Hadoop实战:用Hadoop处理Excel通话记录
项目需求
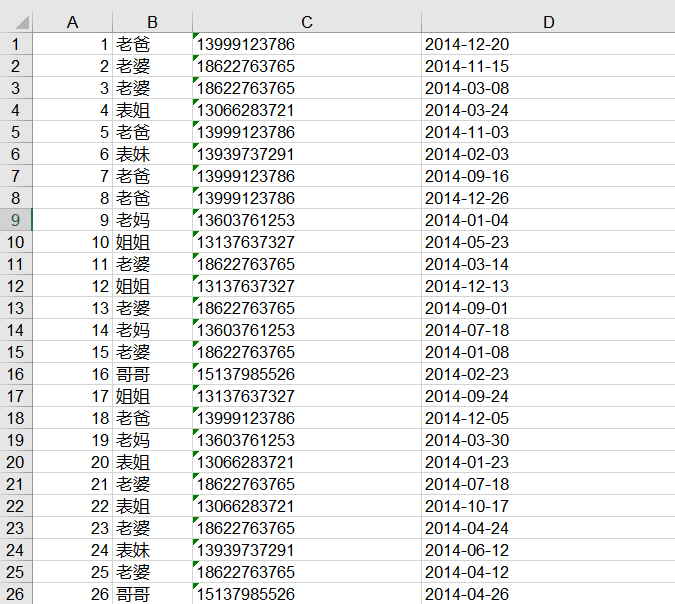
有博主与家庭成员之间的通话记录一份,存储在Excel文件中,如下面的数据集所示。我们需要基于这份数据,统计每个月每个家庭成员给自己打电话的次数,并按月份输出到不同文件夹。
数据集
下面是部分数据,数据格式:编号 联系人 电话 时间。
项目实现
首先,输入文件是Excel格式,我们可以借助poi jar包来解析Excel文件,如果本地没有可以下载:poi-3.9.jar 和 poi-excelant-3.9.jar 并引入到项目中。借助这两个jar包,我们先来实现一个Excel的解析类 —— ExcelParser.java。
package com.hadoop.phoneStatistics;
import java.io.IOException;
import java.io.InputStream;
import java.util.Iterator;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
/**
* @author Zimo
* 用于解析Excel中的通话记录
*/
public class ExcelParser {
private static final Log LOG = LogFactory.getLog(ExcelParser.class);
private StringBuilder currentString = null;
private long bytesRead = 0;
public String parseExcelData(InputStream is) {
try {
HSSFWorkbook workbook = new HSSFWorkbook();
// Taking first sheet from the workbook
HSSFSheet sheet = workbook.getSheetAt(0);
// Iterate through each rows from first sheet
Iterator<Row> rowIterator = sheet.iterator();
currentString = new StringBuilder();
while (rowIterator.hasNext()) {
Row row = rowIterator.next();
// For each row, iterate through each columns
Iterator<Cell> cellIterator = row.cellIterator();
while (cellIterator.hasNext()) {
Cell cell = cellIterator.next();
switch (cell.getCellType()) {
case Cell.CELL_TYPE_BOOLEAN:
bytesRead++;
currentString.append(cell.getBooleanCellValue() + "\t");
break;
case Cell.CELL_TYPE_NUMERIC:
bytesRead++;
currentString.append(cell.getNumericCellValue() + "\t");
break;
case Cell.CELL_TYPE_STRING:
bytesRead++;
currentString.append(cell.getStringCellValue() + "\t");
break;
}
}
currentString.append("\n");
}
is.close();
} catch (IOException ioe) {
// TODO: handle exception
LOG.error("IO Exception : File not found " + ioe);
}
return currentString.toString();
}
public long getBytesRead()
{
return bytesRead;
}
}
ExcelPhoneStatistics.java
package com.hadoop.phoneStatistics;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* @author Zimo
* 处理通话记录
*/
public class ExcelPhoneStatistics extends Configured implements Tool {
private static Logger logger = LoggerFactory.getLogger(ExcelPhoneStatistics.class);
public static class ExcelMapper extends
Mapper<LongWritable, Text, Text, Text>
{
private static Logger LOG = LoggerFactory.getLogger(ExcelMapper.class);
private Text pkey = new Text();
private Text pvalue = new Text();
/**
* Excel Spreadsheet is supplied in string form to the mapper. We are
* simply emitting them for viewing on HDFS.
