Logistic回归 逻辑回归 练习——以2018建模校赛为数据源
把上次建模校赛一个根据三围将女性分为四类(苹果型、梨形、报纸型、沙漏)的问题用逻辑回归实现了,包括从excel读取数据等一系列操作。
Excel的格式如下:假设有r列,则前r-1列为数据,最后一列为类别,类别需要从1开始,1~k类,

如上表所示,前10列是身高、胸围、臀围等数据(以及胸围和腰围、胸围和臀围的比值),最后一列1表示属于苹果型。
import tensorflow as tf import os import numpy import xlrd XDATA = 0 YDATA = 0 one_hot_size = 0 M = 0 def readData(): global XDATA, YDATA, one_hot_size, M workbook = xlrd.open_workbook('divdata.xlsx') booksheet = workbook.sheet_by_index(0) col = booksheet.ncols row = booksheet.nrows M = row tempcol = [] for i in range(col - 1): tempcol = tempcol + booksheet.col_values(i) XDATA = numpy.array(tempcol).reshape(col - 1, row).T one_hot_size = int(max(booksheet.col_values(col - 1))) YDATA = numpy.zeros([row, one_hot_size]) for i in range(row): YDATA[i, int(booksheet.cell_value(i, col - 1) - 1)] = 1 def getData(batch_size): ran = numpy.random.randint(0, M - 1, [batch_size]) # print(ran) return XDATA[ran], YDATA[ran] readData() checkpoint_dir = 'modelsave/' learning_rate = 0.0005 save_step = 100 total_step = 1000 batch_size = 1000 config = tf.ConfigProto() config.gpu_options.allow_growth = True x = tf.placeholder(tf.float32, [None, 10], name='x') y_data = tf.placeholder(tf.float32, [None, 4], name='data') # y = tf.Variable(tf.zeros(4,1), dtype=tf.float32,name='y') # w = tf.Variable(tf.zeros([10, 4], dtype=tf.float32)) w = tf.Variable(numpy.zeros([10, 4]),dtype=tf.float32) # b = tf.Variable(tf.zeros([1, 4], dtype=tf.float32)) b = tf.Variable(numpy.zeros([1,4]),dtype=tf.float32) y = tf.nn.softmax(tf.matmul(x, w) + b) loss = tf.reduce_mean(-tf.reduce_sum(y_data * tf.log(y), reduction_indices=1)) # 损失函数 optimizer = tf.train.GradientDescentOptimizer(learning_rate) # 选择梯度下降的方法 train_op = optimizer.minimize(loss) # 迭代的目标:最小化损失函数 sess = tf.InteractiveSession(config=config) # 设置按需使用GPU saver = tf.train.Saver() # 用来存储训练结果 if not os.path.exists(checkpoint_dir): os.mkdir(checkpoint_dir) ############################# # 读取并初始化: ckpt = tf.train.get_checkpoint_state(checkpoint_dir) if ckpt and ckpt.model_checkpoint_path: saver.restore(sess, ckpt.model_checkpoint_path) else: sess.run(tf.global_variables_initializer()) ############################## print(sess.run(b)) for i in range(total_step): batch = getData(batch_size) # print(batch[0]) # print(batch[1]) sess.run(train_op, feed_dict={x: batch[0], y_data: batch[1]}) if (i + 1) % save_step == 0: print(i + 1, sess.run(w), sess.run(b)) saver.save(sess, checkpoint_dir + 'model.ckpt', global_step=i + 1) # 储存 writer = tf.summary.FileWriter('./my_graph', sess.graph) # tensorboard使用 writer.close() sess.close() # 查看tensorboard的代码 在命令行输入: # tensorboard --logdir=C:\Users\Rear82\PycharmProjects\MM_School_2018\my_graph
训练完成之后,使用以下代码读取并测试模拟:
import tensorflow as tf import os import numpy checkpoint_dir = 'modelsave/' config = tf.ConfigProto() config.gpu_options.allow_growth = True x = tf.placeholder(tf.float32, [None, 10], name='x') w = tf.Variable(numpy.zeros([10, 4]),dtype=tf.float32) b = tf.Variable(numpy.zeros([1,4]),dtype=tf.float32) y = tf.nn.softmax(tf.matmul(x, w) + b) sess = tf.InteractiveSession(config=config) # 设置按需使用GPU saver = tf.train.Saver() # 用来存储训练结果 if not os.path.exists(checkpoint_dir): os.mkdir(checkpoint_dir) ############################# # 读取并初始化: ckpt = tf.train.get_checkpoint_state(checkpoint_dir) if ckpt and ckpt.model_checkpoint_path: saver.restore(sess, ckpt.model_checkpoint_path) else: print("Can't find trained nn.") ############################## jdata = [[167,86,72,71.5,76.5,90.5,119.4444444,120.2797203,112.4183007,95.02762431]] print(jdata) print(sess.run(y,feed_dict={x:jdata})) sess.close()
训练了3000次后:
w:
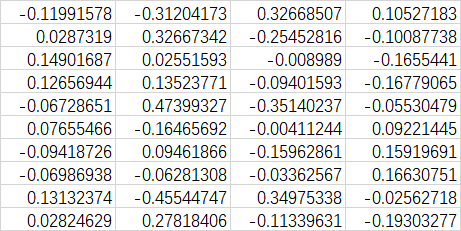
b:
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号