HBase分布式集群部署与设计
HBase是一个高可靠、高性能、面向列、可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建 大规模结构化存储集群。
HBase 是Google Bigtable 的开源实现,与Google Bigtable 利用GFS作为其文件存储系统类似, HBase 利用Hadoop HDFS 作为其文件存储系统;Google 运行MapReduce 来处理Bigtable中的海量数据, HBase 同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable 利用Chubby作为协同服务, HBase 利用Zookeeper作为对应。
1.下载HBase并安装
1)下载Apache版本的HBase。
2)下载Cloudera版本的HBase。
3)这里选择下载cdh版本的hbase-0.98.6-cdh5.3.0.tar.gz,然后上传至bigdata-pro01.kfk.com节点/opt/softwares/目录下
4)解压hbase
tar -zxf hbase-0.98.6-cdh5.3.0.tar.gz -C /opt/modules/
2.分布式集群的相关配置
1)HBase架构体系
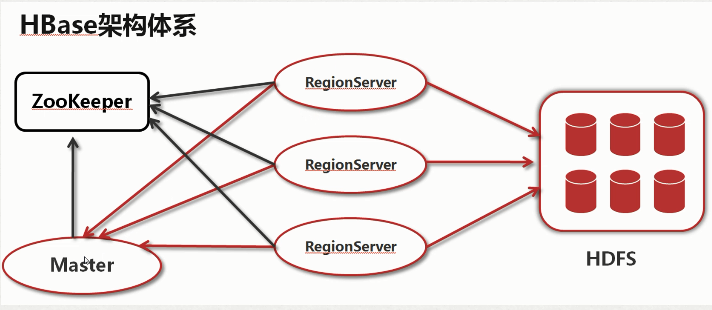
a.Zookeeper
Zookeeper Quorum中除了存储了-ROOT-表的地址和HMaster的地址,HRegionServer也会把自己以Ephemeral方式注册到Zookeeper中,使得HMaster可以随时感知到各个HRegionServer的健康状态。此外,Zookeeper也避免了HMaster的单点问题。
b.HBase Master
每台HRegion服务器都会和HMaster服务器通信,HMaster的主要任务就是要告诉每台HRegion服务器它要维护哪些HRegion。 当一台新的HRegion服务器登录到HMaster服务器时,HMaster会告诉它先等待分配数据。而当一台HRegion死机时,HMaster会把它负责的HRegion标记为未分配,然后再把它们分配到其他HRegion服务器中。
c.HRegionServer
HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
2)HBase集群规划

3)分布式集群相关配置
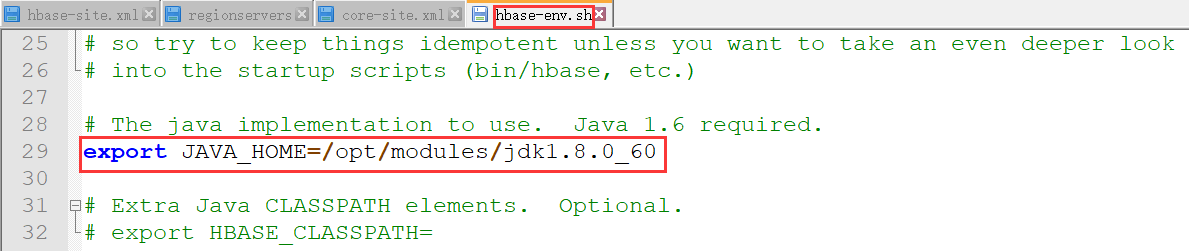
a.hbase-env.sh
#配置jdk export JAVA_HOME=/opt/modules/jdk1.8.0_60 #使用独立的Zookeeper export HBASE_MANAGES_ZK=false

b.hbase-site.xml
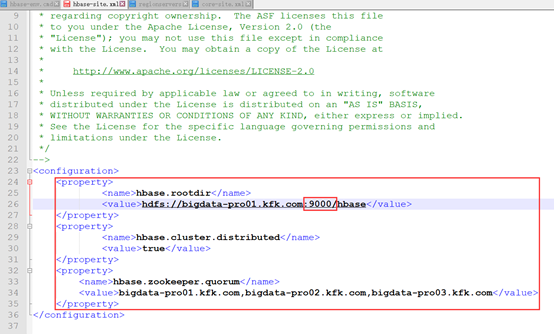
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs:// bigdata-pro01.kfk.com:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>bigdata-pro01.kfk.com,bigdata-pro02.kfk.com,
bigdata-pro03.kfk.com</value>
</property>
</configuration>
注意:以上端口号请与当初配置hdfs集群时的端口号保持一致,如下所示。

c.regionservers
bigdata-pro01.kfk.com bigdata-pro02.kfk.com bigdata-pro03.kfk.com
4)将hbase配置分发到各个节点
scp -r hbase-0.98.6-cdh5.3.0 bigdata-pro02.kfk.com:/opt/modules/ scp -r hbase-0.98.6-cdh5.3.0 bigdata-pro03.kfk.com:/opt/modules/
然后,考虑到大家的计算机配置问题,我们这里先不采用HA集群,而是仅仅使用最开始配置的hdfs集群,下面我们来还原一下hdfs集群环境(对三个节点进行以下操作)。
[kfk@bigdata-pro01 hbase-0.98.6-cdh5.3.0]$ cd /opt/modules/hadoop-2.6.0/etc/ [kfk@bigdata-pro01 etc]$ ls dist-hadoop hadoop [kfk@bigdata-pro01 etc]$ mv hadoop/ hadoop-ha [kfk@bigdata-pro01 etc]$ ls dist-hadoop hadoop-ha [kfk@bigdata-pro01 etc]$ mv dist-hadoop/ hadoop [kfk@bigdata-pro01 etc]$ ls hadoop hadoop-ha [kfk@bigdata-pro01 etc]$ cd ../data/ [kfk@bigdata-pro01 data]$ ls dist-tmp jn tmp [kfk@bigdata-pro01 data]$ mv tmp tmp-ha [kfk@bigdata-pro01 data]$ ls dist-tmp jn tmp-ha [kfk@bigdata-pro01 data]$ mv dist-tmp/ tmp [kfk@bigdata-pro01 data]$ ls jn tmp tmp-ha
