三节点Hadoop集群搭建
1. 基础环境搭建
新建3个CentOS6.5操作系统的虚拟机,命名(可自定)为masternode、slavenode1和slavenode2。该过程参考上一篇博文CentOS6.5安装配置详解
2.Hadoop集群搭建(以下操作中三个节点相同的地方就只给出主节点的截图,不同的才给出所有节点的截图)
2.1 系统时间同步
使用date命令查看当前系统时间

系统时间同步
[root@masternode ~]# cd /usr/share/zoneinfo/
[root@masternode zoneinfo]# ls //找到Asia
[root@masternode zoneinfo]# cd Asia/ //进入Asia目录
[root@masternode Asia]# ls //找到Shanghai
[root@masternode Asia]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime //当前时区替换为上海
我们可以同步当前系统时间和日期与NTP(网络时间协议)一致。
[root@masternode Asia]# yum install ntp //如果ntp命令不存在,在线安装ntp
[root@masternode Asia]# ntpdate pool.ntp.org //执行此命令同步日期时间
分别在masternode、slavenode1和slavenode2节点内新建hadoop用户组和用户,专用于Hadoop集群的操作和管理。命令如下:
[root@masternode ~]# groupadd hadoop
[root@masternode ~]# useradd -g hadoop hadoop
创建结果如下:
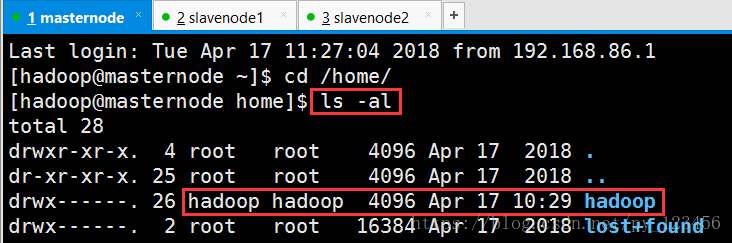
然后执行命令创建密码。注意:此过程你所输入的内容是不可见的,但其实已经输入了。还有,不可以删除。
[root@masternode hadoop]# passwd hadoop
2.2 目录规划
下面首先为这三台机器分配IP地址及相应的角色
192.168.86.135-----master,namenode,jobtracker
192.168.86.136-----slave1,datanode,tasktracker
192.168.86.137-----slave2,datanode,tasktracker
在所有节点的hosts文件中添加静态IP与hostname的映射配置信息。
[root@masternode ~]# vi /etc/hosts

然后依次对master、slave1、slave2进行目录规划。
名称 路径
所有集群安装的软件目录 /home/hadoop/app/
所有临时目录 /tmp
系统默认的临时目录是在/tmp下,而这个目录在每次重启后都会被删掉,必须重新执行format才行,否则会出错。
2.3 禁用防火墙
所有节点的防火墙都要关闭。查看防火墙状态:
[root@masternode ~]# service iptables status
iptables: Firewall is not running.
如果不是上面的关闭状态,则需要关闭防火墙。
[root@masternode ~]# chkconfig iptables off //永久关闭防火墙
[root@masternode ~]# service iptables stop //临时关闭防火墙

2.4 SSH免密通信配置
[hadoop@masternode ~]$ su root //切换到hadoop用户下
Password:
[root@masternode hadoop]# su hadoop //切换到hadoop用户目录
[hadoop@masternode ~]$ mkdir .ssh
mkdir: cannot create directory `.ssh': File exists //我的已经存在,不影响,继续下面的操作
[hadoop@masternode ~]$ ssh-keygen -t rsa //执行命令一路回车,生成秘钥
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
4b:a8:30:35:0e:cc:82:3f:1b:78:81:9c:e2:ee:ca:7d hadoop@masternode
The key's randomart image is:
+--[ RSA 2048]----+ //生成的密钥图像
| |
|o+. |
|=o= o |
|o+ = . . |
|..B . . S |
|.. * . . . |
| .. . . |
|o . E |
|oo .. |
+-----------------+
[hadoop@masternode ~]$ cd .ssh
[hadoop@masternode .ssh]$ ls
id_rsa id_rsa.pub
[hadoop@masternode .ssh]$ cat id_rsa.pub >> authorized_keys //将公钥保存到authorized_keys认证文件中
[hadoop@masternode .ssh]$ ls
authorized_keys id_rsa id_rsa.pub
[hadoop@masternode .ssh]$ cd ..
[hadoop@masternode ~]$ chmod 700 .ssh
[hadoop@masternode ~]$ chmod 600 .ssh/*
[hadoop@masternode ~]$ ssh masternode
The authenticity of host 'masternode (192.168.86.135)' can't be established.
RSA key fingerprint is 45:13:ab:81:3a:53:44:2b:59:8f:06:fb:56:2f:b6:d8.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'masternode,192.168.86.135' (RSA) to the list of known hosts.
