
Hadoop2.X HA架构与部署
HDFS-HA原理及配置
1.HDFS-HA架构原理介绍
hadoop2.x之后,Clouera提出了QJM/Qurom Journal Manager,这是一个基于Paxos算法实现的HDFS HA方案,它给出了一种较好的解决思路和方案,示意图如下:
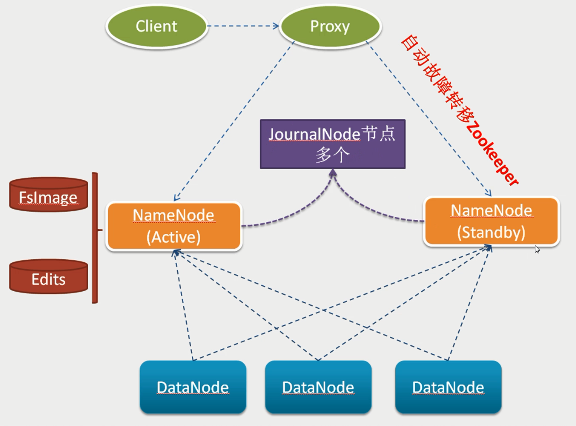
- 基本原理就是用2N+1台 JN 存储EditLog,每次写数据操作有大多数(>=N+1)返回成功时即认为该次写成功,数据不会丢失了。当然这个算法所能容忍的是最多有N台机器挂掉,如果多于N台挂掉,这个算法就失效了。这个原理是基于Paxos算法
- 在HA架构里面SecondaryNameNode这个冷备角色已经不存在了,为了保持standby NN时时的与主Active NN的元数据保持一致,他们之间交互通过一系列守护的轻量级进程JournalNode
- 任何修改操作在 Active NN上执行时,JN进程同时也会记录修改log到至少半数以上的JN中,这时 Standby NN 监测到JN 里面的同步log发生变化了会读取 JN 里面的修改log,然后同步到自己的的目录镜像树里面,如下图:
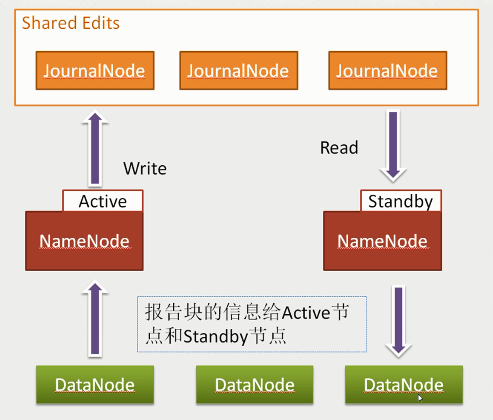
当发生故障时,Active的 NN 挂掉后,Standby NN 会在它成为Active NN 前,读取所有的JN里面的修改日志,这样就能高可靠的保证与挂掉的NN的目录镜像树一致,然后无缝的接替它的职责,维护来自客户端请求,从而达到一个高可用的目的。
2.HDFS-HA 详细配置
1)环境准备
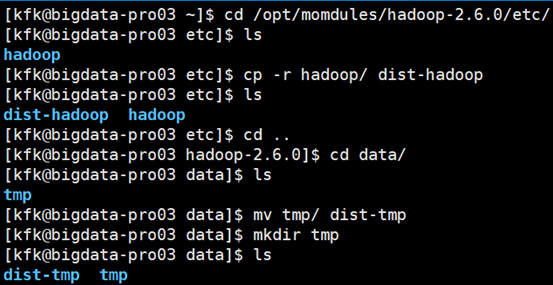
根据以上介绍,要完成HA的配置则必须要添加一个NameNode(2号节点)和三个JournalNode。为了和我们之前配置的非HA避免冲突,我们选择对原来的环境进行备份,然后在备份的基础上重新配置HA环境,即两个环境隔离开互不影响。
[kfk@bigdata-pro01 etc]$ ls hadoop [kfk@bigdata-pro01 etc]$ cp -r hadoop/ dist-hadoop [kfk@bigdata-pro01 etc]$ ls dist-hadoop hadoop [kfk@bigdata-pro01 etc]$ cd .. [kfk@bigdata-pro01 hadoop-2.6.0]$ ls bin data etc include lib libexec LICENSE.txt logs NOTICE.txt README.txt sbin share [kfk@bigdata-pro01 hadoop-2.6.0]$ cd data/ [kfk@bigdata-pro01 data]$ ls tmp [kfk@bigdata-pro01 data]$ mv tmp/ dist-tmp [kfk@bigdata-pro01 data]$ mkdir tmp [kfk@bigdata-pro01 data]$ ls dist-tmp tmp
2)修改hdfs-site.xml配置文件
vi hdfs-site.xml <configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> <property> <name>dfs.nameservices</name> <value>ns</value> </property> <property> <name>dfs.ha.namenodes.ns</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.ns.nn1</name> <value>bigdata-pro01.kfk.com:8020</value> </property> <property> <name>dfs.namenode.rpc-address.ns.nn2</name> <value>bigdata-pro02.kfk.com:8020</value> </property> <property> <name>dfs.namenode.http-address.ns.nn1</name> <value>bigdata-pro01.kfk.com:50070</value> </property> <property> <name>dfs.namenode.http-address.ns.nn2</name> <value>bigdata-pro02.kfk.com:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://bigdata-pro01.kfk.com:8485;bigdata-pro02.kfk.com:8485;bigdata-pro03.kfk.com:8485/ns</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/modules/hadoop-2.6.0/data/jn</value> </property> <property> <name>dfs.client.failover.proxy.provider.ns</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.automatic-failover.enabled.ns</name> <value>true</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>bigdata-pro01.kfk.com:2181,bigdata-pro02.kfk.com:2181,bigdata-pro03.kfk.com:2181</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/kfk/.ssh/id_rsa</value> </property> </configuration>
然后创建JournalNode日志目录:
[kfk@bigdata-pro01 data]$ mkdir jn [kfk@bigdata-pro01 data]$ ls dist-tmp jn tmp [kfk@bigdata-pro01 data]$ cd jn [kfk@bigdata-pro01 jn]$ pwd /opt/momdules/hadoop-2.6.0/data/jn
3)修改core-site.xml配置文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>kfk</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.6.0/data/tmp</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
</configuration>
4)将修改的配置分发到其他节点
先同样对非HA环境进行备份:

然后再将HA环境分发给其他节点:
scp -r hadoop/ bigdata-pro02.kfk.com:/opt/modules/hadoop-2.6.0/etc scp -r hadoop/ bigdata-pro03.kfk.com:/opt/modules/hadoop-2.6.0/etc
3.HDFS-HA 服务启动及自动故障转移测试
1)启动所有节点上面的Zookeeper进程
zkServer.sh start(本次在前面的过程中已经启动了,以后注意启动顺序)
2)启动所有节点上面的journalnode进程
sbin/hadoop-daemon.sh start journalnode
3)在[nn1]上,对namenode进行格式化,并启动
#namenode 格式化 bin/hdfs namenode -format #格式化高可用并启动1和2节点的zkfc bin/hdfs zkfc -formatZK sbin/hadoop-daemon.sh start zkfc #启动节点一的namenode sbin/hadoop-daemon.sh start namenode
4)在[nn2]上,同步nn1元数据信息
bin/hdfs namenode -bootstrapStandby
然后启动节点二的namenode
sbin/hadoop-daemon.sh start namenode


5)启动所有节点的DataNode
sbin/hadoop-daemon.sh start datanode
然后通过命令上传文件至hdfs,检查hdfs是否可用。
[kfk@bigdata-pro01 hadoop-2.6.0]$ bin/hdfs dfs -mkdir -p /user/kfk/data [kfk@bigdata-pro01 hadoop-2.6.0]$ bin/hdfs dfs -put /opt/momdules/hadoop-2.6.0/etc/hadoop/core-site.xml /user/kfk/data

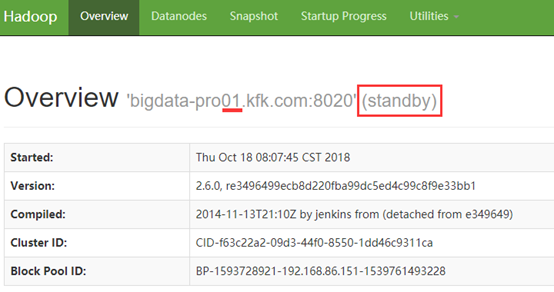
hdfs启动之后,kill其中active状态的namenode,观察另外一个NameNode是否会自动切换为active状态。然后在节点1(停掉的NameNode)上查看我们刚才上传的文件,如果成功表示HA配置是成功的!
[kfk@bigdata-pro01 hadoop-2.6.0]$ sbin/hadoop-daemon.sh stop namenode stopping namenode [kfk@bigdata-pro01 hadoop-2.6.0]$ bin/hdfs dfs -text /user/kfk/data/core-site.xml

