Hadoop文件压缩
1. Hadoop的文件压缩需求
文件压缩对于大容量的分布式存储系统而言是必须的,它能带来两个好处:
1)减少了文件所需的存储空间;
2)加快了文件在网络上或磁盘间的传输速度。
2. Hadoop支持的压缩格式
首先看一下 Hadoop 常见压缩格式,如DEFLATE、Gzip、bzip2、LZO、LZ4、Snappy等。
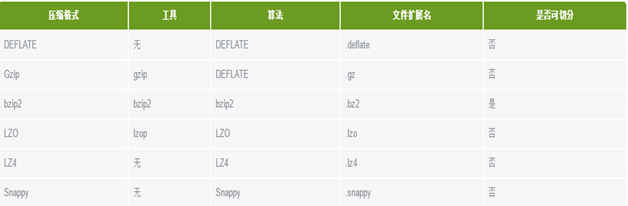
1)gzip压缩
优点:压缩率比较高,而且压缩/解压速度也比较快;hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;有hadoop native库;大部分linux系统都自带gzip命令,使用方便。
缺点:不支持split。
应用场景:当每个文件压缩之后在130M以内的(1个块大小内),都可以考虑用gzip压缩格式。譬如说一天或者一个小时的日志压缩成一个gzip 文件,运行mapreduce程序的时候通过多个gzip文件达到并发。hive程序,streaming程序,和java写的mapreduce程序完全和文本处理一样,压缩之后原来的程序不需要做任何修改。
2)lzo压缩
优点:压缩/解压速度也比较快,合理的压缩率;支持split,是hadoop中最流行的压缩格式;支持hadoop native库;可以在linux系统下安装lzop命令,使用方便。
缺点:压缩率比gzip要低一些;hadoop本身不支持,需要安装;在应用中对lzo格式的文件需要做一些特殊处理(为了支持split需要建索引,还需要指定inputformat为lzo格式)。
应用场景:一个很大的文本文件,压缩之后还大于200M以上的可以考虑,而且单个文件越大,lzo优点越越明显。
3)snappy压缩
优点:高速压缩速度和合理的压缩率;支持hadoop native库。
缺点:不支持split;压缩率比gzip要低;hadoop本身不支持,需要安装;linux系统下没有对应的命令。
应用场景:当mapreduce作业的map输出的数据比较大的时候,作为map到reduce的中间数据的压缩格式;或者作为一个mapreduce作业的输出和另外一个mapreduce作业的输入。
4)bzip2压缩
优点:支持split;具有很高的压缩率,比gzip压缩率都高;hadoop本身支持,但不支持native;在linux系统下自带bzip2命令,使用方便。
缺点:压缩/解压速度慢;不支持native。
应用场景:适合对速度要求不高,但需要较高的压缩率的时候,可以作为mapreduce作业的输出格式;或者输出之后的数据比较大,处理之后的数据需要压缩存档减少磁盘空间并且以后数据用得比较少的情况;或者对单个很大的文本文件想压缩减少存储空间,同时又需要支持split,而且兼容之前的应用程序(即应用程序不需要修改)的情况。
3. 如何选择压缩格式
Hadoop 应用处理的数据集非常大,因此需要借助于压缩。使用哪种压缩格式与待处理的文件的大小、格式和所使用的工具相关。 下面我们给出了一些建议,大致是按照效率从高到低排序的。
1)使用容器文件格式,例如顺序文件、RCFile或者 Avro 数据文件,所有这些文件格式同时支持压缩和切分。通常最好与一个快速压缩工具联合使用, 例如 LZO,LZ4,或者 Snappy。
2)使用支持切分的压缩格式,例如 bzip2(尽管 bzip2 非常慢),或者使用通过索引实现切分的压缩格式,例如 LZO。
3)在应用中将文件切分成块,并使用任意一种压缩格式为每个数据块建立压缩文件(不论它是否支持切分)。这种情况下,需要合理选择数据块的大小,以确保压缩后数据块的大小近似与 HDFS 块的大小。
4)存储未经压缩的文件。
对大文件来说,不要使用不支持切分整个文件的压缩格式,因为会失去数据的本地特性,进而造成 MapReduce 应用效率低下。
4. 如何在MapReduce中使用压缩
1)输入的文件的压缩
如果输入的文件是压缩过的,那么在被 MapReduce 读取时,它们会被自动解压,根据文件扩展名来决定应该使用哪一个压缩解码器。
2)MapReduce作业的输出的压缩
如果要压缩 MapReduce 作业的输出,应在作业配置过程中将 mapred.output.compress 属性设置为 true 和 mapred.output.compression.codec 属性设置为自己打算使用的压缩编码/解码器的类名。 另一种方案是在 FileOutputFormat 中使用更便捷的方法设置这些属性,如下所示。
FileOutputFormat.setCompressOutput(job, true);//对输出结果设置压缩
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);//设置压缩类型
如果为输出生成顺序文件(sequence file),可以设置 mapred.output.compression.type 属性来控制压缩格式。默认值是RECORD,即针对每条记录进行压缩。如果将其改为 BLOCK,则针对一组记录进行压缩,这是推荐的压缩策略,因为它的压缩效率更高。 在 SequenceFileOutputFormat 类中还有一个静态方法 putCompressionType() 可用来便捷地设置该属性。
下图归纳概述了用于设置 MapReduce 作业输出的压缩格式的配置属性。

如果你的 MapReduce 驱动使用 Tool 接口,则可以通过命令行将这些属性传递给程序,这比通过程序代码来修改压缩属性更加简便。 比如,要生成 gzip 文件格式的输出,只需设置streaming 作业中的选项,示例如下所示。
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/hadoop-streaming.jar \
-input /weather/ \
-output /weather/out/ \
-mapper com.dajiangtai.hadoop.middle.TemperatureMapper \
-reducer com.dajiangtai.hadoop.middle.TemperatureReducer \
-jobconf mapred.output.compress=true \
-jobconf mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCode
3)map作业输出结果的压缩
即使MapReduce应用使用非压缩的数据来读取和写入,我们也可以受益于压缩map阶段的中间输出。因为map作业的输出会被写入磁盘并通过网络传输到reducer节点,所以如果使用 LZO、LZ4或者Snappy之类的快速压缩方式,能得到更好的性能,因为传输的数据量大大减少了。启用 map 任务输出压缩和设置压缩格式的配置属性,如下表所示。
下面是在作业中启用 map 任务输出 gzip 压缩格式的代码(使用新 API)。

以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号