Last login: Tue Apr 17 14:16:46 2018 from 192.168.86.1
[hadoop@masternode ~]$ ssh masternode
Last login: Tue Apr 17 15:45:44 2018 from masternode
集群所有节点都要行上面的操作,然后将所有节点中的共钥id_ras.pub拷贝到masternode中的authorized_keys文件中。
[hadoop@masternode ~]$ cat ~/.ssh/id_rsa.pub | ssh hadoop@masternode 'cat >> ~/.ssh/authorized_keys'
//所有节点都需要执行这条命令
再将masternode中的authorized_keys文件分发到所有节点上面。
[hadoop@masternode ~]$ cd .ssh
[hadoop@masternode .ssh]$ ls
authorized_keys id_rsa id_rsa.pub known_hosts
[hadoop@masternode .ssh]$ scp -r authorized_keys hadoop@slavenode1:~/.ssh/
hadoop@slavenode1's password:
authorized_keys 100% 1596 1.6KB/s 00:00
[hadoop@masternode .ssh]$ scp -r authorized_keys hadoop@slavenode2:~/.ssh/
hadoop@slavenode2's password:
authorized_keys 100% 1596 1.6KB/s 00:00
到此,集群的SSH免密通信就配置完成了。
2.5 脚本工具
在masternode节点上创建/home/hadoop/tools目录。
[hadoop@masternode ~]$ mkdir /home/hadoop/tools
[hadoop@masternode ~]$ cd /home/hadoop/tools
将本地脚本文件上传至/home/hadoop/tools目录下。这些脚本大家如果能看懂也可以自己写, 如果看不懂直接使用就可以,后面慢慢补补Linux相关的知识。
先创建脚本文件,然后分别填入下面内容:
[hadoop@masternode tools]$ touch deploy.conf
[hadoop@masternode ~]$ vi deploy.conf
masternode,all,namenode,zookeeper,resourcemanager,
slavenode1,all,slave,namenode,zookeeper,resourcemanager,
slavenode2,all,slave,datanode,zookeeper,
[hadoop@masternode tools]$ touch deploy.sh
[hadoop@masternode ~]$ vi deploy.sh
#!/bin/bash
#set -x
if [ $# -lt 3 ]
then
echo "Usage: ./deply.sh srcFile(or Dir) descFile(or Dir) MachineTag"
echo "Usage: ./deply.sh srcFile(or Dir) descFile(or Dir) MachineTag confFile"
exit
fi
src=$1
dest=$2
tag=$3
if [ 'a'$4'a' == 'aa' ]
then
confFile=/home/hadoop/tools/deploy.conf
else
confFile=$4
fi
if [ -f $confFile ]
then
if [ -f $src ]
then
for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
do
scp $src $server":"${dest}
done
elif [ -d $src ]
then
for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
do
scp -r $src $server":"${dest}
done
else
echo "Error: No source file exist"
fi
else
echo "Error: Please assign config file or run deploy.sh command with deploy.conf in same directory"
fi
[hadoop@masternode tools]$ touch runRemoteCmd.sh
[hadoop@masternode ~]$ vi runRemoteCmd.sh#!/bin/bash
#set -x
if [ $# -lt 2 ]
then
echo "Usage: ./runRemoteCmd.sh Command MachineTag"
echo "Usage: ./runRemoteCmd.sh Command MachineTag confFile"
exit
fi
cmd=$1
tag=$2
if [ 'a'$3'a' == 'aa' ]
then
confFile=/home/hadoop/tools/deploy.conf
else
confFile=$3
fi
if [ -f $confFile ]
then
for server in `cat $confFile|grep -v '^#'|grep ','$tag','|awk -F',' '{print $1}'`
do
echo "*******************$server***************************"
ssh $server "source /etc/profile; $cmd"
done
else
echo "Error: Please assign config file or run deploy.sh command with deploy.conf in same directory"
fi
如果我们想直接使用脚本,还需要给脚本添加执行权限。
