

容器生态圈之旅--第二章《容器》
第二章 容器

重点先知:
1. 容器技术基础原理
2. docker的基本用法
3. docker镜像管理基础
4. 容器网络
5. docker存储卷
6. dockerfile详解
7. docker仓库
8. docker的系统资源限制及验证
原文分享:http://note.youdao.com/noteshare?id=cfaaab1ea5ecc8472e31313ee2bf3d9f&sub=7395451B766449B180466AECA5834D8E
2.1 前言
依旧记得初次听到容器这个词是在2018年的8月份。
依旧记得那月发生了两件改变我IT轨迹的事:1. 加入小马哥的运维群(骏马金龙:www.junmajinlong.com) 2. 买了马哥的docker和kubernetes视频。
依旧记得那时候的自己完成了某孩的期末架构就自认为自己已经足够强了。
那时候我大二刚结束。
白驹过隙,又是一年,2019年的8月份到了,我大三刚结束。
2019年的7月29号,我开始动笔写下我对于容器这块的总结性笔记。
我有写过docker的系统性博文的:https://blog.csdn.net/zisefeizhu/article/category/7960629 自认为写的蛮好的。
我对容器总结性的一句话概括:容器等于镜像加进程,镜像是应用程序及其依赖环境的封装。
2.3 容器技术基础
统称来说,容器是一种工具,指的是可以装下其它物品的工具,以方便人类归纳放置物品、存储和异地运输,具体来说比如人类使用的衣柜、行李箱、背包等可以成为容器,但今天我们所说的容器是一种IT技术。
容器技术是虚拟化、云计算、大数据之后的一门新兴的并且是炙手可热的新技术,容器技术提高了硬件资源利用率、方便了企业的业务快速横向扩容、实现了业务宕机自愈功能,因此未来数年会是一个容器愈发流行的时代,这是一个对于IT行业来说非常有影响和价值的技术,而对于IT行业的从业者来说,熟练掌握容器技术无疑是一个很有前景的的行业工作机会。
知名的容器技术有:Docker(Docker的同名开源容器化引擎适用于大多数后续产品以及许多开源工具),CSDE(Docker公司拥有扩展Docker的所有权。CSDE支持在Windows服务器上运行docker实例),Rkt(rkt的发音为“rocket”,它是由CoreOS开发的。rkt是Docker容器的主要竞争对手),Solaris Containers(Solaris容器架构比Docker更早出现。想必那些已经在Solaris上标准化的IT企业会继续研究它),Microsoft容器(作为Linux的竞争对手,Microsoft Containers可以在非常特定的情况下支持Windows容器)。
这里我将讲的容器技术是docker,毕竟别的容器技术我都没接触过,招聘简历上也没见过。
Docker是一个在2013年开源的应用程序并且是一个基于go语言编写是一个开源的paas服务(Platform as a Service,平台即服务的缩写),go语言是由google开发,docker公司最早叫dotCloud,后由于Docker开源后大受欢迎就将公司改名为 Docker Inc,总部位于美国加州的旧金山,Docker是基于linux 内核实现,Docker最早采用LXC技术(LinuX Container的简写,LXC是Linux 原生支持的容器技术,可以提供轻量级的虚拟化,可以说 docker 就是基于 LXC 发展起来的,提供 LXC 的高级封装,发展标准的配置方法),源代码托管在 Github 上,而虚拟化技术KVM(Kernel-based Virtual Machine) 基于模块实现,Docker后改为自己研发并开源的runc技术运行容器。
Docker利用现有的Linux容器技术,以不同方式将其封装及扩展(通过提供可移植的镜像及友好的接口),创建(负责创建与运行容器的docker引擎)及发布方案(用来发布容器的云服务docker hub)。
Docker的基本组成:docker client 客户端、docker daemon 守护进程、docker image 镜像、docker container 容器、docker registry 仓库、docker 主机。
Docker 相比虚拟机的交付速度更快,资源消耗更低,Docker 采用客户端/服务端架构,使用远程API来管理和创建Docker容器,其可以轻松的创建一个轻量级的、可移植的、自给自足的容器,docker 的三大理念是build(构建)、ship(运输)、run(运行),Docker遵从apache 2.0协议,并通过(namespace及cgroup等)来提供容器的资源隔离与安全保障等(安全和隔离可以使你可以同时在机器上运行多个容器),所以Docke容器在运行时不需要类似虚拟机(空运行的虚拟机占用物理机6-8%性能)的额外资源开销,因此可以大幅提高资源利用率,总而言之Docker是一种用了新颖方式实现的轻量级虚拟机.类似于VM但是在原理和应用上和VM的差别还是很大的,并且docker的专业叫法是应用容器(Application Container)。
IDC/IAAS/PAAS/SAAS 对比

IAAS:基础架构即服务
PAAS:平台即服务
SAAS:软件即服务
2.3.1docker运行原理
构建 -- > 运输 --> 运行
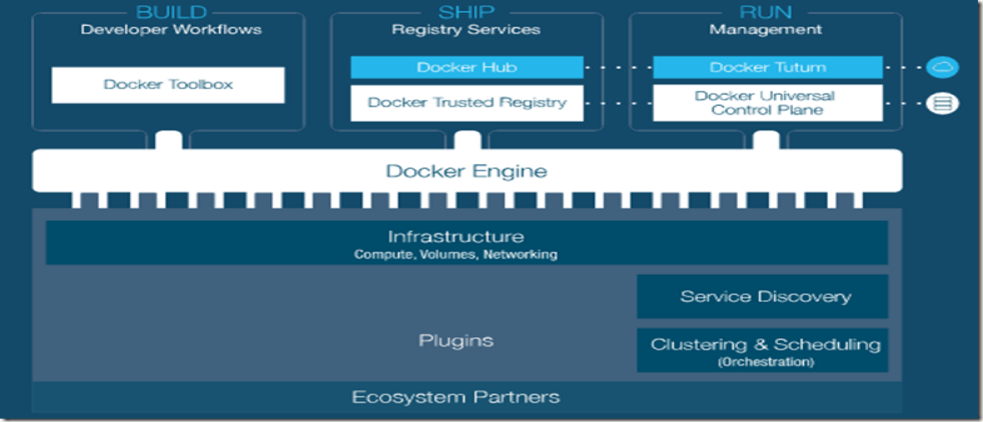
2.3.2 docker架构图
总架构图

主要模块:
DockerClient(与Daemon建立通信,发起容器的管理请求)
DockerDaemon(接收Client请求,处理请求)
Docker Regisrty(镜像管理)
Graph(存储镜像)
Drvier(镜像管理驱动)
libcontainer(系统内核特性,提供完整、明确的接口给Daemon)
Docker Container
各模块功能及实现
Docker Client
Docker架构中用户与Docker Daemon建立通信的客户端。
用户可以使用可执行文件docker作为Docker Client,发起Docker容器的管理请求。
三种方式建立通信:
tcp://host:port
unix://path_to_socket
fd://socketfd
Docker Client发送容器管理请求后,请求由Docker Daemon接收并处理,当Docker Client接收到返回的请求响应并做简单处理后,Docker Client一次完整的生命周期就结束了。
Docker Daemon
常驻在后台的系统进程。
主要作用:
接收并处理Docker Client发送的请求
管理所有的Docker容器
Docker Daemon运行时,会在后台启动一个Server,Server负责接收Docker Client发送的请求;接收请求后,Server通过路由与分发调度,找到相应的Handler来处理请求。
三部分组成:
A.Docker Server
专门服务于Docker Client,接收并调度分发Client请求。
Server通过包gorilla/mux创建mux。Router路由器,提供请求的路由功能,每一个路由项由HTTP请求方法(PUT、POST、GET、DELETE)、URL和Handler组成。
每一个Client请求,Server均会创建一个全新的goroutine来服务,在goroutine中,Server首先读取请求内容,然后做请求解析工作,接着匹配相应的路由项,随后调用相应的Handler来处理,最后Handler处理完请求后给Client回复响应。
B.Engine
核心模块,运行引擎。
存储着大量容器信息,管理着Docker大部分Job的执行。
handlers对象:
存储众多特定Job各自的处理方法handler。
例如:
{"create":daemon.ContainerCreate,}
当执行名为"create"的Job时,执行的是daemon.ContainerCreate这个handler。
C.Job
Engine内部最基本的执行单元,Daemon完成的每一项工作都体现为一个Job。
Docker Registry
存储容器镜像(Docker Image)的仓库。
Docker Image是容器创建时用来初始化容器rootfs的文件系统内容。
主要作用:
搜索镜像
下载镜像
上传镜像
方式:
公有Registry
私有Registry
Graph
容器镜像的保管者。
Driver
驱动模块,通过Driver驱动,Docker实现对Docker容器运行环境的定制,定制的维度包括网络、存储、执行方式。
作用:
将与Docker容器有关的管理从Daemon的所有逻辑中区分开。
实现:
A.graphdriver
用于完成容器镜像管理。
初始化前的四种文件系统或类文件系统的驱动在Daemon中注册:
aufs、btrfs、devmapper用于容器镜像的管理
vfs用于容器volume的管理
B.networkdriver
完成Docker容器网络环境的配置。
C.execdriver
执行驱动,负责创建容器运行时的命名空间,负责容器资源使用的统计与限制,负责容器内部进程的真正运行等。
Daemon启动过程中加载ExecDriverflag参数在配置文件中默认设为native。
libcontainer
使用Go语言设计的库,不依靠任何依赖,直接访问内核中与容器相关的系统调用。
Docker Container
服务交付的最终体现。
用户对Docker容器的配置:
通过指定容器镜像,使得Docker容器可以自定义rootfs等文件系统;
通过指定物理资源的配额,使得Docker容器使用受限的资源;
通过配置容器网络及其安全策略,使得Docker容器拥有独立且安全的网络环境;
通过指定容器的运行命令,使得Docker容器执行指定的任务;
2.3.3 docker架构
Docker使用C/S架构,Client 通过接口与Server进程通信实现容器的构建,运行和发布。client和server可以运行在同一台集群,也可以通过跨主机实现远程通信。
Docker 客户端会与Docker守护进程进行通信。Docker 守护进程会处理复杂繁重的任务,例如建立、运行、发布你的 Docker 容器。
Docker 客户端和守护进程可以运行在同一个系统上,当然也可以使用Docker客户端去连接一个远程的 Docker 守护进程。
Docker 客户端和守护进程之间通过socket或者RESTful API进行通信。

2.3.4 docker的组成
Docker 客户端(Client):Docker 客户端,实际上是 docker 的二进制程序,是主要的用户与 Docker 交互方式。它接收用户指令并且与背后的 Docker 守护进程通信,如此来回往复。
Docker 服务端(Server):Docker守护进程,运行docker容器。Docker守护进程运行在一台主机上。用户并不直接和守护进程进行交互,而是通过 Docker 客户端间接和其通信。
Docker 镜像(Images):Docker 镜像是Docker容器运行时的只读模板,每一个镜像由一系列的层 (layers) 组成。Docker 使用 UnionFS 来将这些层联合到单独的镜像中。UnionFS 允许独立文件系统中的文件和文件夹(称之为分支)被透明覆盖,形成一个单独连贯的文件系统。正因为有了这些层的存在,Docker 是如此的轻量。当你改变了一个 Docker 镜像,比如升级到某个程序到新的版本,一个新的层会被创建。因此,不用替换整个原先的镜像或者重新建立(在使用虚拟机的时候你可能会这么做),只是一个新 的层被添加或升级了。现在你不用重新发布整个镜像,只需要升级层使得分发 Docker 镜像变得简单和快速。
Docker 容器(Container): 容器是从镜像生成对外提供服务的一个或一组服务。Docker 容器和文件夹很类似,一个Docker容器包含了所有的某个应用运行所需要的环境。每一个 Docker 容器都是从 Docker 镜像创建的。Docker 容器可以运行、开始、停止、移动和删除。每一个 Docker 容器都是独立和安全的应用平台,Docker 容器是 Docker 的运行部分。
Docker 仓库(Registry): 保存镜像的仓库,类似于git或svn这样的版本控制系统,官方仓库: https://hub.docker.com/ 。同样的,Docker 仓库也有公有和私有的概念。公有的 Docker 仓库名字是 Docker Hub。Docker Hub 提供了庞大的镜像集合供使用。这些镜像可以是自己创建,或者在别人的镜像基础上创建。Docker 仓库是 Docker 的分发部分。
Docker 主机(Host):一个物理机或虚拟机,用于运行Docker服务进程和容器。

2.3.5 docker对比虚拟机
资源利用率更高:一台物理机可以运行数百个容器,但是一般只能运行数十个虚拟机。
开销更小:容器与主机的操作系统共享资源,提高了效率,性能损耗低
启动速度更快:可以在做到秒级完成启动。
容器具有可移植性
容器是轻量的,可同时运行数十个容器,模拟分布式系统
不必花时间在配置和安装上,无需担心系统的改动,以及依赖关系是否满足

区别:
A.容器只能运行与主机一样的内核
B.容器程序库可以共用
C.容器中执行的进程与主机的进程等价(没有虚拟机管理程序的损耗)
D.隔离能力,虚拟机更高(将容器运行在虚拟机中)
E.使用虚拟机是为了更好的实现服务运行环境隔离,但是一个虚拟机只运行一个服务,很明显资源利用率比较低

2.3.6 docker的优势与缺点
优势
快速部署:短时间内可以部署成百上千个应用,更快速交付到线上。
高效虚拟化:不需要额外的hypervisor支持,直接基于linux 实现应用虚拟化,相比虚拟机大幅提高性能和效率。
节省开支:提高服务器利用率,降低IT 支出。
简化配置:将运行环境打包保存至容器,使用时直接启动即可。
快速迁移和扩展:可夸平台运行在物理机、虚拟机、公有云等环境,良好的兼容性可以方便将应用从A宿主机迁移到B宿主机,甚至是A平台迁移到B平台。
缺点:
隔离性:各应用之间的隔离不如虚拟机。
2.3.7 docker容器的核心技术
容器规范:
除了docker之外的docker技术,还有coreOS的rkt,还有阿里的Pouch,为了保证容器生态的标志性和健康可持续发展,包括Google、Docker等公司共同成立了一个叫open container(OCI)的组织,其目的就是制定开放的标准的容器规范,目前OCI一共发布了两个规范,分别是runtime spec和image format spec,有了这两个规范,不同的容器公司开发的容器只要兼容这两个规范,就可以保证容器的可移植性和相互可操作性。
容器runtime:
runtime是真正运行容器的地方,因此为了运行不同的容器runtime需要和操作系统内核紧密合作相互在支持,以便为容器提供相应的运行环境。
目前主流的三种runtime:
Lxc:linux上早期的runtime,Docker早期就是采用lxc作为runtime。
runc:目前Docker默认的runtime,runc遵守OCI规范,因此可以兼容lxc。
rkt:是CoreOS开发的容器runtime,也符合OCI规范,所以使用rktruntime也可以运行Docker容器。
容器管理工具:
管理工具连接runtime与用户,对用户提供图形或命令方式操作,然后管理工具将用户操作传递给runtime执行。
Lxd是lxc的管理工具。
Runc的管理工具是docker engine,docker engine包含后台deamon和cli两部分,大家经常提到的Docker就是指的docker engine。
Rkt的管理工具是rkt cli。
容器定义工具:
容器定义工具允许用户定义容器的属性和内容,以方便容器能够被保存、共享和重建。
Docker image:是docker 容器的模板,runtime依据docker image创建容器。
Dockerfile:包含N个命令的文本文件,通过dockerfile创建出docker image。
ACI(App container image):与docker image类似,是CoreOS开发的rkt容器的镜像格式。
Registry:
统一保存共享镜像的地方,叫做镜像仓库。
Image registry:docker 官方提供的私有仓库部署工具。
Docker hub:docker官方的公共仓库,已经保存了大量的常用镜像,可以方便大家直接使用。
Harbor:vmware 提供的自带web的镜像仓库,目前有很多公司使用。
编排工具:
当多个容器在多个主机运行的时候,单独管理每个容器是相当复杂而且很容易出错,而且也无法实现某一台主机宕机后容器自动迁移到其他主机从而实现高可用的目的,也无法实现动态伸缩的功能,因此需要有一种工具可以实现统一管理、动态伸缩、故障自愈、批量执行等功能,这就是容器编排引擎。
容器编排通常包括容器管理、调度、集群定义和服务发现等功能。
Docker swarm:docker 开发的容器编排引擎。
Kubernetes:google领导开发的容器编排引擎,内部项目为Borg,且其同时支持docker和rkt。
Mesos+Marathon:通用的集群组员调度平台,mesos与marathon一起提供容器编排引擎功能。
2.3.8 docker容器的依赖技术
容器网络:
docker自带的网络docker network仅支持管理单机上的容器网络,当多主机运行的时候需要使用第三方开源网络,例如calico、flannel等。
服务发现:
容器的动态扩容特性决定了容器IP也会随之变化,因此需要有一种机制开源自动识别并将用户请求动态转发到新创建的容器上,kubernetes自带服务发现功能,需要结合kube-dns服务解析内部域名。 【现在是Core-dns】
容器监控:
可以通过原生命令docker ps/top/stats 查看容器运行状态,另外也可以使heapster/ Prometheus等第三方监控工具监控容器的运行状态。
数据管理:
容器的动态迁移会导致其在不同的Host之间迁移,因此如何保证与容器相关的数据也能随之迁移或随时访问,可以使用逻辑卷/存储挂载等方式解决。
日志收集:
docker 原生的日志查看工具docker logs,但是容器内部的日志需要通过ELK等专门的日志收集分析和展示工具进行处理。
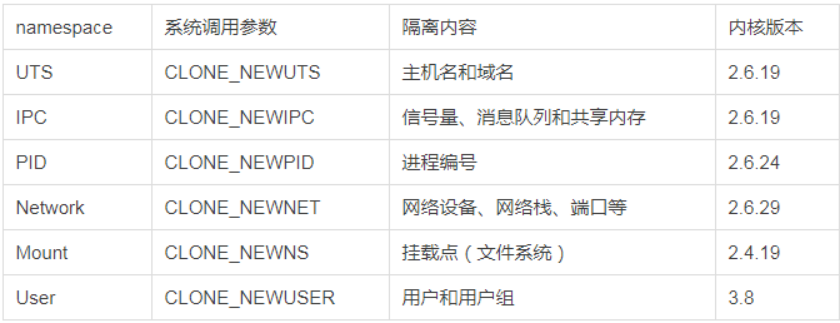
2.3.9 docker命名空间【namespaces】
实现内核级虚拟化(容器)服务,让同一个Namespace下的进程可以感知彼此的变化,同时又能确保对外界的进程一无所知,以达到独立和隔离的目的。
通过查看 /proc 目录下以进程ID作为名称的子目录中的信息,能了解该进程的一组Namespace ID
pid namespace
不同用户的进程就是通过pid namespace隔离开的,且不同 namespace 中可以有相同 PID。
具有以下特征:
每个namespace中的pid是有自己的pid=1的进程(类似 /sbin/init 进程)
每个 namespace 中的进程只能影响自己的同一个 namespace 或子 namespace 中的进程
因为 /proc 包含正在运行的进程,因此在 container 中的 pseudo-filesystem 的 /proc 目录只能看到自己namespace 中的进程
因为 namespace 允许嵌套,父 namespace 可以影响子 namespace 的进程,所以子 namespace 的进程可以在父namespace中看到,但是具有不同的 pid
mnt namespace
类似 chroot,将一个进程放到一个特定的目录执行。mnt namespace 允许不同namespace的进程看到的文件结构不同,这样每个namespace 中的进程所看到的文件目录就被隔离开了。同 chroot 不同,每个 namespace 中的 container 在 /proc/mounts 的信息只包含所在namespace的mount point。
net namespace
网络隔离是通过 net namespace 实现的, 每个 net namespace 有独立的 network devices, IP addresses, IP routing tables, /proc/net 目录。这样每个 container 的网络就能隔离开来。 docker 默认采用 veth 的方式将 container 中的虚拟网卡同 host 上的一个 docker bridge 连接在一起。
uts namespace
UTS ("UNIX Time-sharing System") namespace 允许每个 container 拥有独立的 hostname 和 domain name, 使其在网络上可以被视作一个独立的节点而非 Host 上的一个进程。
ipc namespace
container 中进程交互还是采用 Linux 常见的进程间交互方法 (interprocess communication - IPC), 包括常见的信号量、消息队列和共享内存。然而同 VM 不同,container 的进程间交互实际上还是 host 上具有相同 pid namespace 中的进程间交互,因此需要在IPC资源申请时加入 namespace 信息 - 每个 IPC 资源有一个唯一的 32bit ID。
user namespace
每个 container 可以有不同的 user 和 group id, 也就是说可以以 container 内部的用户在 container 内部执行程序而非 Host 上的用户。
有了以上6种namespace从进程、网络、IPC、文件系统、UTS 和用户角度的隔离,一个 container 就可以对外展现出一个独立计算机的能力,并且不同container从OS层面实现了隔离。然而不同 namespace 之间资源还是相互竞争的,仍然需要类似ulimit 来管理每个container所能使用的资源。
2.3.10 docker资源配额【cgroups】
cgroups是Linux内核提供的一种可以限制、记录、隔离进程组所使用的物理资源(包括CPU、内存、磁盘I/O速度等)的机制,也是容器管理虚拟化系统资源的手段。
查看任意进程在/proc目录下的内容,可以看到一个名为cgroup的文件,每个挂载点都是一个CGroup子系统的根目录
实现了对资源的配额和度量。cgroups的使用非常简单,提供类似文件的接口,在/cgroup目录下新建一个文件夹即可新建一个group,在此文件夹中新建 task 文件,并将 pid 写入该文件,即可实现对该进程的资源控制。具体的资源配置选项可以在该文件夹中新建子 subsystem ,{子系统前缀}.{资源项} 是典型的配置方法, 如 memory.usageinbytes 就定义了该 group 在 subsystem memory 中的一个内存限制选项。
另外,cgroups 中的 subsystem 可以随意组合,一个 subsystem 可以在不同的 group 中,也可以一个 group 包含多个 subsystem - 也就是说一个 subsystem。
在Linux 4.7.1内核中,已经支持了10类不同的子系统,分别如下所示:
hugetlb:
限制进程对大页内存(Hugepage)的使用
memory:
限制进程对内存和Swap的使用,并生成每个进程使用的内存资源报告
pids:
限制每个CGroup中能够创建的进程总数
cpuset:
在多核系统中为进程分配独立CPU和内存
devices:
允许或拒绝进程访问特定设备
net_cls 和 net_prio:
标记每个网络包,并控制网卡优先级
cpu 和 cpuacct:
限制进程对CPU的用量,并生成每个进程所使用的CPU报告
freezer:
挂起或恢复特定的进程
blkio:
为进程对块设备(如磁盘、USB等)限制输入/输出
perf_event:
监测属于特定的CGroup的所有线程以及运行在特定CPU上的线程
2.3.11 docker的工作原理
1)可以建立一个容纳应用程序的容器。
2)可以从Docker镜像创建Docker容器来运行应用程序。
3)可以通过Docker Hub或者自己的Docker仓库分享Docker镜像。
docker镜像是如何工作的
Docker镜像是Docker容器运行时的只读模板,每一个镜像由一系列的层(layers)组成;
Docker使用UnionFS(联合文件系统)来将这些层联合到一二镜像中,UnionFS文件系统允许独立文件系统中的文件和文件夹(称之为分支)被透明覆盖,形成一个单独连贯的文件系统。
正因为有了这些层(layers)的存在,Docker才会如此的轻量。当你改变了一个Docker镜像,比如升级到某个程序到新的版本,一个新的层会被创建。因此,不用替换整个原先的镜像或者重新建立(在使用虚拟机的时候你可能会这么做),只是一个新的层被添加或升级了。所以你不用重新发布整个镜像,只需要升级层,使得分发Docker镜像变得简单和快速。
每个镜像都是从一个基础的镜像开始的,比如ubuntu,一个基础的Ubuntu镜像,或者是Centos,一个基础的Centos镜像。你可以使用你自己的镜像作为新镜像的基础,例如你有一个基础的安装了Nginx的镜像,你可以使用该镜像来建立你的Web应用程序镜像。(Docker通常从Docker Hub获取基础镜像)
Docker镜像从这些基础的镜像创建,通过一种简单、具有描述性的步骤,我们称之为 指令(instructions)。
每一个指令会在镜像中创建一个新的层,指令可以包含这些动作:
1)运行一个命令。
2)增加文件或者文件夹。
3)创建一个环境变量。
4)当运行容器的时候哪些程序会运行。
这些指令存储在Dockerfile文件中。当你需要建立镜像的时候,Docker可以从Dockerfile中读取这些指令并且运行,然后返回一个最终的镜像。
docker仓库是如何工作的
Docker仓库是Docker镜像的存储仓库。可以推送镜像到Docker仓库中,然后在Docker客户端,可以从Docker仓库中搜索镜像。
Docker容器是如何工作的
一个Docker容器包含了一个操作系统、用户添加的文件和元数据(meta-data)。每个容器都是从镜像建立的,镜像告诉Docker容器内包含了什么,当容器启动时运行什么程序,还有许多配置数据。
Docker镜像是只读的,当Docker运行一个从镜像建立的容器,它会在镜像顶部添加一个可读写的层,应用程序可以在这里运行。
当运行docker容器时发生了什么
使用docker命令时,Docker客户端都告诉Docker守护进程运行一个容器。
docker run -i -t ubuntu /bin/bash
可以来分析这个命令,Docker客户端使用docker命令来运行,run参数表明客户端要运行一个新的容器。
Docker客户端要运行一个容器需要告诉Docker守护进程的最少参数信息是:
1)这个容器从哪个镜像创建,这里是ubuntu,基础的Ubuntu镜像。
2)在容器中要运行的命令,这里是/bin/bash,在容器中运行Bash shell。
那么运行这个命令之后在底层发生了什么呢?
按照顺序,Docker做了这些事情:
1)拉取ubuntu镜像: Docker检查ubuntu镜像是否存在,如果在本地没有该镜像,Docker会从Docker Hub下载。如果镜像已经存在,Docker会使用它来创建新的容器。
2)创建新的容器: 当Docker有了这个镜像之后,Docker会用它来创建一个新的容器。
3)分配文件系统并且挂载一个可读写的层: 容器会在这个文件系统中创建,并且一个可读写的层被添加到镜像中。
4)分配网络/桥接接口: 创建一个允许容器与本地主机通信的网络接口。
5)设置一个IP地址: 从池中寻找一个可用的IP地址并且附加到容器上。
6)运行你指定的程序: 运行指定的程序。
7)捕获并且提供应用输出: 连接并且记录标准输出、输入和错误让你可以看到你的程序是如何运行的。
由此你就可以拥有一个运行着的Docker容器了!从这里开始你可以管理你的容器,与应用交互,应用完成之后,可以停止或者删除你的容器。
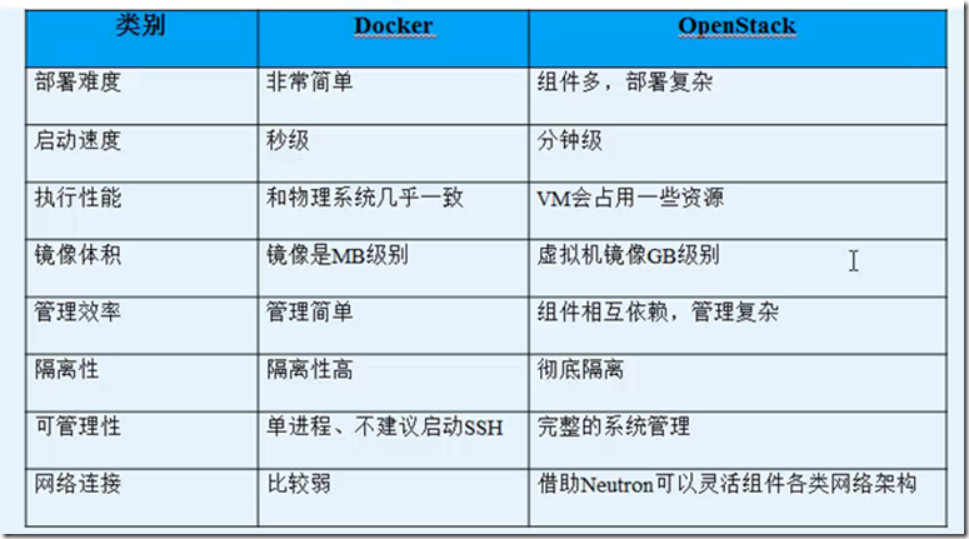
2.3.12 docker与openstack的对比
2.3.13 docker用途
简单配置、代码流水线管理、开发效率、应用隔离、服务器整合、调试能力、多租户、快速部署
2.4 dcker的基本用法
2.4.1 docker安装及验证
官方网址:
系统版本选择:
Docker 目前已经支持多种操作系统的安装运行,比如Ubuntu、CentOS、Redhat、Debian、Fedora,甚至是还支持了Mac和Windows,在linux系统上需要内核版本在3.10或以上,docker版本号之前一直是0.X版本或1.X版本,但是从2017年3月1号开始改为每个季度发布一次稳版,其版本号规则也统一变更为YY.MM,例如18.09表示是2018年9月份发布的,本次演示的操作系统使用Centos 7.6为例,内核4.4。
[root@docker ~]# cat /etc/redhat-release
CentOS Linux release 7.6.1810 (Core)
[root@docker ~]# uname -r
4.4.186-1.el7.elrepo.x86_64
Docker版本选择:
Docker之前没有区分版本,但是2017年推出(将docker更名为)新的项目Moby,github地址:https://github.com/moby/moby,Moby项目属于Docker项目的全新上游,Docker将是一个隶属于的Moby的子产品,而且之后的版本之后开始区分为CE版本(社区版本)和EE(企业收费版),CE社区版本和EE企业版本都是每个季度发布一个新版本,但是EE版本提供后期安全维护1年,而CE版本是4个月,本次演示的Docker版本为19.03。
下载rpm包安装:
官方rpm包下载地址: https://download.docker.com/linux/centos/7/x86_64/stable/Packages/
阿里镜像下载地址:https://mirrors.aliyun.com/docker-ce/linux/centos/7/x86_64/stable/Packages/
通过yum源安装:【常用】
[root@docker ~]# wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@docker ~]# yum repolist
......
* extras: mirrors.aliyun.com --- > extras仓库里有docker安装包,版本可以通过Centos镜像直接查看
......
docker-ce-stable/x86_64 Docker CE Stable - x86_64
#安装
[root@docker ~]# yum install docker-ce
......
正在安装:
docker-ce x86_64 3:19.03.1-3.el7 docker-ce-stable 24 M 52
启动并验证docker服务:
#启动docker服务
[root@docker ~]# systemctl enable docker ; systemctl start docker;systemctl status docker|grep Active
Active: active (running) since 一 2019-07-29 16:37:37 CST; 23s ago
#验证docker信息
[root@docker ~]# docker info
Server Version: 19.03.1
Storage Driver: overlay2
Backing Filesystem: xfs
Supports d_type: true
Native Overlay Diff: true
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host ipvlan macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog
Swarm: inactive
Runtimes: runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 894b81a4b802e4eb2a91d1ce216b8817763c29fb
runc version: 425e105d5a03fabd737a126ad93d62a9eeede87f
init version: fec3683
Security Options:
seccomp
Profile: default
Kernel Version: 4.4.186-1.el7.elrepo.x86_64
Operating System: CentOS Linux 7 (Core)
OSType: linux
Architecture: x86_64
CPUs: 4
Total Memory: 1.936GiB
Name: docker
ID: 6EXA:7EIF:JC2F:W5SG:RG2U:7FDZ:TSI7:TTUF:2OMS:BDX2:TMDF:CFN7
Docker Root Dir: /var/lib/docker
Debug Mode: false
Registry: https://index.docker.io/v1/
Labels:
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: false
在docker安装启动之后,默认会生成一个名称为docker0的网卡并且默认IP地址为172.17.0.1的网卡。
#验证docker0网卡
[root@docker ~]# ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
ether 02:42:22:7f:4a:b1 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 20.0.0.209 netmask 255.255.255.0 broadcast 20.0.0.255
ether 00:0c:29:da:d7:53 txqueuelen 1000 (Ethernet)
RX packets 79925 bytes 109388735 (104.3 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 14335 bytes 1002691 (979.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
#查看docker网络
[root@docker ~]# docker network list
NETWORK ID NAME DRIVER SCOPE
064e0098dd15 bridge bridge local
48cf42c3b371 host host local
4c1006be1ea1 none null local
docker存储引擎
目前docker的默认存储引擎为overlay2,需要磁盘分区支持d-type文件分层功能,因此需要系统磁盘的额外支持。
官方文档关于存储引擎的选择文档:https://docs.docker.com/storage/storagedriver/select-storage-driver/
Docker官方推荐首选存储引擎为overlay2其次为devicemapper,但是devicemapper存在使用空间方面的一些限制,虽然可以通过后期配置解决,但是官方依然推荐使用overlay2,以下是网上查到的部分资料:https://www.cnblogs.com/youruncloud/p/5736718.html
[root@docker ~]# xfs_info /
meta-data=/dev/sda3 isize=512 agcount=4, agsize=1179584 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0 spinodes=0
data = bsize=4096 blocks=4718336, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
如果docker数据目录是一块单独的磁盘分区而且是xfs格式的,那么需要在格式化的时候加上参数-n ftype=1,否则后期在启动容器的时候会报错不支持d-type。
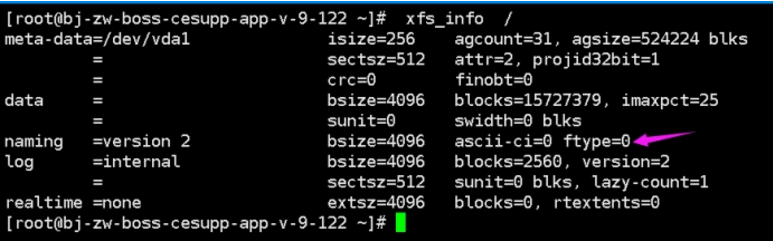
报错界面:

