

MapReduce的输入格式
1. InputFormat接口
InputFormat接口包含了两个抽象方法:getSplits()和creatRecordReader()。InputFormat决定了Hadoop如何对文件进行分片和接收, 它能够从一个 job 中得到一个 split 集合(InputSplit[]),然后再为这个 split 集合配上一个合适的 RecordReader(getRecordReader)来读取每个split中的数据。InputFormat接口的实现细节如下。
public abstract class Inputformat<K,V> {
public abstract List<InputSplit> getSplits(JobContext context);
public abstract RecordReader<K, V>creatRecordReader(InputSplit split, TaskAttemptContext context);
}
2. InputFormat接口实现类层次结构
InputFormat接口的实现类有很多,其结构层次如下。
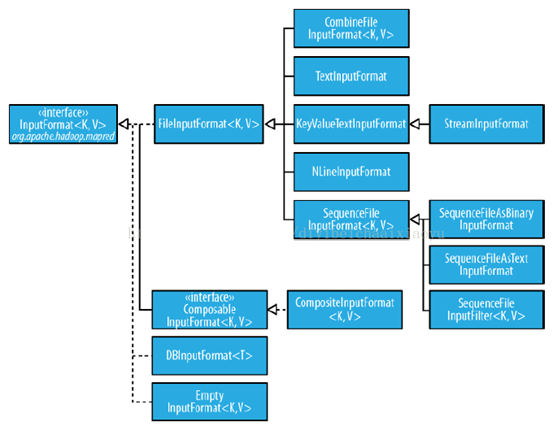
3. FileInputformat输入路径设置
FileInputformat为MapReduce中文件输入格式实现类的基类,其作用主要是指定输入文件路径,它提供了四种静态方法来指定输入路径。
public static void addInputPath(Job job, Path path); public static void addInputPaths(Job job, String commaSeparatedPaths); public static void setInputPaths(Job job, Path inputPaths); public static void setInputPaths(Job job, String commaSeparatedPaths);
实例如下,
FileInputFormat.addInputPath(job, newPath("Path1")); //设置一个源路径
FileInputFormat.addInputPaths(job," Path1, Path2,..."); //设置多个源路径,多个源路径之间用逗号分开
FileInputFormat.setInputPaths(job,new Path(“path1”), new Path(“path2”),…); //可以包含多个源路径,
FileInputFormat.setInputPaths(job,”Path1”,” Path2,..."); //设置多个源路径,多个源路径之间用逗号分开
4. FileInputformat子类
这里我们介绍几种常用的文件类型的输入格式:TextInputformat,KeyValueTextInputformat,NLineInputformat和SequenceFileInputFormat。
4.1 TextInputformat
TextInputformat是一种文本输入格式,它也是MapReduce默认的输入格式。TextInputformat将每条记录作为一行输入,其键值是LongWritable 类型,存储该行在整个文件中的字节偏移量。 值是这行的内容,不包括任何行终止符(换行符合回车符),它们被打包成一个 Text 对象。
以下是一个示例,比如,一个分片包含了如下4条文本记录。
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise
每条记录表示为以下键/值对:
(0,Rich learning form)
(19,Intelligent learning engine)
(47,Learning more convenient)
(72,From the real demand for more close to the enterprise)
很明显,键并不是行号。一般情况下,很难取得行号,因为文件按字节而不是按行切分为分片。
4.1 KeyValueTextInputformat
KeyValueTextInputformat为键值对文本输入格式。每一行均为一条记录,被分隔符(缺省是tab(\t))分割为key(Text),value(Text)。
以下是一个示例,输入是一个包含4条记录的分片。其中——>表示一个(水平方向的)制表符,即tab键。
line1 ——>Rich learning form
line2 ——>Intelligent learning engine
line3 ——>Learning more convenient
line4 ——>From the real demand for more close to the enterprise
每条记录表示为以下键/值对:
(line1,Rich learning form)
(line2,Intelligent learning engine)
(line3,Learning more convenient)
(line4,From the real demand for more close to the enterprise)