成功读取!并且两个节点的状态也发生了改变。

YARN-HA原理及配置
1.YARN-HA架构原理及介绍
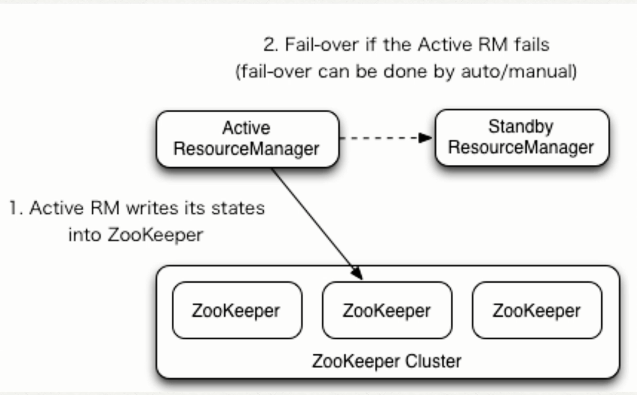
ResourceManager HA 由一对Active,Standby结点构成,通过RMStateStore存储内部数据和主要应用的数据及标记。目前支持的可替代的RMStateStore实现有:基于内存的MemoryRMStateStore,基于文件系统的FileSystemRMStateStore,及基于zookeeper的ZKRMStateStore。 ResourceManager HA的架构模式同NameNode HA的架构模式基本一致,数据共享由RMStateStore,而ZKFC成为 ResourceManager进程的一个服务,非独立存在。
2.YARN-HA详细配置
修改yarn-site.xml配置文件
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rs</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>bigdata-pro01.kfk.com</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>bigdata-pro02.kfk.com</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>bigdata-pro01.kfk.com:2181,bigdata-pro02.kfk.com:2181,bigdata-pro03.kfk.com:2181</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>10000</value>
</property>
</configuration>
3)将修改的配置分发到其他节点
scp yarn-site.xml bigdata-pro02.kfk.com:/opt/modules/hadoop-2.6.0/etc/hadoop/ scp yarn-site.xml bigdata-pro03.kfk.com:/opt/modules/hadoop-2.6.0/etc/hadoop/
3.YARN-HA服务启动及自动故障转移测试
1)在rm1节点上启动yarn服务
sbin/start-yarn.sh
2)在rm2节点上启动ResourceManager服务
sbin/yarn-daemon.sh start resourcemanager
3)查看yarn的web界面
http://bigdata-pro01.kfk.com:8088
http://bigdata-pro02.kfk.com:8088

4)查看ResourceManager主备节点状态
#bigdata-pro01.kfk.com节点上执行
bin/yarn rmadmin -getServiceState rm1

#bigdata-pro02.kfk.com节点上执行
bin/yarn rmadmin -getServiceState rm2

5)hadoop集群测试WordCount运行
[kfk@bigdata-pro01 hadoop-2.6.0]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /user/kfk/data/wc.input /user/kfk/data/output 18/10/22 16:56:47 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 18/10/22 16:56:50 INFO input.FileInputFormat: Total input paths to process : 1 18/10/22 16:56:50 INFO mapreduce.JobSubmitter: number of splits:1 18/10/22 16:56:51 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1540197665543_0001 18/10/22 16:56:52 INFO impl.YarnClientImpl: Submitted application application_1540197665543_0001 18/10/22 16:56:52 INFO mapreduce.Job: The url to track the job: http://bigdata-pro01.kfk.com:8088/proxy/application_1540197665543_0001/ 18/10/22 16:56:52 INFO mapreduce.Job: Running job: job_1540197665543_0001 18/10/22 16:57:04 INFO mapreduce.Job: Job job_1540197665543_0001 running in uber mode : false 18/10/22 16:57:04 INFO mapreduce.Job: map 0% reduce 0% 18/10/22 16:57:18 INFO mapreduce.Job: map 100% reduce 0% 18/10/22 16:57:29 INFO mapreduce.Job: map 100% reduce 100% 18/10/22 16:57:30 INFO mapreduce.Job: Job job_1540197665543_0001 completed successfully 18/10/22 16:57:31 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=65 FILE: Number of bytes written=216777 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=131 HDFS: Number of bytes written=39 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=11009 Total time spent by all reduces in occupied slots (ms)=9027 Total time spent by all map tasks (ms)=11009 Total time spent by all reduce tasks (ms)=9027 Total vcore-seconds taken by all map tasks=11009 Total vcore-seconds taken by all reduce tasks=9027 Total megabyte-seconds taken by all map tasks=11273216 Total megabyte-seconds taken by all reduce tasks=9243648 Map-Reduce Framework Map input records=3 Map output records=6 Map output bytes=58 Map output materialized bytes=65 Input split bytes=97 Combine input records=6 Combine output records=5 Reduce input groups=5 Reduce shuffle bytes=65 Reduce input records=5 Reduce output records=5 Spilled Records=10 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=193 CPU time spent (ms)=2800 Physical memory (bytes) snapshot=292130816 Virtual memory (bytes) snapshot=4124540928 Total committed heap usage (bytes)=165810176 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=34 File Output Format Counters Bytes Written=39 [kfk@bigdata-pro01 hadoop-2.6.0]$ bin/hdfs dfs -text /user/kfk/data/output/par* 18/10/22 16:59:37 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable hadoop 1 hbase 1 hive 2 java 1 spark 1
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!同时也欢迎转载,但必须在博文明显位置标注原文地址,解释权归博主所有!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号