2.4.2 镜像加速
因为国情的原因,国内下载 Docker HUB 官方的相关镜像比较慢,可以使用国内(docker.io)的一些镜像加速器,镜像保持和官方一致,关键是速度块,推荐使用。
这里需要明确一个问题,就是Mirror与Private Registry的区别。二者有着本质的差别:
1)Private Registry(私有仓库)是开发者或者企业自建的镜像存储库,通常用来保存企业内部的 Docker 镜像,用于内部开发流程和产品的发布、版本控制。
2)Mirror是一种代理中转服务,我们(比如daocloud)提供的Mirror服务,直接对接Docker Hub的官方Registry。Docker Hub 上有数以十万计的各类 Docker 镜像。
3)在使用Private Registry时,需要在Docker Pull 或Dockerfile中直接键入Private Registry 的地址,通常这样会导致与 Private Registry 的绑定,缺乏灵活性。
4)使用 Mirror 服务,只需要在 Docker 守护进程(Daemon)的配置文件中加入 Mirror 参数,即可在全局范围内透明的访问官方的 Docker Hub,避免了对 Dockerfile 镜像引用来源的修改。
5)简单来说,Mirror类似CDN(内容分发网络),本质是官方的cache;Private Registry类似私服,跟官方没什么关系。对用户来说,由于用户是要拖docker hub上的image,对应的是Mirror。 yum/apt-get的Mirror又有点不一样,它其实是把官方的库文件整个拖到自己的服务器上做镜像(不管有没有用),并定时与官方做同步;而Docker Mirror只会缓存曾经使用过的image。
目前国内访问docker hub速度上有点尴尬,使用docker Mirror势在必行。
现有国内提供docker镜像加速服务的商家有不少,下面重点介绍几家:
(1). ustc的镜像
ustc是老牌的linux镜像服务提供者了,还在遥远的ubuntu 5.04版本的时候就在用。之前在blog里有提到可以用ustc的docker仓库镜像.
使用方法参考ustc docker镜像使用帮助
ustc的docker镜像加速器速度很不错,一直用的挺happy。ustc docker mirror的优势之一就是不需要注册,真正是公共服务啊。
----------------------------------这里顺便说下在新版Docker里使用ustc的做法-------------------------------------
新版的Docker配置方法:
[root@localhost ~]# vim /etc/docker/daemon.json //如果没有该文件的话,就手动创建。在该文件里添加下面内容
{
"registry-mirrors": ["https://docker.mirrors.ustc.edu.cn"]
}
然后就可以直接docker pull下载镜像了,速度杠杠滴!!!
[root@localhost docker]# docker pull ubuntu
Using default tag: latest
Trying to pull repository docker.io/library/ubuntu ...
latest: Pulling from docker.io/library/ubuntu
d54efb8db41d: Pull complete
f8b845f45a87: Pull complete
e8db7bf7c39f: Pull complete
9654c40e9079: Pull complete
6d9ef359eaaa: Pull complete
Digest: sha256:dd7808d8792c9841d0b460122f1acf0a2dd1f56404f8d1e56298048885e45535
Status: Downloaded newer image for docker.io/ubuntu:latest
[root@localhost ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/ubuntu latest 0ef2e08ed3fa 2 weeks ago 130 MB
----------------------------------------------------------------------------------------------------------------------
(2). daocloud镜像
DaoCloud也提供了docker加速器,但是跟ustc不同,需要用户注册后才能使用,并且每月限制流量10GB。linux上使用比较简单,一条脚本命令搞定:
curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://{your_id}.m.daocloud.io
实际上面的脚本执行后,改的是/usr/lib/systemd/system/docker.service文件,加了个–registry-mirror参数。如果不执行上面的脚本命令,可以如下直接修改这个文件也可:
ExecStart=/usr/bin/docker-current daemon --registry-mirror=http://{your_id}.m.daocloud.io\
设置后,需要重新加载配置&重启:
# systemctl enable docker
# systemctl daemon-reload
# systemctl restart docker
但是最近使用DaoCloud的docker加速器体验非常差,加速效果不是很明显。
(3). alicloud
阿里云也提供了docker加速器,不过比daocloud更麻烦:不光要注册为阿里云的用户,还得加入开发者平台。
不过虽然麻烦,但是它的服务还真是不错,pull速度很溜!配置方法跟daocloud类似,也是开通加速器以后给一个url。
可以直接去改/usr/lib/systemd/system/docker.service:
ExecStart=/usr/bin/docker-current daemon --registry-mirror=https://{your_id}.mirror.aliyuncs.com\
重新加载配置&重启:
# systemctl enable docker
# systemctl daemon-reload
# systemctl restart docker
pull的时候还是显示docker.io,但速度一点都不docker.io。
# docker pull ubuntu
Using default tag: latest
Trying to pull repository docker.io/library/ubuntu ...
latest: Pulling from docker.io/library/ubuntu
cad964aed91d: Pull complete
3a80a22fea63: Pull complete
50de990d7957: Pull complete
61e032b8f2cb: Pull complete
9f03ce1741bf: Pull complete
Digest: sha256:28d4c5234db8d5a634d5e621c363d900f8f241240ee0a6a978784c978fe9c737
Status: Downloaded newer image for docker.io/ubuntu:latest
(4). 网易镜像
网易也提供了Docker镜像服务:网易蜂巢
echo "DOCKER_OPTS=\"\$DOCKER_OPTS --registry-mirror=http://hub-mirror.c.163.com\"" >> /etc/default/docker
service docker restart
综上,虽然aliyun docker mirror用之前的流程有点繁琐,但服务讲真是很不错的。
我在本次学习中使用的是如下:

[root@docker ~]# sudo mkdir -p /etc/docker
[root@docker ~]# sudo tee /etc/docker/daemon.json <<-'EOF'
> {
> "registry-mirrors": ["https://llpuz83z.mirror.aliyuncs.com"]
> }
> EOF
{
"registry-mirrors": ["https://llpuz83z.mirror.aliyuncs.com"]
}
[root@docker ~]# sudo systemctl daemon-reload
[root@docker ~]# sudo systemctl restart docker
[root@docker ~]# docker info
Registry Mirrors:
https://llpuz83z.mirror.aliyuncs.com/
2.4.3 docker镜像基础命令
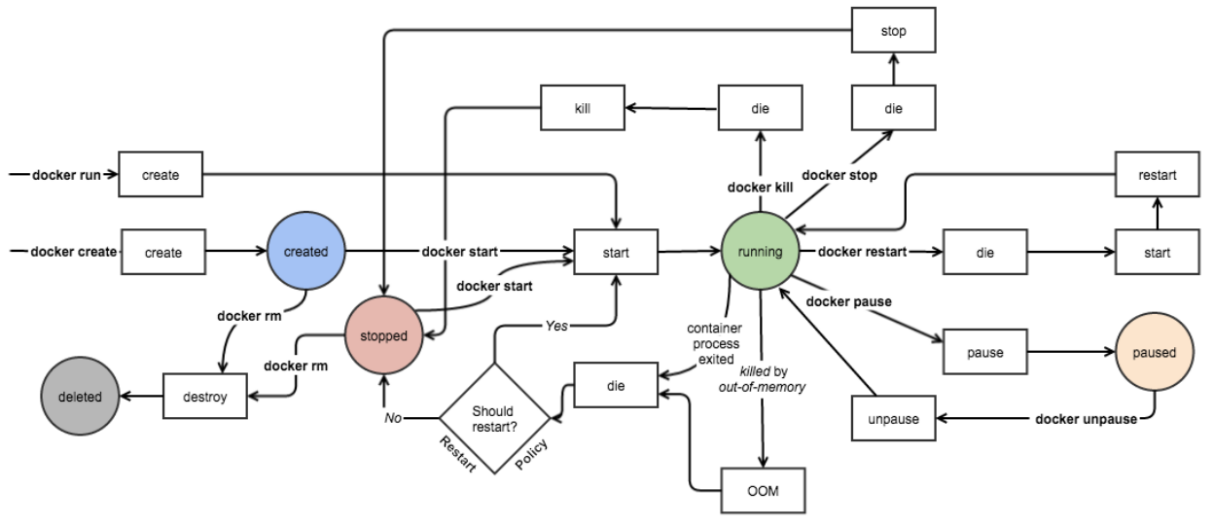
[root@docker ~]# docker --help
Usage: docker [OPTIONS] COMMAND
Commands:
attach Attach to a running container # 当前 shell 下 attach 连接指定运行镜像
build Build an image from a Dockerfile # 通过 Dockerfile 定制镜像
commit Create a new image from a container's changes # 提交当前容器为新的镜像
cp Copy files/folders from the containers filesystem to the host path # 从容器中拷贝指定文件或者目录到宿主机中
create Create a new container # 创建一个新的容器,同 run,但不启动容器
diff Inspect changes on a container's filesystem # 查看 docker 容器变化
events Get real time events from the server # 从 docker 服务获取容器实时事件
exec Run a command in an existing container # 在已存在的容器上运行命令
export Stream the contents of a container as a tar archive # 导出容器的内容流作为一个 tar 归档文件[对应 import ]
history Show the history of an image # 展示一个镜像形成历史
images List images # 列出系统当前镜像
import Create a new filesystem image from the contents of a tarball # 从tar包中的内容创建一个新的文件系统映像[对应 export]
info Display system-wide information # 显示系统相关信息
inspect Return low-level information on a container # 查看容器详细信息
kill Kill a running container # kill 指定 docker 容器
load Load an image from a tar archive # 从一个 tar 包中加载一个镜像[对应 save]
login Register or Login to the docker registry server # 注册或者登陆一个 docker 源服务器
logout Log out from a Docker registry server # 从当前 Docker registry 退出
logs Fetch the logs of a container # 输出当前容器日志信息
port Lookup the public-facing port which is NAT-ed to PRIVATE_PORT # 查看映射端口对应的容器内部源端口
pause Pause all processes within a container # 暂停容器
ps List containers # 列出容器列表
pull Pull an image or a repository from the docker registry server # 从docker镜像源服务器拉取指定镜像或者库镜像
push Push an image or a repository to the docker registry server # 推送指定镜像或者库镜像至docker源服务器
restart Restart a running container # 重启运行的容器
rm Remove one or more containers # 移除一个或者多个容器
rmi Remove one or more images # 移除一个或多个镜像[无容器使用该镜像才可删除,否则需删除相关容器才可继续或 -f 强制删除]
run Run a command in a new container # 创建一个新的容器并运行一个命令
save Save an image to a tar archive # 保存一个镜像为一个 tar 包[对应 load]
search Search for an image on the Docker Hub # 在 docker hub 中搜索镜像
start Start a stopped containers # 启动容器
stop Stop a running containers # 停止容器
tag Tag an image into a repository # 给源中镜像打标签
top Lookup the running processes of a container # 查看容器中运行的进程信息
unpause Unpause a paused container # 取消暂停容器
version Show the docker version information # 查看 docker 版本号
wait Block until a container stops, then print its exit code # 截取容器停止时的退出状态值
大多数子命令下都用选项,需要用到时--help下。
docker 命令是最常使用的命令,其后面可以加不同的参数以实现相应的功能,常用的命令如下:
#查看docker版本信息
[root@docker ~]# docker --version
Docker version 19.03.1, build 74b1e89
[root@docker ~]# docker info
#搜索镜像
在官方的docker 仓库中搜索指定名称的docker镜像,也会有很多三方镜像。
[root@docker ~]# docker search nginx #不带版本号默认latest
[root@docker ~]# docker search nginx:1.17 #带指定版本号
从站点查看搜索镜像
https://hub.docker.com/ -->nginx -->nginx -->Tags
#下载镜像
[root@docker ~]# docker pull busybox
Using default tag: latest
latest: Pulling from library/busybox
ee153a04d683: Pull complete
Digest: sha256:9f1003c480699be56815db0f8146ad2e22efea85129b5b5983d0e0fb52d9ab70
Status: Downloaded newer image for busybox:latest
docker.io/library/busybox:latest
BusyBox是一种特殊类型的程序,它将许多重要程序与标准UNIX命令(如Coreutils) “打包”到一个可执行文件中(有时称为其打包方法)。BusyBox 可执行文件被设计为Linux上最小的可执行文件,与安装每个命令的可执行文件相比,可以大大减少磁盘使用量。因此,应用程序特定的Linux发行版和嵌入式系统都适合,“ 嵌入式Linux的Jittoku刀也称为”。它是GPLv2中发布的免费软件。
从功能上讲,它类似于crunchgen命令,它是1994年由马里兰大学帕克分校的James da Silva开发的FreeBSD程序。
#查看本地镜像
下载完成的镜像比下载的大,因为下载完成后会解压
[root@docker ~]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
busybox latest db8ee88ad75f 10 days ago 1.22MB
REPOSITORY #镜像所属的仓库名称
TAG #镜像版本号(标识符),默认为latest
IMAGE ID #镜像唯一ID标示
CREATED #镜像创建时间
VIRTUAL SIZE #镜像的大小
#删除镜像
[root@docker ~]# docker image rm busybox:latest
Untagged: busybox:latest
Untagged: busybox@sha256:9f1003c480699be56815db0f8146ad2e22efea85129b5b5983d0e0fb52d9ab70
Deleted: sha256:db8ee88ad75f6bdc74663f4992a185e2722fa29573abcc1a19186cc5ec09dceb
Deleted: sha256:0d315111b4847e8cd50514ca19657d1e8d827f4e128d172ce8b2f76a04f3faea
#docker 镜像导入导出(import export)和加载保存(load,save)
save和load是一对,export和import是一对
export和import是对容器来讲的,export时会对容器做快照保存下来,import时可以重新命名镜像,也可以根据文件或url或目录来创建镜像(import命令比较复杂,推荐看文档来尝试)
docker export container_id/container_name > latest.tar
docker import latest.tar image:tag
save和load对镜像来讲的,save时可能会保存所有层,之后可以层回滚(我还没试)
docker save > latest.tar image[:tag] #将image(可指定tag,不指定默认所有)打包
docker load < latest.tar
区别
docker import可以重新指定镜像的名字,docker load不可以
export导出的镜像文件大小 小于 save保存的镜像
我们发现导出后的版本会比原来的版本稍微小一些。那是因为导出后,会丢失历史和元数据。执行下面的命令就知道了:
显示镜像的所有层(layer)
docker images --tree
执行命令,显示下面的内容。正如看到的,导出后再导入(exported-imported)的镜像会丢失所有的历史,而保存后再加载(saveed-loaded)的镜像没有丢失历史和层(layer)。这意味着使用导出后再导入的方式,你将无法回滚到之前的层(layer),同时,使用保存后再加载的方式持久化整个镜像,就可以做到层回滚(可以执行docker tag 来回滚之前的层)。
2.4.4 docker容器操作基础命令
docker最核心的命令:docker run
docker run [选项] [镜像名] [shell命令] [参数]
[root@docker ~]# docker run --help
-d, --detach=false 指定容器运行于前台还是后台,默认为false
-i, --interactive=false 打开STDIN,用于控制台交互
-t, --tty=false 分配tty设备,该可以支持终端登录,默认为false
-u, --user="" 指定容器的用户
-a, --attach=[] 登录容器(必须是以docker run -d启动的容器)
-w, --workdir="" 指定容器的工作目录
-c, --cpu-shares=0 设置容器CPU权重,在CPU共享场景使用
-e, --env=[] 指定环境变量,容器中可以使用该环境变量
-m, --memory="" 指定容器的内存上限
-P, --publish-all=false 指定容器暴露的端口
-p, --publish=[] 指定容器暴露的端口
-h, --hostname="" 指定容器的主机名
-v, --volume=[] 给容器挂载存储卷,挂载到容器的某个目录
--volumes-from=[] 给容器挂载其他容器上的卷,挂载到容器的某个目录
--cap-add=[] 添加权限,权限清单详见:http://linux.die.net/man/7/capabilities
--cap-drop=[] 删除权限,权限清单详见:http://linux.die.net/man/7/capabilities
--cidfile="" 运行容器后,在指定文件中写入容器PID值,一种典型的监控系统用法
--cpuset="" 设置容器可以使用哪些CPU,此参数可以用来容器独占CPU
--device=[] 添加主机设备给容器,相当于设备直通
--dns=[] 指定容器的dns服务器
--dns-search=[] 指定容器的dns搜索域名,写入到容器的/etc/resolv.conf文件
--entrypoint="" 覆盖image的入口点
--env-file=[] 指定环境变量文件,文件格式为每行一个环境变量
--expose=[] 指定容器暴露的端口,即修改镜像的暴露端口
--link=[] 指定容器间的关联,使用其他容器的IP、env等信息
--lxc-conf=[] 指定容器的配置文件,只有在指定--exec-driver=lxc时使用
--name="" 指定容器名字,后续可以通过名字进行容器管理,links特性需要使用名字
--net="bridge" 容器网络设置:
bridge 使用docker daemon指定的网桥
host //容器使用主机的网络
container:NAME_or_ID >//使用其他容器的网路,共享IP和PORT等网络资源
none 容器使用自己的网络(类似--net=bridge),但是不进行配置
--privileged=false 指定容器是否为特权容器,特权容器拥有所有的capabilities
--restart="no" 指定容器停止后的重启策略:
no:容器退出时不重启
on-failure:容器故障退出(返回值非零)时重启
always:容器退出时总是重启
--rm=false 指定容器停止后自动删除容器(不支持以docker run -d启动的容器)
--sig-proxy=true 设置由代理接受并处理信号,但是SIGCHLD、SIGSTOP和SIGKILL不能被代理
#从镜像启动一个容器
会直接进入到容器,并随机生成容器ID和名称
[root@docker ~]# docker run --name b1 -it busybox:latest ---> --name 自定义容器名称
Unable to find image 'busybox:latest' locally ---> 本地没有 就从默认的公有仓库中拉取
latest: Pulling from library/busybox
ee153a04d683: Pull complete
Digest: sha256:9f1003c480699be56815db0f8146ad2e22efea85129b5b5983d0e0fb52d9ab70
Status: Downloaded newer image for busybox:latest
/ # ---> 直接进入到容器
/ # ps ---> 默认情况下进入的是sh
PID USER TIME COMMAND
1 root 0:00 sh
8 root 0:00 ps
/ # ls /
bin dev etc home proc root sys tmp usr var ---> 都是busybox的别名
/ # hostname ---> 随机生成的容器ID
02379c036216
#退出容器不注销
/ # exit ---> exit或者ctrl + d 退出容器 容器是退出的
[root@docker ~]# docker ps ---> 显示正在运行的容器
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[root@docker ~]# docker container ls --->列出正在运行的容器
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[root@docker ~]# docker ps -a ---> 显示所有容器,包括当前正在运行以及已经关闭的所有容器
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
02379c036216 busybox:latest "sh" 4 minutes ago Exited (0) 14 seconds ago b1
[root@docker ~]# docker container ls -a ---> 显示所有容器,包括当前正在运行以及已经关闭的所有容器
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
02379c036216 busybox:latest "sh" 38 minutes ago Exited (1) About a minute ago b1
[root@docker ~]# docker exec -it b1 sh ---> 进入容器
Error response from daemon: Container 02379c036216092f07c46c58361c2da6b5df7d15a733b3c39cfc984cd2dcf314 is not running
[root@docker ~]# docker start b1 ---> 启动暂定的容器
b1
[root@docker ~]# docker exec -it b1 sh
/ # hostname
02379c036216
#容器暂停不删除是对容器原有资源信息无影响的
ctrl +p +q 操作,退出容器,容器依然运行
[root@docker ~]# docker exec -it b1 sh
/ # read escape sequence
[root@docker ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
02379c036216 busybox:latest "sh" 17 minutes ago Up 4 minutes b1
停止容器的另一种方法:
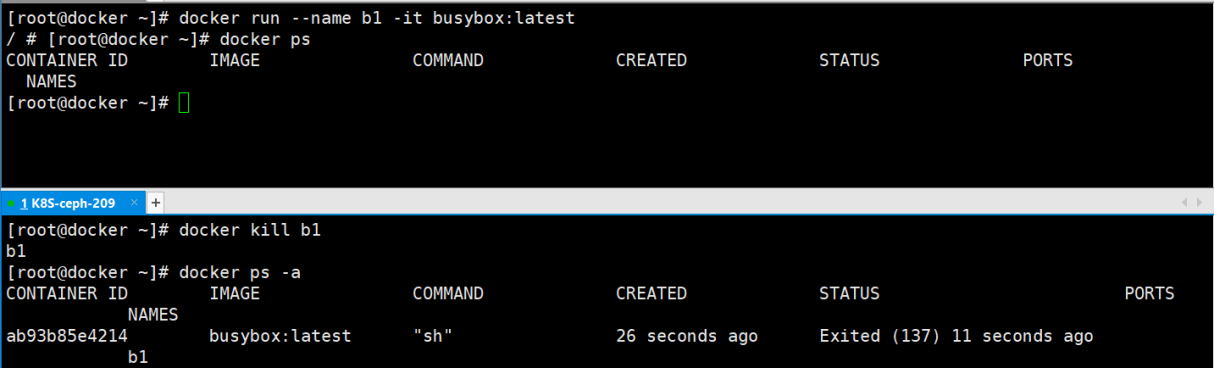
进入容器的方法对比
方法一: docker attach container_NAME/container_ID

