Hadoop 2.2.0单节点的伪分布集成环境搭建
Hadoop版本发展历史
第一代Hadoop被称为Hadoop 1.0
1)0.20.x
2)0.21.x
3)0.22.x
第二代Hadoop被称为Hadoop 2.0(HDFS Federation、YARN)
1)0.23.x
2)2.x
3)2.2.0 稳定版本 Namenode HA
4)2.4 ResourceManager HA
5)2.6 稳定版本
6)2.7 jdk1.7
Hadoop角色部署
Hadoop的安装模式分为三种:
1)单机模式:默认的安装模式,占用资源少,不需要修改配置文件,且完全运行于本地,不需要与其它节点进行交互,也不需要使用HDFS文件系统和加载任何守护进程,主要应用于开发调试MapReduce应用程序。
2)伪分布模式:也即单节点集成模式,其所有守护进程都运行在同一台机器上(比如Namenode、Datanode、Nodemanager、ResourceManger和、SecondaryNamenode等);这种模式增加了代码的调试功能,可查看内存情况、HDFS的输入和输出、以及其它守护进城之间的交互。
3)全分布模式:主要用于生产环境,且在实际应用中均使用分布式集群。
考虑到大家学习时的硬件条件限制,我们将安装第二种伪分布模式并将Namenode、Datanode、Nodemanager、ResourceManger和、SecondaryNamenode配置到同一节点。
Hadoop环境安装准备
Centos系统
版本:6.5
JDK
版本:1.7.0
Hadoop
版本:2.2.0 稳定版本
