


MapReduce实战项目:查找相同字母组成的字谜
实战项目:查找相同字母组成的字谜
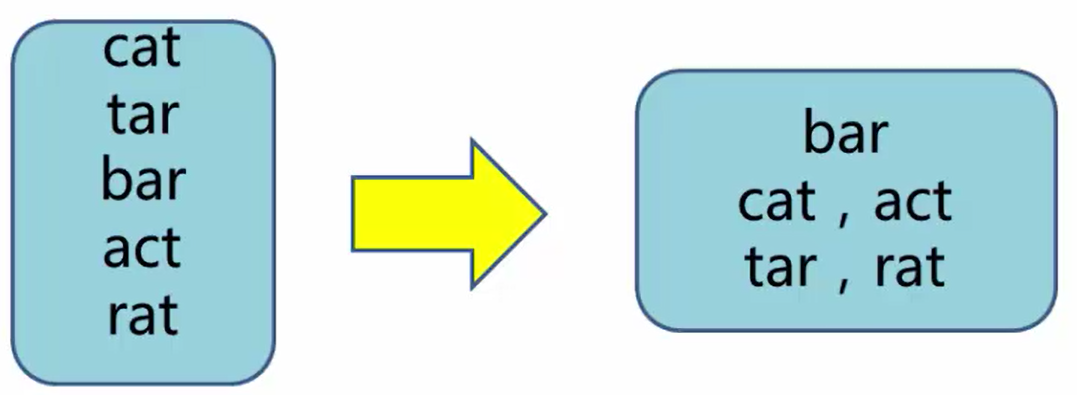
项目需求:一本英文书籍中包含有成千上万个单词或者短语,现在我们要从中找出相同字母组成的所有单词。
数据集和期望结果举例:
思路分析:
1)在Map阶段,对每个word按字母进行升序(或降序)排序生成sortWord,然后输出key/value键值对(sortWord, word)。
2)在Reduce阶段,统计出每组根据相同字母组成的所有anahrams(字谜)。
项目代码:
/**
*
*/
package com.hadoop.train;
import java.io.IOException;
import java.util.Arrays;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @author Zimo
* 统计相同字母组成的所有单词
* 1、编写Map()函数
* 2、编写Reduce()函数
* 3、编写run()函数
* 4、编写main()方法
*/
public class Anagram extends Configured implements Tool {
public static class AnagramMapper extends Mapper<LongWritable, Text, Text, Text> {
private Text sortedText = new Text();
private Text orginalText = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将单词转换为字符串,然后存入字符数组
String word = value.toString();
char[] wordChars = word.toCharArray();
//排序
Arrays.sort(wordChars);
//将排好序的字符数组转换为字符串类型,此时为一个Word按其字母排序后组成的另一个Word,然后存入sortedText中
String sortedWord = new String(wordChars);
sortedText.set(sortedWord);
//将原始字母存入orginalText
orginalText.set(word);
context.write(sortedText, orginalText);
}
}
public static class AnagramReducer extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//将相同字母组成的单词用"~"符号链接起来
String output = "";
for(Text anagram:values) {
if (!output.equals("")) {
output = output + "~";
}
output += anagram.toString();
}
StringTokenizer outputTokenizer = new StringTokenizer(output, "~");