*/
public void map(LongWritable key, Text value, Context context)
throws InterruptedException, IOException
{
//1.0, 老爸, 13999123786, 2014-12-20
String line = value.toString();
String[] records = line.split("\\s+");
String[] months = records[3].split("-");//获取月份
pkey.set(records[1] + "\t" + months[1]);//昵称+月份
pvalue.set(records[2]);//手机号
context.write(pkey, pvalue);
LOG.info("Map processing finished");
}
}
public static class PhoneReducer extends Reducer<Text, Text, Text, Text>
{
private Text pvalue = new Text();
protected void reduce(Text Key, Iterable<Text> Values, Context context)
throws IOException, InterruptedException
{
int sum = 0;
Text outKey = Values.iterator().next();
for (Text value : Values)
{
sum++;
}
pvalue.set(outKey+"\t"+sum);
context.write(Key, pvalue);
}
}
public static class PhoneOutputFormat extends
MailMultipleOutputFormat<Text, Text>
{
@Override
protected String generateFileNameForKeyValue(Text key,
Text value, Configuration conf)
{
//name+month
String[] records = key.toString().split("\t");
return records[1] + ".txt";
}
}
@Override
public int run(String[] args) throws Exception
{
Configuration conf = new Configuration();// 配置文件对象
Path mypath = new Path(args[1]);
FileSystem hdfs = mypath.getFileSystem(conf);// 创建输出路径
if (hdfs.isDirectory(mypath))
{
hdfs.delete(mypath, true);
}
logger.info("Driver started");
Job job = new Job();
job.setJarByClass(ExcelPhoneStatistics.class);
job.setJobName("Excel Record Reader");
job.setMapperClass(ExcelMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setInputFormatClass(ExcelInputFormat.class);//自定义输入格式
job.setReducerClass(PhoneReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setOutputFormatClass(PhoneOutputFormat.class);//自定义输出格式
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
return 0;
}
public static void main(String[] args) throws Exception
{
String[] args0 = {
// args[0], args[1]
"hdfs://master:8020/phone/phone.xls",
"hdfs://master:8020/phone/out/"
};
int ec = ToolRunner.run(new Configuration(), new ExcelPhoneStatistics(), args0);
System.exit(ec);
}
}
ExcelInputFormat.java
package com.hadoop.phoneStatistics;
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
/**
* @author Zimo
* 自定义输入格式
* * <p>
* An {@link org.apache.hadoop.mapreduce.InputFormat} for excel spread sheet files.
* Multiple sheets are supported
* <p/>
* Keys are the position in the file, and values are the row containing all columns for the
* particular row.