3.启动HBase服务
1)各个节点启动Zookeeper
zkServer.sh start
2)主节点启动HDFS
[kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/start-dfs.sh 18/10/23 09:58:30 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [bigdata-pro01.kfk.com] bigdata-pro01.kfk.com: starting namenode, logging to /opt/modules/hadoop-2.6.0/logs/hadoop-kfk-namenode-bigdata-pro01.kfk.com.out bigdata-pro01.kfk.com: starting datanode, logging to /opt/modules/hadoop-2.6.0/logs/hadoop-kfk-datanode-bigdata-pro01.kfk.com.out bigdata-pro03.kfk.com: starting datanode, logging to /opt/modules/hadoop-2.6.0/logs/hadoop-kfk-datanode-bigdata-pro03.kfk.com.out bigdata-pro02.kfk.com: starting datanode, logging to /opt/modules/hadoop-2.6.0/logs/hadoop-kfk-datanode-bigdata-pro02.kfk.com.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /opt/modules/hadoop-2.6.0/logs/hadoop-kfk-secondarynamenode-bigdata-pro01.kfk.com.out 18/10/23 09:58:50 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
3)启动HBase
bin/start-hbase.sh(一步到位)
我们也可以体验一下分布启动:
starting master, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-master-bigdata-pro01.kfk.com.out [kfk@bigdata-pro01 bin]$ jps 2180 NameNode 2284 DataNode 3325 Jps 2589 QuorumPeerMain 3263 HMaster [kfk@bigdata-pro01 bin]$ ./hbase-daemon.sh start regionserver starting regionserver, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-regionserver-bigdata-pro01.kfk.com.out [kfk@bigdata-pro01 bin]$ jps 2180 NameNode 3398 HRegionServer 3450 Jps 2284 DataNode 2589 QuorumPeerMain 3263 HMaster
然后再启动另外两个节点的regionserver
[kfk@bigdata-pro02 hbase-0.98.6-cdh5.3.0]$ bin/hbase-daemon.sh start regionserver starting regionserver, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-regionserver-bigdata-pro02.kfk.com.out [kfk@bigdata-pro02 hbase-0.98.6-cdh5.3.0]$ jps 2162 QuorumPeerMain 2403 Jps 2355 HRegionServer 2070 DataNode [kfk@bigdata-pro03 hbase-0.98.6-cdh5.3.0]$ bin/hbase-daemon.sh start regionserver starting regionserver, logging to /opt/modules/hbase-0.98.6-cdh5.3.0/bin/../logs/hbase-kfk-regionserver-bigdata-pro03.kfk.com.out [kfk@bigdata-pro03 hbase-0.98.6-cdh5.3.0]$ jps 2644 Jps 2598 HRegionServer 2170 QuorumPeerMain 2078 DataNode
4)查看HBase Web界面
bigdata-pro01.kfk.com:60010/
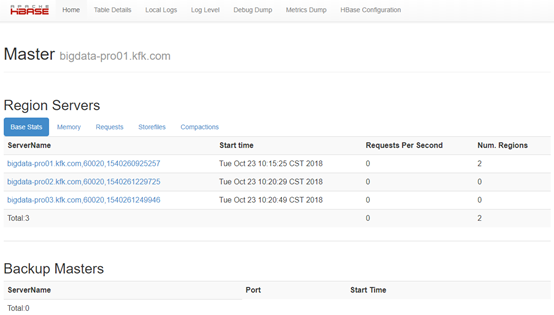
如果各个节点启动正常,那么HBase就搭建完毕。
4.通过shell测试数据库
1)选择主节点进入HBase目录,启动hbase-shell
[kfk@bigdata-pro01 hbase-0.98.6-cdh5.3.0]$ bin/hbase shell 2018-10-23 10:27:01,120 INFO [main] Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 0.98.6-cdh5.3.0, rUnknown, Tue Dec 16 19:18:44 PST 2014 hbase(main):001:0>