注意:为了避免许多不必要的错误,以上各环境位数应该保持一致,我们选择为64位。
Hadoop伪分布环境搭建
安装过程主要分为三步:JDK安装、.SSH无密码访问配置和Hadoop环境配置
1. JDK安装
首先使用Xshell工具登陆到虚拟机环境下(虚拟机安装及配置点击此处跳转:CentOS 6.5的安装详解,在此感谢“大数据躺过的坑”博主为我们提供的如此详尽的介绍),首先检查是否已经安装JDK,在命令行下输入java -version命
令,结果如下图所示:
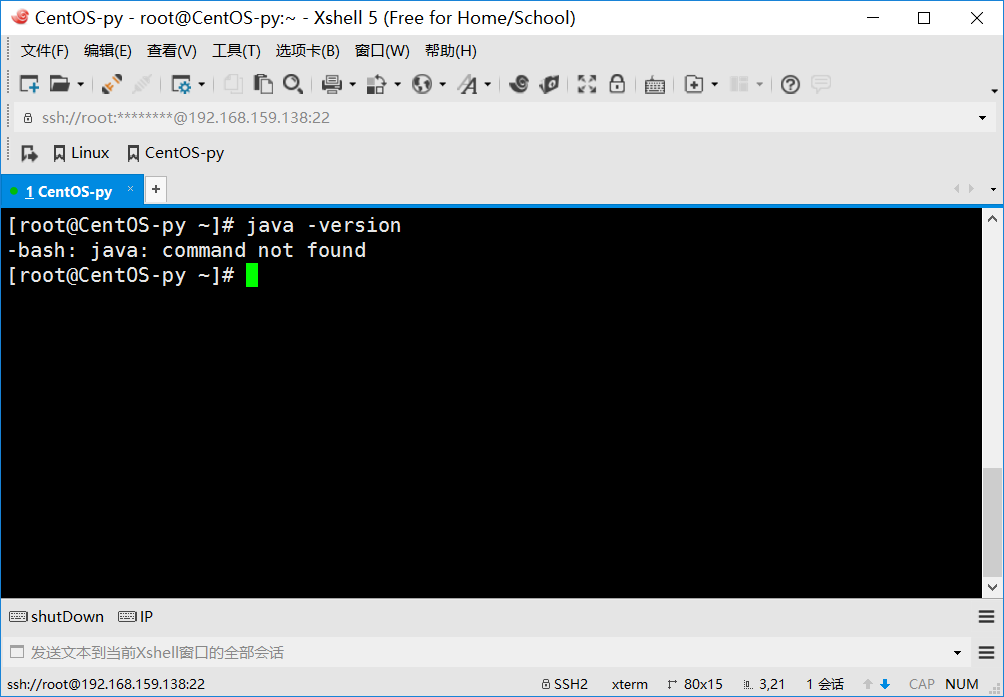
很明显现在我们还没有安装JDK,于是接下来我们就一起来学习如何从零开始搭建我们的JDK环境。
首先,查看我们Centos系统位数:file /bin/ls;结果如下,我们的Centos系统为64位,所以我们的JDK、SSH和Hadoop也必须保持位数一致。

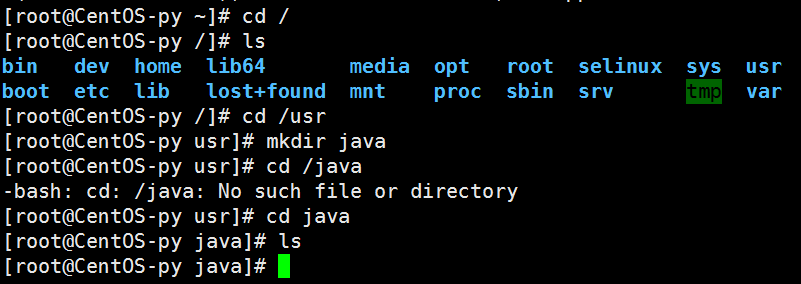
我们先在usr目录下创建个java目录作为存放JDK的目录:首先进入根目录cd /,列出目录信息ls,然后进入usr目录,并创建java目录mkdir java,此时java应该为空目录,如图所示:
然后,将本地下载好的jdk1.7.0包放到本地目录,再使用rz命令上传。首先,我们先运行rz命令,检查是否已经安装此命令。结果如图(由于我已经安装过此命令,下图为网上找到错误示例图):
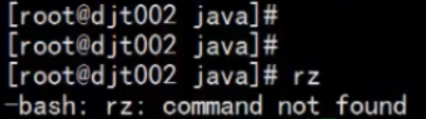
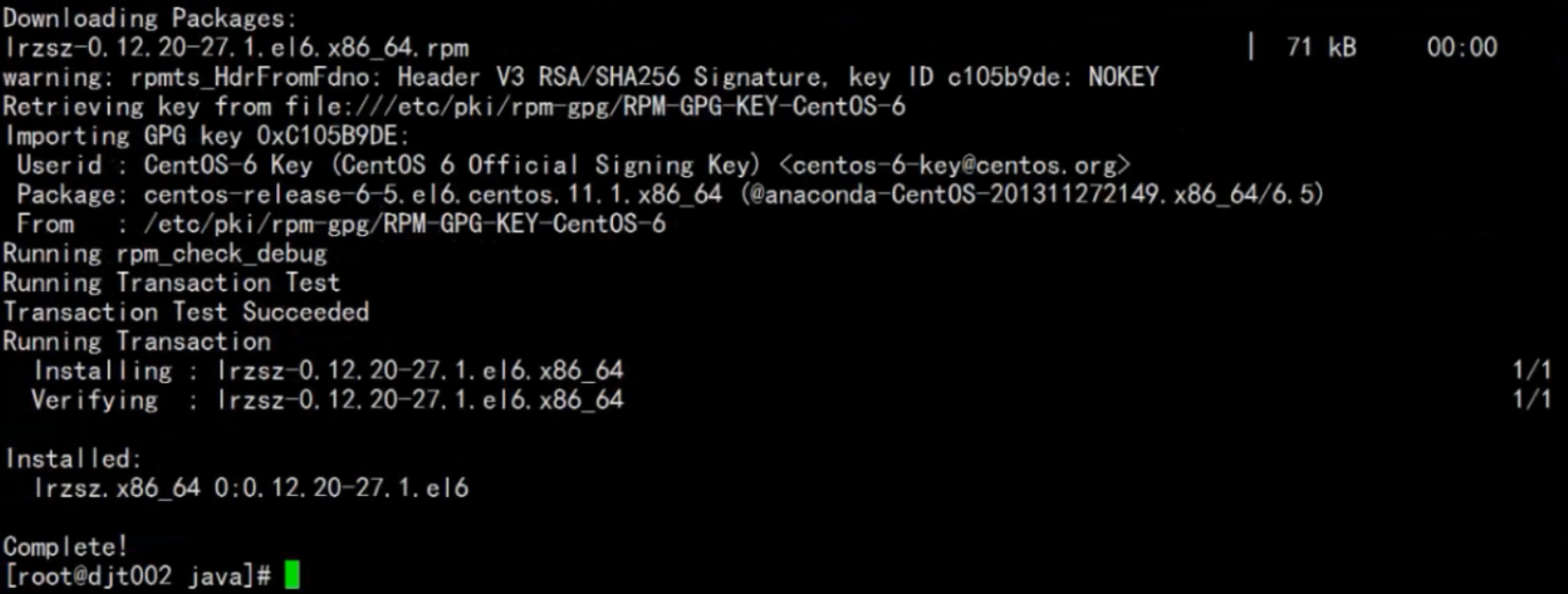