[hadoop@masterndoe tools]$ chmod u+x deploy.sh
[hadoop@masterndoe tools]$ chmod u+x runRemoteCmd.sh
此时,我们需要将/home/hadoop/tools目录配置到PATH路径中,并使配置文件生效。
[hadoop@masterndoe tools]$ su root
Password:
[root@masterndoe tools]# vi /etc/profile
PATH=/home/hadoop/tools:$PATH
export PATH
[root@masternode app]# source /etc/profile
我们在masternode节点上,通过runRemoteCmd.sh脚本,一键创建所有节点的软件安装目录/home/hadoop/app。
[hadoop@masterndoe tools]$ runRemoteCmd.sh "mkdir /home/hadoop/app" all
我们可以在所有节点查看到/home/hadoop/app目录已经创建成功。
2.6 JDK安装与配置
将本地下载好的jdk1.7,上传至hadoop11节点下的/home/hadoop/app目录并解压。
[hadoop@masternode ~]$ cd /home/hadoop/app/
[hadoop@masternode app]$ rz
[hadoop@masternode app]$ ls
jdk-8u60-linux-x64.tar.gz
[hadoop@masternode app]$ tar zxvf jdk-8u60-linux-x64.tar.gz //解压
[hadoop@masternode app]$ ls
jdk1.8.0_60 jdk-8u60-linux-x64.tar.gz
[hadoop@masternode app]$ rm -f jdk-8u60-linux-x64.tar.gz //删除安装包
然后,添加JDK环境变量。
[hadoop@masternode app]$ su root
Password:
[root@masternode app]# vi /etc/profile
JAVA_HOME=/home/hadoop/app/jdk1.8.0_60
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:/home/hadoop/tools:$PATH //黑色字体为2.5中脚本工具的配置信息
export JAVA_HOME CLASSPATH PATH
[root@masternode app]# source /etc/profile
[root@masternode app]# java -version
java version "1.8.0_60"
Java(TM) SE Runtime Environment (build 1.8.0_60-b27)
Java HotSpot(TM) 64-Bit Server VM (build 25.60-b23, mixed mode)
slavenode1和slavenode2节点重复masternode节点上的jdk配置即可。
2.7 Zookeeper安装与配置
将本地下载好的zookeeper-3.4.6.tar.gz安装包,上传至masternode节点下的/home/hadoop/app目录下。
[root@masternode app]# su hadoop
[hadoop@masternode app]$ rz //选择本地下载好的zookeeper-3.4.6.tar.gz
[hadoop@masternode app]$ ls
jdk1.8.0_60 zookeeper-3.4.5-cdh5.10.0.tar.gz
[hadoop@masternode app]$ //重命名
[hadoop@masternode app]$ ls
jdk1.8.0_60 zookeeper
修改Zookeeper中的配置文件,一定注意将下面配置信息中的所有中文注释去掉,否则编码会出错导致无法启动zookeeper,以后也是,配置中尽量不要出现中午和字符(空格,tab等)!
[hadoop@masternode app]$ cd /home/hadoop/app/zookeeper/conf/
[hadoop@masternode conf]$ ls
configuration.xsl log4j.properties zoo_sample.cfg
[hadoop@masternode conf]$ cp zoo_sample.cfg zoo.cfg //复制生成zoo.cfg文件
[hadoop@masternode conf]$ vi zoo.cfg
dataDir=/home/hadoop/data/zookeeper/zkdata //数据文件目录
dataLogDir=/home/hadoop/data/zookeeper/zkdatalog //日志目录
# the port at which the clients will connect
clientPort=2181 //默认端口号
#server.服务编号=主机名称:Zookeeper不同节点之间同步和通信的端口:选举端口(选举leader)
server.1=masternode:2888:3888
server.2=slavenode1:2888:3888
server.3=slavenode2:2888:3888
通过远程命令远程拷贝命令scp将Zookeeper安装目录拷贝到其他节点上面。
[hadoop@masternode zookeeper]# scp -r zookeeper slavenode1:/home/hadoop/app
[hadoop@masternode zookeeper]# scp -r zookeeper slavenode2:/home/hadoop/app
通过远程命令runRemoteCmd.sh在所有的节点上面创建目录:
[hadoop@masternode app]$ runRemoteCmd.sh "mkdir -p /home/hadoop/data/zookeeper/zkdata" all
