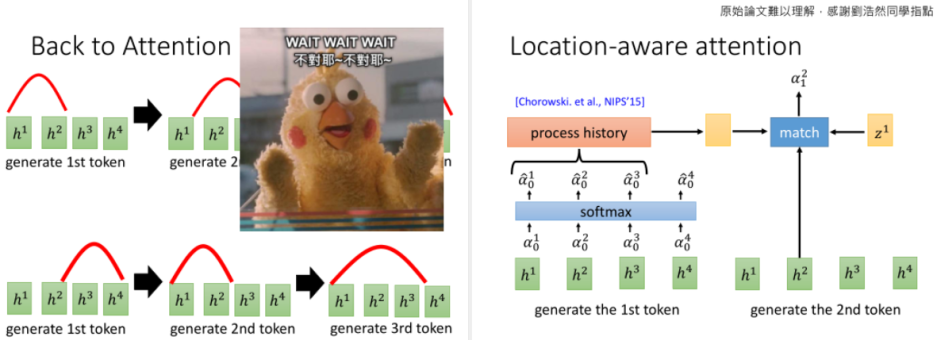
关于 LAS 的效果,这里就不赘述了,可参考 paper 或者参考文章。
参考
2 CTC、RNN-T and more
由于 LAS 网上实在没找到说的比较详细的解说,作为入门语音识别的第一篇 paper,还是要把细节搞清楚的,所以自己写得比较详细。有了 LAS 的基础后,后面的模型就可以快速的阅读其特性了,而且网上也有写的比较好的笔记,为了节省时间,直接参考:https://www.cnblogs.com/yanqiang/p/13267172.html
总结对比图:
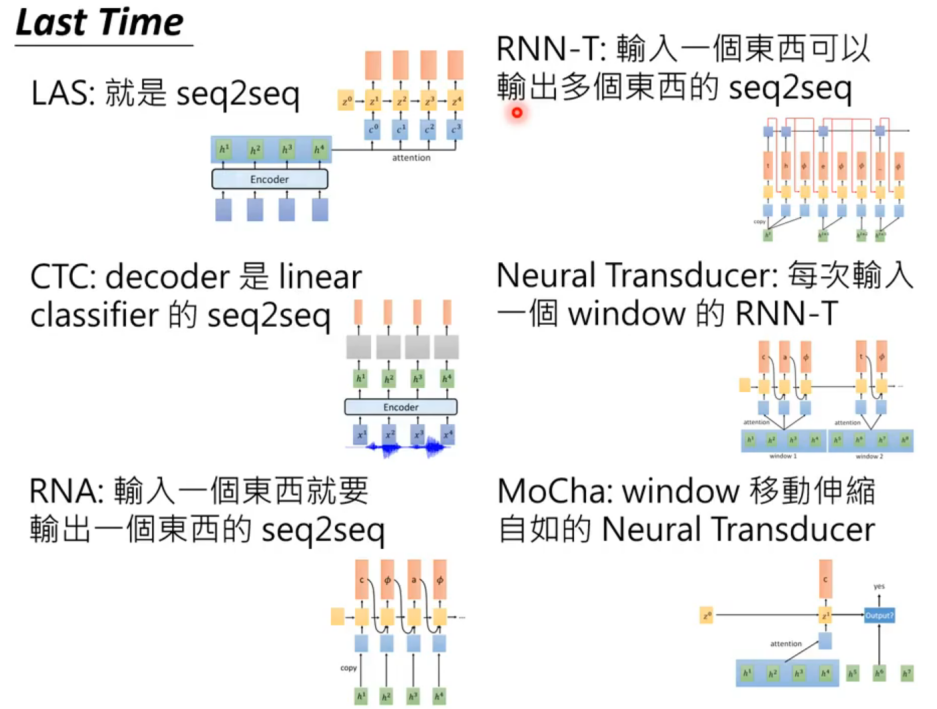
本文来自博客园,作者:sinatJ,转载请注明原文链接:https://www.cnblogs.com/zishu/p/17338560.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号