论文阅读:A neuralized feature engineering method for entity relation extraction
对应代码的github网址:https://github.com/WeizheYang-SHIN/Feature_Engineering_RE
神经化特征工程模型的架构
本文提出的识别实体关系的模型分为两个组件:特征工程组件和神经网络组件。
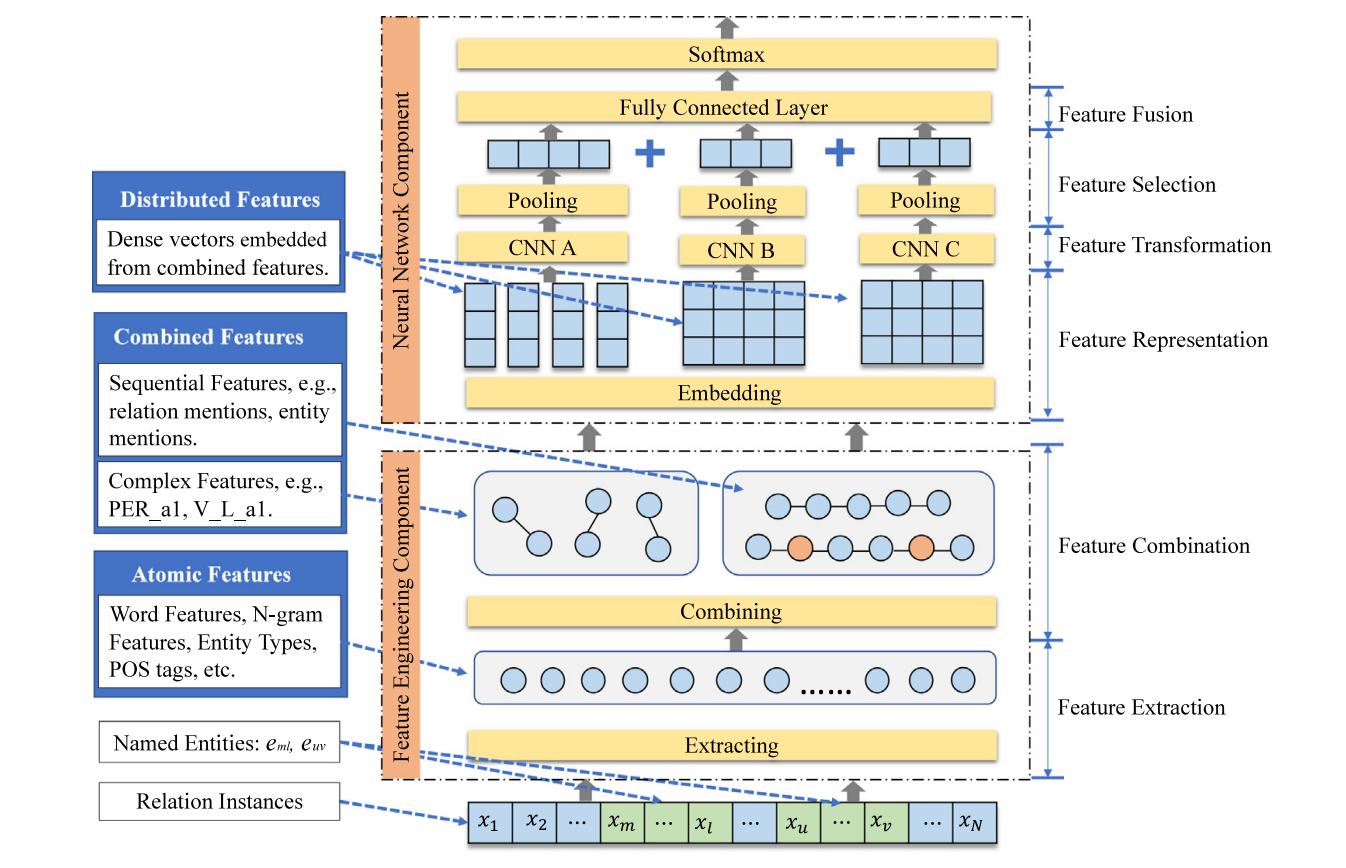
- 特征工程组件包含两个步骤:
特征提取和特征组合。
在特征提取过程中,从输入句子中提取分类特征,这些分类特征可以是
原子特征或组合特征。
- 神经网络组件有四个步骤:
特征表示、特征转换、特征选择和特征融合。
- 特征表示:组合的特征被编码为
分布式表示,并通过嵌入层输入到深度神经网络中。- 特征转换:
卷积层将局部特征转换为高阶抽象表示。三个具有不同架构的卷积网络被设计用于分别处理不同类型的特征。- 特征选择:通过
池化层实现,池化层从输入中收集显著特征。- 特征融合:使用
全连接层将池化层的输出连接成一个向量以进行特征融合。- 最后,
softmax 层输出所有关系类型之间的分布。
特征工程
在基于特征的模型中,特征组合具有使用先验知识和经验的优点。这种组合将任务的特征空间映射到更高维的空间,这可以导致更灵活的决策边界。
从技术角度来看,我们将组合特征分为两种类型:复杂特征和序列特征。
- 复杂特征是通过连接两个(或几个)原子特征来生成的。每个复杂特征都用作
单个token。在神经网络中,每个复杂的特征都被嵌入到一个向量中。 - 序列特征是序列数据,例如句子中的子句。每个序列特征都通过
神经网络映射到向量中。
原子特征
在提取方面,通常使用七种类型的原子特征集:实体类型、实体子类型、头部名词、左词和右词 POS 标签、实体结构和 n-gram 特征。
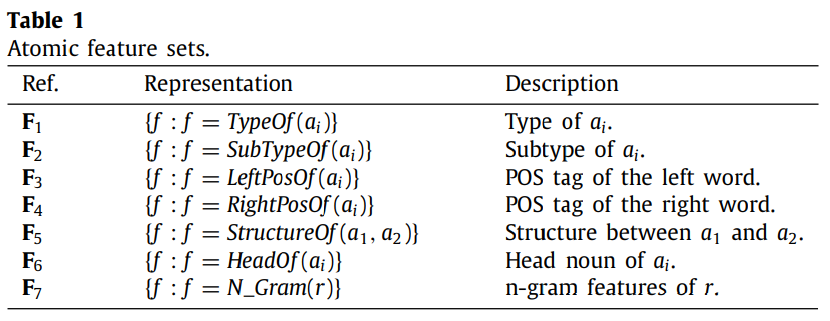
- 实体类型和子类型是关于命名实体的语义信息。
- 头部名词确定命名实体的类别,如“印度尼西亚法院”中的“法院”。
- 左词和右词 POS 标签是实体两侧相邻词的词性 (POS) 标签。
- 实体结构是实体对在句子中的相对位置。
- N-gram 特征是句子中连续的单词序列,并捕获相邻单词之间的语义依赖性。
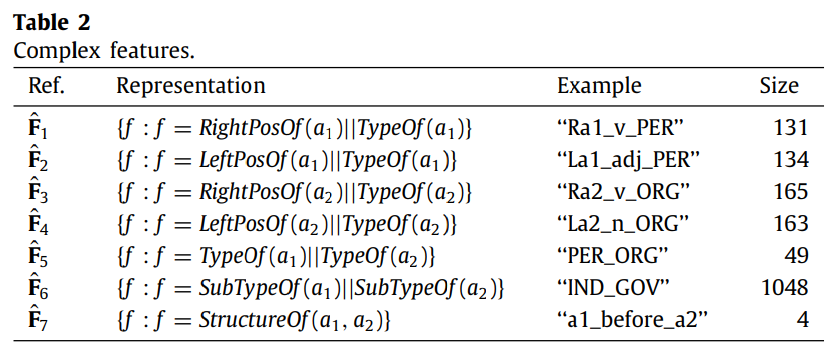
复杂特征
本文采用七种特征运算来生成复杂特征。
序列特征
另一种类型的组合特征是序列特征,它是通过连接句子的子字符串生成的。