很明显,如果第一次使用一定是没有安装的,接下来我们先安装此命令(如果已经安装的则跳过以下rz工具包安装过程)。我们运行在线下载命令即可直接进行安装:yum -y install lrzsz(yum为包管理器,可帮助我们快速实现在线下载,-y命令可在下载后直接安装而跳过其中的询问过程,推荐使用)

此图显示的即为安装过程,如果出现下图所示信息,则表示安装完成。
接下来,我们使用rz命令上传jdk1.7.0包(前提得先下载好放到本地,可到官网自行下载:http://www.oracle.com/technetwork/java/javase/downloads/index.html),运行日志命令后会弹出以下选择框进行上传文件选择,我们选中下载好的包上传即可。
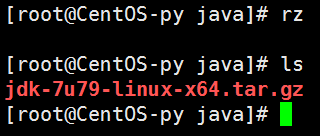
此时,输入ls命令查看即可发现文件已成功上传:
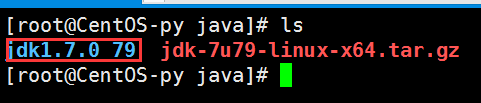
运行tar zxvf jdk-7u79-linux-x64.tar.gz命令进行解压,解压完成后再使用ls命令进行查看,此时可看到已经成功解压出来了,接下来的关键步骤是设置JDK环境变量。
我们依次运行下图中命令即可创建java环境变量的脚本文件

进入后输入“i“进入编辑模式,在此模式下想文档中写入一下内容:
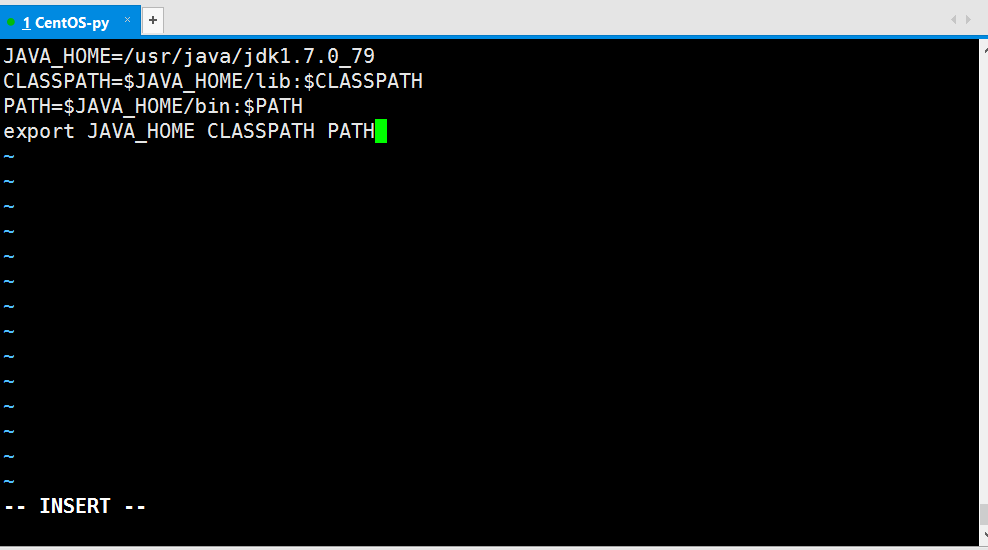
输完以上内容之后,先按Esc键退出编辑模式,然后按下Shift+;组合键并输入wq或x保存退出。此时,直接输入java -version命令还是会出错(如下图所以),为什么呢?