注:当多个窗口使用该命令进入该容器时,所有窗口都会显示同步。如果一个窗口阻塞了,其他窗口无法再进行操作;。因此docker attach命令不太适合于生产环境。且该命令有点古老,不太建议使用
方法二:使用ssh 进入docker容器
docker应用容器是一个Linux虚拟主机,那么就可以在该主机上面安装一个ssh server 就可以通过ssh协议来链接该容器
注:这种出力不讨好的方法,了解一下就可以了。
方法三:使用nsenter进入docker容器
对于nsenter网上有比较多且详细的介绍,这里我大致写一下操作过程
nsenter命令需要通过PID进入到容器内部,不过可以使用docker inspect获取到容器的PID
# 安装nsenter
wget https://www.kernel.org/pub/linux/utils/util-linux/v2.24/util-linux-2.24.tar.gz
tar -xzvf util-linux-2.24.tar.gz
cd util-linux-2.24/
./configure --without-ncurses
make nsenter
cp nsenter /usr/local/bin
nsenter --help
# nsenter可以访问另一个进程名称空间。因此我们需要获取容器的PID
docker inspect -f {{.State.Pid}} container_NAME/container_ID // 假设进程号为 4426
nsenter --target 目标PID --mount --uts --ipc --net --pid
简写:
nsenter -t 目标PID -m -u -i -n -p
#--target 4426 目标pid
脚本方式:
将nsenter命令写入到脚本进行调用
vim /service/scripts/docker-in.sh
#!/bin/bash
docker_in(){
NAME_ID=$1
PID=$(docker inspect -f "{{.State.Pid}}" ${NAME_ID})
nsenter -t ${PID} -m -u -i -n -p
}
docker_in $1
chmod a+x /service/scripts/docker-in.sh
#测试脚本是否可以正常进入到容器且退出后仍正常运行
/service/scripts/docker-in.sh container_NAME/container_ID
exit
/service/scripts/docker-in.sh container_NAME/container_ID
exit
注:个人理解nsenter:通过容器在宿主机中的pid进行通讯
因此:nsenter需要在宿主机安装而非容器或者镜像
方法四:docker exec 命令
[root@docker ~]# docker exec --help
Usage: docker exec [OPTIONS] CONTAINER COMMAND [ARG...]
Run a command in a running container
Options:
-d, --detach Detached mode: run command in the background
--detach-keys string Override the key sequence for detaching a container
-e, --env list Set environment variables
-i, --interactive Keep STDIN open even if not attached
--privileged Give extended privileges to the command
-t, --tty Allocate a pseudo-TTY
-u, --user string Username or UID (format: <name|uid>[:<group|gid>])
-w, --workdir string Working directory inside the container
[root@docker ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
02379c036216 busybox:latest "sh" 33 minutes ago Up 12 minutes b1
[root@docker ~]# docker exec -it b1 sh
注:最常用的方法!!!
#删除运行中的容器
即使容器正在运行中,也会被强制删除
[root@docker ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
02379c036216 busybox:latest "sh" 39 minutes ago Up 2 seconds b1
[root@docker ~]# docker container rm -f b1
b1
[root@docker ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
端口映射
#随机映射端口
[root@docker ~]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
busybox latest db8ee88ad75f 11 days ago 1.22MB
[root@docker ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[root@docker ~]# docker pull nginx
docker.io/library/nginx:latest

注:随机端口映射,其实默认是从1024开始
浏览器访问

#指定端口映射
方式1:本地端口81映射到容器80端口:
# docker run -d -p 81:80 --name nginx-test-port1 nginx --> -d 后台启动容器
方式2:本地IP:本地端口:容器端口
# docker run -d -p 20.0.0.209:82:80 --name nginx-test-port2 docker.io/nginx
方式3:本地IP:本地随机端口:容器端口
# docker run -d -p 20.0.0.209::80 --name nginx-test-port3 docker.io/nginx
方式4:本机ip:本地端口:容器端口/协议,默认为tcp协议
# docker run -d -p 20.0.0.209:83:80/udp --name nginx-test-port4 docker.io/nginx
方式5:一次性映射多个端口+协议:
# docker run -d -p 86:80/tcp -p 443:443/tcp -p 53:53/udp --name nginx-test-port5 docker.io/nginx
查看容器的日志
#一次查看
[root@docker ~]# docker logs nginx-test-port2
20.0.0.1 - - [30/Jul/2019:03:42:17 +0000] "GET / HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
20.0.0.1 - - [30/Jul/2019:03:42:17 +0000] "GET /favicon.ico HTTP/1.1" 404 555 "http://20.0.0.209:82/" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
2019/07/30 03:42:17 [error] 6#6: *2 open() "/usr/share/nginx/html/favicon.ico" failed (2: No such file or directory), client: 20.0.0.1, server: localhost, request: "GET /favicon.ico HTTP/1.1", host: "20.0.0.209:82", referrer: "http://20.0.0.209:82/"
#持续查看
[root@docker ~]# docker logs -f nginx-test-port2
20.0.0.1 - - [30/Jul/2019:03:42:17 +0000] "GET / HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
20.0.0.1 - - [30/Jul/2019:03:42:17 +0000] "GET /favicon.ico HTTP/1.1" 404 555 "http://20.0.0.209:82/" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
2019/07/30 03:42:17 [error] 6#6: *2 open() "/usr/share/nginx/html/favicon.ico" failed (2: No such file or directory), client: 20.0.0.1, server: localhost, request: "GET /favicon.ico HTTP/1.1", host: "20.0.0.209:82", referrer: "http://20.0.0.209:82/"
20.0.0.1 - - [30/Jul/2019:03:43:07 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
20.0.0.1 - - [30/Jul/2019:03:43:08 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
20.0.0.1 - - [30/Jul/2019:03:43:08 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
20.0.0.1 - - [30/Jul/2019:03:43:08 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
20.0.0.1 - - [30/Jul/2019:03:43:08 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
查看容器已经映射的端口
[root@docker ~]# docker port nginx-test-port3
80/tcp -> 20.0.0.209:1024
容器退出后自动删除
[root@docker ~]# docker run -it --rm --name nginx nginx bash
传递运行命令
容器需要有一个前台运行的进程才能保持容器的运行,通过传递运行参数是一种方式,另外也可以在构建镜像的时候指定容器启动时运行的前台命令。
[root@docker ~]# docker run -d centos /usr/bin/tail -f '/etc/hosts'
[root@docker ~]# docker ps -l
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c8a7605ede61 centos "/usr/bin/tail -f /e…" 32 seconds ago Up 31 seconds strange_curie
容器的启动和关闭
docker stop/start container_NAME/container_ID
批量操作
#批量关闭正在运行的容器
[root@docker ~]# docker stop $(docker ps -a -q) --->正常关闭所有运行中的容器
#批量强制关闭正在运行的容器
[root@docker ~]# docker kill $(docker ps -a -q) --->强制关闭所有运行中的容器
#批量删除已退出的容器
[root@docker ~]# docker rm -f `docker ps -aq -f status=exited`
#批量删除所有容器
[root@docker ~]# docker rm -f `docker ps -a -q`
一个例子
[root@docker ~]# docker run --name text -it --network bridge -h zisefeizhu.com --dns 223.6.6.6 --rm busybox:latest
/ # hostname
zisefeizhu.com
/ # cat /etc/resolv.conf
nameserver 223.6.6.6
/ # exit
[root@docker ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2.5 docker镜像技术
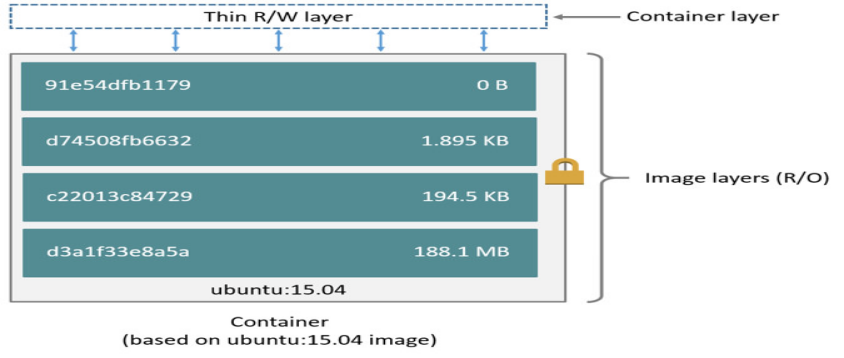
一个镜像是一个惰性的,不可变的文件,它本质上是一个容器的快照。它只是一个模板,其中包含有关创建Docker容器的说明。
镜像存储在Docker仓库中,例如registry.hub.docker.com。因为它们可能变得非常大,所以镜像被设计为由其他镜像的层组成,允许在通过网络传输图像时发送最少量的数据。
docker 镜像是一个只读的 docker 容器模板,含有启动 docker 容器所需的文件系统结构及其内容,因此是启动一个 docker 容器的基础。docker 镜像的文件内容以及一些运行 docker 容器的配置文件组成了 docker 容器的静态文件系统运行环境:rootfs。可以这么理解,docker 镜像是 docker 容器的静态视角,docker 容器是 docker 镜像的运行状态。我们可以通过下图来理解 docker daemon、docker 镜像以及 docker 容器三者的关系(此图来自互联网):
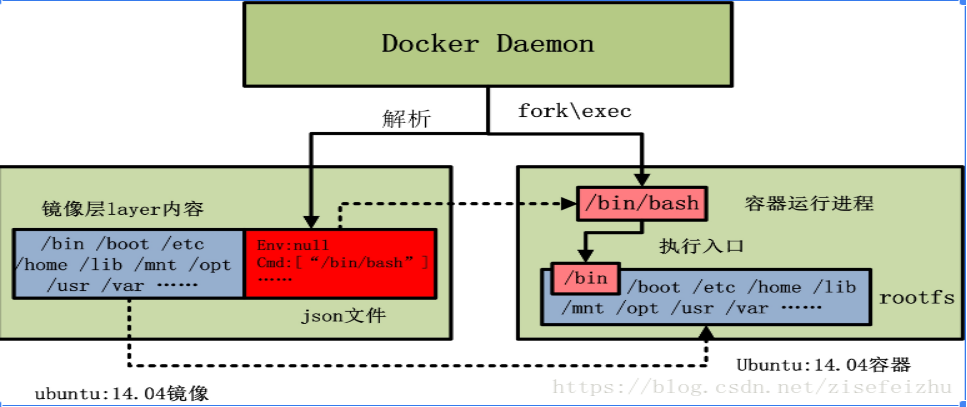
从上图中我们可以看到,当由 ubuntu:14.04 镜像启动容器时,ubuntu:14.04 镜像的镜像层内容将作为容器的 rootfs;而 ubuntu:14.04 镜像的 json 文件,会由 docker daemon 解析,并提取出其中的容器执行入口 CMD 信息,以及容器进程的环境变量 ENV 信息,最终初始化容器进程。当然,容器进程的执行入口来源于镜像提供的 rootfs。
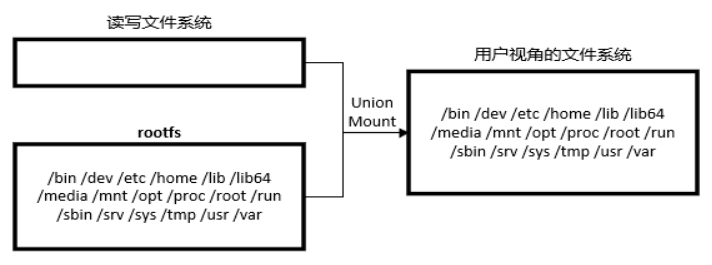
rootfs
rootfs 是 docker 容器在启动时内部进程可见的文件系统,即 docker 容器的根目录。rootfs 通常包含一个操作系统运行所需的文件系统,例如可能包含典型的类 Unix 操作系统中的目录系统,如 /dev、/proc、/bin、/etc、/lib、/usr、/tmp 及运行 docker 容器所需的配置文件、工具等。
在传统的 Linux 操作系统内核启动时,首先挂载一个只读的 rootfs,当系统检测其完整性之后,再将其切换为读写模式。而在 docker 架构中,当 docker daemon 为 docker 容器挂载 rootfs 时,沿用了 Linux 内核启动时的做法,即将 rootfs 设为只读模式。在挂载完毕之后,利用联合挂载(union mount)技术在已有的只读 rootfs 上再挂载一个读写层。这样,可读写的层处于 docker 容器文件系统的最顶层,其下可能联合挂载了多个只读的层,只有在 docker 容器运行过程中文件系统发生变化时,才会把变化的文件内容写到可读写层,并隐藏只读层中的旧版本文件。
2.5.1 Docker 镜像的主要特点
为了更好的理解 docker 镜像的结构,下面介绍一下 docker 镜像设计上的关键技术。
分层
docker 镜像是采用分层的方式构建的,每个镜像都由一系列的 "镜像层" 组成。分层结构是 docker 镜像如此轻量的重要原因。当需要修改容器镜像内的某个文件时,只对处于最上方的读写层进行变动,不覆写下层已有文件系统的内容,已有文件在只读层中的原始版本仍然存在,但会被读写层中的新版本所隐藏。当使用 docker commit 提交这个修改过的容器文件系统为一个新的镜像时,保存的内容仅为最上层读写文件系统中被更新过的文件。分层达到了在不的容器同镜像之间共享镜像层的效果。
分层技术——aufs

Aufs是Another Union File System的缩写,支持将多个目录挂载到同一个虚拟目录下。
已构建的镜像会设置成只读模式,read-write写操作是在read-only上的一种增量操作,固不影响read-only层。
这个研究有一个好处,比如我们现在可以看到手机里面的APP,在命令里面都会用APP字段下回来,在下回来之前它就是一个静态的,我们没有往里面写东西,但是我们启动起来以后,我们就可以往里面写东西,进行各种各样的操作。但是如果我们把它关掉了以后,或者删除了以后,它的这个镜像是存在远端的,所以在这个镜像里面是不会去修改的。并且这样也会有一个非常好的地方,这个场景非常适合我们去实现测试环境,因为我们的测试环境经常会有一个操作就是灌数据,我们可以提前把这个镜像数据打包到测试里面,那么这个镜像软件里面包含了,最上面是nginx,比如它里面会有一些数据,我们可以在往上面打一层数据,打完之后把它起成一个容器就可以去测试,测试完之后这个容器里面会生成各种各样的数据,也就是脏数据,这样的话,我们就可以把这个容器删掉,删掉以后我们镜像里面的容器是不会受影响的。如果说它想再创建一套,我们可以把这个镜像再启一个容器,就可以是一个一模一样的,并且是一个干净的环境。
我们先来看一个Ubuntu系统的镜像

我们看见镜像可以分层很多个layer,并且他们都有大小和ID,我们可以看到这里有4个layer ID号,最终这个镜像是由他们layer组合而成,并且这个镜像它是只读的,它不能往里面写数据,如果想写数据怎么办呢?我们会在镜像上启一层contain layer,其实就是相当于把镜像启动成一个容器,那么在容器这一层,我们是可写的。
比如我们想在Ubuntu这个系统上加一层,只能在上面继续叠加,这些工作其实都是由cow,写字库下的机制来实现的。
写时复制
docker 镜像使用了写时复制(copy-on-write)的策略,在多个容器之间共享镜像,每个容器在启动的时候并不需要单独复制一份镜像文件,而是将所有镜像层以只读的方式挂载到一个挂载点,再在上面覆盖一个可读写的容器层。在未更改文件内容时,所有容器共享同一份数据,只有在 docker 容器运行过程中文件系统发生变化时,才会把变化的文件内容写到可读写层,并隐藏只读层中的老版本文件。写时复制配合分层机制减少了镜像对磁盘空间的占用和容器启动时间。
内容寻址
在 docker 1.10 版本后,docker 镜像改动较大,其中最重要的特性便是引入了内容寻址存储(content-addressable storage) 的机制,根据文件的内容来索引镜像和镜像层。与之前版本对每个镜像层随机生成一个 UUID 不同,新模型对镜像层的内容计算校验和,生成一个内容哈希值,并以此哈希值代替之前的 UUID 作为镜像层的唯一标识。该机制主要提高了镜像的安全性,并在 pull、push、load 和 save 操作后检测数据的完整性。另外,基于内容哈希来索引镜像层,在一定程度上减少了 ID 的冲突并且增强了镜像层的共享。对于来自不同构建的镜像层,主要拥有相同的内容哈希,也能被不同的镜像共享。
联合挂载
通俗地讲,联合挂载技术可以在一个挂载点同时挂载多个文件系统,将挂载点的原目录与被挂载内容进行整合,使得最终可见的文件系统将会包含整合之后的各层的文件和目录。实现这种联合挂载技术的文件系统通常被称为联合文件系统(union filesystem)。以下图所示的运行 Ubuntu:14.04 镜像后的容器中的 aufs 文件系统为例:
由于初始挂载时读写层为空,所以从用户的角度看,该容器的文件系统与底层的 rootfs 没有差别;然而从内核的角度看,则是显式区分开来的两个层次。当需要修改镜像内的某个文件时,只对处于最上方的读写层进行了变动,不复写下层已有文件系统的内容,已有文件在只读层中的原始版本仍然存在,但会被读写层中的新版本文件所隐藏,当 docker commit 这个修改过的容器文件系统为一个新的镜像时,保存的内容仅为最上层读写文件系统中被更新过的文件。
联合挂载是用于将多个镜像层的文件系统挂载到一个挂载点来实现一个统一文件系统视图的途径,是下层存储驱动(aufs、overlay等) 实现分层合并的方式。所以严格来说,联合挂载并不是 docker 镜像的必需技术,比如在使用 device mapper 存储驱动时,其实是使用了快照技术来达到分层的效果。
2.5.2 docker镜像的存储组织方式
综合考虑镜像的层级结构,以及 volume、init-layer、可读写层这些概念,一个完整的、在运行的容器的所有文件系统结构可以用下图来描述:
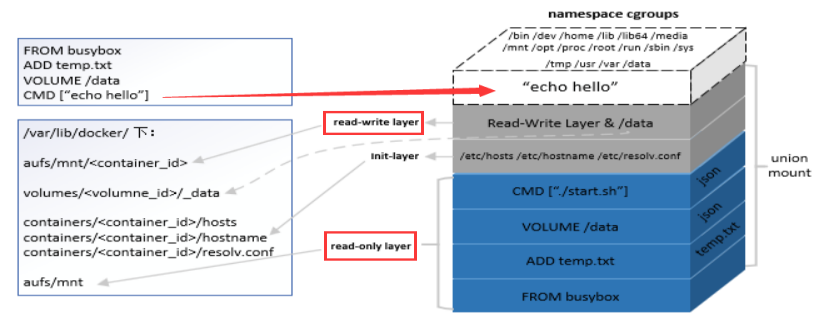
从图中我们不难看到,除了 echo hello 进程所在的 cgroups 和 namespace 环境之外,容器文件系统其实是一个相对独立的组织。可读写部分(read-write layer 以及 volumes)、init-layer、只读层(read-only layer) 这 3 部分结构共同组成了一个容器所需的下层文件系统,它们通过联合挂载的方式巧妙地表现为一层,使得容器进程对这些层的存在一无所知。
2.5.3 docker镜像中的关键概念
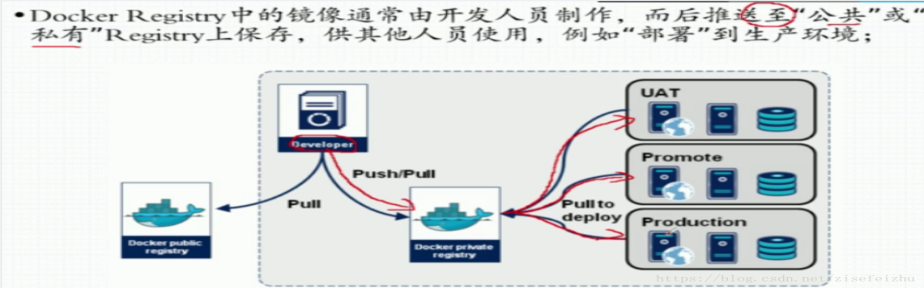
registry
我们知道,每个 docker 容器都要依赖 docker 镜像。那么当我们第一次使用 docker run 命令启动一个容器时,是从哪里获取所需的镜像呢?
答案是,如果是第一次基于某个镜像启动容器,且宿主机上并不存在所需的镜像,那么 docker 将从 registry 中下载该镜像并保存到宿主机。如果宿主机上存在该镜像,则直接使用宿主机上的镜像完成容器的启动。
那么 registry 是什么呢?
registry 用以保存 docker 镜像,其中还包括镜像层次结构和关于镜像的元数据。可以将 registry 简单的想象成类似于 Git 仓库之类的实体。
用户可以在自己的数据中心搭建私有的 registry,也可以使用 docker 官方的公用 registry 服务,即 Docker Hub。它是由 Docker 公司维护的一个公共镜像库。Docker Hub 中有两种类型的仓库,即用户仓库(user repository) 与顶层仓库(top-level repository)。用户仓库由普通的 Docker Hub 用户创建,顶层仓库则由 Docker 公司负责维护,提供官方版本镜像。理论上,顶层仓库中的镜像经过 Docker 公司验证,被认为是架构良好且安全的。
分类:
Sponsor Registry: 第三方的registry,供客户和Docker社区使用
Mirror Registry: 第三方的registry,只让客户使用
Vendor Registry: 由发布Docker镜像的供应商提供的registry
Private Registry: 通过设有防火墙和额外的安全层的私有实体提供的registry
repository
repository 由具有某个功能的 docker 镜像的所有迭代版本构成的镜像组。Registry 由一系列经过命名的 repository 组成,repository 通过命名规范对用户仓库和顶层仓库进行组织。所谓的顶层仓库,其其名称只包含仓库名,如:

而用户仓库的表示类似下面:

可以看出,用户仓库的名称多了 "用户名/" 部分。
比较容易让人困惑的地方在于,我们经常把 mysql 视为镜像的名称,其实 mysql 是 repository 的名称。repository 是一个镜像的集合,其中包含了多个不同版本的镜像,这些镜像之间使用标签进行版本区分,如 mysql:5.6、mysql:5.7 等,它们均属于 mysql 这个 repository。
简单来说,registry 是 repository 的集合,repository 是镜像的集合。
manifest
manifest(描述文件)主要存在于 registry 中作为 docker 镜像的元数据文件,在 pull、push、save 和 load 过程中作为镜像结构和基础信息的描述文件。在镜像被 pull 或者 load 到 docker 宿主机时,manifest 被转化为本地的镜像配置文件 config。在我们拉取镜像时显示的摘要(Digest):就是对镜像的 manifest 内容计算 sha256sum 得到的。

image 和 layer
docker 内部的 image 概念是用来存储一组镜像相关的元数据信息,主要包括镜像的架构(如 amd64)、镜像默认配置信息、构建镜像的容器配置信息、包含所有镜像层信息的 rootfs。docker 利用 rootfs 中的 diff_id 计算出内容寻址的索引(chainID) 来获取 layer 相关信息,进而获取每一个镜像层的文件内容。
layer(镜像层) 是 docker 用来管理镜像层的一个中间概念。我们前面提到,镜像是由镜像层组成的,而单个镜像层可能被多个镜像共享,所以 docker 将 layer 与 image 的概念分离。docker 镜像管理中的 layer 主要存放了镜像层的 diff_id、size、cache-id 和 parent 等内容,实际的文件内容则是由存储驱动来管理,并可以通过 cache-id 在本地索引到。
2.5.4 获取docker镜像的方法
docker.hub
现在docker官方公有仓库里面有大量的镜像,所以最基础的镜像,我们可以在公有仓库直接拉取,因为这些镜像都是原厂维护,可以得到及时的更新和修护。
Dockerfile:
我们如果想去定制这些镜像,我们可以去编写Dockerfile,然后重新bulid,最后把它打包成一个镜像,这种方式是最为推荐的方式包括我们以后去企业当中去实践应用的时候也是推荐这种方式。
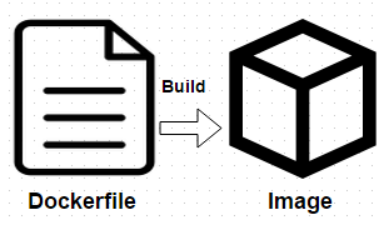
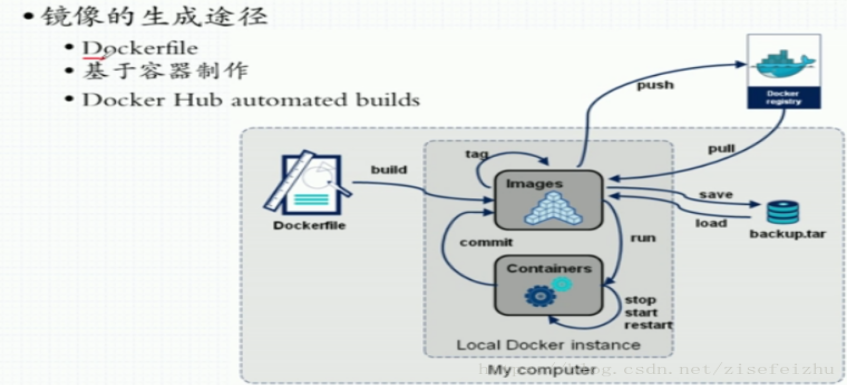
Commit :
当然还有另外一种方式,就是通过镜像启动一个容器,然后进行操作,最终通过commit这个命令commit一个镜像,但是不推荐这种方式,虽然说通过commit这个命令像是操作虚拟机的模式,但是容器毕竟是容器,它不是虚拟机,所以大家还是要去适应用Dockerfile去定制这些镜像这种习惯。
[root@docker ~]# docker commit --help
Usage: docker commit [OPTIONS] CONTAINER [REPOSITORY[:TAG]]
Create a new image from a container's changes
Options:
-a, --author string Author (e.g., "John Hannibal Smith <hannibal@a-team.com>")
-c, --change list Apply Dockerfile instruction to the created image
-m, --message string Commit message
-p, --pause Pause container during commit (default true)
2.5.5 镜像的一个例子详解
#从默认仓库拉取buxybox镜像,默认为docker.hub
[root@docker ~]# docker pull buxybox
#查看主机现有镜像
[root@docker ~]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
busybox latest db8ee88ad75f 13 days ago 1.22MB
#用buxybox镜像启动一个名称为b1的容器
[root@docker ~]# docker run --name b1 -it busybox
/ # ls /
bin dev etc home proc root sys tmp usr var
#在b1容器中创先一个index.html
/ # mkdir -p /data/html
/ # vi /data/html/index.html
/ # cat /data/html/index.html
#ctrl+p+q退出容器不关闭
<h1> Busybox httpd server. </h1>
/ # [root@docker ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7b030688d7c6 busybox "sh" About a minute ago Up About a minute b1
#利用b1容器创建新镜像
[root@docker ~]# docker commit -p b1
sha256:470b5b0a5f15cf5270634f4ae53c227592114e45eeba925468f662f710b26a12
#因为在用commit创建镜像时未指明镜像名称,所以为none
[root@docker ~]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
<none> <none> 470b5b0a5f15 14 seconds ago 1.22MB
busybox latest db8ee88ad75f 13 days ago 1.22MB
#给镜像打标签,类似与硬连接。
[root@docker ~]# docker tag 470b5b0a5f15 zisefeizhu/httpd:v0.1-1
[root@docker ~]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
zisefeizhu/httpd v0.1-1 470b5b0a5f15 About a minute ago 1.22MB
busybox latest db8ee88ad75f 13 days ago 1.22MB
[root@docker ~]# docker tag zisefeizhu/httpd:v0.1-1 zhujingxing/httpd:latest
[root@docker ~]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
zhujingxing/httpd latest 470b5b0a5f15 2 minutes ago 1.22MB
zisefeizhu/httpd v0.1-1 470b5b0a5f15 2 minutes ago 1.22MB
busybox latest db8ee88ad75f 13 days ago 1.22MB
#删除镜像类似于删除硬链接。关于文件的删除原理在此不声明,必须要懂!
[root@docker ~]# docker image rm zisefeizhu/httpd:v0.1-1
Untagged: zisefeizhu/httpd:v0.1-1
#获取镜像源/容器数据,json 格式
[root@docker ~]# docker inspect -f '{{.ContainerConfig.Cmd}}' busybox
[/bin/sh -c #(nop) CMD ["sh"]]
[root@docker ~]# docker inspect -f '{{.ContainerConfig.Cmd}}' zhujingxing/httpd:latest
[sh]
[root@docker ~]# docker run -it --name t1 zhujingxing/httpd:latest
/ # ls /
bin data dev etc home proc root sys tmp usr var
/ # cat /data/html/index.html
<h1> Busybox httpd server. </h1>
/ # [root@docker ~]#
[root@docker ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7cf93b2d56be zhujingxing/httpd:latest "sh" 6 minutes ago Up 6 minutes t1
7b030688d7c6 busybox "sh" 22 minutes ago Up 22 minutes b1
[root@docker ~]# docker commit -a "zisefeizhu <zisefeizhu@zhujingxing.com>" -c 'CMD ["/bin/httpd","-f","-h","/data/html"]' -p b1 zisefeizhu/httpd:v0.2
sha256:9f0e2f6192bf72cb2230e9654d92985bbbd77a800f749a58fa72e496dd28f452
[root@docker ~]# docker run --name t2 zisefeizhu/httpd:v0.2
前台运行 卡住 另开一个窗口
[root@docker ~]# docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a39c73488430 zisefeizhu/httpd:v0.2 "/bin/httpd -f -h /d…" 12 seconds ago Up 11 seconds t2
7cf93b2d56be zhujingxing/httpd:latest "sh" 9 minutes ago Up 9 minutes t1
7b030688d7c6 busybox "sh" 25 minutes ago Up 25 minutes b1
[root@docker ~]# docker inspect -f '{{.Config.Cmd}}' t2
[/bin/httpd -f -h /data/html]
[root@docker ~]# docker inspect -f '{{.NetworkSettings.IPAddress}}' t2
172.17.0.4
[root@docker ~]# curl 172.17.0.4
<h1> Busybox httpd server. </h1>
2.5.6 共享存储
注:我建议还是自建仓库harbor,所以这部分,在此不提,后面讲“docker 仓库”会重点介绍harbor。有兴趣的同道可以看此篇博文:https://blog.csdn.net/zisefeizhu/article/details/83378322
2.6 docker容器网络
在开始的时候就有提过,现在的linux内核已经支持六种名称空间:
UTS:主机名和域名
USER:用户
Mount:挂载文件系统
IPC:进程间通信
Pid:进程id
Net:网络
网络作为docker容器化实现的6个名称空间的其中之一,是必不可少的。其在Linux内核2.6时已经被加载进内核支持了。
网络名称空间主要用于实现网络设备和协议栈的隔离。
2.6.1 理解网络虚拟化
网络虚拟化相对计算、存储虚拟化来说是比较抽象的,以我们在学校书本上学的那点网络知识来理解网络虚拟化可能是不够的。
在我们的印象中,网络就是由各种网络设备(如交换机、路由器)相连组成的一个网状结构,世界上的任何两个人都可以通过网络建立起连接。
带着这样一种思路去理解网络虚拟化可能会感觉云里雾里——这样一个庞大的网络如何实现虚拟化?
其实,网络虚拟化更多关注的是数据中心网络、主机网络这样比较「细粒度」的网络,所谓细粒度,是相对来说的,是深入到某一台物理主机之上的网络结构来谈的。
如果把传统的网络看作「宏观网络」的话,那网络虚拟化关注的就是「微观网络」。网络虚拟化的目的,是要节省物理主机的网卡设备资源。从资源这个角度去理解,可能会比较好理解一点。
2.6.2 传统网络架构
在传统网络环境中,一台物理主机包含一个或多个网卡(NIC),要实现与其他物理主机之间的通信,需要通过自身的 NIC 连接到外部的网络设施,如交换机上,如下图所示。

这种架构下,为了对应用进行隔离,往往是将一个应用部署在一台物理设备上,这样会存在两个问题
1)是某些应用大部分情况可能处于空闲状态
2)是当应用增多的时候,只能通过增加物理设备来解决扩展性问题。不管怎么样,这种架构都会对物理资源造成极大的浪费。
2.6.3 虚拟化网络架构
为了解决这个问题,可以借助虚拟化技术对一台物理资源进行抽象,将一张物理网卡虚拟成多张虚拟网卡(vNIC),通过虚拟机来隔离不同的应用。
这样对于上面的问题
针对问题 1),可以利用虚拟化层 Hypervisor (系统管理程序)的调度技术,将资源从空闲的应用上调度到繁忙的应用上,达到资源的合理利用;
针对问题 2),可以根据物理设备的资源使用情况进行横向扩容,除非设备资源已经用尽,否则没有必要新增设备。
这种架构如下所示:
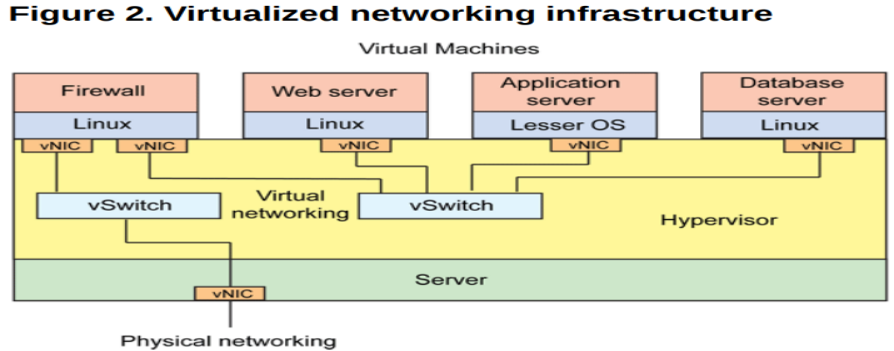
其中虚拟机与虚拟机之间的通信,由虚拟交换机完成,虚拟网卡和虚拟交换机之间的链路也是虚拟的链路,整个主机内部构成了一个虚拟的网络,如果虚拟机之间涉及到三层的网络包转发,则又由另外一个角色——虚拟路由器来完成。
一般,这一整套虚拟网络的模块都可以独立出去,由第三方来完成,如其中比较出名的一个解决方案就是 Open vSwitch(OVS)。
OVS 的优势在于它基于 SDN 的设计原则,方便虚拟机集群的控制与管理,另外就是它分布式的特性,可以「透明」地实现跨主机之间的虚拟机通信。
如下是跨主机启用 OVS 通信的:
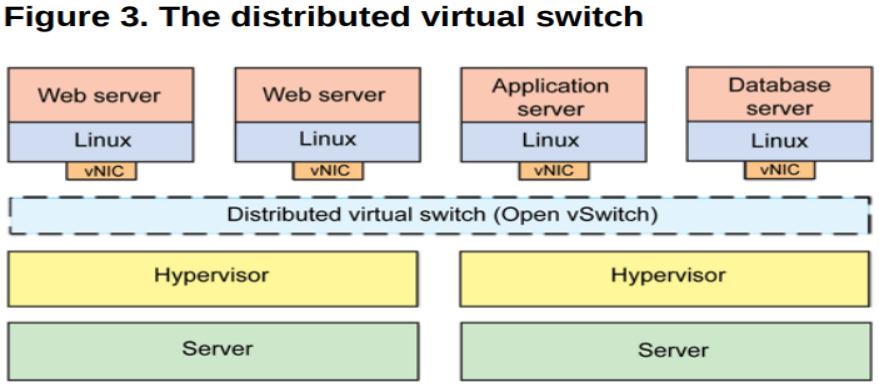
总结下来,网络虚拟化主要解决的是虚拟机构成的网络通信问题,完成的是各种网络设备的虚拟化,如网卡、交换设备、路由设备等。
2.6.4 linux下网络设备虚拟化的几种形式
为了完成虚拟机在同主机和跨主机之间的通信,需要借助某种“桥梁”来完成用户态到内核态(Guest 到 Host)的数据传输,这种桥梁的角色就是由虚拟的网络设备来完成,上面介绍了一个第三方的开源方案——OVS,它其实是一个融合了各种虚拟网络设备的集大成者,是一个产品级的解决方案。
但 Linux 本身由于虚拟化技术的演进,也集成了一些虚拟网络设备的解决方案,主要有以下几种:
TAP/TUN/VETH
TAP/TUN 是 Linux 内核实现的一对虚拟网络设备,TAP 工作在二层,TUN 工作在三层。Linux 内核通过 TAP/TUN 设备向绑定该设备的用户空间程序发送数据,反之,用户空间程序也可以像操作物理网络设备那样,向 TAP/TUN 设备发送数据。
基于 TAP 驱动,即可实现虚拟机 vNIC 的功能,虚拟机的每个 vNIC 都与一个 TAP 设备相连,vNIC 之于 TAP 就如同 NIC 之于 eth。
当一个 TAP 设备被创建时,在 Linux 设备文件目录下会生成一个对应的字符设备文件,用户程序可以像打开一个普通文件一样对这个文件进行读写。
比如,当对这个 TAP 文件执行 write 操作时,相当于 TAP 设备收到了数据,并请求内核接受它,内核收到数据后将根据网络配置进行后续处理,处理过程类似于普通物理网卡从外界收到数据。当用户程序执行 read 请求时,相当于向内核查询 TAP 设备是否有数据要发送,有的话则发送,从而完成 TAP 设备的数据发送。
TUN 则属于网络中三层的概念,数据收发过程和 TAP 是类似的,只不过它要指定一段 IPv4 地址或 IPv6 地址,并描述其相关的配置信息,其数据处理过程也是类似于普通物理网卡收到三层 IP 报文数据。
VETH 设备总是成对出现,一端连着内核协议栈,另一端连着另一个设备,一个设备收到内核发送的数据后,会发送到另一个设备上去,这种设备通常用于容器中两个 namespace 之间的通信。
Bridge
Bridge 也是 Linux 内核实现的一个工作在二层的虚拟网络设备,但不同于 TAP/TUN 这种单端口的设备,Bridge 实现为多端口,本质上是一个虚拟交换机,具备和物理交换机类似的功能。
Bridge 可以绑定其他 Linux 网络设备作为从设备,并将这些从设备虚拟化为端口,当一个从设备被绑定到 Bridge 上时,就相当于真实网络中的交换机端口上插入了一根连有终端的网线。
如下图所示,Bridge 设备 br0 绑定了实际设备 eth0 和 虚拟设备 tap0/tap1,当这些从设备接收到数据时,会发送给 br0 ,br0 会根据 MAC 地址与端口的映射关系进行转发。
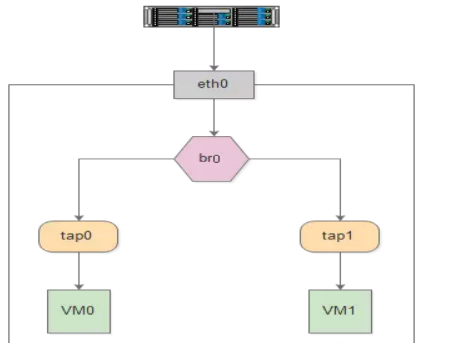
因为 Bridge 工作在二层,所以绑定到它上面的从设备 eth0、tap0、tap1 均不需要设 IP,但是需要为 br0 设置 IP,因为对于上层路由器来说,这些设备位于同一个子网,需要一个统一的 IP 将其加入路由表中。
这里有人可能会有疑问,Bridge 不是工作在二层吗,为什么会有 IP 的说法?其实 Bridge 虽然工作在二层,但它只是 Linux 网络设备抽象的一种,能设 IP 也不足为奇。
对于实际设备 eth0 来说,本来它是有自己的 IP 的,但是绑定到 br0 之后,其 IP 就生效了,就和 br0 共享一个 IP 网段了,在设路由表的时候,就需要将 br0 设为目标网段的地址。
2.6.5 跨主机docker容器通信方案介绍
NET:网络名称空间
描述:主要是网络设备、协议栈等实现,假设物理机上有四块网卡,需要创建两个名称空间,这些设备可以单独关联给某个空间所使用的,如第一个网卡分配给第一个名称空间使用,其他就看不见这个设备了,一个设备一般只能授予一个空间,同样有四个网卡就可以使用四个名称空间,使得每个名称空间都可以配置IP地址与外界进行通信。
如果名称空间的数量超过物理网卡数量,每个名称空间内部的进程也是需要通过网络进行通信,应该如何上报,可以使用模拟技术,linux设备支持两种内核级的模拟,是二层设备和三层设备,网卡就是一个二层设备,工作在链路层,能够封装报文实现各设备之间报文转发的实现,这功能是完全可以在Linux之上利用内核中对二层虚拟设备的支持,创建虚拟网卡接口,而且这种虚拟网卡接口很独特,每个网络接口设备是成对出现的,可以模拟为一根网线的两头,其中一头可以插在主机之上,另一头插在交换机之上进行模拟,相当于一个主机连接到交换机上去了,而linux内核源生就支持模拟二层网络设备,使用软件来构建一个交换机。
如果有两个名称空间,那么两台主机就像连接到同一个交换机上进行通信,如果配置的网络地址在同一个网段就可以直接进行通讯了。这就是虚拟化的网络。
OVS: OpenVSwitch 可以模拟高级的网络技术,二层交换,甚至三层网络设备,vlan,,不属于Linux内核组件,要额外安装,由cisco众多公司所构建的,有云计算的浪潮下,构建网络是比较复杂的,然后才是网络之上所承载的主机,才能通讯,这个网络虚拟化所实现的功能,需要软件硬件结合起来实现,而且把传统意义上的网络平面,控制平面,传输平面等,隔离开来,集中到一个设备之上实现全局的调度,实现SDN,软件定义网络。
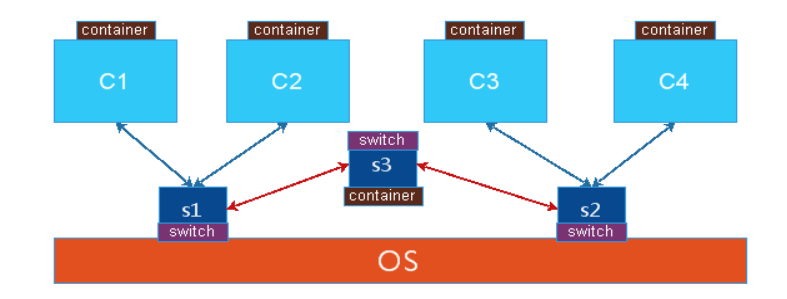
单节点上容器通讯:同一个物理机上的两个容器,或者两个名称空间要通讯,就是在主机上建立一个虚拟的交换机,让两个容器各自使用纯软件的方式,建一对虚拟网卡,一半在交换机上,一半在容器上,从而实现单节点上容器进行通讯,但是也有比较复杂的情况,有可能会出现有两个软交换机的情况,连接不同的容器,这时两个软交换机要连接,需要再做一块网卡,一头在交换机1上,另一头在交换机2之上,如果不同交换机之间要实现路由转发,就需要在两能交换机上加一台路由器,linux内核自身可以当作路由器来使用,打开转发或者使用iptables规则,但是路由器是一个三层的设备,在linux内核直接使用一个单独的名称空间就可以实现,就是再做一个容器当作路由器来使用,但是要模拟出网卡来让它们建立关联关系。
多节点:另一台主机上的一个容器,与1号主机上的容器进行通信,vmware实现不同主机上的虚拟机之间的通讯可以使用桥接的方式,就是把物理网卡当作交换机来使用,所有一台主机上的容器都到一个物理网卡来,通过MAC地址来确定交给那个容器,如果是到物理机的,就给物理机,也就是虚拟机里也有自身的独特的MAC地址,所以数据包来时可以区别各个设备,把物理网卡当作交换机来使用,把报文转发给各容器,如果报文目标是物理网卡时,需要虚拟出一个软网卡作为物理网卡的使用,这样就没有虚拟交换机概念,所以两台主机上的虚拟机要使用桥接通讯时,都是连接到各自主机上的物理网卡的的。但是这种通讯方式要实现有很大的代价,因为所有容器的桥接都在同一个平面中,很容易产生风暴,所以在大规模的虚拟机或容器的使用场景中使用桥接不太好,除非能隔离得很好(桥接)。
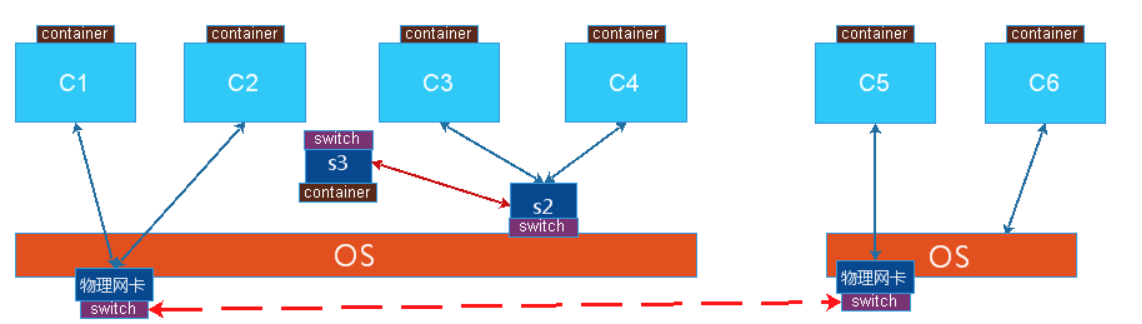
Nat技术:如图中C3与C6通讯,C3是虚拟网卡,C3网卡与物理网卡物理地址不在同一个网段中,C3把网关指向S2,把S3当作宿主机的一个网卡来使用,IP地址与C3在同一个网段,把C3的网关指向S2,然后在物理机上打开核心转发功能,所以当C3与C6通讯时,先转给s2,再到达内核,内核判定查路由列不是自己要到另一个主机上的C6,这时报文回不来,因为C3和C4是一个私有地址,如果要报文能够回来,最后到报文送走物理机之前,要把源IP地址修改成物理网卡的IP地址,这样C5或者C6回复物理主机的IP就可以了,通过NAT表的查询是C3的访问,就把报文送给C3,这就使用NAT实现跨主机之间的通讯,但是这里有一个很大的问题,C6也可能是NAT的模式下工作,也就是说它也是使用私有地址的,如果C6要被访问只能把它暴露出去,在物理机的能外网卡上明确说明某个端口是提供服务的,如果要C4能够访问C6,就要先访问C6所在的宿主机的物理地址,再使用S2做dnat发给C6,但是C4发送报文时是通过SNAT出来的,C4也是隐藏在NAT背后的,发出去的报文要其他的主机可以响应就应该改写源地址。所以在跨服务主机实现两个虚拟机之间的通讯要实现两级的NAT操作,从C4到C6,首先C4出去就SNAT,到到C6要使用到DNAT,这样的效率不会高,但是网络比较容易管理。
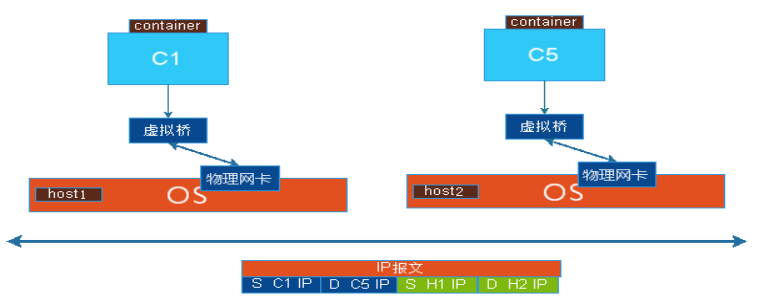
Overlay Network: 叠加网络,是NAT和桥接的一个解决方案,有多个物理主机,在虚拟机上做一个虚拟的桥,让各虚拟机连接到虚拟桥上,通信时借用物理网络来完成报文的隧道转发,从而实现C1可以直接看见C5或C6,物理主机本来就是使用物理网络连接在一起的,C1与物理网络不在同一个地址段内,但是C1与C5是在同一地址段内的,C1发送报文时,先发送给虚拟机,假设它是知道C5是不要本地的物理主机上的,以是报文要从物理网卡发送出去,但是要做隧道转发,也就是C1的报文源IP地址是C1,目标地址是C5,然后再封装一个IP包头的首部源地址是C1所在物理主机的IP地址,目标地址是C5所在物理主机的IP地址,当报文送到C5所在的物理机,把报文拆完第一层后,第二层的目标地址就是C5的,就直接交给本地的软交换机,再交给C5,C1与C5之间的通讯直接源地址和目标地址就是各自双方,但是它寄于别的网络,本地自身就是一个三层的网络,应该封装二层,但是没有封装,又封装三层四层报文,就是一个TCP或者UDP的首部,再封装一个首部实现一个两级的三层封装,从而完成报文的转发
2.6.5.1 其他方案
基于实现方式的分类
隧道方案(Overlay Networking):
Weave:UDP广播,本机建立新的BR,通过PCAP互通。
Open vSwitch(OVS):基于VxLAN和GRE协议,但是性能方面损失比较严重。
Flannel:UDP广播,VxLan。
路由方案:
Calico:基于BGP协议的路由方案,支持很细致的ACL控制,对混合云亲和度比较高。
Macvlan:从逻辑和Kernel层来看隔离性和性能最优的方案,基于二层隔离,所以需要二层路由器支持,大多数云服务商不支持,所以混合云上比较难以实现。
基于网络模型分类
Docker Libnetwork Container Network Model(CNM):
Docker Swarm overlay
Macvlan & IP network drivers
Calico
Contiv(from Cisco)
#Docker Libnetwork的优势就是原生,而且和Docker容器生命周期结合紧密;缺点也可以理解为是原生,被Docker“绑架”。
Container Network Interface(CNI):
Kubernetes
Weave
Macvlan
Flannel
Calico
Contiv
Mesos CNI
#CNI的优势是兼容其他容器技术(e.g. rkt)及上层编排系统(Kuberneres & Mesos),而且社区活跃势头迅猛,Kubernetes加上CoreOS主推;缺点是非Docker原生。
既然聊到了k8s 简单阐述一下:dockerd shim containerd kubelet runc 的关系
dockerd是docker的守护进程
containerd是处理dockerd收到的请求的
shim是处理信号量的
runc是启动容器的
kubelet是k8s中用来管理节点容器生命周期的
它们的关系应该是kubelet--->pod--->dockerd--->containerd--->shim--->runc--->container
详解:
以Flannel方案为例
Flannel之前的名字是Rudder,它是由CoreOS团队针对Kubernetes设计的一个重载网络工具,它的主要思路是:预先留出一个网段,每个主机使用其中一部分,然后每个容器被分配不同的ip;让所有的容器认为大家在同一个直连的网络,底层通过UDP/VxLAN等进行报文的封装和转发
下面这张是Flannel网络的经典架构图:

- 容器直接使用目标容器的ip访问,默认通过容器内部的eth0发送出去。
- 报文通过veth pair被发送到vethXXX。
- vethXXX是直接连接到虚拟交换机docker0的,报文通过虚拟bridge docker0发送出去。
- 查找路由表,外部容器ip的报文都会转发到flannel0虚拟网卡,这是一个P2P的虚拟网卡,然后报文就被转发到监听在另一端的flanneld。
- flanneld通过etcd维护了各个节点之间的路由表,把原来的报文UDP封装一层,通过配置的iface发送出去。
- 报文通过主机之间的网络找到目标主机。
- 报文继续往上,到传输层,交给监听在8285端口的flanneld程序处理。
- 数据被解包,然后发送给flannel0虚拟网卡。
- 查找路由表,发现对应容器的报文要交给docker0。
- docker0找到连到自己的容器,把报文发送过去
关于docker网络解决方案,强烈建议参考“散尽浮华”前辈的博文:https://www.cnblogs.com/kevingrace/category/839227.html
注:关于“散尽浮华”前辈,我有必要说一下:此乃我IT路上的良师和精神支柱!
关于docker网络解决方案,我本人更推荐使用calico方案。关于calico 网络插件会在kubernetes章节重点阐述
docker 网络是深入学习docker的重点、难点,强烈建议:一定要耐着性子深入学习这部分。
2.6.6 单机网络
[root@docker ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
1fbc952b8c69 bridge bridge local
48cf42c3b371 host host local
4c1006be1ea1 none null local
bridge:默认网络驱动程序。当你的应用程序在需要通信的独立容器中运行时,通常会使用桥接网络。
host:对于独立容器,删除容器和Docker主机之间的网络隔离,并直接使用主机的网络。
none:对于此容器,禁用所有网络。
container: Container 网络模式是 Docker 中一种较为特别的网络的模式。处于这个模式下的 Docker 容器会共享其他容器的网络环境,因此,至少这两个容器之间不存在网络隔离,而这两个容器又与宿主机以及除此之外其他的容器存在网络隔离。
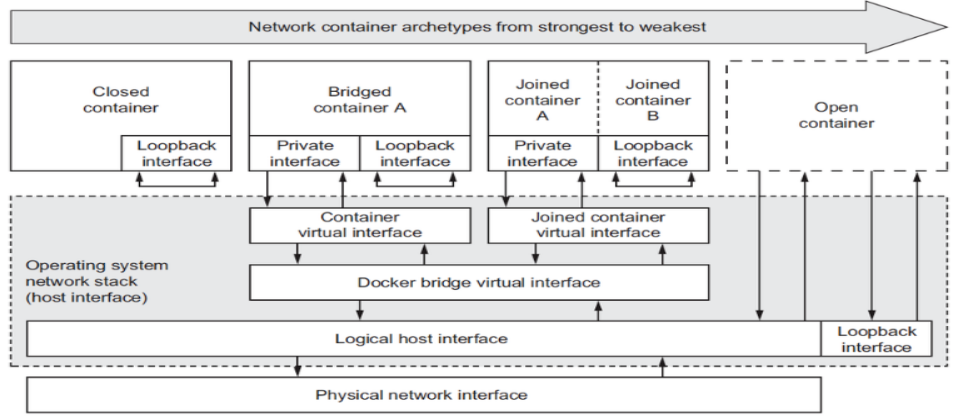
bridge 模式【默认网络模式】
桥接时网络,并不是物理桥,在本机上创建一个纯粹的软交换机docker0,也可以当作网卡来使用,每启动一个容器就可以给容器分配一段网卡的地址,一半在容器上,一半在docker0桥上,veth176661b这种在机器可以看到的无论容器还是KVM时,每次创建网卡时,都是创建一对的,一半放在虚拟机上,一半放在软交换机上,相当于一根网线连接着两个设备一样。
bridge网络的特点
使用一个 linux bridge,默认为 docker0
使用veth 对,一头在容器的网络 namespace中,一头在docker0上
该模式下Docker Container不具有一个公有IP,因为宿主机的IP地址与veth pair的IP地址不在同一个网段内
Docker采用NAT方式,将容器内部的服务监听的端口与宿主机的某一个端口进行“绑定”,使得宿主机以外的世界可以主动将网络报文发送至容器内部
外界访问容器内的服务时,需要访问宿主机的 IP 以及宿主机的端口 port
NAT 模式由于是在三层网络上的实现手段,故肯定会影响网络的传输效率。
容器拥有独立、隔离的网络栈;让容器和宿主机以外的世界通过NAT建立通信
#当前运行有三个容器
[root@docker ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a39c73488430 zisefeizhu/httpd:v0.2 "/bin/httpd -f -h /d…" 27 hours ago Up 27 hours t2
7cf93b2d56be zhujingxing/httpd:latest "sh" 27 hours ago Up 27 hours t1
7b030688d7c6 busybox "sh" 27 hours ago Up 27 hours b1
#因为启动了三个容器,所以生成了三个虚拟IP,同时这三个虚拟IP都是插在docker0桥上的
[root@docker ~]# ifconfig
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
......
veth0a020f8: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
......
veth74be495: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
......
veth99cb539: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
[root@docker ~]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242dcbf397a no veth0a020f8
veth74be495
veth99cb539
#查看网卡之间的连接关系、红色为容器内部网卡
[root@docker ~]# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:0c:29:da:d7:53 brd ff:ff:ff:ff:ff:ff
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:dc:bf:39:7a brd ff:ff:ff:ff:ff:ff
5: veth99cb539@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether 42:07:17:86:75:3b brd ff:ff:ff:ff:ff:ff link-netnsid 0
7: veth0a020f8@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether 3a:de:33:6e:cc:ff brd ff:ff:ff:ff:ff:ff link-netnsid 1
9: veth74be495@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether 3e:02:4d:e7:34:e5 brd ff:ff:ff:ff:ff:ff link-netnsid 2
#进入容器t2
[root@docker ~]# docker exec -it t2 sh
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:04
inet addr:172.17.0.4 Bcast:172.17.255.255 Mask:255.255.0.0
#Nat桥:docker创建时默认就是nat桥,是使用Iptables来实现的
[root@docker ~]# iptables -t nat -vnL
Chain PREROUTING (policy ACCEPT 231 packets, 28675 bytes)
pkts bytes target prot opt in out source destination
5 260 DOCKER all -- * * 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL
Chain INPUT (policy ACCEPT 231 packets, 28675 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 611 packets, 45623 bytes)
pkts bytes target prot opt in out source destination
0 0 DOCKER all -- * * 0.0.0.0/0 !127.0.0.0/8 ADDRTYPE match dst-type LOCAL
Chain POSTROUTING (policy ACCEPT 611 packets, 45623 bytes)
pkts bytes target prot opt in out source destination
0 0 MASQUERADE all -- * !docker0 172.17.0.0/16 0.0.0.0/0
in: 从使用接口进来,只要不出docker0出去,源地址来自于172.17.0.0/16的,无论到达任何主机0.0.0.0/0,都要做地址伪装MASQUERADE,相当于SNAT,而且是自动实现SNAT,也就是自动选择一个最合适物理地址当作源地址,所以docker0桥默认就是nat桥
Chain DOCKER (2 references)
pkts bytes target prot opt in out source destination
0 0 RETURN all -- docker0 * 0.0.0.0/0 0.0.0.0/0
#创建bridge容器
[root@docker ~]# docker run --name t3 -it --rm busybox:latest
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:05
inet addr:172.17.0.5 Bcast:172.17.255.255 Mask:255.255.0.0
......
/ # exit
[root@docker ~]# docker run --name t3 -it --network bridge --rm busybox:latest
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:05
inet addr:172.17.0.5 Bcast:172.17.255.255 Mask:255.255.0.0
......
容器中网络通讯情况
同一个宿主机中,使用同一个docker0中的软交换机进行通讯。
/ # netstat -lnt
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 :::80 :::* LISTEN
#容器内访问
/ # wget -O - -q http://172.17.0.4
<h1> Busybox httpd server. </h1>
#宿主机访问
[root@docker ~]# curl http://172.17.0.4
<h1> Busybox httpd server. </h1>
跨主机通讯
在同一个宿方机之间的容器通讯可以实现,但是跨主机就会产生问题,因为docker本身就是一个nat bridge,对外来说是不可见的,要实现不同主机之间的容器的实现通讯,就要做dnat,把接口中发布出来的,假设物理主机上有一个物理网卡,开通一个端口然后提供对外服务,外部主机访问容器中的服务时,使用dnat的方式转到容器中的虚拟网卡中,提供服务。
但是存在一个问,如果在同一台宿主机上,起了两个容器分别是两个nginx的web服务,但是对外的IP只有一个,只能使用端口来区分,假设nginx1使用80,另一个nginx2就只能使用非80的端口,这时client访问的出现问题,因为默认访问就要给80,如果是非80端口就请求不到。
如查使用ovetlay network叠加网络方式就可以直接使用隧道来承载,直接访问就可以了,可以不用对地址进行映射。一般的跨主机之间的虚拟机访问方式桥接、nat的。
容器特殊功能,在容器内部有6个隔离的名称空间,user,mount,pid,uts,net,ipc,每个容器都有自身独立的资源,假设让每个容器都有隔离而独立的user,mount,pid,而uts,net,ipc这三个资源是共享使用的,拥有同一个网卡,同一组网络协议栈,有同一个主机名和域名,对外使用同一个IP地址,优点是如第一个容器使用的tomcat服务,第二个容器的是redis服务时,如果tomcat要访问redis中的数据时,是同一个协议栈,之前如果是隔离的,通过127来访问是不可以的,实现有自己独立隔离的名称空间,却又共享一部分名称空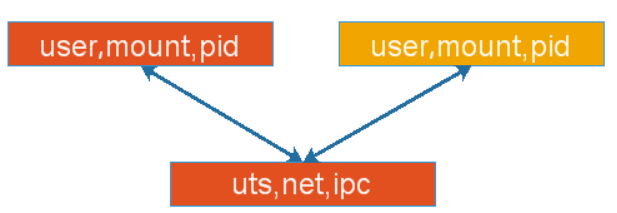
host 模式
Host模式并没有为容器创建一个隔离的网络环境。该模式下的Docker容器会和host宿主机共享同一个网络namespace,所以容器可以和宿 主机一样,使用宿主机的eth0,实现和外界的通信。
host 网络特点
这种模式下的容器没有隔离的network namespace
容器的IP地址同 Docker主机的IP地址
需要注意容器中服务的端口号不能与Docker主机上已经使用的端口号相冲突
host模式能够和其它模式共存
[root@docker ~]# docker run --name b2 --network host -it --rm busybox
/ # ifconfig
docker0 Link encap:Ethernet HWaddr 02:42:DC:BF:39:7A
inet addr:172.17.0.1 Bcast:172.17.255.255 Mask:255.255.0.0
......
/ # echo "live zhujingxing" > /tmp/index.html
/ # httpd -h /tmp/
/ # netstat -nat | grep 80
tcp 0 0 :::80 :::* LISTEN
[root@docker ~]# netstat -ant | grep 80
tcp6 0 0 :::80 :::* LISTEN

none 模式
网络模式为 none,即不为Docker容器构造任何网络环境,不会为容器创建网络接口,一旦Docker容器采用了none网络模式,那么容器内部就只能使用loop back网络设备,不会再有其他的网络资源。
[root@docker ~]# docker run -it --name host --network none --rm busybox
/ # ifconfig
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
......
container模式
joined 容器是另一种实现容器间通信的方式。它可以使两个或多个容器共享一个网络栈,共享网卡和配置信息,joined 容器之间可以通过 127.0.0.1 直接通信。
[root@docker ~]# docker run --name busy01 -it --rm busybox
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
8: eth0@if9: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:0a:00:00:03 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.3/16 brd 10.0.255.255 scope global eth0
valid_lft forever preferred_lft forever
/ # hostname
4a5449c67f3a
# 此时另开一窗口,在启动另外一个容器,可以看到ip和主机名啥的都是一样的
[root@docker ~]# docker run --name busy02 -it --network container:busy01 --rm busybox
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
8: eth0@if9: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:0a:00:00:03 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.3/16 brd 10.0.255.255 scope global eth0
valid_lft forever preferred_lft forever
/ # hostname
4a5449c67f3a
# 做个测试,证明两个容器时共用lo接口的,在busy01上面启动一个httpd
/ # echo 'I live zhujingxing' >/tmp/index.html
/ # httpd -f -h /tmp/
# 在busy02上访问本地接口lo,可以看到是成功的
/ # wget -O - -q 127.0.0.1
I live zhujingxing
# 但是文件系统还是隔离的,在busy01容器中创建一个目录
/ # mkdir /tmp/test
# 在busy02中查看,是没有的
/ # ls /tmp/
2.6.7 自定义docker的网络属性
#修改docker0桥的地址,添加bip设置
[root@docker ~]# docker ps
[root@docker ~]# ip a | grep docker0
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
[root@docker ~]# systemctl stop docker
[root@docker ~]# cp /etc/docker/daemon.json{,.bak}
[root@docker ~]# vim /etc/docker/daemon.json
[root@docker ~]# systemctl start docker
[root@docker ~]# diff /etc/docker/daemon.json{,.bak}
2,3c2
< "registry-mirrors": ["https://llpuz83z.mirror.aliyuncs.com"],
< "bip": "10.0.0.1/16"
---
> "registry-mirrors": ["https://llpuz83z.mirror.aliyuncs.com"]
[root@docker ~]# ip a | grep docker0
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
inet 10.0.0.1/16 brd 10.0.255.255 scope global docker0
#还可以修改其他选项
[root@node2 ~]# cat /etc/docker/daemon.json
{
"registry-mirrors": ["https://registry.docker-cn.com"],
"bip": "10.0.0.1/16", #核心选项为big,即bridge ip,用于指定docker0桥自身的IP地址,其他选项可以通过此计算出来,除了DNS
"fixed-cidr": "10.20.0.0/16",
"fixed-cidr-v6": "2001:db8::/64",
"default-gateway": "10.20.1.1",
"default-gateway-v6": "2001:db8:abcd::89",
"dns": ["10.20.1.2","10.20.1.3"]
}
#关于daemon.json 请看1.5.2.2章节
#设定外部主机连接docker
dockerd守护进程的C/S,其默认仅监听unix socket格式地址,/var/run/docker.sock;如果使用tcp套接字
# 现在我的docker01和docker02主机都是有安装docker的,我现在修改配置,使docker01能够控制docker02的容器
[root@docker2 ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2157df82161b hamerle/httpd:v1 "/bin/httpd -f -h /d…" 2 days ago Exited (135) 1 hours ago web01
[root@docker02 ~]# systemctl edit docker.service
[Service]
ExecStart=
ExecStart=/usr/bin/dockerd -H fd:// -H tcp://0.0.0.0:2375
[root@docker02 ~]# systemctl daemon-reload
[root@docker02 ~]# systemctl restart docker.service
[root@docker02 ~]# netstat -lntp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 765/sshd
tcp 0 0 127.0.0.1:2375 0.0.0.0:* LISTEN 5180/dockerd
tcp6 0 0 :::22 :::* LISTEN 765/sshd
# docke daemon已经监听到2375的端口,我们现在可以通过docker01远程启动docker02上的web007容器
[root@docker01 ~]# docker -H 20.0.0.210:2375 ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2157df82161b hamerle/httpd:v1 "/bin/httpd -f -h /d…" 2 days ago Exited (135) 1 hours ago web01
[root@docker01 ~]# docker -H 20.0.0.210:2375 start web01
web01
[root@docker2 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2157df82161b hamerle/httpd:v1 "/bin/httpd -f -h /d…" 2 days ago Exited (135) 1 hours ago web01
#手动创建一个网络类型,并指定对应网桥设备的名称为docker,最终实现基于两个不同网络启动的容器间互相通信。
[root@docker ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
bddc0093fe11 bridge bridge local
48cf42c3b371 host host local
4c1006be1ea1 none null local
[root@docker ~]# docker network create --help
[root@docker ~]# docker network create -o com.docker.network.bridge.name=docker -d bridge --subnet '172.18.0.0/16' bridge-test
38ce06f558bab2dd57959448953dc214411c3d6147185c2d78fd90b37ae34c62
# -o:在使用bridge的driver类型时,可以使用-o的附加参数。上面实例中的参数意思是指定创建bridge类型网络时对应虚拟网桥设备的名字。(就是ip a命令看到的名字)
# -d:指定driver,默认类型就是bridge。
# --subnet:指定新建的docker网络的网段
# 最后的bridg-test是即将要将创建出的网络的名字.
[root@docker ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
bddc0093fe11 bridge bridge local
38ce06f558ba bridge-test bridge local
48cf42c3b371 host host local
4c1006be1ea1 none null local
[root@docker ~]# ip a | grep docker
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
inet 10.0.0.1/16 brd 10.0.255.255 scope global docker0
19: docker: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
inet 172.18.0.1/16 brd 172.18.255.255 scope global docker
# 我们以bridge-test网络启动一个容器
[root@docker ~]# docker run --name busy01 -it --network bridge-test --rm busybox:latest
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
20: eth0@if21: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.2/16 brd 172.18.255.255 scope global eth0
valid_lft forever preferred_lft forever
/ #
# 另开一个窗口,使用bridge网络再起一个容器
[root@docker ~]# docker run --name busy02 -it --network bridge --rm busybox:latest
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
22: eth0@if23: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:0a:00:00:02 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.2/16 brd 10.0.255.255 scope global eth0
valid_lft forever preferred_lft forever
# 可以看到两个容器,一个是172.18网段,一个是10.0网段,此时做连通性测试。
/ # ping 172.18.0.2
# 不通,此时确定宿主机的ip_forward是否开启,如果开启还不通,则需要另开一个窗口排查防火墙规则。
[root@docker ~]# cat /proc/sys/net/ipv4/ip_forward
1
[root@docker ~]# iptables -nvL
# 排查防火墙规则,其实很简单,把target类型为DROP的删掉就好了。我这里只列出有DROP的链,并删除
[root@docker ~]# iptables -nvL DOCKER-ISOLATION-STAGE-2 --line-number
Chain DOCKER-ISOLATION-STAGE-2 (2 references)
num pkts bytes target prot opt in out source destination
1 0 0 DROP all -- * docker 0.0.0.0/0 0.0.0.0/0
2 0 0 DROP all -- * docker0 0.0.0.0/0 0.0.0.0/0
3 7 588 RETURN all -- * * 0.0.0.0/0 0.0.0.0/0
[root@docker ~]# iptables -D DOCKER-ISOLATION-STAGE-2 2
[root@docker ~]# iptables -D DOCKER-ISOLATION-STAGE-2 1
# 删除完后再ping
/ # ping 172.18.0.2
PING 172.18.0.2 (172.18.0.2): 56 data bytes
64 bytes from 172.18.0.2: seq=0 ttl=63 time=0.115 ms
64 bytes from 172.18.0.2: seq=1 ttl=63 time=0.081 ms
64 bytes from 172.18.0.2: seq=2 ttl=63 time=0.169 ms
2.7 docker存储卷
2.7.1 为什么需要数据卷
这得从 docker 容器的文件系统说起。出于效率等一系列原因,docker 容器的文件系统在宿主机上存在的方式很复杂,这会带来下面几个问题:
不能在宿主机上很方便地访问容器中的文件。
无法在多个容器之间共享数据。
当容器删除时,容器中产生的数据将丢失。
为了解决这些问题,docker 引入了数据卷(volume) 机制。数据卷是存在于一个或多个容器中的特定文件或文件夹,这个文件或文件夹以独立于 docker 文件系统的形式存在于宿主机中。数据卷的最大特定是:其生存周期独立于容器的生存周期。
2.7.2 使用数据卷的最佳场景
在多个容器之间共享数据,多个容器可以同时以只读或者读写的方式挂载同一个数据卷,从而共享数据卷中的数据。
当宿主机不能保证一定存在某个目录或一些固定路径的文件时,使用数据卷可以规避这种限制带来的问题。
当你想把容器中的数据存储在宿主机之外的地方时,比如远程主机上或云存储上。
当你需要把容器数据在不同的宿主机之间备份、恢复或迁移时,数据卷是很好的选择。
2.7.3 细述存储卷
背景:一个程序,对于容器来说,启动时依赖于可能不止一层的镜像,联合挂载启动而成,使用overlay2文件系统,引导最上层的可写层,对于读写层来说,所有在容器中可执行的操作,包括对数据和内容的修改,都是保存在最上层之上的,对于下层内容的操作,假设要删除一个文件,需要使用写时复制。
docker镜像由多个只读层叠加面成,启动容器时,docker会加载只读镜像层并在镜像栈顶部加一个读写层
如果运行中的容器修改了现有的一个已经存在的文件,那该文件将会从读写层下面的只读层复制到读写层,该文件版本仍然存在,只是已经被读写层中该文件的副本所隐藏,此即“写时复制(COW)”机制
描述:如果一个文件在最底层是可见的,如果在layer1上标记为删除,最高的层是用户看到的Layer2的层,在layer0上的文件,在layer2上可以删除,但是只是标记删除,用户是不可见的,总之在到达最顶层之前,把它标记来删除,对于最上层的用户是不可见的,当标记一删除,只有用户在最上层建一个同名一样的文件,才是可见的。
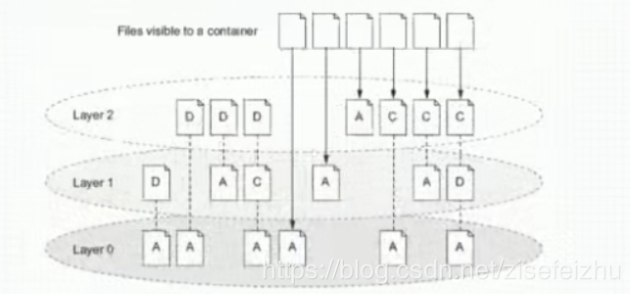
对于这类的操作,修改删除等,一般效率非常低,如果对一于I/O要求比较高的应用,如redis在实现持久化存储时,是在底层存储时的性能要求比较高。
假设底层运行一个存储库mysql,mysql本来对于I/O的要求就比较高,如果mysql又是运行在容器中自己的文件系统之上时,也就是容器在停止时,就意味着删除,其实现数据存取时效率比较低,要避免这个限制要使用存储卷来实现。
存储卷:可以想象来在各全局的名称空间中,也就是理解为在宿主机中找一个本地的文件系统,可能存在某一个目录中,直接与容器上的文件系统中的某一目录建立绑定关系。
类似于挂载一样,宿主机的/data/web目录与容器中的/container/data/web目录绑定关系,然后容器中的进程向这个目录中写数据时,是直接写在宿主机的目录上的,绕过容器文件系统与宿主机的文件系统建立关联关系,使得可以在宿主机和容器内共享数据库内容,让容器直接访问宿主机中的内容,也可以宿主机向容器供集内容,两者是同步的。
mount名称空间本来是隔离的,可以让两个本来是隔离的文件系统,在某个子路径上建立一定程度的绑定关系,从而使得在两个容器之间的文件系统的某个子路径上不再是隔离的,实现一定程度上共享的效果。
在宿主机上能够被共享的目录(可以是文件)就被称为volume。
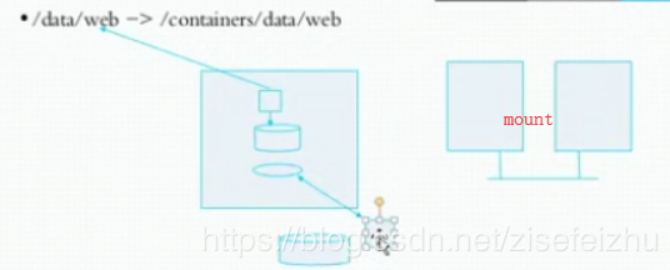
优点:容器中进程所生成的数据,都保存在存储卷上,从而脱离容器文件系统自身后,当容器被关闭甚至被删除时,都不用担心数据被丢失,实现数据可以脱离容器生命周期而持久,当再次重建容器时,如果可以让它使用到或者关联到同一个存储卷上时,再创建容器,虽然不是之前的容器,但是数据还是那个数据,特别类似于进程的运行逻辑,进程本身不保存任何的数据,数据都在进程之外的文件系统上,或者是专业的存储服务之上,所以进程每次停止,只是保存程序文件,对于容器也是一样,
容器就是一个有生命周期的动态对象来使用,容器关闭就是容器删除的时候,但是它底层的镜像文件还是存在的,可以基于镜像再重新启动容器。
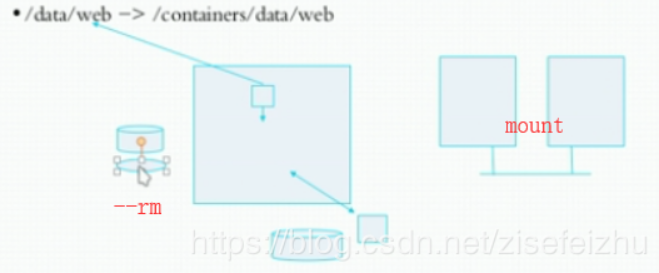
但是容器有一个问题,一般与进程的启动不太一样,就是容器启动时选项比较多,如果下次再启动时,很多时候会忘记它启动时的选项,所以最好有一个文件来保存容器的启动,这就是容器编排工具的作用。一般情况下,是使用命令来启动操作docker,但是可以通过文件来读,也就读文件来启动,读所需要的存储卷等,但是它也只是操作一个容器,这也是需要专业的容器编排工具的原因。
另一个优势就是容器就可以不置于启动在那台主机之上了,如几台主机后面挂载一个NFS,在各自主机上创建容器,而容器上通过关联到宿主机的某个目录上,而这个目录也是NFS所挂载的目录中,这样容器如果停止或者是删除都可以不限制于只能在原先的宿主机上启动才可以,可以实现全集群范围内调试容器的使用,当再分配存储、计算资源时,就不会再局限于单机之上,可以在集群范围内建立起来,基本各种docker的编排工具都能实现此功能,但是后面严重依赖于共享存储的使用。
考虑到容器应用是需要持久存储数据的,可能是有状态的,如果考虑使用NFS做反向代理是没必要存储数据的,应用可以分为有状态和无状态,有状态是当前这次连接请求处理一定此前的处理是有关联的,无状态是前后处理是没有关联关系的,大多数有状态应用都是数据持久存储的,如mysql,redis有状态应用,在持久存储,如nginx作为反向代理是无状态应用,tomcat可以是有状态的,但是它有可能不需要持久存储数据,因为它的session都是保存在内存中就可以的,会导致节点宕机而丢失session,如果有必要应该让它持久,这也算是有状态的。

