使用经验风险最小化ERM方法来估计模型误差 开坑
虽然已经学习了许多机器学习的方法,可只有我们必须知道何时何处使用哪种方法,才能将他们正确运用起来。
那不妨使用经验最小化ERM方法来估计 。
首先:
![]()
其中,
δ代表训练出错的概率
k代表假设类的个数
m代表样本(数据集)个数
γ代表误差阈值
于是我们可以得到:
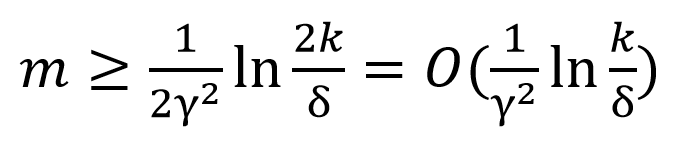
但我们的假设都是建立在k有限的条件上,那么如果Η为无限类,又该如何估计呢?
先说一个粗略结论:其实根据有限字长效应,我们知道,每个数最多有64字节,例如如果有d个特征,则:
![]()
也就是说:
![]()
这个粗略结论已经比较实用了,不是吗。
其实,在现实情况中,不一定满足独立同分布的条件,因此真正的结果会比此结果乐观的多。具体的数字意义也不大,只需确定数量级即可。
不妨记住一个简答的结论:所需样本数量与VC维成正比

 浙公网安备 33010602011771号
浙公网安备 33010602011771号