*/
public class ExcelInputFormat extends FileInputFormat<LongWritable, Text> {
@Override
public RecordReader<LongWritable, Text> createRecordReader(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
return new ExcelRecordReader();
}
public class ExcelRecordReader extends RecordReader<LongWritable, Text> {
private LongWritable key;
private Text value;
private InputStream is;
private String[] strArrayofLines;
@Override
public void initialize(InputSplit genericSplit, TaskAttemptContext context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
FileSplit split = (FileSplit) genericSplit;
Configuration job = context.getConfiguration();
final Path file = split.getPath();
FileSystem fs = file.getFileSystem(job);
FSDataInputStream fileIn = fs.open(file);
is = fileIn;
String line = new ExcelParser().parseExcelData(is);//调用解析excel方法
this.strArrayofLines = line.split("\n");
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
// TODO Auto-generated method stub
if (key == null) {
key = new LongWritable(0);
value = new Text(strArrayofLines[0]);
} else {
if (key.get() < this.strArrayofLines.length - 1) {
long pos = (int)key.get();
key.set(pos + 1);
value.set(this.strArrayofLines[(int)(pos + 1)]);
pos++;
} else {
return false;
}
}
if (key == null || value == null) {
return false;
} else {
return true;
}
}
@Override
public LongWritable getCurrentKey() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return key;
}
@Override
public Text getCurrentValue() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
// TODO Auto-generated method stub
return 0;
}
@Override
public void close() throws IOException {
// TODO Auto-generated method stub
if (is != null) {
is.close();
}
}
}
}
MailMultipleOutputFormat.java
package com.hadoop.phoneStatistics;
import java.io.DataOutputStream;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.OutputCommitter;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.ReflectionUtils;
import com.jcraft.jsch.Compression;
/**
* @author Zimo
* @param <MultiRecordWriter>
* 自定义输出格式
*/
public abstract class MailMultipleOutputFormat<K extends WritableComparable<?>, V extends Writable>
extends FileOutputFormat<K, V>{
private MultiRecordWriter writer = null;
public RecordWriter<K, V> getRecordWriter(TaskAttemptContext job) throws IOException {
if (writer == null) {
writer = new MultiRecordWriter(job, getTaskOutputPath(job));
}
return writer;
}
private Path getTaskOutputPath(TaskAttemptContext conf) throws IOException {
Path workPath = null;
OutputCommitter committer = super.getOutputCommitter(conf);
if (committer instanceof FileOutputCommitter) {
workPath = ((FileOutputCommitter) committer).getWorkPath();
} else {
Path outputPath = super.getOutputPath(conf);
if (outputPath == null) {
throw new IOException("Undefined job output-path");
}
workPath = outputPath;
}
return workPath;
}
//通过key, value, conf来确定输出文件名(含扩展名)
protected abstract String generateFileNameForKeyValue(K key, V value, Configuration conf);
public class MultiRecordWriter extends RecordWriter<K, V> {
//RecordWriter的缓存
private HashMap<String, RecordWriter<K, V>> recordWriters = null;
private TaskAttemptContext job = null;
//输出目录
private Path workPath = null;
public MultiRecordWriter(TaskAttemptContext job, Path workpath) {
// TODO Auto-generated constructor stub
super();
this.job = job;
this.workPath = workpath;
recordWriters = new HashMap<String, RecordWriter<K, V>>();
}
@Override