*******************masternode***************************
*******************slavenode1***************************
mkdir: cannot create directory `/home/hadoop/data/zookeeper': Permission denied
*******************slavenode2***************************
mkdir: cannot create directory `/home/hadoop/data/zookeeper': Permission denied
结果出现访问拒绝命令,这是由于用户组权限问题,应该是我们之前创建的data/目录是属于root用户组的,我们需要赋予权限给hadoop用户组。
[hadoop@masternode hadoop]$ chown -R hadoop:hadoop data
接下来就可以成功创建目录了:
[hadoop@masternode tools]$ runRemoteCmd.sh "mkdir -p /home/hadoop/data/zookeeper/zkdata" all
*******************masternode***************************
*******************slavenode1***************************
*******************slavenode2***************************
[hadoop@masternode tools]$ runRemoteCmd.sh "mkdir -p /home/hadoop/data/zookeeper/zkdatalog" all
*******************masternode***************************
*******************slavenode1***************************
*******************slavenode2***************************
然后分别在masternode、slavenode1和slavenode2上面,进入zkdata目录下,创建文件myid,里面的内容分别填充为:1、2、3, 这里我们以masternode为例。
[hadoop@masternode tools]$ cd /home/hadoop/data/zookeeper/zkdata
[hadoop@masternode zkdata]$ vi myid
1
配置Zookeeper环境变量。
[hadoop@masternode zkdata]$ su root
Password:
[root@masternode zookeeper]# vi /etc/profile
TOOL_HOME=/home/hadoop/tools
JAVA_HOME=/home/hadoop/app/jdk1.8.0_60
ZOOKEEPER_HOME=/home/hadoop/app/zookeeper
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$TOOLO_HOME:$PATH
export JAVA_HOME CLASSPATH PATH ZOOKEEPER_HOME
[root@masternode zookeeper]# source /etc/profile //使配置生效
在masternode节点上面启动所有节点的Zookeeper并查看状态。
[hadoop@masternode ~]$ cd /home/hadoop/tools/
[hadoop@masternode tools]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh start" zookeeper
*******************masternode***************************
JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
*******************slavenode1***************************
JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
*******************slavenode2***************************
JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@masternode tools]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh status" zookeeper
*******************masternode***************************
JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Mode: follower
*******************slavenode1***************************
JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Mode: leader //leader节点是通过zookeeper的leader选举算法决定的,和启动顺序有关,
//正常启动时第一个启动的就是leade;如果该节点挂掉则根据算法再选举另一个节点作为leader节点。
*******************slavenode2***************************
JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Mode: follower
2.8 Hadoop环境配置
将下载好的apache hadoop-2.6.0.tar.gz安装包,上传至masternode节点下的/home/hadoop/app目录下,然后解压。
[hadoop@masternode tools]$ cd /home/hadoop/app //将本地的hadoop-2.6.0.tar.gz安装包上传至当前目录