注意:hbase shell模式下的删除操作有点恶心,直接用删除键不起作用,应该用‘Ctrl+删除’组合键(但我的电脑也不起作用,只能是按一下Ctrl之后放开,然后使用Del键才行,并且只能向后删除)。
2)查看所有表命令
hbase(main):005:0> list
TABLE
0 row(s) in 0.0160 seconds
=> []
3)使用help查看所有命令及使用帮助
hbase(main):003:0> help HBase Shell, version 0.98.6-cdh5.3.0, rUnknown, Tue Dec 16 19:18:44 PST 2014 Type 'help "COMMAND"', (e.g. 'help "get"' -- the quotes are necessary) for help on a specific command. Commands are grouped. Type 'help "COMMAND_GROUP"', (e.g. 'help "general"') for help on a command group. COMMAND GROUPS: Group name: general Commands: status, table_help, version, whoami Group name: ddl Commands: alter, alter_async, alter_status, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, show_filters Group name: namespace Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables Group name: dml Commands: append, count, delete, deleteall, get, get_counter, incr, put, scan, truncate, truncate_preserve Group name: tools Commands: assign, balance_switch, balancer, catalogjanitor_enabled, catalogjanitor_run, catalogjanitor_switch, close_region, compact, flush, hlog_roll, major_compact, merge_region, move, split, trace, unassign, zk_dump Group name: replication Commands: add_peer, disable_peer, enable_peer, list_peers, list_replicated_tables, remove_peer, set_peer_tableCFs, show_peer_tableCFs Group name: snapshots Commands: clone_snapshot, delete_snapshot, list_snapshots, rename_snapshot, restore_snapshot, snapshot Group name: quotas Commands: list_quotas, set_quota Group name: security Commands: grant, revoke, user_permission Group name: visibility labels Commands: add_labels, clear_auths, get_auths, set_auths, set_visibility SHELL USAGE: Quote all names in HBase Shell such as table and column names. Commas delimit command parameters. Type <RETURN> after entering a command to run it. Dictionaries of configuration used in the creation and alteration of tables are Ruby Hashes. They look like this: {'key1' => 'value1', 'key2' => 'value2', ...