应用状态:是否有状态或无状态,是否需要持久存储,可以定立一个正轴坐标系,第一象限中是那些有状态需要存储的,像mysql,redis等服务,有些有有状态但是无需进行存储的,像tomcat把会话保存在内存中时,无状态也无需要存储的数据,如各种反向代理服务器nginx,lvs请求连接都是当作一个独立的连接来调度,本地也不需要保存数据,第四象限是无状态,但是需要存储数据是比较少见。
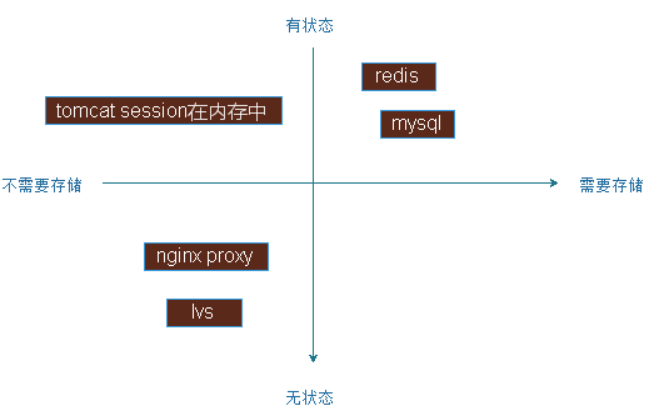
运维起来比较难的是有状态且需要持久的,需要大量的运维经验和大量的操作步骤才能操作起来的,如做一个Mysql主从需要运维知识、经验整合进去才能实现所谓的部署,扩展或缩容,出现问题后修复,必须要了解集群的规模有多大,有多少个主节点,有多少个从节点,主节点上有多少个库,这些都要一清二楚,才能修复故障,这些就强依赖于运维经验,无状态的如nginx一安装就可以了,并不复杂,对于无状态的应用可以迅速的实现复制,在运维上实现自动化是很容易的,对于有状态的现状比较难脱离运维人员来管理,即使是k8s在使用上也暂时没有成熟的工具来实现。
总之:对于有状态的应用的数据,不使用存储卷,只能放在容器本地,效率比较低,而导致一个很严重问题就是无法迁移使用,而且随着容器生命周期的停止,还不能把它删除,只能等待下次再启动状态才可以,如果删除了数据就可能没了,因为它的可写层是随着容器的生命周期而存在的,所以只要持久存储数据,存储卷就是必需的。
docker存储卷难度:对于docker存储卷运行起来并不太麻烦,如果不自己借助额外的体系来维护,它本身并没有这么强大,因为docker存储卷是使用其所在的宿主机上的本地文件系统目录,也就是宿主机有一块磁盘,这块磁盘并没有共享给其他的docker主要,然后容器所使用的目录,只是关联到宿主机磁盘上的某个目录而已,也就是容器在这宿主机上停止或删除,是可以重新再创建的,但是不能调度到其他的主机上,这也是docker本身没有解决的问题,所以docker存储卷默认就是docker所在主机的本地,但是自己搭建一个共享的NFS来存储docker存储的数据,也可以实现,但是这个过程强依赖于运维人员的能力。
2.7.3.1 使用存储卷的原因
关闭并重启容器,其数据不受影响,但是删除docker容器,则其更改将会全部丢失
存在的问题
存储于联合文件系统中,不易于宿主机访问
容器间数据共享不便
删除容器其数据会丢失
解决方案:卷
卷是容器上一个或多个"目录“,此类目录可绕过联合文件系统,与宿主机上的某目录绑定(关联)

2.7.3.2 存储卷原理
volume于容器初始化之时会创建,由base image提供的卷中的数据会于此期间完成复制
volume的初意是独立于容器的生命周期实现数据持久化,因此删除容器之时既不会删除卷,也不会对哪怕未被引用的卷做垃圾回收操作
卷为docker提供了独立于容器的数据管理机制
可以把“镜像”想像成静态文件,例如“程序”,把卷类比为动态内容,例如“数据”,于是,镜像可以重用,而卷可以共享
卷实现了“程序(镜像)"和”数据(卷)“分离,以及”程序(镜像)“和"制作镜像的主机”分离,用记制作镜像时无须考虑镜像运行在容器所在的主机的环境
描述:有了存储卷,如果写在/上,还是存在联合挂载文件系统中,如果要写到卷上,就会写到宿主机关联的目录上,程序运行过程生成的临时数据会写到tmp目录中,也就会在容器的可写层中存储,随着容器被删除而删除,并没太大的影响,只有关键型的数据才会保存在存储卷上。