[hadoop@masternode app]$ rz
[hadoop@masternode app]$ tar zvxf hadoop-2.6.0.tar.gz //解压
[hadoop@masternode app]$ ls
hadoop-2.6.0 hadoop-2.6.0.tar.gz jdk1.8.0_60 zookeeper
[hadoop@masternode app]$ rm -f hadoop-2.6.0.tar.gz //删除安装包
[hadoop@masternode app]$ mv hadoop-2.6.0/ hadoop //重命名
[hadoop@masternode app]$ ls
hadoop jdk1.8.0_60 zookeeper
配置HDFS
切换到/home/hadoop/app/hadoop/etc/hadoop/目录下,修改配置文件。
[hadoop@masternode app]$ cd /home/hadoop/app/hadoop/etc/hadoop/
[hadoop@masternode hadoop]$ ls
capacity-scheduler.xml httpfs-env.sh mapred-env.sh
configuration.xsl httpfs-log4j.properties mapred-queues.xml.template
container-executor.cfg httpfs-signature.secret mapred-site.xml.template
core-site.xml httpfs-site.xml slaves
hadoop-env.cmd kms-acls.xml ssl-client.xml.example
hadoop-env.sh kms-env.sh ssl-server.xml.example
hadoop-metrics2.properties kms-log4j.properties yarn-env.cmd
hadoop-metrics.properties kms-site.xml yarn-env.sh
hadoop-policy.xml log4j.properties yarn-site.xml
hdfs-site.xml mapred-env.cmd
配置hadoop-env.sh文件
[hadoop@masternode hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_60
配置core-site.xml文件
[hadoop@masternode hadoop]$ vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
</property>
< 这里的值指的是默认的HDFS路径 ,取名为cluster1>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data/tmp</value>
</property>
< hadoop的临时目录,如果需要配置多个目录,需要逗号隔开,data目录需要我们自己创建>
<property>
<name>ha.zookeeper.quorum</name>
<value>masternode:2181,slavenode1:2181,slavenode2:2181</value>
</property>
< 配置Zookeeper 管理HDFS>
</configuration>
配置hdfs-site.xml文件
[hadoop@masternode hadoop]$ vi hdfs-site.xm
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
< 数据块副本数为3>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
< 权限默认配置为false>
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
</property>
< 命名空间,它的值与fs.defaultFS的值要对应,namenode高可用之后有两个namenode,cluster1是对外提供的统一入口>
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>masternode,slavenode1</value>
</property>
< 指定 nameService 是 cluster1 时的nameNode有哪些,这里的值也是逻辑名称,名字随便起,相互不重复即可>
<property>
<name>dfs.namenode.rpc-address.cluster1.masternode</name>
<value>masternode:9000</value>
</property>
< masternode rpc地址>
<property>
<name>dfs.namenode.http-address.cluster1.masternode</name>
<value>masternode:50070</value>
</property>
< masternode http地址>
<property>
<name>dfs.namenode.rpc-address.cluster1.slavenode1</name>
<value>slavenode1:9000</value>
</property>
< slavenode1 rpc地址>
<property>
<name>dfs.namenode.http-address.cluster1.slavenode1</name>
<value>slavenode1:50070</value>
</property>
< slavenode2 http地址>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
< 启动故障自动恢复>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://masternode:8485;slavenode1:8485;slavenode2:8485/cluster1</value>