} and are opened and closed with curley-braces. Key/values are delimited by the '=>' character combination. Usually keys are predefined constants such as NAME, VERSIONS, COMPRESSION, etc. Constants do not need to be quoted. Type 'Object.constants' to see a (messy) list of all constants in the environment. If you are using binary keys or values and need to enter them in the shell, use double-quote'd hexadecimal representation. For example: hbase> get 't1', "key\x03\x3f\xcd" hbase> get 't1', "key\003\023\011" hbase> put 't1', "test\xef\xff", 'f1:', "\x01\x33\x40" The HBase shell is the (J)Ruby IRB with the above HBase-specific commands added. For more on the HBase Shell, see http://hbase.apache.org/docs/current/book.html
4)创建表
hbase(main):004:0> create 'test','info' 0 row(s) in 0.4040 seconds => Hbase::Table – test hbase(main):005:0> list TABLE test 1 row(s) in 0.0160 seconds => ["test"]
Hbase创建表有两个属性:表名(test)和列簇名(info)。
5)添加数据
hbase(main):006:0> put 'test','0001','info:userName','zimo' 0 row(s) in 0.1750 seconds hbase(main):008:0> put 'test','0001','info:age','24' 0 row(s) in 0.0150 seconds
6)全表扫描数据
hbase(main):009:0> scan 'test' ROW COLUMN+CELL 0001 column=info:age, timestamp=1540262335985, value=24 0001 column=info:userName, timestamp=1540262255713, value=zimo 1 row(s) in 0.0220 seconds hbase(main):010:0> put 'test','0002','info:userName','ant' 0 row(s) in 0.0170 seconds hbase(main):011:0> put 'test','0002','info:age','5' 0 row(s) in 0.0120 seconds hbase(main):012:0> scan 'test' ROW COLUMN+CELL 0001 column=info:age, timestamp=1540262335985, value=24 0001 column=info:userName, timestamp=1540262255713, value=zimo 0002 column=info:age, timestamp=1540262771192, value=5 0002 column=info:userName, timestamp=1540262757635, value=ant 2 row(s) in 0.0340 seconds
7)查看表结构
hbase(main):013:0> describe 'test' DESCRIPTION ENABLED 'test', {NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_C true ELLS => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMPRESSION => 'NONE', MIN_VERSION S => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'} 1 row(s) in 0.0630 seconds
8)删除表
hbase(main):014:0> disable 'test' 0 row(s) in 1.3600 seconds hbase(main):015:0> drop 'test' 0 row(s) in 0.2220 seconds hbase(main):016:0> list TABLE 0 row(s) in 0.0100 seconds => []
5.根据业务需求创建表结构
在这里,我们将会接触到真实的数据,并根据数据的结构来创建表,为我们后面使用Flume进行数据采集和抽取的时候就可以实时地把数据写到我们下面创建的表中个去。大家有必要知道,其实hbase最终存储的位置是我们的hdfs。
1)下载数据源文件

我们下载个精简版进行测试即可,不过在项目完成时大家可以用完整版进行收官。

2)HBase上创建表
hbase(main):017:0> create 'weblogs','info' 0 row(s) in 0.4350 seconds => Hbase::Table - weblogs hbase(main):018:0> list TABLE weblogs 1 row(s) in 0.0110 seconds => ["weblogs"]
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!同时也欢迎转载,但必须在博文明显位置标注原文地址,解释权归博主所有!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号