Volume types

Docker有两种类型的卷,每种类型都在容器中存在一个挂载点,但其在宿主机上位置有所不同:
绑定挂载卷:在宿主机上的路径要人工的指定一个特定的路径,在容器中也需要指定一个特定的路径,两个已知的路径建立关联关系
docker管理卷: 只需要在容器内指定容器的挂载点是什么,而被绑定宿主机下的那个目录,是由容器引擎daemon自行创建一个空的目录,或者使用一个已经存在的目录,与存储卷建立存储关系,这种方式极大解脱用户在使用卷时的耦合关系,缺陷是用户无法指定那些使用目录,临时存储比较适合
2.7.3.3 docker volume 子命令
docker 专门提供了 volume 子命令来操作数据卷:
create 创建数据卷
inspect 显示数据卷的详细信息
ls 列出所有的数据卷
prune 删除所有未使用的 volumes,并且有 -f 选项
rm 删除一个或多个未使用的 volumes,并且有 -f 选项
2.7.3.4 使用mount 语法挂载数据卷
使用 --volume(-v) 选项来挂载数据卷,现在 docker 提供了更强大的 --mount 选项来管理数据卷。mount 选项可以通过逗号分隔的多个键值对一次提供多个配置项,因此 mount 选项可以提供比 volume 选项更详细的配置。使用 mount 选项的常用配置如下:
type 指定挂载方式,我们这里用到的是 volume,其实还可以有 bind 和 tmpfs。
volume-driver 指定挂载数据卷的驱动程序,默认值是 local。
source 指定挂载的源,对于一个命名的数据卷,这里应该指定这个数据卷的名称。在使用时可以写 source,也可以简写为 src。
destination 指定挂载的数据在容器中的路径。在使用时可以写 destination,也可以简写为 dst 或 target。
readonly 指定挂载的数据为只读。
volume-opt 可以指定多次,用来提高更多的 mount 相关的配置。
2.7.3.5 数据的覆盖问题
如果挂载一个空的数据卷到容器中的一个非空目录中,那么这个目录下的文件会被复制到数据卷中。
如果挂载一个非空的数据卷到容器中的一个目录中,那么容器中的目录中会显示数据卷中的数据。如果原来容器中的目录中有数据,那么这些原始数据会被隐藏掉。
这两个规则都非常重要:
灵活利用第一个规则可以帮助我们初始化数据卷中的内容。
掌握第二个规则可以保证挂载数据卷后的数据总是你期望的结果
2.7.3.5 在容器中使用volumes
为docker run 命令使用-v 选项可使用volume
docker-managed volume
docker run -it -name bbox1 -v /data busybox #/data指定docker的目录
docker inspect -f {{.Mounts}} bbox1 #查看rbox1容器的卷,卷标识符及挂载的主机目录
Bind-mount volume
docker run -it -v HOSTDIR:VOLUMEDIR --name bbox2 busybox #宿主机目录:容器目录
docker inspect -f {{.Mounts}} bbox2
2.7.4 实操:docker管理卷
[root@docker ~]# docker run --help
-v, --volume list Bind mount a volume
--volume-driver string Optional volume driver for the container
--volumes-from list Mount volumes from the specified container(s)
[root@docker ~]# docker run --name volume01 -it -v /data busybox
/ # ls /
bin data dev etc home proc root sys tmp usr var ---> data目录默认是不存在的
[root@docker ~]# docker inspect volume01
"Mounts": [
{
"Type": "volume",
"Name": "632514d35d152b677553d166601fe44091720ac9788dc30e2912cb7c63ba76b4",
"Source": "/var/lib/docker/volumes/632514d35d152b677553d166601fe44091720ac9788dc30e2912cb7c63ba76b4/_data",
"Destination": "/data", ---> 容器中的data目录挂载在宿主机上的Source所指目录
"Driver": "local",
"Mode": "",
"RW": true,
"Propagation": ""
}
],
#宿主机: 可以很方便实现在宿主机和容器之间共享目录
[root@docker ~]# cd /var/lib/docker/volumes/632514d35d152b677553d166601fe44091720ac9788dc30e2912cb7c63ba76b4/_data
[root@docker _data]# ls
[root@docker _data]# echo "hello zhujingxing" > test.html
#在容器中查看
/ # ls /data/
test.html
/ # cat /data/test.html
hello zhujingxing
/ # echo "hello zisefeizhu" >> /data/test.html
[root@docker _data]# cat test.html
hello zhujingxing
hello zisefeizhu
#docker绑定卷
[root@docker ~]# docker run --name volume02 -it --rm -v /data/volumes/volume02:/data busybox
/ #
[root@docker _data]# docker inspect volume02
"Mounts": [
{
"Type": "bind",
"Source": "/data/volumes/volume02",
"Destination": "/data",
"Mode": "",
"RW": true,
"Propagation": "rprivate"
}
],
[root@docker _data]# cd /data/volumes/volume02/ ---> 目录会自动创建
[root@docker volume02]# echo "<h1> hello zhujingxing </h1>" > index.html
/ # cat /data/index.html
<h1> hello zhujingxing </h1>
#持久化的实现
/ # exit
[root@docker ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[root@docker ~]# docker run --name volume02 -it --rm -v /data/volumes/volume02:/data/web/htm busybox
/ # cat /data/web/htm/index.html
<h1> hello zhujingxing </h1>
#使用golong模板查看
[root@docker volume02]# docker inspect -f {{.Mounts}} volume02
[{bind /data/volumes/volume02 /data/web/htm true rprivate}]
[root@docker volume02]# docker inspect -f {{.NetworkSettings}} volume02
{{ 03562d1741cd19808e9a904d991a6c0f1db1ba9d5098e20779edbd4529798d0d false 0 map[] /var/run/docker/netns/03562d1741cd [] []} {fd45e4499b9bbebbfe6d383593a20ccaadbcac2d130bb097037ed19444abb009 10.0.0.1 0 10.0.0.3 16 02:42:0a:00:00:03} map[bridge:0xc0005a8000]}
##引入某个键(键中键)
[root@docker volume02]# docker inspect -f {{.NetworkSettings.IPAddress}} volume02
10.0.0.3
场景:一个docker容器可以关联到宿主机的目录中,也可以让两个docker容器同时关联到同一个宿主机的目录中,实现共享使用同一个存储卷,容器之间的数据共享
[root@docker ~]# docker run --name volume02 -it --rm -v /data/volumes/volume02:/data/web/htm busybox
/ # cat /data/web/htm/index.html
<h1> hello zhujingxing </h1>
[root@docker volume02]# docker run --name volume03 -it --rm -v /data/volumes/volume02:/data busybox
/ # cat /data/index.html
<h1> hello zhujingxing </h1>
[root@docker ~]# cat /data/volumes/volume02/index.html
<h1> hello zhujingxing </h1>
场景:需要多个容器同进使用多个卷,卷在那里写每次初始化时都要使用-v来指定,如果不想记录这个路径,docker还支持复制其他的存储卷路径
实现:制定一个容器,不执行任何任务,创建时,只要指定它的存储路径,作为其他相关联容器的基础架构容器,其他的容器启动时去复制它的存储卷设置,但是这样的点浪费,不过使用joined container的基础的话,几个容器本来就有密切的关系,如nginx+tomcat,nginx的容器和tomcat容器共享一个底层的网络,有一个对外的接口,有一个loop接口,这样80给nginx,在内loop给tomcat,请求进来,nginx作为反射代理转给tomcat就可以了,再加一个mysql,也是使用loop接口来通讯。
让它们共享网络名称空间中的uts,net,ipc,还可以共享存储卷,ngInx处理静态,tomcat处理动态的,在同一个目录下,使用存储卷来解决这个问题,这种组织方式使用构建应用。
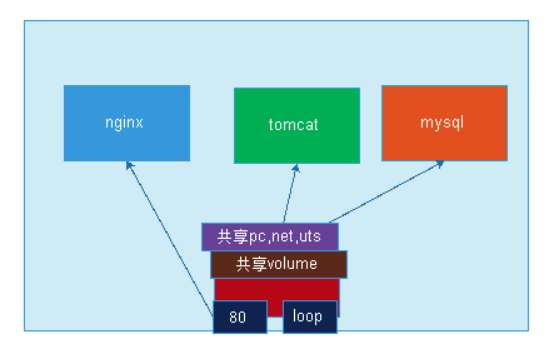
#多个容器的卷使用同一个主机目录,如
docker run -it --name c1 -v /docker/volumes/v1:/data/ busybox
#复制使用其他容器的卷,为docker run 命令使用--volumes-from选项
docker run -it --name bbox1 -v /docker/volumes/v1:/data busybox
docker run -it --name bbox2 --volumes-from bbox1 busybox
#制定基础镜像(网上有专门制作基础架构容器的,不用启动,只要创建就可以了)
[root@docker ~]# docker run --name basiccon -it -v /data/basic/volume/:/data/web/html busybox
/ # ls /data/
web
[root@docker ~]# docker run --name nginx --network container:basiccon --volumes-from basiccon -it busybox #加入网络,同时复制卷
/ # ls /data/
web
2.8 dockerfile详解
各位想必应该记得,此前如果安装一个nginx的话,安装完以后,通常不会运行在默认配置下,那因此,我们通常需要去改一改它的配置文件或者定义模块化配置文件,然后启动服务。那为什么,nginx的默认配置不符合我们的需要呢?很显然,不同的生产场景所需要用到的配置参数各不相同,因此,对方只能用一个默认的,认为适用于大多数普遍场景情形的或者适用于较小主机资源情况下的那么一个设定来启动服务,同样的逻辑,各位试想一下,如果我们从docker hub下拖下来一个nginx的镜像,去启动nginx容器的时候,请问这个镜像内的nginx容器内的配置文件一定就会符合我们的需要吗?应该说叫一定不会,基本上几乎不能完全适合我们的需要,此时我们就必须去要修改配置,那怎么改呢?
之前做法:启动容器docker exec连进容器,在内部执行vi,再reload重启
另外一种方式:假设我们把它对应的那个配置文件的路径做存储卷,从我们宿主机上加载文件,在宿主机上进行编辑,也能让它立即生效,启动容器之前先把它编辑好(容器启动之前,我们事先找一目录把配置文件准备好,然后启动容器时,把容器内的应用程序默认加载配置文件的路径与宿主机上的目录进行建立关联关系,然后去启动容器,也能加载到在宿主机上定制的配置文件)
缺点:我们在宿主上做的编辑,能不能让它立即生效呢?比如我们启动以后发现,有些参数还是需要改,改完以后依然需要重载才能生效。
还有一种方式:自制镜像
基于容器:先启动起来,交互式连入进来,做修改,改完以后,改的结果一定时保存在最上层的可写层的。这个时候我们把可写层保存在一个新镜像中,而后,我们再去创建容器时,根据我们自己所创建的镜像来使用。
缺点:做的镜像也是直接把文件直接备进镜像中的,直接写死在镜像中的就是,如果我们想在改,还是改不了,运行过程当中去修改配置的需求可能对于做运维来讲,变更不就是日常操作吗?很多时候,也有可能需要随时进行修改。那依然解决不了问题。而且这种备进镜像的设计方式,最悲惨的地方在于:一次更新,维护复杂 。环境简单可以使用。
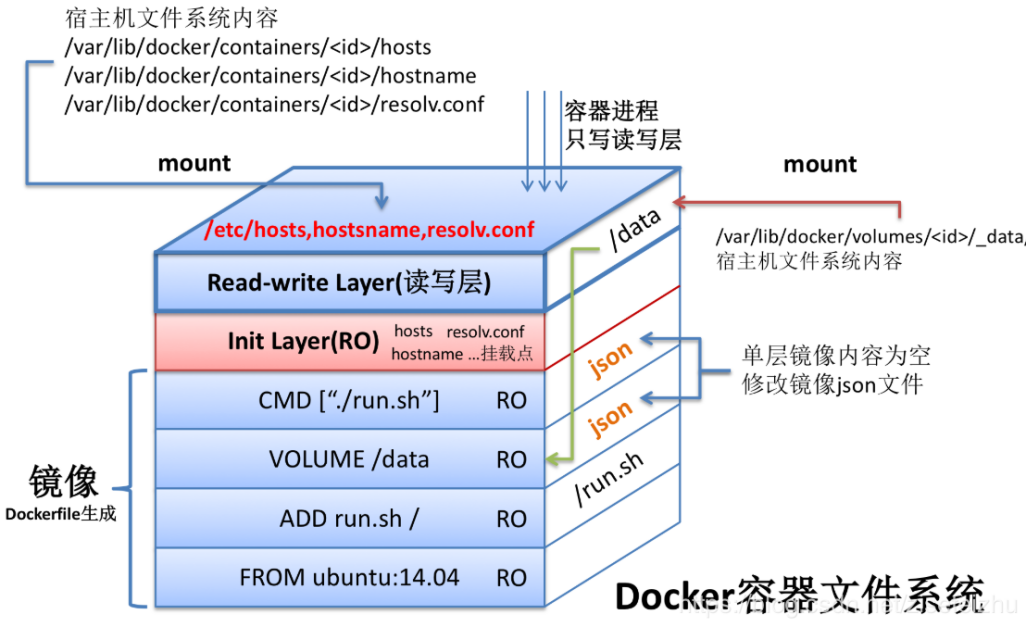
基于dockerfile:dockerfile,相当于是一个文档,客户可以基于dockerfile生成新的容器。dockerfile仅仅是用来制作镜像的源码文件,是构建容器过程中的指令,docker能够读取dockerfile的指定进行自动构建容器,基于dockerfile制作镜像,每一个指令都会创建一个镜像层,即镜像都是多层叠加而成,因此,层越多,效率越低,创建镜像,层越少越好。因此能在一个指令完成的动作尽量通过一个指令定义。
2.8.1 docker镜像制作的工作逻辑
首先需要有一个制作镜像的目录,该目录下有个文件,名称必须为Dockerfile,Dockerfile有指定的格式,#号开头为注释,,指定默认用大写字母来表示,以区分指令和参数,docker build读取Dockerfile是按顺序依次Dockerfile里的配置,且第一条非注释指令必须是FROM 开头,表示基于哪个基础镜像来构建新镜像。可以根据已存在的任意镜像来制作新镜像。
Dockerfile可以使用环境变量,用ENV来定义环境变量,变量名支持bash的变量替换,如${variable:-word},表示如果变量值存在,就使用原来的变量,变量为空时,就使用word的值作为变量的值,一般使用这个表示法。${variable:+word},表示如果变量存在了,不是空值,那么变量将会被赋予为word对应的值,如果变量为空,那么依旧是空值。
[root@docker ~]# echo ${NAME:-zhujingxing}
zhujingxing
[root@docker ~]# NAME=zisefeizhu
[root@docker ~]# echo ${NAME:-zhujingxing}
zisefeizhu
[root@docker ~]# echo ${NAME:+zhujingxing}
zhujingxing
[root@docker ~]# unset NAME
[root@docker ~]# echo ${NAME:+zhujingxing}
[root@docker ~]#
dockerignore file:在docker发送上下文给 docker daemon 之前,会寻找.dockerignore file文件,去排除一些不需要的文件,或者很大的文件,不把这些文件发送给docker daemon,提升效率。而如果之后需要用到,则可以使用 ADD 或者 COPY 把他们放进image中。
2.8.2 dockerfile 格式
Dockerfile整体就两类语句组成:
# Comment 注释信息
Instruction arguments 指令 参数,一行一个指令。
Dockerfile文件名首字母必须大写。
Dockerfile指令不区分大小写,但是为方便和参数做区分,通常指令使用大写字母。
Dockerfile中指令按顺序从上至下依次执行。
Dockerfile中第一个非注释行必须是FROM指令,用来指定制作当前镜像依据的是哪个基础镜像。
Dockerfile中需要调用的文件必须跟Dockerfile文件在同一目录下,或者在其子目录下,父目录或者其它路径无效
2.8.3 dockerfile --> image --> registry
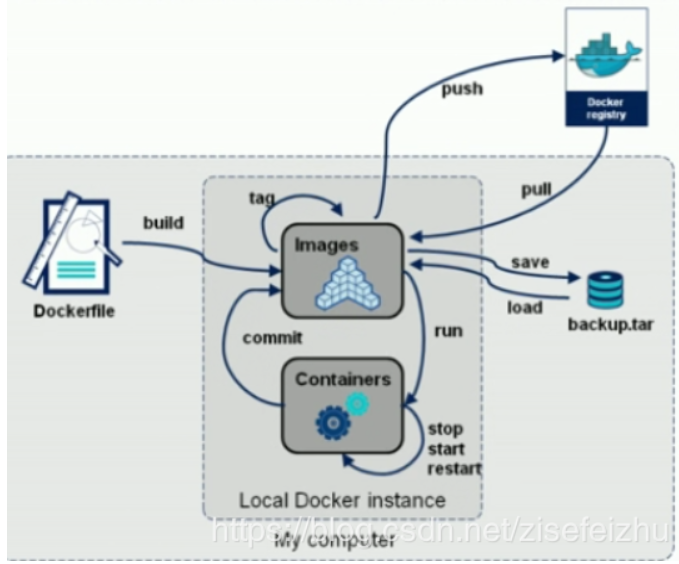
2.8.4 dockerfile 指令语法
1.FROM 介绍 FROM指令是最重要的一个且必须为 Dockerfile文件开篇的第一个非注释行,用于为镜像文件构建过程指定基准镜像,后续的指令运行于此基准镜像所提供的运行环境 . 实践中,基准镜像可以是任何可用镜像文件,默认情况下, docker build会在 docker主机上查找指定的镜像文件,在其不存在时,则会从 Docker Hub Registry上拉取所需的镜像文件 .如果找不到指定的镜像文件, docker build会返回一个错误信息 语法 FROM <repository>[:<tag>] 或者 FROM <repository>@<digest> <repository>:指定作为base image的名称 <tag>:base image的标签,为可选项,省略时默认为 latest; <digest>为校验码 例子 FROM busybox:latest
2.LABEL 介绍 LABEL用于为镜像添加元数据,元数以键值对的形式指定,使用LABEL指定元数据时,一条LABEL指定可以指定一条或多条元数据,指定多条元数据时不同元数据之间通过空格分隔。推荐将所有的元数据通过一条LABEL指令指定,以免生成过多的中间镜像。 语法 LABEL <key>=<value> <key>=<value> <key>=<value> ... 例子 LABEL version="1.0" description="这是一个Web服务器" by="IT笔录" 指定后可以通过docker inspect查看: docker inspect itbilu/test "Labels": { "version": "1.0", "description": "这是一个Web服务器", "by": "IT笔录" },
3.COPY 介绍 用于从 Docker宿主机复制文件至创建的镜像文件。 语法 COPY <src>... <dest> 或者 COPY ["<src>",... "<dest>"] <src>:要复制的源文件或者目录,支持通配符 <dest>:目标路径,即正创建的镜像的文件系统路径,建议使用绝对路径,绝对路径为镜像中的路径,而不是宿主机的路径。否则,COPY指令会以WORKDIR为其起始路径。 如果路径中如果包含空白字符,建议使用第二种格式用引号引起来,否则会被当成两个文件。 规则 <src>必须是build上下文中的目录,即只能放在workshop这个工作目录下,不能是其父目录中的文件。 如果<src>是目录,则其内部的文件或则子目录会被递归复制,但<src>目录本身不会被复制。 如果指定了多个<src>,或者<src>中使用通配符,则<dest>必须是一个目录,且必须以 / 结尾。 如果<dest>事先不存在,它将会被自动创建,包括其父目录路径。 例子 copy文件 COPY index.html /data/web/html/ copy目录 COPY yum.repos.d /etc/yum.repos.d/
4.ADD 介绍 ADD指令跟COPY类似,不过它还支持使用tar文件和URL路径。主机可以联网的情况下,docker build可以将网络上的某文件引用下载并打包到新的镜像中。 语法 ADD <src> ... <dest>或 ADD ["<src>",... "<dest>"] 规则 同COPY指令的4点准则 如果<src>为URL且<dest>不以/结尾,则<src>指定的文件将被下载并直接被创建为<dest>;如果<dest>以/结尾,则文件名URL指定的文件将被直接下载,并保存为<dest>/<filename>,注意,URL不能是ftp格式的url。 如果<src>是一个本地系统上的压缩格式的tar文件,它将被展开为一个目录,其行为类似于“tar -x”命令,然后,通过URL获取到的tar文件将不会自动展开。 如果<src>有多个,或其间接或直接使用了通配符,则<dest>必须是一个以/结尾的目录路径;如果<dest>不以/结尾,则其被视作一个普通文件,<src>的内容将被直接写入到<dest>; 例子 ADD http://nginx.org/download/nginx-1.15.5.tar.gz /usr/local/src/
5.WORKDIR 介绍 workdir为工作目录,指当前容器环境的工作目录,用于为Dockerfile中所有的RUN、CMD、ENTRYPOINT、COPY和ADD指定设定工作目录。在Dockerfile文件中,WORKDIR指令可出现多次,其路径也可以为相对路径,不过,其是相对此前一个WORKDIR指令指定的路径。另外,WORKDIR也可调用由ENV指定定义的变量。 语法 WORKDIR <dirpath> 例子 WORKDIR /var/log WORKDIR $STATEPATH
6.VOLUME 介绍 定义卷,只能是docker管理的卷VOLUME为容器上的目录(也就是说只能指定容器内的路径,不能指定宿主机的路径),用于在image中创建一个挂载点目录,以挂载Docker host上的卷或其它容器上的卷。如果挂载点目录路径下此前在文件存在,docker run命令会在卷挂载完成后将此前的所有文件复制到新挂载的卷中。 语法 VOLUME <mountpoint> 或者 VOLUME ["<mountpoint>"] 例子 VOLUME /data/mysql/
7.EXPOSE 介绍 暴露指定端口,用于为容器打开指定要监听的端口以实现与外部通信。EXPOSE指令可一次指定多个端口,但是不能指定暴露为宿主机的指定端口,因为指定的宿主机端口可能已经被占用,因此这里使用随机端口。比如容器提供的是一个https服务且需要对外提供访问,那就需要指定待暴露443端口,然后在使用此镜像启动容器时搭配 -P 的参数才能将待暴露的状态转换为真正暴露的状态,转换的同时443也会转换成一个随机端口,跟 -p :443一个意思 语法 EXPOSE <port>[/<protocol>] [<port>[/<protocol>] ...] 例子 EXPOSE 11211/udp 11211/tcp
8.ENV 介绍 ENV用于为镜像定义所需的环境变量,并可被Dockerfile文件中位于其后的其它指令(如WORKDIR、ADD、COPY等)所调用,即先定义后调用,调用格式为$variable_name或${variable_name} 使用docker run启动容器的时候加上 -e 的参数为variable_name赋值,可以覆盖Dockerfile中ENV指令指定的此variable_name的值。但是不会影响到dockerfile中已经引用过此变量的文件名。 语法 ENV <key> <value> ENV <key>=<value> ... 第一种格式一次只能定义一个变量,<key>之后所有内容都会被视为<value>的组成部分 第二种格式一次可以定义多个变量,每个变量为一个"="的键值对,如果<value>中包含空格,可以用反斜线 进行转义,也可以为<value>加引号,另外参数过长时可用反斜线做续行。 定义多个变量时,建议使用第二种方式,因为Dockerfile中每一行都是一个镜像层,构建起来比较吃资源。 例子 # 基于busybox启动一个镜像,将test文件拷贝至容器内的/usr/local/zisefeizhu/目录下。 [root@docker dockerfile]# pwd /root/dockerfile [root@docker dockerfile]# echo zhujingxing > zisefeizhu [root@docker dockerfile]# vim Dockerfile # Description: test image FROM busybox ENV file=zisefeizhu ADD ./test /usr/local/$file/ [root@docker dockerfile]# docker build -t busy:v1 ./ # 根据此镜像启动容器并查看文件是否拷贝成功,并且查看file变量的值 [root@docker dockerfile]# docker run --name busy02 --rm busy:v1 ls /usr/local/zisefeizhu zhujingxing [root@docker dockerfile]# docker run --name busy02 --rm busy:v1 printenv PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin HOSTNAME=57111b7b234c file=zisefeizhu HOME=/root # 接下来我们在启动容器的时候加上-e参数为file变量指定一个新值,并且查看file变量的值 [root@docker dockerfile]# docker run --name busy02 -e file=zhujingxing --rm busy:v1 printenv PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin HOSTNAME=787ad8582fs0 file=zhujingxing HOME=/root # 此时再看test的文件,依然是在zisefeizhu的目录下的 [root@docker1 docker]# docker run --name busy02 -e file=bbb --rm busy:v1 ls /usr/local/zisefeizhu zhujingxing # 这是因为docker build属于第一阶段,而docker run属于第二阶段。第一阶段定义file变量的值zisefeizhu已经被引用了,生米已经煮成熟饭了,后续阶段再改file变量的值也影响不了zisefeizhu。
9.RUN 介绍 RUN用于指定 docker build过程中运行的程序,其可以是任何命令,但是这里有个限定,一般为基础镜像可以运行的命令,如基础镜像为centos,安装软件命令为yum而不是ubuntu里的apt-get命令。 RUN和CMD都可以改变容器运行的命令程序,但是运行的时间节点有区别,RUN表示在docker build运行的命令,而CMD是将镜像启动为容器运行的命令。因为一个容器正常只用来运行一个程序,因此CMD一般只有一条命令,如果CMD配置多个,则只有最后一条命令生效。而RUN可以有多个。 语法 RUN <command> 或者 RUN ["<executable>", "<param1>", "<param2>"] 第一种格式中,<command>通常是一个shell命令,系统默认会把后面的命令作为shell的子进程来运行,以“/bin/sh -c”作为父进程来运行它,这意味着此进程在容器中的PID不为1(如果是PID为1完事就结束了。用腿想),不能接收Unix信号,因此,当使用 docker stop <container>命令停止容器时,此进程接收不到SIGTERM信号; 第二种语法格式中的参数是一个JSON格式的数组,其中<executable>为要运行的命令,后面的<paramN>为传递给命令的选项或参数;然而,此种格式指定的命令不会以“/bin/sh -c”来发起(也就是直接由内核创建),表示这种命令在容器中直接运行,不会作为shell的子进程,因此常见的shell操作如变量替换以及通配符(?,*等)替换将不会进行。过,如果要运行的没能力依赖此shell特性的话,可以将其替换为类似下面的格式 RUN ["/bin/bash","-C","<executable>","<paraml>"] 如果RUN的命令很多,就用&&符号连接多个命令,少构建镜像层,提高容器的效率 例子 基础镜像为centos,RUN多个命令 由于安装是到互联网上的仓库进行安装,所以,建议把centos的yum源配置为本地,即创建镜像时,把yum的配置有本地仓库源配置在CentOS-Base.repo文件放在imp1下面,配置文件配置ADD拷贝一份到新建镜像的/etc/yum.repos.d目录下,因为经常默认会优先加载CentOS-Base.repo下的包,但是不建议使用这个方法,除非本地仓库有足够的包解决依赖关系,否则建议仅使用默认的即可 编辑dockerfile [root@docker img1]# vim Dockerfile # Description: nginx image FROM centos:7.3.1611 MAINTAINER "zisefeizhu <zisefeizhu@zhujingxing.com>" ENV nginx_ver=1.14.0 ENV nginx_url=http://nginx.org/download/nginx-${nginx_ver}.tar.gz WORKDIR "/usr/local/src" ADD CentOS-Base.repo /etc/yum.repos.d/ ADD ${nginx_url} /usr/local/src/ RUN tar xf nginx-${nginx_ver}.tar.gz && \ yum -y install gcc pcre-devel openssl-devel make && \ cd nginx-${nginx_ver} && \ ./configure && make && make install 创建镜像 [root@docker img1]# docker build -t nginx:v1 ./ 运行容器,启动nginx进程 [root@docker img1]# docker run -it --rm --name nginxv1 nginx:v1 [root@ccedfdf5e63f src]# /usr/local/nginx/sbin/nginx 此时,nginx进程运行于后台,不建议这么做,因为容器的进程要运行于前台模式,否则容器会终止,nginx运行于前台,需要在nginx的配置文件nginx.conf里添加配置项 vi /usr/local/nginx/conf/nginx.conf daemon off; 这样使得nginx运行于前台 再次运行nginx,则运行于前台 或者通过-g选项,在运行nginx的全局配置模式之后再运行某些参数,注意off后面的冒号 [root@ccedfdf5e63f local]# /usr/local/nginx/sbin/nginx -g "daemon off;"
10.CMD 介绍 指定启动容器的默认要运行的程序,也就是PID为1的进程命令,且其运行结束后容器也会终止。如果不指定,默认是bash。CMD指令指定的默认程序会被docker run命令行指定的参数所覆盖。Dockerfile中可以存在多个CMD指令,但仅最后一个生效。因为一个docker容器只能运行一个PID为1的进程。类似于RUN指令,也可以运行任意命令或程序,但是两者的运行时间点不同:RUN指令运行在docker build的过程中,而CMD指令运行在基于新镜像启动容器(docker run)时。 语法 CMD <command> 或者 CMD ["<executable>","<param1>","<param2>"] 或者 CMD["<param1>","<param2>"] 前两种语法格式的意义同 RUN 第三种则用于为 ENTRYPOINT指令提供默认参数 例子 CMD /bin/httpd -f -h ${WEB_DOC_ROOT} CMD [ "/bin/httpd","-f","-h ${WEB_DOC_ROOT}"] CMD [ "/bin/sh","-c","/bin/httpd","-f","-h ${WEB_DOC_ROOT}"] CMD [ "/bin/sh","-c","/bin/httpd","-f","-h /data/web/html"] CMD ["/usr/local/nginx/sbin/nginx","-g","daemon off;"] [root@docker dockerfile]# cat Dockerfile #Description: test image FROM busybox LABEL maintainer="zisefeizhu <zisefeizhu@qq.com>" app="httpd" ENV WEBDIR="/data/web/html" RUN mkdir -p ${WEBDIR} && \ echo 'this is a test web' > ${WEBDIR}/index.html CMD [ "sh","-c","/bin/httpd","-f","-h ${WEBDIR}" ] [root@docker dockerfile]# docker build -t httpd:v1 ./ [root@docker dockerfile]# docker run --name web01 -it --rm httpd:v1 ls /data/web/html index.html # 可以看出命令行的参数已经替代了原本的CMD指令指定的程序
11.ENTRYPOINT 介绍 类似CMD指令的功能,用于为容器指定默认运行程序。Dockerfile中可以存在多个ENTRYPOINT指令,但仅最后一个生效。与CMD区别在于,由ENTRYPOINT启动的程序不会被docker run命令行指定的参数所覆盖,而且这些命令行参数会被当做参数传递给ENTRYPOINT指令指定的程序。不过,docker run的--entrypoint选项的参数可覆盖ENTRYPOINT指定的默认程序 语法 ENTRYPOINT command param1 param2 ENTRYPOINT ["executable", "param1", "param2"] 例子 [root@docker dockerfile]# cat Dockerfile #Description: test image FROM busybox LABEL maintainer="zisefeizhu <zisefeizhu@qq.com>" app="httpd" ENV WEBDIR="/data/web/html" RUN mkdir -p ${WEBDIR} && \ echo 'this is a test web' > ${WEBDIR}/index.html ENTRYPOINT [ "sh","-c","/bin/httpd -f -h ${WEBDIR}" ] [root@docker dockerfile]# docker build -t httpd:v2 ./ [root@docker dockerfile]# docker run --name web01 -it --rm httpd:v2 # 也是前台启动,复制一个窗口,kill掉容器,然后开始docker run结尾传入新的指令 [root@docker dockerfile]# docker run --name web01 -it --rm httpd:v2 ls /data/web/html # 可以看到没有反应,这种情况其实是把ls /data/web/html当做参数传给了/bin/httpd -f -h ${WEBDIR}程序。只是httpd不识别罢了。我们kill掉容器。加上--entrypoint参数再试一下 [root@docker dockerfile]# docker run --name web01 -it --rm --entrypoint="" httpd:v2 ls /data/web/html index.html # 使用--entrypoint参数替换命令成功。 # 再测试下CMD的第三种语法,CMD指令的后面的命令作为参数传给ENTRYPOINT指令后的命令 [root@docker dockerfile]# vim Dockerfile # Description: test image FROM busybox LABEL maintainer="zisefeizhu <zisefeizhu@qq.com>" app="httpd" ENV WEBDIR="/data/web/html" RUN mkdir -p ${WEBDIR} && \ echo 'this is a test web' > ${WEBDIR}/index.html CMD [ "/bin/httpd -f -h ${WEBDIR}" ] ENTRYPOINT [ "sh","-c" ] [root@docker dockerfile]# docker build -t httpd:v3 ./ [root@docker dockerfile]# docker run --name web01 -it --rm httpd:v3 # OK的,前面有说过:指定ENTRYPOINT的情况下,如果docker run命令行结尾有参数指定,那CMD后面的参数不生效,下面咱再试试,还用v3的镜像。 [root@docker dockerfile]# docker run --name web01 -it --rm httpd:v3 "ls /data/web/html" index.html [root@docker dockerfile]# vim Dockerfile FROM nginx:1.14-alpine LABEL maintainer="zhujingxing <zisefeizhu@zhujingxing>" ENV NGX_DOC_ROOT='/data/web/html/' ADD index.html ${NGX_DOC_ROOT} ADD entrypoint.sh /bin/ CMD ["/usr/sbin/nginx","-g","daemon off;"] //注:双引号 ENTRYPOINT ["/bin/entrypoint.sh"] [root@docker dockerfile]# vim entrypoint.sh #!/bin/sh cat > /etc/nginx/conf.d/www.conf <<EOF server { server_name $HOSTNAME; listen ${IP:-0.0.0.0}:${PORT:-80}; root ${NGX_DOC_ROOT:-/usr/share/nginx/html}; } EOF exec "$@" [root@docker dockerfile]# docker build -t myweb:v0.3-6 ./ [root@docker dockerfile]# docker run --name myweb1 --rm -P -e "PORT=8080" myweb:v0.3-6 [root@docker dockerfile]# docker exec -it myweb1 /bin/sh / # netstat -lnt Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN / # ps PID USER TIME COMMAND 1 root 0:00 nginx: master process /usr/sbin/nginx -g daemon off; 8 nginx 0:00 nginx: worker process 9 root 0:00 /bin/sh 15 root 0:00 ps / # wget -O - -q adf1e144ec50 <h1>zhujingxing</h1> / # exit
12.HEALTHCHECK 介绍 健康检查。此指令的就是告诉docker如果检查容器是否正常工作。拿apache举例,即便进程运行,服务也不一定正常,因为万一root指错了呢? 通过HEALTHCHECK,我们可以知道如何测试一个容器查检一个它是否在工作,比如检测一个web 服务是否陷入死循环,不能处理新的连接、即使服务器进程仍在运行。 当一个窗口指定了健康检查时、除了正常状态之外、还会有一个健康状态作为初始、如果检查通过、则会变成健康状态、如果经过了一定次数的连续故障、则会变成非健康状态。 语法 HEALTHCHECK [OPTIONS] CMD command (通过在容器中运行一个命令执行健康检查) HEALTHCHECK NONE (禁用从基本镜像继承的任何健康检查) HEALTHCHECK指令让我们去定义一个CMD,在CMD后面编写一条命令去判断我们的服务运行是否正常。检查肯定不是一次性的,所以OPTIONS就是指定检查的频率等等。 --interval=DURATION(默认值:30s):每隔多久检查一次,默认30s --timeout=DURATION(默认值:30s):超时时长,默认30s --start-period=DURATION(默认值:0s):启动健康检查的等待时间。因为容器启动成功时,进程不一定立马就启动成功,那过早开始检查就会返回不健康。 --retries=N(默认值:3):如果检查一次失败就返回不健康未免太武断,所以默认三次机会。 CMD健康检测命令发出时,返回值有三种情况 0:成功 1:不健康 2:保留,无实际意义。 HEALTHCHECK NONE就是不做健康检查 规则 启动周期为需要时间启动的容器提供初始化时间。 在此期间的探测失败不会计入最大重试次数。 但是,如果在启动期间运行状况检查成功,则认为容器已启动,并且所有连续的故障都将计入最大重试次数。 单次运行检查花费时间超过timeout指定时间、判定失败。 每个Dockerfile中只能存在一个HEALTHCHECK指令,如果有多个则最后一个起作用。 HEALTHCHECK CMD后面的命令既可以是一个shell命令、也可以是一个exec 的数组。 例子 实例:每隔五分钟检查一次网络服务器是否能够在三秒钟内为该网站的主页面提供服务 HEALTHCHECK --interval=5m --timeout=3s CMD curl -f http://localhost/ || exit 1 为方便故障探测调试、检测命令通过stdout或者stderr输出的文本都会被缓存在健康状态中(缓存大小为4096字节)、并可以通过docker inspect查询 当容器的运行状况发生变化时,新的状态会生成一个health_status事件 成功的例子: [root@docker dockerfile]# cat Dockerfile FROM nginx:1.14-alpine LABEL maintainer="zhujingxing <zisefeizhu@zhujingxing>" ENV NGX_DOC_ROOT=”/data/web/html/” ADD index.html ${NGX_DOC_ROOT} ADD entrypoint.sh /bin/ EXPOSE 80/TCP HEALTHCHECK --start-period=3s CMD wget -O - -q http://${IP:-0.0.0.0}:${PORT:80}/ CMD ["/usr/sbin/nginx","-g","daemon off;"] ENTRYPOINT ["/bin/entrypoint.sh"] [root@docker dockerfile]# docker build -t myweb:v0.1 ./ [root@docker dockerfile]# docker run --name myweb1 --rm -P -e "PORT=8080" myweb:v0.1 [root@docker dockerfile]# docker exec -it myweb1 /bin/sh / # netstat -tnl Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN / # wget -O [root@docker dockerfile]# docker run --name myweb1 --rm -P -e "PORT=8080" myweb:v0.1 127.0.0.1 - - [03/Aug/2019:13:15:35 +0000] "GET / HTTP/1.1" 200 612 "-" "Wget" "-" 127.0.0.1 - - [03/Aug/2019:13:15:43 +0000] "GET / HTTP/1.1" 200 612 "-" "Wget" "-" 失败的例子 [root@docker dockerfile]# vim Dockerfile FROM nginx:1.14-alpine LABEL maintainer="zhujingxing <zisefeizhu@zhujingxing>" ENV NGX_DOC_ROOT='/data/web/html/' ADD index.html ${NGX_DOC_ROOT} ADD entrypoint.sh /bin/ EXPOSE 80/TCP HEALTHCHECK --start-period=3s CMD wget -O - -q http://${IP:-0.0.0.0}:10080/ CMD ["/usr/sbin/nginx","-g","daemon off;"] ENTRYPOINT ["/bin/entrypoint.sh"] [root@docker dockerfile]# docker build -t myweb:v0.2 ./ [root@docker dockerfile]# docker run --name myweb1 --rm -P -e "PORT=8080" myweb:v0.2 //三个周期默认1.5分钟后报错 [root@docker dockerfile]# docker exec -it myweb1 /bin/sh / # netstat -tnl Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN
13.ARG 介绍 ARG命令同EVN类似,也是指定一个变量,但不同的是,ENV指令配合-e参数可以在docker run过程中传参,而使用ARG指令配合--build-arg参数可以在docker build过程中传参,这方便了我们为不同场景构建不同镜像。 语法 ARG <name>[=<default value>] 例子 [root@docker dockerfile]# vim Dockerfile FROM nginx:1.14-alpine ARG AUTHOR=";zisefeizhu <zisefeizhu@qq.com>" # 指定默认值 LABEL maintainer=$AUTHOR ENV NGXDIR='/data/web/html/' ADD index.html $NGXDIR ADD entrypoint.sh /bin/ CMD ["nginx", "-g", "daemon off;"] ENTRYPOINT ["/bin/entrypoint.sh"] [root@docker dockerfile]# docker build --build-arg AUTHOR="zhujingxing <zhujingxing@qq.com>" -t nginx:v4 ./ [root@docker dockerfile]# docker image inspect nginx:v4 | grep maintainer "maintainer": "zhujingxing <zhujingxing@qq.com>" # 上面只是以maintainer举例,实践环境中可以修改为不同jar包的名字构建不同java程序镜像。
14.STOPSIJNAL 介绍 指定发送使容器退出的系统调用信号。docker stop之所以能停止容器,就是发送了15的信号给容器内PID为1的进程。此指令一般不会使用。 语法 STOPSIGNAL signal
15.SHELL 介绍 用来指定运行程序默认要使用的shell类型,因为windows环境默认是powershell。此指令一般不会使用。 语法 SHELL ["executable", "parameters"] 例子 # Executed as powershell -command Write-Host hello SHELL ["powershell", "-command"] RUN Write-Host hello # Executed as cmd /S /C echo hello SHELL ["cmd", "/S"", "/C"] RUN echo hello
16.USER 介绍 USER用于指定运行image时的或运行Dockerfile中任何RUN、CMD或ENTRYPOINT指令指定的程序时的用户名或UID,即改变容器中运行程序的身份。默认情况下,container的运行身份为root用户。 语法 USER <user>[:<group>] USER <UID>[:<GID>] 实践中UID需要是/etc/passwd中某用户的有效UID,否则docker run命令将运行失败 规则 使用USER指定用户后,Dockerfile中其后的命令 RUN、CMD、ENTRYPOINT 都将使用该用户。镜像构建完成后,通过 docker run运行容器时,可以通过-u 参数来覆盖所指定的用户。
17.ONBUILD 介绍 ONBUILD用于在Dockerfile中定义一个触发器,用来指定运行docker指令。Dockerfile用于build镜像文件,此镜像文件亦可作为base image被另一个Dockerfile用作FROM指令的参数,并以之构建新的镜像文件。在后面的这个Dockerfile中的FROM指令在build过程中被执行时,将会“触发”创建其base image的Dockerfile文件中的ONBUILD指令定义的触发器。 语法 ONBUILD <INSTRUCTION> 规则 尽管任何指令都可注册成为触发器指令,但是ONBUILD不能自我嵌套,且不会触发FROM和MAINTAINER(LABEL)指令。 使用包含ONBUILD指令的Dockerfile构建的镜像应该使用特殊的标签,例如ruby:2.0-onbuild。 在ONBUILD指令中使用ADD或COPY指令应该格外小心,因为新构建过程的上下文在缺少指定的源文件时会失败。 ONBUILD 在构建镜像时不会运行,是别人基于这个镜像作为基础镜像构建时,才会运行。 例子 增加一个ONBUILD命令,执行RUN FROM centos:7.3.1611 ENV nginx_ver=1.14.0 ENV nginx_url=http://nginx.org/download/nginx-${nginx_ver}.tar.gz WORKDIR "/usr/local/src" EXPOSE 80/tcp ADD ${nginx_url} /usr/local/src/ RUN tar xf nginx-${nginx_ver}.tar.gz && yum -y install gcc pcre-devel openssl-devel make \ && cd nginx-${nginx_ver} && ./configure && make && make install CMD ["/usr/local/nginx/sbin/nginx","-g","daemon off;"] ONBUILD RUN echo -e "\nSunny do an onbuild~\n" >> /etc/issue 构建镜像 [root@docker dockerfile]# docker build -t nginx:v6 ./ 基于nginx:v6启动容器,此时/etc/issue还没写入echo要插入的信息 [root@docker dockerfile]# docker run -it --rm -P --name nginxv3 nginx:v6 /bin/bash [root@docker dockerfile]# cat /etc/issue \S Kernel \r on an \m 然后基于这个nginx:v6镜像,再次制作一个新镜像,编辑一个新的Dockerfile [root@docker dockerfile]# mkdir nginxv7 [root@docker dockerfile]# cd nginxv7/ [root@docker dockerfile]# vim Dockerfile FROM nginx:v6 CMD "/bin/bash" 构建镜像,注意,会提示执行一个build trigger,如下Executing 1 build trigger [root@docker dockerfile]# docker build -t nginx:v7 ./ 基于新镜像nginx:v7启动新容器nginxv7 [root@docker dockerfile]# docker run -it --rm --name nginxv7 nginx:v7 [root@becc66948713 src]# cat /etc/issue \S Kernel \r on an \m Sunny do an onbuild [root@becc66948713 src]# 此时,在旧的镜像中的dockerfile里的ONBUILD已经触发,把信息写入到/etc/issue里
2.8.5 dockerfile 优化
最不容易发生变化的文件的拷贝操作放在较低的镜像层中
容器轻量化。从镜像中产生的容器应该尽量轻量化,能在足够短的时间内停止、销毁、重新生成并替换原来的容器。
为了减少镜像的大小,减少依赖,仅安装需要的软件包。
一个容器只做一件事。解耦复杂的应用,分成多个容器,而不是所有东西都放在一个容器内运行。如一个 Python Web 应用,可能需要 Server、DB、Cache、MQ、Log 等几个容器。一个更加极端的说法:One process per container。
减少镜像的图层。不要多个 Label、ENV 等标签。
对续行的参数按照字母表排序,特别是使用apt-get install -y安装包的时候。
使用构建缓存。如果不想使用缓存,可以在构建的时候使用参数--no-cache=true来强制重新生成中间镜像。
2.9 docker仓库
细心的道友一定发现,我在第一章的集群搭建中并没有部署仓库集群。原因是:我个人想把镜像仓库做成kubernetes集群的pod,这样的话必然牵扯到后端存储。而存储是我要单独用一章来讲的。为了docker章节的完整性,不得不阐述镜像仓库,但这并不代表我集群中的仓库部署。仅仅是为了学习,为了章节完整性。
前面的章节有讲过公有仓库的使用,如 Docker.Hub 和阿里云镜像仓库。这种方式有明显的缺陷:push 和 pull 的速度很慢,假若实际环境有上百台机器,那需要多大带宽才能 hold 住。所以多数时候还是需要创建自己的私有仓库。工作中的生产环境主机选择基本有三种:自建机房、IDC机房托管和阿里公有云,前两种情况最好是将 docker 私有仓库建立在局域网内,而第三种使用阿里云镜像仓库无非是最恰当的选择。
搭建私有仓库有两种种方式:
使用 Docker 官方提供的 docker-distribution。可以通过 docker container 或者 yum 的方式安装。docker container 的方式需要把镜像存储目录挂载到宿主机的某目录下,防止容器意外中止或者删除导致仓库不可用。此种 registry 功能比较单一。
使用 harbor,这是 VMware 基于 docker-distribution 二次开发的软件,现在已经加入了 CNCF。功能强大,界面美观。值得一提的是harbor支持中文,是不是很 happy,道友们。因为二次开发此软件的主力是 VMware 中国区团队。另外,原本的 harbor 部署是非常困难的,因此 harbor 官网直接把 harbor 做成了可以在容器中运行的应用,且 harbor 容器启动时要依赖于其它一些容器协同工作,所以它在部署和使用时需要用到 docker 的单机编排工具 docker compose。
在生产实际中,现阶段的镜像仓库还是harbor占据明显优势,so,这节,我将直接阐述harbor仓库。
我曾写过一篇《docker私有registry和harbor的使用》。我认为已经阐述的足够详尽,有兴趣的道友可以了解:https://blog.csdn.net/zisefeizhu/article/details/83511586
2.9.1 harbor简介
Harbor 是Vmware公司开源的企业级Docker Registry管理项目,开源项目地址:https://github.com/vmware/harbor
Harbor的所有组件都在Docker中部署,所以Harbor可使用Docker Compose快速部署。(由于Harbor是基于Docker Registry V2版本,所以docker版本至少1.10.0、docker-compose版本至少1.6.0)
组件
(1)proxy:nginx前端代理,分发前端页面ui访问和镜像上传和下载流量;
(2)ui:提供前端页面和后端API,底层使用mysql数据库;
(3)registry:镜像仓库,负责存储镜像文件,当镜像上传完毕后通过hook通知ui创建repository,registry的token认证也是通过ui组件完成;
(4)adminserver是系统的配置管理中心附带检查存储用量,ui和jobserver启动时候回需要加载adminserver的配置
(5)jobsevice:负责镜像复制工作,和registry通信,从一个registry pull镜像然后push到另一个registry,并记录job_log;
(6)log:日志汇总组件,通过docker的log-driver把日志汇总到一起。
Harbor介绍
Harbor是一个用于存储和分发Docker镜像的企业级Registry服务器,通过添加一些企业必需的功能特性,例如安全、标识和管理等,扩展了开源Docker Distribution。作为一个企业级私有Registry服务器,Harbor提供了更好的性能和安全。提升用户使用Registry构建和运行环境传输镜像的效率。Harbor支持安装在多个Registry节点的镜像资源复制,镜像全部保存在私有Registry中, 确保数据和知识产权在公司内部网络中管控。另外,Harbor也提供了高级的安全特性,诸如用户管理,访问控制和活动审计等。
Harbor特性
基于角色的访问控制 :用户与Docker镜像仓库通过“项目”进行组织管理,一个用户可以对多个镜像仓库在同一命名空间(project)里有不同的权限。
镜像复制 : 镜像可以在多个Registry实例中复制(同步)。尤其适合于负载均衡,高可用,混合云和多云的场景。
图形化用户界面 : 用户可以通过浏览器来浏览,检索当前Docker镜像仓库,管理项目和命名空间。
AD/LDAP 支持 : Harbor可以集成企业内部已有的AD/LDAP,用于鉴权认证管理。
审计管理 : 所有针对镜像仓库的操作都可以被记录追溯,用于审计管理。
国际化 : 已拥有英文、中文、德文、日文和俄文的本地化版本。更多的语言将会添加进来。
RESTful API : RESTful API 提供给管理员对于Harbor更多的操控, 使得与其它管理软件集成变得更容易。
部署简单 : 提供在线和离线两种安装工具, 也可以安装到vSphere平台(OVA方式)虚拟设备。
2.9.2 harbor部署
[root@docker02 ~]# hostname -I
20.0.0.200
# harbor 托管在GitHub上,页面搜索" Installation & Configuration Guide "可以查看安装步骤。下载 harbor压缩包,并解压。
[root@docker02 ~]# mkdir work
[root@docker02 ~]# cd work
[root@docker02 work]# wget https://storage.googleapis.com/harbor-releases/release-1.8.0/harbor-offline-installer-v1.8.1.tgz
[root@docker02 work]# ls
harbor-offline-installer-v1.8.1.tgz
[root@docker02 work]# tar xf harbor-offline-installer-v1.8.1.tgz
[root@docker02 work]# tar xf harbor-offline-installer-v1.8.1.tgz -C /usr/local/
[root@docker02 work]# cd /usr/local/harbor/
[root@docker02 harbor]# ll
总用量 551208
-rw-r--r-- 1 root root 564403568 6月 17 11:30 harbor.v1.8.1.tar.gz
-rw-r--r-- 1 root root 4519 6月 17 11:29 harbor.yml
-rwxr-xr-x 1 root root 5088 6月 17 11:29 install.sh
-rw-r--r-- 1 root root 11347 6月 17 11:29 LICENSE
-rwxr-xr-x 1 root root 1654 6月 17 11:29 prepare
#修改hardor的配置文件
hostname: 20.0.0.200 # 填写局域网或者互联网可以访问得地址,有域名可以写域名
harbor_admin_password: 123456 # 管理员的初始密码,默认用户名为admin
database:
password: root123 # 数据库密码。默认是root123
data_volume: /data # 存储harbor数据的位置
jobservice:
max_job_workers: 10 # 启动几个并发进程来处理用户的上传下载请求。一般略小于CPU核心数。
# 一般会修改的参数也就上面几项,另外http和https根据自己实际情况配置进行,这里就使用默认的http。
[root@docker02 harbor]# ./install.sh
[Step 0]: checking installation environment ...
Note: docker version: 19.03.1
✖ Need to install docker-compose(1.18.0+) by yourself first and run this script again.
[root@docker02 harbor]# yum info docker-compose | egrep -i 'repo|version'
* elrepo: hkg.mirror.rackspace.com
[root@docker02 harbor]# yum -y install docker-compose
# 开始安装harbor,因为需要解压使用harbor.v1.8.1.tar.gz中打包好的镜像,所以需要稍微等一下。
[root@docker02 harbor]# ./install.sh
✔ ----Harbor has been installed and started successfully.----
Now you should be able to visit the admin portal at http://20.0.0.200.
For more details, please visit https://github.com/goharbor/harbor .
[root@docker02 harbor]# netstat -lntup
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:1514 0.0.0.0:* LISTEN 2973/docker-proxy
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 955/sshd
tcp6 0 0 :::80 :::* LISTEN 3724/docker-proxy
tcp6 0 0 :::22 :::* LISTEN 955/sshd
udp 0 0 127.0.0.1:323 0.0.0.0:* 709/chronyd
udp6 0 0 ::1:323 :::* 709/chronyd
问harbor的web界面,上面执行 ./install.sh 的结尾有提示web登入的方式。用户名和密码:admin/123456