</property>
< 指定journal>
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
< 指定 cluster1 出故障时,哪个实现类负责执行故障切换>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/data/journaldata/jn</value>
</property>
< 指定JournalNode集群在对nameNode的目录进行共享时,自己存储数据的磁盘路径 >
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>10000</value>
</property>
< 脑裂默认配置>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
</configuration>
配置slave文件
[hadoop@masternode hadoop]$ vi slaves
slavenode2
向所有节点分发hadoop安装包。
[hadoop@masternode app]# scp -r zookeeper slavenode1:/home/hadoop/app
[hadoop@masternode app]# scp -r zookeeper slavenode2:/home/hadoop/app
hdfs配置完毕后的启动顺序
1)启动所有节点上面的Zookeeper进程
[hadoop@masternode app]$ cd /home/hadoop/tools/
[hadoop@masternode tools]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh start" zookeeper
*******************masternode***************************
JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
*******************slavenode1***************************
JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
*******************slavenode2***************************
JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@masternode tools]$ runRemoteCmd.sh "/home/hadoop/app/zookeeper/bin/zkServer.sh status" zookeeper
*******************masternode***************************
JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Mode: follower
*******************slavenode1***************************
JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Mode: follower
*******************slavenode2***************************
JMX enabled by default
Using config: /home/hadoop/app/zookeeper/bin/../conf/zoo.cfg
Mode: leader
[hadoop@masternode hadoop]$ jps
6560 Jps
6459 QuorumPeerMain
其中,QuorumPeerMain对应zookeeper的进程。
2)启动所有节点上面的journalnode进程
[hadoop@masternode tools]$ runRemoteCmd.sh "/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh start journalnode" all
*******************masternode***************************
starting journalnode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-journalnode-masternode.out
*******************slavenode1***************************
starting journalnode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-journalnode-slavenode1.out
*******************slavenode2***************************
starting journalnode, logging to /home/hadoop/app/hadoop/logs/hadoop-hadoop-journalnode-slavanode2.out
[hadoop@masternode tools]$ jps
6672 Jps
6624 JournalNode
6459 QuorumPeerMain
或者在每个节点上使用以下命令分别启动
[hadoop@masterndoe hadoop]$ sbin/hadoop-daemon.sh start journalnode
3)首先在主节点上(比如,masterndoe)执行格式化并启动Namenode
[hadoop@masterndoe hadoop]$ bin/hdfs namenode -format //namenode 格式化
[hadoop@masterndoe hadoop]$ bin/hdfs zkfc -formatZK //格式化高可用
[hadoop@masterndoe hadoop]$ bin/hdfs namenode //启动namenode
4)与此同时,需要在备节点(比如,slavenode1)上执行数据同步