由表1-3,定义了五个特征集:

神经网络组件
在深度神经网络中,输入的值表示信号的时态。因此,每个组合特征都表示为高维独热向量。
- 每个
复杂特征都直接嵌入到向量中。 - 相反,
序列特征中的词首先被映射到向量序列中,然后通过递归神经网络转化为向量。
基于组合特征的特征,设计了三种常规模型(''CNN_A''、''CNN_B''和''CNN_C'')分别处理Fcomplex、Fsequential和FML。

- 由于
复杂特征(Fcomplex) 彼此不依赖,因此设计了具有两个 1 × 1 核的卷积网络CNN_A。 - 为了处理实体头对和
n-gram 特征,通过关系提及 r 实现了两个 3 × 1 卷积核。神经网络与最大池化层堆叠在一起。它被称为“CNN_B”。 标有实体边界的关系提及由卷积神经网络处理,称为“CNN_C”,该网络由 1 × 1 核和 3 × 1 核组成。
因此,给定一个关系实例作为输入,其抽象表示按如下方式编码:
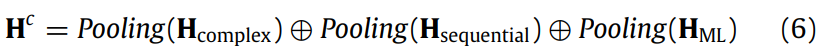
池化操作从输入中收集显著特征。在池化层之后,堆叠了一个全连接层,用于进行全局调节。最后,softmax 层输出所有关系类型之间的分布。
数据集
ACE corpus
Chen Y, Yang W, Wang K, et al. A neuralized feature engineering method for entity relation extraction[J]. Neural Networks, 2021, 141: 249-260.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号