接下来我们开始创建私有仓库。
先创建一个普通的账户
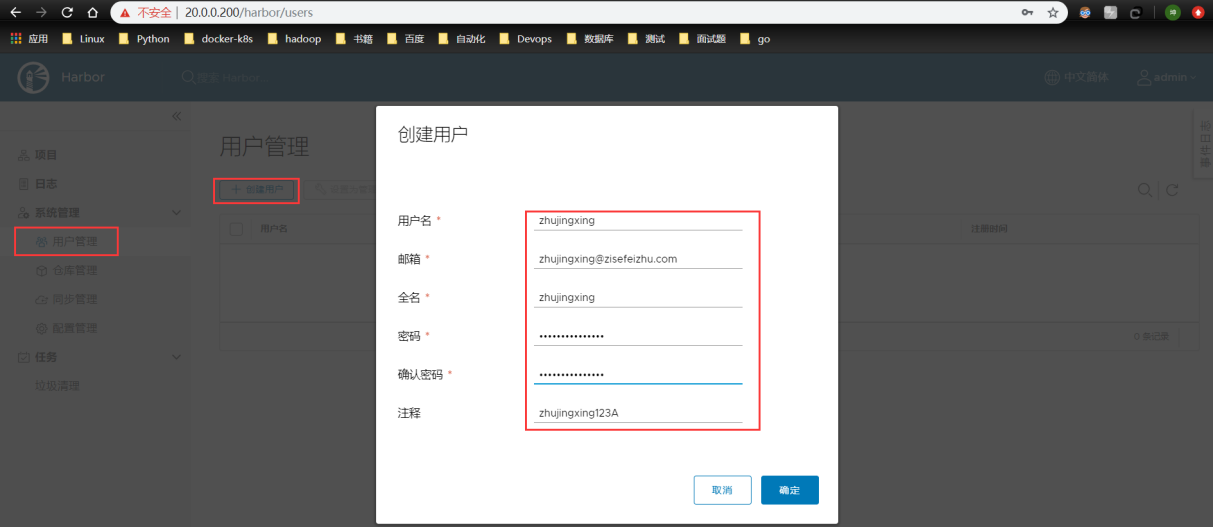
切换上面的普通账户,新建立一个私有项目
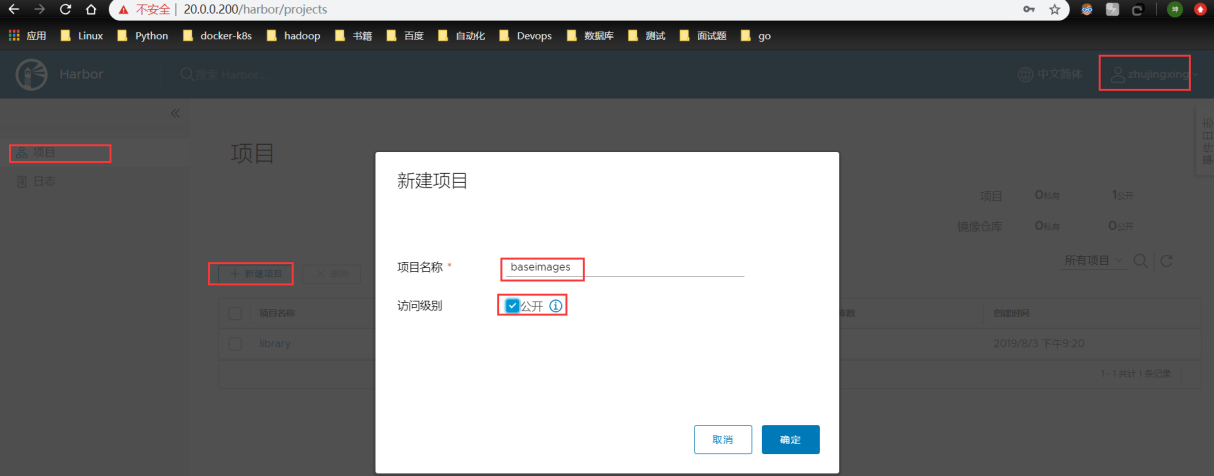
推送镜像到baseimages项目中
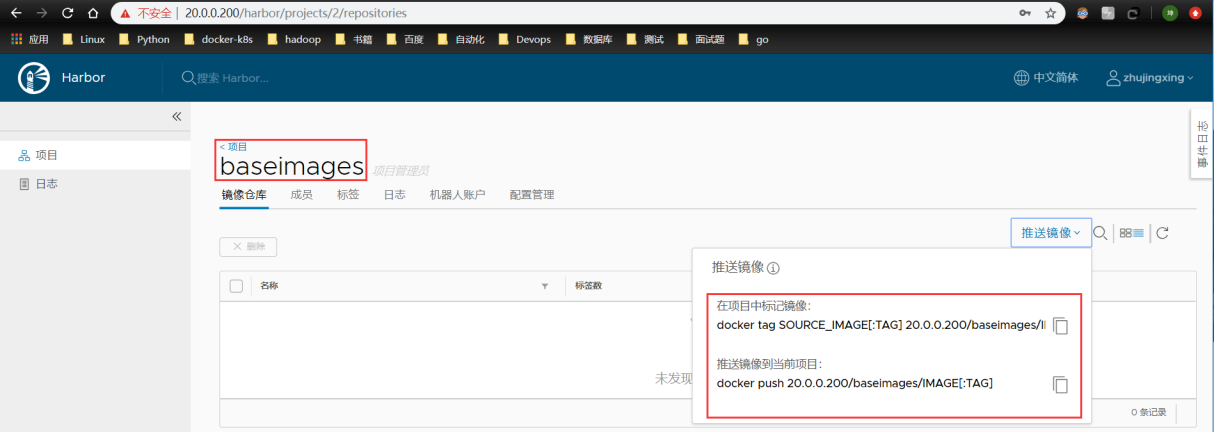
[root@docker ~]# cp /etc/docker/daemon.json{,.bak}
cp:是否覆盖"/etc/docker/daemon.json.bak"? y
[root@docker ~]# vim /etc/docker/daemon.json
[root@docker ~]# diff /etc/docker/daemon.json{,.bak}
3,4c3
< "bip": "10.0.0.1/16",
< "insecure-registries": ["20.0.0.200"]
---
> "bip": "10.0.0.1/16"
[root@docker ~]# systemctl restart docker
Warning: docker.service changed on disk. Run 'systemctl daemon-reload' to reload units.
[root@docker ~]# systemctl daemon-reload
[root@docker ~]# systemctl restart docker
[root@docker ~]# docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
busy v1 e0078e53d05d 6 hours ago 1.22MB
[root@docker ~]# docker tag busy:v1 20.0.0.200/baseimages/busy:v1
[root@docker ~]# docker login -u zhujingxing 20.0.0.200
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
[root@docker ~]# docker push 20.0.0.200/baseimages/busy:v1
The push refers to repository [20.0.0.200/baseimages/busy]
f6d434d1b26b: Pushed
0d315111b484: Pushed
v1: digest: sha256:2c7184696987b361dbf2c30cc4410858d1245a31921cec80bf6ca6b73857470b size: 734
刷新harbor页面
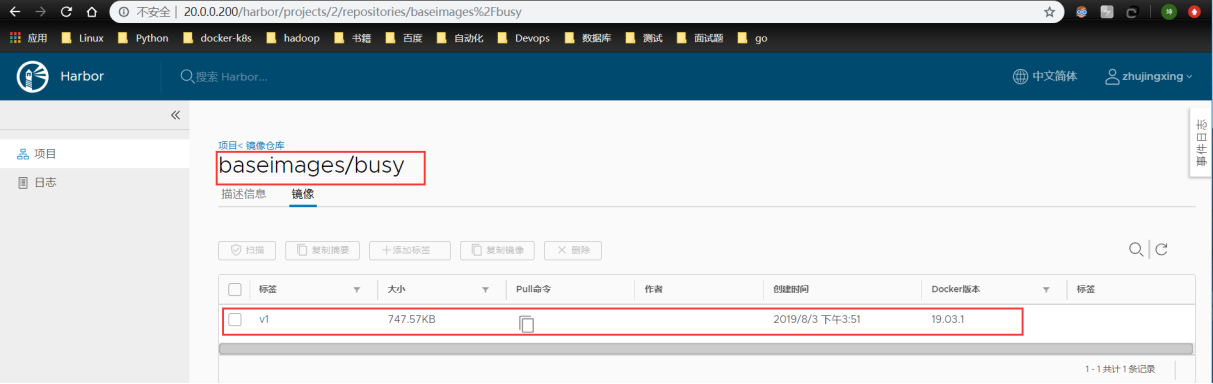
到这私有仓库也就搭建完成了,也可以在 /data 目录下查看数据
[root@docker02 harbor]# ll /data/registry/docker/registry/v2/repositories/baseimages/
总用量 0
drwxr-xr-x 5 10000 10000 55 8月 3 21:35 busy
如果要对harbor服务做一些操作,需要使用docker-compose命令
# 其实前面的./install.sh也是使用的 docker-compose create 和 docker-compose start 命令启动的 harbor。注意,命令执行需要再harbor的目录下,否则会报错找不到配置文件。
[root@docker02 harbor]# docker-compose --help
[root@docker02 ~]# docker-compose pause
ERROR:
Can't find a suitable configuration file in this directory or any
parent. Are you in the right directory?
Supported filenames: docker-compose.yml, docker-compose.yaml
[root@docker02 ~]# cd -
/usr/local/harbor
[root@docker2 harbor]# docker-compose pause
Pausing harbor-log ... done
Pausing redis ... done
Pausing harbor-db ... done
Pausing registry ... done
Pausing registryctl ... done
Pausing harbor-core ... done
Pausing harbor-portal ... done
Pausing harbor-jobservice ... done
Pausing nginx ... done
#开机自启动harbor
[root@docker02 harbor]# cp /etc/rc.d/rc.local{,.bak}
[root@docker02 harbor]# vim /etc/rc.d/rc.local
[root@docker02 harbor]# diff /etc/rc.d/rc.local{,.bak}
14,15d13
< #harbor
< cd /usr/local/harbor && docker-compose start
注:
在此章节,我只是围绕harbor仓库进行阐述,详细了解请看我提供的链接。
在此章节,我并没有阐述harbor仓库的高可用,安全等问题,这算几处坑吧,在kubernetes编排工具章,我会进行填补。
2.10 docker资源限制
默认情况下,容器没有资源限制,可以使用主机内核调度程序允许的尽可能多的给定资源。
Docker同LXC一样,其对资源的隔离和管控是以Linux内核的namespaces和cgroup为基础。Docker的资源隔离使用了Linux内核 Kernel中的Namespaces功能来实现,隔离的对象包括:主机名与域名、进程编号、网络设备、文件系统的挂载点等,namespace中的IPC隔离docker并未使用,docker中使用TCP替代IPC。
在使用Namespaces隔离资源的同时,Docker使用了Linux内核Kernel提供的cgroup来对Container使用的CPU、内存、磁盘IO资源进行配额管控。换句话说,在docker的容器启动参数中,像--cpu*、--memory*和--blkio*的设置,实际上就是设置cgroup的相对应cpu子系统、内存子系统、磁盘IO子系统的配额控制文件,只不过这个修改配额控制文件的过程是docker实例代替我们做掉罢了。因此,我们完全可以直接修改docker容器所对应的cgroup子系统中的配额控制文件来达到控制docker容器资源配额的同样目的。
2.10.1 memory
内存风险
不允许容器消耗宿主机太多的内存是非常重要的。在Linux主机上,如果内核检测到没有足够的内存来执行重要的系统功能,它会抛出OOME或Out of Memory异常,并开始终止进程以释放内存。任何进程都会被杀死,包括 Docker和其他重要的应用程序。如果杀错进程,可能导致整个系统瘫痪。
Docker 通过调整 Docker daemon 上的 OOM 优先级来降低这些风险,以便它比系统上的其他进程更不可能被杀死。容器上的 OOM 优先级未调整,这使得单个容器被杀死的可能性比 Docker daemon 或其他系统进程被杀死的可能性更大。你不应试图通过在 daemon 或容器上手动设置--oom-score-adj到极端负数,或通过在容器上设置--oom-kill-disable来绕过这些安全措施。
有关Linux内核的OOM管理的更多信息,查看 Out of Memory Management:https://www.kernel.org/doc/gorman/html/understand/understand016.html
可以通过以下方式降低 OOME 导致系统不稳定的风险:
在应用程序发布到生产之前,执行相关测试以便了解应用程序的内存要求;
确保应用程序仅在具有足够资源的主机上运行;
限制容器可以使用的内存,如下所述;
在 Docker 主机上配置 Swap 时要小心,Swap 比内存更慢且性能更低,但可以提供缓冲以防止系统内存耗尽;
考虑将 Container 转换部署为 Service,并使用服务级别约束和节点标签来确保应用程序仅在具有足够内存的主机上运行。
限制容器内存
下述选项中的大多数采用正整数,后跟b/k/m/g的后缀,代表单位:字节/千字节/兆字节/千兆字节。
有关 cgroup 和内存的更多信息,查看Memory Resource Controller:https://www.kernel.org/doc/Documentation/cgroup-v1/memory.txt
关于 --memory-swap
--memory-swap是一个修饰符标志,只有在设置了--memory时才有意义。使用swap允许容器在容器耗尽所有可用的RAM时,将多余的内存需求写入磁盘。对于经常将内存交换到磁盘的应用程序,性能会受到影响。
它的设置会产生复杂的影响:
如果--memory-swap设置为正整数,则必须设置--memory和--memory-swap。--memory-swap表示可以使用的memory和swap总量, --memory控制no-swap的用量。所以,如果设置--memory="300m"和--memory-swap="1g", 容器可以使用300m memory和700m (1g - 300m)swap。
如果--memory-swap设置为0,该设置被忽略,该值被视为未设置。
如果--memory-swap的值等于--memory的值,并且--memory设置为正整数,则容器无权访问swap。这是因为--memory-swap是可以使用组合的 Memory和 Swap,而--memory只是可以使用的 Memory。
如果--memory-swap不设置,并且--memory设置了值, 容器可以使用--memory两倍的Swap(如果主机容器配置了Swap)。
示例:设置--memory="300m"并且不设置--memory-swap,容器可以使用300m memory和600m swap。
如果--memory-swap设置为-1,允许容器无限制使用Swap。
在容器内部,像free等工具报告的是主机的可用Swap,而不是容器内可用的。不要依赖于free或类似工具的输出来确定是否存在 Swap。

关于 --memory-swappiness
值为0时,关闭匿名页交换。
值为100时,将所有匿名页设置为可交换。
默认情况下,如果不设置--memory-swappiness,该值从主机继承。
关于 --kernel-memory
内核内存限制是就分配给容器的总内存而言的,考虑一下方案:
无限内存,无限内核内存:这是默认行为。
无限内存,有限内核内存:当所有 cgroup 所需的内存量大于主机上实际存在的内存量时,它是合适的。可以将内核内存配置为永远不会超过主机上可用的内存,而需求更多内存的容器需要等待它。
有限内存,无限内核内存:整体内存有限,但内核内存不是。
有限内存,有限内核内存:限制用户和内核内存对于调试与内存相关的问题非常有用,如果容器使用意外数量的任意类型的内存,则内存不足不会影响其他容器或主机。在此设置中,如果内核内存限制低于用户内存限制,则内核内存不足会导致容器遇到 OOM 错误。如果内核内存限制高于用户内存限制,则内核限制不会导致容器遇到OOM。
当你打开任何内核内存限制时,主机会根据每个进程跟踪“高水位线”统计信息,因此你可以跟踪哪些进程正在使用多余的内存。通过查看主机上的/proc/<PID>/status,可以在每个进程中看到这一点。
2.10.2 cpu
默认情况下,每个容器对主机 CPU 周期的访问权限是不受限制的,你可以设置各种约束来限制给定容器访问主机的CPU周期。大多数用户使用和配置默认 CFS调度程序。在Docker 1.13 及更高版本中,还可以配置实时调度程序。
配置默认 CFS 调度程序
CFS 是用于普通Linux进程的Linux内核CPU调度程序。通过以下设置,可以控制容器的CPU资源访问量,使用这些设置时,Docker会修改主机上容器的 cgroup的设置。

示例:如果你有 1 个 CPU,则以下每个命令都会保证容器每秒最多占 CPU 的 50%。
Docker 1.13 或更高版本:
[root@docker ~]# docker run -it --cpus=".5" busybox
配置实时调度程序
在 Docker 1.13 或更高版本,你可以配置容器使用实时调度程序。在配置 Docker daemon 或配置容器之前,需要确保正确配置主机的内核。
警告:CPU 调度和优先级是高级内核级功能,大多数用户不需要从默认值更改这些值,错误地设置这些值可能会导致主机系统变得不稳定或无法使用。
配置主机机器的内核
通过运行zcat /proc/config.gz|grep CONFIG_RT_GROUP_SCHED验证是否在Linux内核中启用了CONFIG_RT_GROUP_SCHED,或者检查是否存在文件/sys/fs/cgroup/cpu.rt_runtime_us。有关配置内核实时调度程序的教程,请参阅操作系统的文档。
配置DOCKER DAEMON
要使用实时调度程序运行容器,请运行Docker daemon,并将--cpu-rt-runtime设置为每个运行时间段为实时任务保留的最大微秒数。例如,默认周期为 1000000 微秒(1秒),设置--cpu-rt-runtime=950000可确保使用实时调度程序的容器每1000000微秒可运行950000微秒,并保留至少50000微秒用于非实时任务。要在使用systemd的系统上永久保留此配置,请参阅Control and configure Docker with systemd:https://docs.docker.com/config/daemon/systemd/
配置个别容器
使用docker run启动容器时,可以传递多个参数来控制容器的CPU优先级。有关适当值的信息,请参阅操作系统的文档或ulimit命令。

示例:
[root@docker ~]# docker run -it --cpu-rt-runtime=95000 --ulimit rtprio=99 --cap-add=sys_nice debian:jessie
注:如果未正确配置内核或 Docker Daemon,则会发生错误。
2.10.3 案例演示
[root@docker ~]# lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 4 #拖压测工具 [root@docker ~]# docker pull lorel/docker-stress-ng #设置选项 给docker传选项,该进程最多占用256M内存 --vm 2 则需要512M,内存溢出 [root@docker ~]# docker run --name stress -it --rm -m 256m lorel/docker-stress-ng stress --vm 2 stress-ng: info: [1] defaulting to a 86400 second run per stressor stress-ng: info: [1] dispatching hogs: 2 vm 另开一个窗口,查看进程 [root@docker ~]# docker top stress UID PID PPID C STIME TTY TIME CMD root 62445 62428 0 11:25 pts/0 00:00:00 /usr/bin/stress-ng stress --vm 2 root 62479 62445 0 11:25 pts/0 00:00:00 /usr/bin/stress-ng stress --vm 2 root 62480 62445 0 11:25 pts/0 00:00:00 /usr/bin/stress-ng stress --vm 2 root 62666 62480 0 11:25 pts/0 00:00:00 /usr/bin/stress-ng stress --vm 2 root 62676 62479 0 11:25 pts/0 00:00:00 /usr/bin/stress-ng stress --vm 2 #显示内存变量信息 [root@docker ~]# docker stats CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS 76c2d2f81ee2 stress 218.24% 215MiB / 256MiB 83.97% 0B / 0B 0B / 0B 5 #演示限制CPU核心数 也可以不加,默认会把CPU核数全吞下去 [root@docker ~]# docker run --name stress -it --rm --cpus 1 lorel/docker-stress-ng:latest stress --cpu 8 stress-ng: info: [1] defaulting to a 86400 second run per stressor stress-ng: info: [1] dispatching hogs: 8 cpu [root@docker ~]# docker top stress UID PID PPID C STIME TTY TIME CMD root 64853 64836 0 11:29 pts/0 00:00:00 /usr/bin/stress-ng stress --cpu 8 root 64887 64853 13 11:29 pts/0 00:00:08 /usr/bin/stress-ng stress --cpu 8 root 64888 64853 12 11:29 pts/0 00:00:07 /usr/bin/stress-ng stress --cpu 8 root 64889 64853 13 11:29 pts/0 00:00:08 /usr/bin/stress-ng stress --cpu 8 root 64890 64853 11 11:29 pts/0 00:00:07 /usr/bin/stress-ng stress --cpu 8 root 64891 64853 13 11:29 pts/0 00:00:08 /usr/bin/stress-ng stress --cpu 8 root 64892 64853 13 11:29 pts/0 00:00:08 /usr/bin/stress-ng stress --cpu 8 root 64893 64853 11 11:29 pts/0 00:00:07 /usr/bin/stress-ng stress --cpu 8 root 64894 64853 11 11:29 pts/0 00:00:07 /usr/bin/stress-ng stress --cpu 8 [root@docker ~]# docker stats CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS 390fae70a245 stress 0.10% 28MiB / 1.936GiB 1.41% 0B / 0B 0B / 0B 9 CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS 390fae70a245 stress 0.10% 28MiB / 1.936GiB 1.41% 0B / 0B 0B / 0B 9 [root@docker ~]# docker stats CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS 390fae70a245 stress 108.93% 28MiB / 1.936GiB 1.41% 0B / 0B
2.11 感言
单单容器是基本不会出现在生产场景的,必然要借助于编排工具,而编排工具能提供诸如:网络、资源限制、存储等功能,也就是说单单对于docker章的学习是集中于docker的基本用法、docker的镜像技术、dockerfile的书写。
对于docker仓库,我并没有详细阐述,甚至是一笔带过的,原因我之前已经有讲,我期待的是将重点、难点、复杂点都放在Kubernetes章节。
又是一星期,现在是2019年8月4号12点14分。到此为止docker章第一版算是基本完成。这个星期我熬了两天晚上的夜,倒不是因为写docker,主要是go语言有点难搞哦。7月份工作稳住,8月份该冲刺一波了。未来可期,应约而至,不忘初心,放得本心。

年轻人,一个星期熬两三次夜,也没得啥事嘛!