public void write(K key, V value) throws IOException, InterruptedException {
// TODO Auto-generated method stub
//得到输出文件名
String baseName = generateFileNameForKeyValue(key, value, job.getConfiguration());
RecordWriter<K, V> rw = this.recordWriters.get(baseName);
if (rw == null) {
rw = getBaseRecordWriter(job, baseName);
this.recordWriters.put(baseName, rw);
}
rw.write(key, value);
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
// TODO Auto-generated method stub
Iterator<RecordWriter<K, V>> values = this.recordWriters.values().iterator();
while (values.hasNext()) {
values.next().close(context);
}
this.recordWriters.clear();
}
private RecordWriter<K, V> getBaseRecordWriter(TaskAttemptContext job, String baseName)
throws IOException {
Configuration conf = job.getConfiguration();
boolean isCompressed = getCompressOutput(job);
String keyValueSeparator = "\t";//key value 分隔符
RecordWriter<K, V> recordWriter = null;
if (isCompressed) {
Class<? extends CompressionCodec> codecClass = getOutputCompressorClass(job, GzipCodec.class);
CompressionCodec codec = ReflectionUtils.newInstance(codecClass, conf);
Path file = new Path(workPath, baseName + codec.getDefaultExtension());
FSDataOutputStream fileOut = file.getFileSystem(conf).create(file, false);
recordWriter = new MailRecordWriter<K, V>(
new DataOutputStream(codec.createOutputStream(fileOut)), keyValueSeparator);
} else {
Path file = new Path(workPath, baseName);
FSDataOutputStream fileOut = file.getFileSystem(conf).create(file, false);
recordWriter = new MailRecordWriter<K, V>(fileOut, keyValueSeparator);
}
return recordWriter;
}
}
}
MailRecordWriter.java
package com.hadoop.phoneStatistics;
import java.io.DataOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
/**
* @author Zimo
*
*/
public class MailRecordWriter< K, V > extends RecordWriter< K, V >
{
private static final String utf8 = "UTF-8";
private static final byte[] newline;
static
{
try
{
newline = "\n".getBytes(utf8);
} catch (UnsupportedEncodingException uee)
{
throw new IllegalArgumentException("can't find " + utf8 + " encoding");
}
}
protected DataOutputStream out;
private final byte[] keyValueSeparator;
public MailRecordWriter(DataOutputStream out, String keyValueSeparator)
{
this.out = out;
try
{
this.keyValueSeparator = keyValueSeparator.getBytes(utf8);
} catch (UnsupportedEncodingException uee)
{
throw new IllegalArgumentException("can't find " + utf8 + " encoding");
}
}
public MailRecordWriter(DataOutputStream out)
{
this(out, "/t");
}
private void writeObject(Object o) throws IOException
{
if (o instanceof Text)
{
Text to = (Text) o;
out.write(to.getBytes(), 0, to.getLength());
} else
{
out.write(o.toString().getBytes(utf8));
}
}
public synchronized void write(K key, V value) throws IOException
{
boolean nullKey = key == null || key instanceof NullWritable;
boolean nullValue = value == null || value instanceof NullWritable;
if (nullKey && nullValue)
{
return;
}
if (!nullKey)
{
writeObject(key);
}
if (!(nullKey || nullValue))
{
out.write(keyValueSeparator);
}
if (!nullValue)
{
writeObject(value);
}
out.write(newline);
}
public synchronized void close(TaskAttemptContext context) throws IOException
{
out.close();
}
}
项目结果
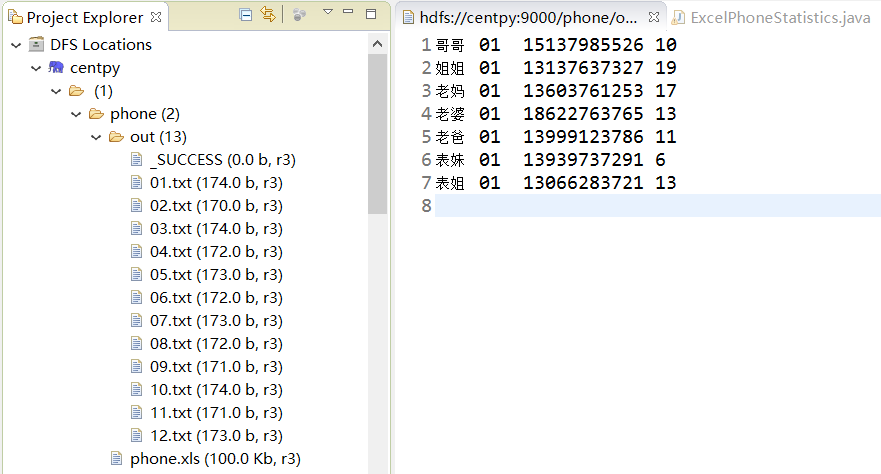
处理结果如上图所示,输出数据格式为:姓名+月份+电话号码+通话次数。我们成功将所有通话记录按月输出为一个文件夹,并统计出了和每一个人的通话次数。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。
本博文由博主子墨言良原创,未经允许禁止转载,若有兴趣请关注博主以第一时间获取更新哦!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号