//过滤掉只有一个字母的单词
if (outputTokenizer.countTokens() >= 2) {
output = output.replaceAll("~", ",");
context.write(key, new Text(output));
}
}
}
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
String[] args0 = {args[0], args[1]};
int ec = ToolRunner.run(new Configuration(), new Anagram(), args0);//运行返回值
System.exit(ec);
}
@Override
public int run(String[] arg0) throws Exception {
// TODO Auto-generated method stub
//加载配置文件
Configuration conf = new Configuration();
//判断输出路径是否存在,存在则删除
Path myPath = new Path(arg0[1]);
FileSystem hdfs = myPath.getFileSystem(conf);
if (hdfs.isDirectory(myPath)) {
hdfs.delete(myPath, true);
}
//构造Job对象
Job job = new Job(conf, "anagram");
//设置主类
job.setJarByClass(Anagram.class);
//设置输入输出路径
FileInputFormat.addInputPath(job, new Path(arg0[0]));
FileOutputFormat.setOutputPath(job, new Path(arg0[1]));
job.setMapperClass(AnagramMapper.class);
job.setReducerClass(AnagramReducer.class);
//设置key和value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//提交作业
job.waitForCompletion(true);
return 0;
}
}
将项目导出为JAR包,上传到Hadoop集群,然后执行命令:
hadoop jar Anagram.jar com.hadoop.train.Anagram /anagram /anagram/output //为了格式在命令前加上了空格,用的时候请去掉
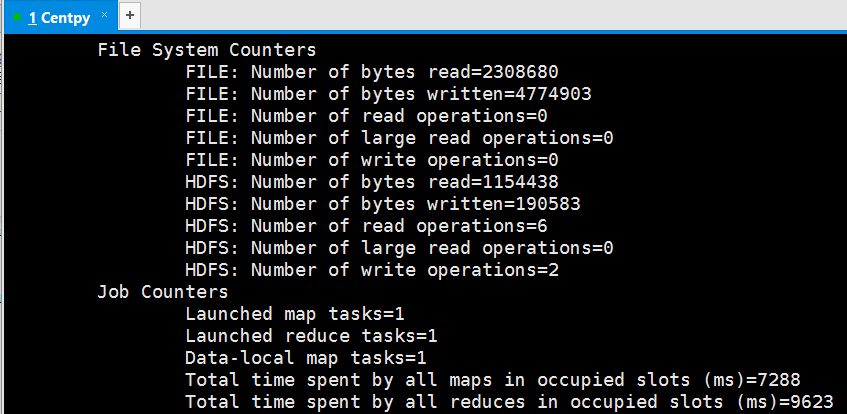
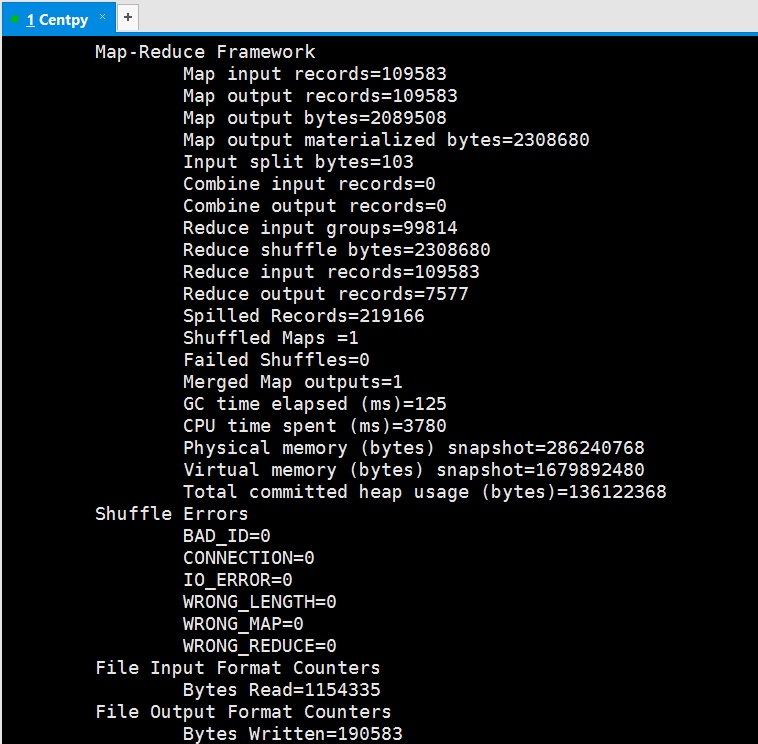
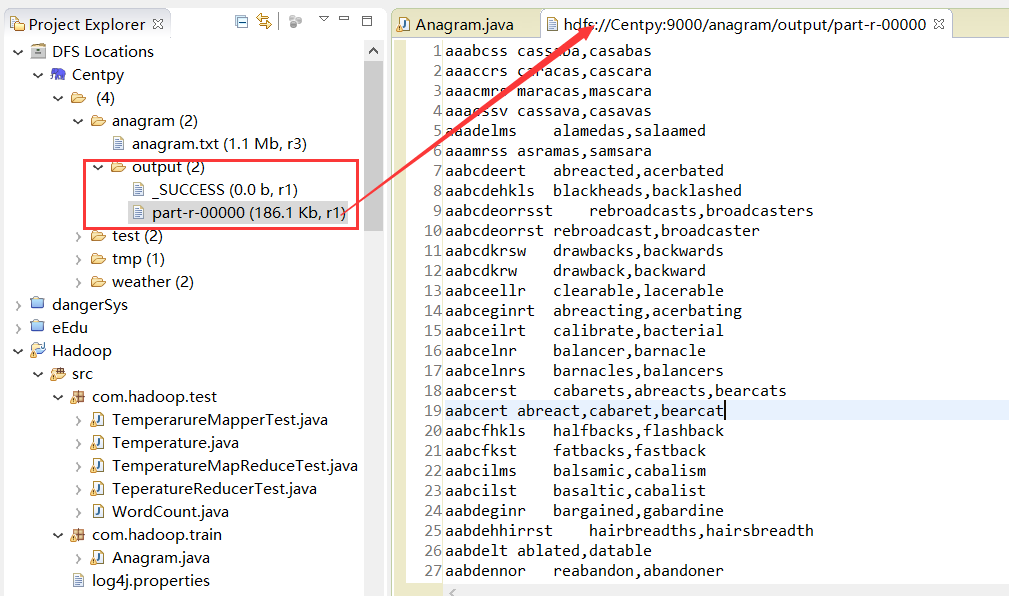
运行结果:
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。
本博文由博主子墨言良原创,未经允许禁止转载,若有兴趣请关注博主以第一时间获取更新哦!