[hadoop@slavenode1 hadoop]$ bin/hdfs namenode -bootstrapStandby //同步主节点和备节点之间的元数据,
5)slavenode1同步完数据后,紧接着在masterndoe节点上,按下ctrl+c来结束namenode进程。 然后关闭所有节点上面的journalnode进程
[hadoop@masternode hadoop]$ runRemoteCmd.sh "/home/hadoop/app/hadoop/sbin/hadoop-daemon.sh stop journalnode" all
//然后停掉各节点的journalnode
[hadoop@masternode hadoop]$ jps
6842 Jps
6459 QuorumPeerMain
6)如果上面操作没有问题,我们可以一键启动hdfs所有相关进程
[hadoop@masternode hadoop]$ sbin/start-dfs.sh
[hadoop@masternode hadoop]$ jps
8640 DFSZKFailoverController
8709 Jps
6459 QuorumPeerMain
8283 NameNode
8476 JournalNode
[hadoop@slavenode1 hadoop]$ jps
5667 DFSZKFailoverController
5721 Jps
5562 JournalNode
4507 QuorumPeerMain
5487 NameNode
[hadoop@slavanode2 hadoop]$ jps
5119 Jps
5040 JournalNode
5355 DataNode
4485 QuorumPeerMain
以上masternode和slavenode1是作为NameNode的,而slavenode2则作为DataNode。
验证是否启动成功,通过web界面查看namenode启动情况。
http://masternode:50070
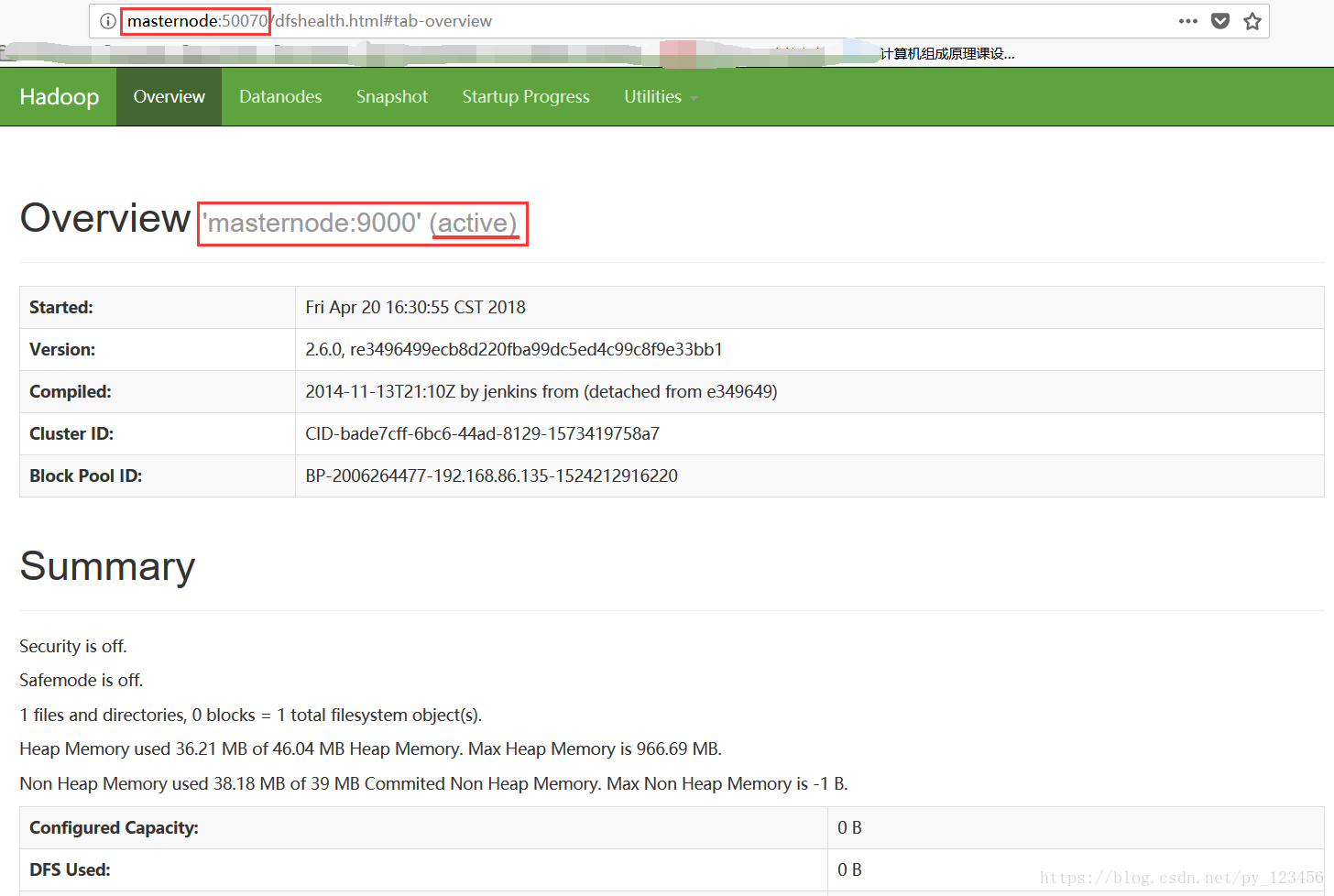
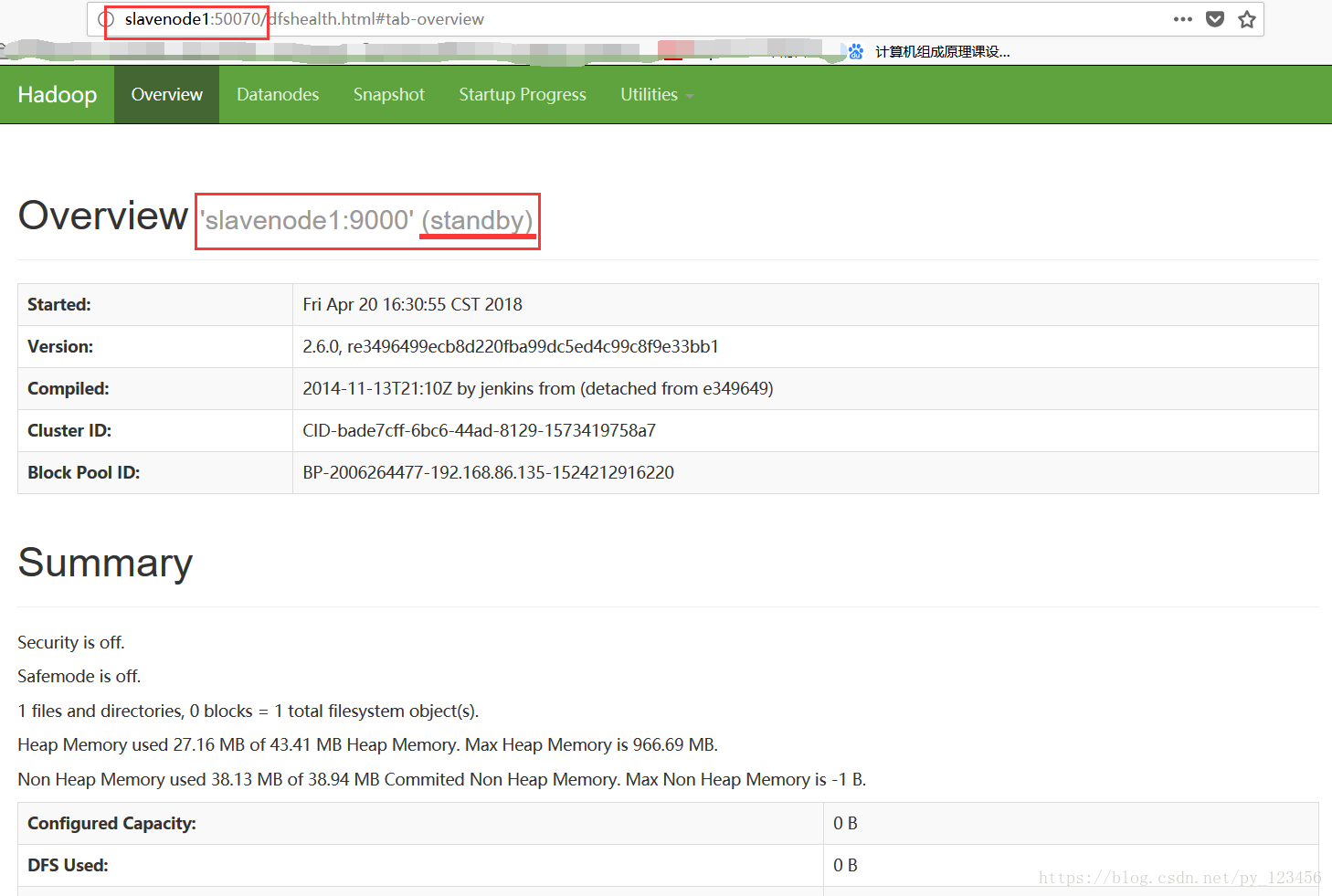
如图,masternode节点状态为active,而slavenode1节点状态为standby。
7)测试集群是否可以正常使用
使用以下命令在HDFS中新建一个文件夹,然后再网页上通过文件系统查看。
[hadoop@masternode hadoop]$ hdfs dfs -mkdir /test

还可以上传文件到文件夹内,这个可以自己下去测试一下。
在这里,我想说的是,哪个是active,哪个是standby是随机的 ,这是由选举决定的。
下面我们来试一下将slavenode1节点变为active。
首先kill掉masternode节点的Namenode,然后刷新网页看看有声明变化。
[hadoop@masternode hadoop]$ jps
8640 DFSZKFailoverController
8901 Jps
6459 QuorumPeerMain
8283 NameNode
8476 JournalNode
[hadoop@masternode hadoop]$ kill -9 8283
[hadoop@masternode hadoop]$ jps
8640 DFSZKFailoverController
8916 Jps
6459 QuorumPeerMain
8476 JournalNode
[hadoop@slavenode1 hadoop]$ jps
5986 Jps
5667 DFSZKFailoverController
5562 JournalNode
4507 QuorumPeerMain
5487 NameNode
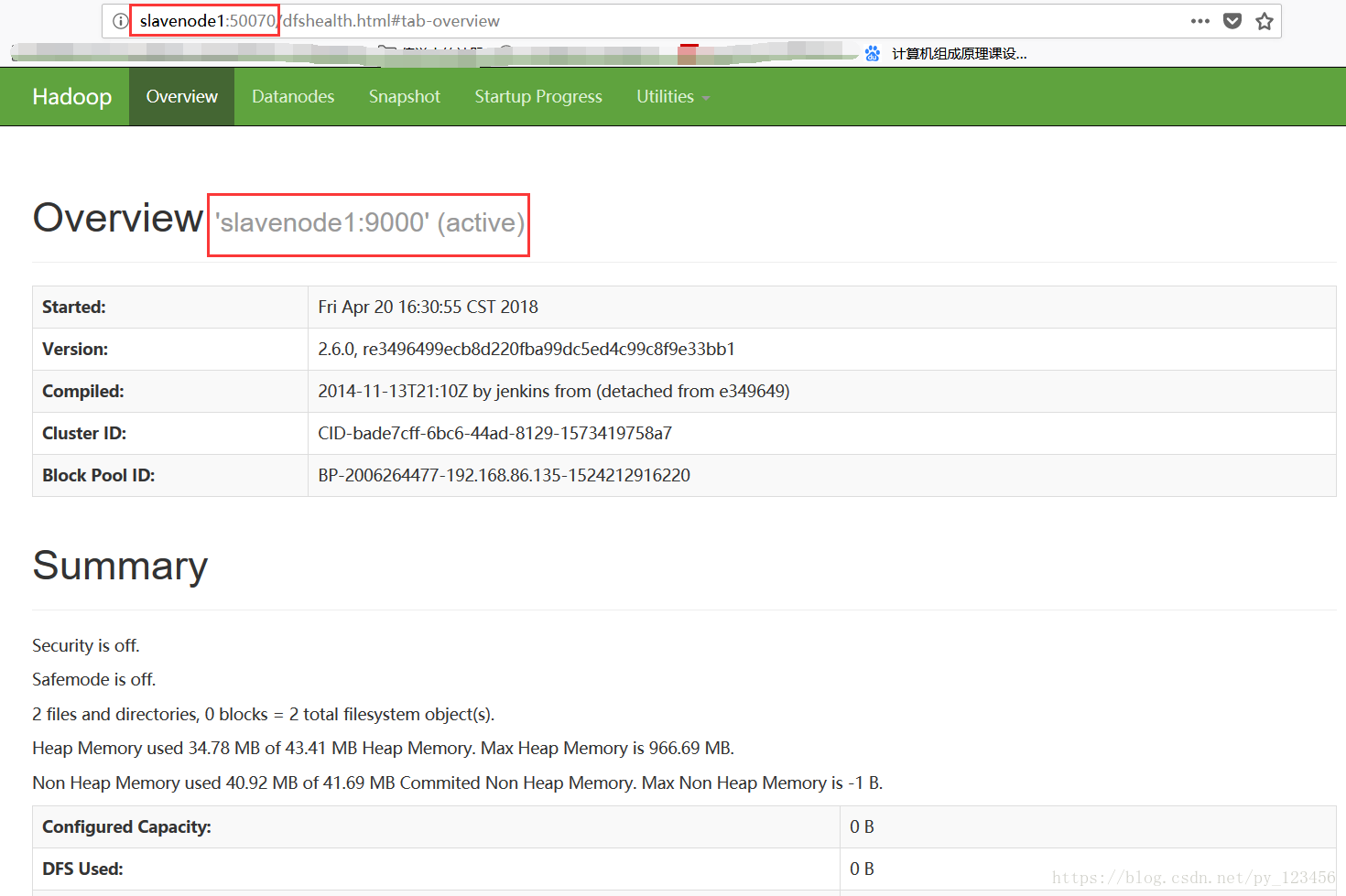
如图,slavenode1节点变为了active状态!刚才将masternode的Namenode kill掉了,所以根据选举算法,slavenode1节点被选举为Namenode节点,所以状态为active。
2.9 YARN安装配置
配置mapred-site.xml
[hadoop@masternode hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@masternode hadoop]$ vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<指定运行mapreduce的环境是Yarn,与hadoop1不同的地方>
</configuration>
配置yarn-site.xml
[hadoop@masternode hadoop]$ vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
< 超时的周期>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
< 打开高可用>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<启动故障自动恢复>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<failover使用内部的选举算法>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-rm-cluster</value>
</property>
<给yarn cluster 取个名字yarn-rm-cluster>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<给ResourceManager 取个名字 rm1,rm2>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>masternode</value>
</property>
<配置ResourceManagerrm1hostname>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slavenode1</value>
</property>