此时的键是每行排在制表符之前的Text序列。
4.3 NLineInputformat
NLineInputformat为多行输入格式。
分别使用 TextInputFormat 和 KeyValueTextInputFormat输入格式时,每个 Mapper 收到的输入行数是不同的,其中的行数取决于输入分片的大小和行的长度。如果希望 Mapper 收到固定行数的输入,需要使用 NLineInputFormat 输入格式。与 TextInputFormat 一样, 键是文件中行的字节偏移量,值是行本身。N 是每个 Mapper 收到的输入行数。N 设置为1(默认值)时,每个 Mapper 正好收到一行输入。
以下是一个示例,仍然以上面的4行输入为例。
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise
例如,如果 N 是2,则每个输入分片包含两行。一个 mapper 收到前两行键值对:
(0,Rich learning form)
(19,Intelligent learning engine)
另一个 mapper 则收到后两行:
(47,Learning more convenient)
(72,From the real demand for more close to the enterprise)
这里的键和值与 TextInputFormat 生成的一样。
4.4 SequenceFileInputFormat
SequenceFileInputFormat为序列化的文件输入格式,用于读取sequence file。序列文件为Hadoop专用的压缩二进制文件格式,它专用于一个MapReduce作业和其他MapReduce作业之间的传送数据,使用于多个MapReduce作业之间的链接操作。
5. MultipleInputs(多输入格式处理)
虽然一个 MapReduce 作业的输入可能包含多个输入文件,但所有文件都由同一个 InputFormat 和 同一个 Mapper 来解释。 然而,数据格式往往会随时间演变,所以必须写自己的 Mapper 来处理应用中的遗留数据格式问题。或者,有些数据源会提供相同的数据, 但是格式不同。
这些问题可以使用 MultipleInputs 类来妥善处理,它允许为每条输入路径指定 InputFormat 和 Mapper。例如,我们想把英国 Met Office 的气象站数据和美国NCDC 的气象站数据放在一起来统计平均气温,则可以按照下面的方式来设置输入路径。
MultipleInputs.addInputPath(job,ncdcInputPath,TextInputFormat.class,NCDCTemperatureMapper.class);
MultipleInputs.addInputPath(job,metofficeInputPath,TextInputFormat.class,MetofficeTemperatureMapper.class);
这样做目的就是为了,不论有多少个数据源、多少种数据格式,经过Map阶段处理,输出类型一样,Reduce不用关心输入格式。!!!
这段代码取代了对 FileInputFormat.addInputPath()和job.setMapperClass() 的常规调用。Met Office 和 NCDC 的数据都是文本文件,所以对两者都使用 TextInputFormat 数据类型。 但这两个数据源的行格式不同,所以我们使用了两个不一样的 Mapper,分别为NCDCTemperatureMapper和MetofficeTemperatureMapper。重要的是两个 Mapper 的输出类型一样,因此,reducer 看到的是聚集后的 map 输出,并不知道这些输入是由不同的 Mapper 产生的。
DBInputFormat
DBInputFormat 这种输入格式用于使用 JDBC 从关系数据库中读取数据。因为它没有任何共享能力,所以在访问数据库的时候必须非常小心,在数据库中运行太多的 mapper 读数据可能会使数据库受不了。 正是由于这个原因,DBInputFormat 最好用于加载少量的数据集。与之相对应的输出格式是DBOutputFormat,它适用于将作业输出数据(中等规模的数据)转存到数据库。
6. 如何自定义Inputformat
有时候 Hadoop 自带的输入格式,并不能完全满足业务的需求,所以需要我们根据实际情况自定义 InputFormat 类。而数据源一般都是文件数据,那么自定义 InputFormat时继承 FileInputFormat 类会更为方便,从而不必考虑如何分片等复杂操作。 自定义输入格式我们分为以下几步:
1)继承 FileInputFormat 基类。
2)重写 FileInputFormat 里面的 isSplitable() 方法。
3)重写 FileInputFormat 里面的 createRecordReader()方法。
在一篇博文中有一个实战项目(MapReduce实战:自定义输入格式实现成绩管理),大家可以学习一下。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。