<配置ResourceManagerrm2hostname>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<启用resourcemanager 自动恢复>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>masternode:2181,slavenode1:2181,slavenode2:2181</value>
</property>
<配置Zookeeper地址>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>masternode:2181,slavenode1:2181,slavenode2:2181</value>
</property>
<配置Zookeeper地址>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>masternode:8032</value>
</property>
< rm1端口号>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>masternode:8034</value>
</property>
< rm1调度器的端口号>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>masternode:8088</value>
</property>
< rm1webapp端口号>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>slavenode1:8032</value>
</property>
< rm2端口号>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>slavenode1:8034</value>
</property>
< rm2调度器的端口号>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>slavenode1:8088</value>
</property>
< rm2webapp端口号>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<执行MapReduce需要配置的shuffle过程>
</configuration>
启动YARN
1) 将yarn-site.xml文件发送到slavenode1和slavenode2节点上。
[hadoop@masternode hadoop]$ scp yarn-site.xml slavenode1:/home/hadoop/app/hadoop/etc/hadoop/
yarn-site.xml 100% 2782 2.7KB/s 00:00
[hadoop@masternode hadoop]$ scp yarn-site.xml slavenode2:/home/hadoop/app/hadoop/etc/hadoop/
yarn-site.xml 100% 2782 2.7KB/s 00:00
2)在masternode节点上执行。
[hadoop@masternode hadoop]$ sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/app/hadoop/logs/yarn-hadoop-resourcemanager-masternode.out
slavenode2: starting nodemanager, logging to /home/hadoop/app/hadoop/logs/yarn-hadoop-nodemanager-slavanode2.out
[hadoop@masternode hadoop]$ jps
8640 DFSZKFailoverController
8969 ResourceManager
6459 QuorumPeerMain
8476 JournalNode
9054 Jps
YARN对应的进程为ResourceManager。
3)在slavenode1节点上执行。
[hadoop@slavenode1 hadoop]$ sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/app/hadoop/logs/yarn-hadoop-resourcemanager-slavenode1.out
[hadoop@slavenode1 hadoop]$ jps
5667 DFSZKFailoverController
5562 JournalNode
4507 QuorumPeerMain
6059 ResourceManager
6127 Jps
5487 NameNode
同时打开以下web界面。
http://hadoop11:8088
http://hadoop12:8088


检查一下ResourceManager状态
[hadoop@slavenode1 hadoop]$ bin/yarn rmadmin -getServiceState rm1
18/04/20 16:58:26 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
standby
[hadoop@slavenode1 hadoop]$ bin/yarn rmadmin -getServiceState rm2
18/04/20 16:58:33 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
active
即slavenode1的ResourceManager,即rm1,是active;masternode的ResourceManager,即rm2,是standby;结论也与web页面吻合。关闭其中一个resourcemanager,然后再启动,同Namenode也能使两节点状态交换。
那么,到此hadoop的3节点集群搭建完毕,我们使用zookeeper来管理hadoop集群,同时,实现了namenode热备和ResourceManager热备。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号