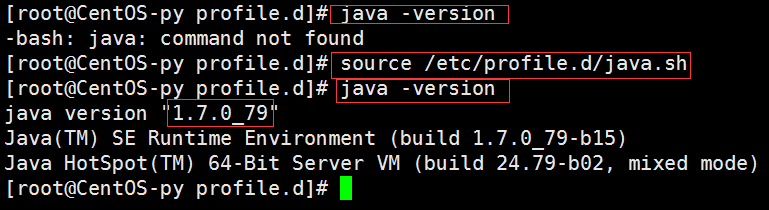
因为我们此时只是生产了该配置文件,但它还没有生效,所以需要使用source命令使其生效,然后再运行就成功了。
到此,JDK的安装就已经完成了。肯定很多人会问我为什么不把命令全部输出来,那大家拷贝粘贴多方便,而要采取截屏的方式展示,那我有必要说一下我的想法。首先,截屏能让大家对于我的操作理解得更形象一点,而不会有种云里雾里的感觉;再者,学习本身就是一个实践的过程,如果大家只是复制粘贴,那本博文就没有任何意义了,我希望各位能亲身体会Linux的环境以及操作,这样才能真正起到学习的作用。所以,希望大家不要复制粘贴我的命令,而是自己完完全全敲上一两遍,自己去切身体会一下Linux系统本身,以及各命令的语法和作用机制。
2. SSH无密码访问配置
首先,我们先修改一下host文件,添加hostname与IP之间的对应关系,以方便我们访问。输入ipconfig命令查看IP配置信息:
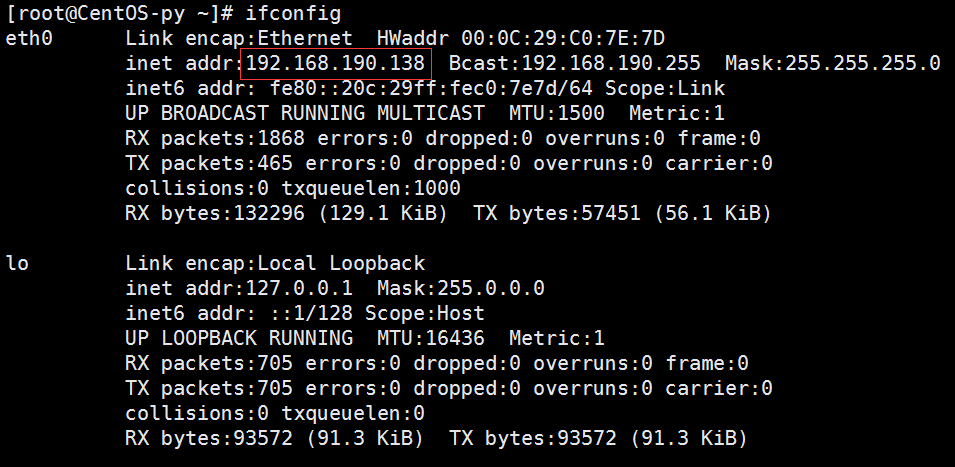
然后,输入vi /etc/hosts,进入host文件并在末尾添加一行配置:

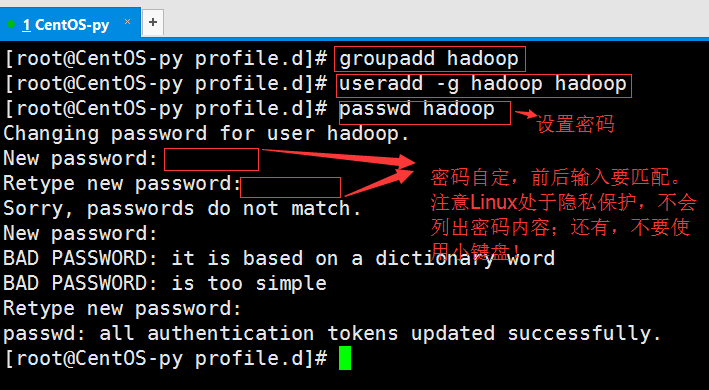
接下来,我们需要创建一个新的用户来安装Hadoop环境。首先,创建用户组;然后,新建Hadoop用户,并添加到Hadoop用户组中。
注意,在配置Hadoop环境之前,我们需要先关闭防火墙,首先查看防火墙状态:
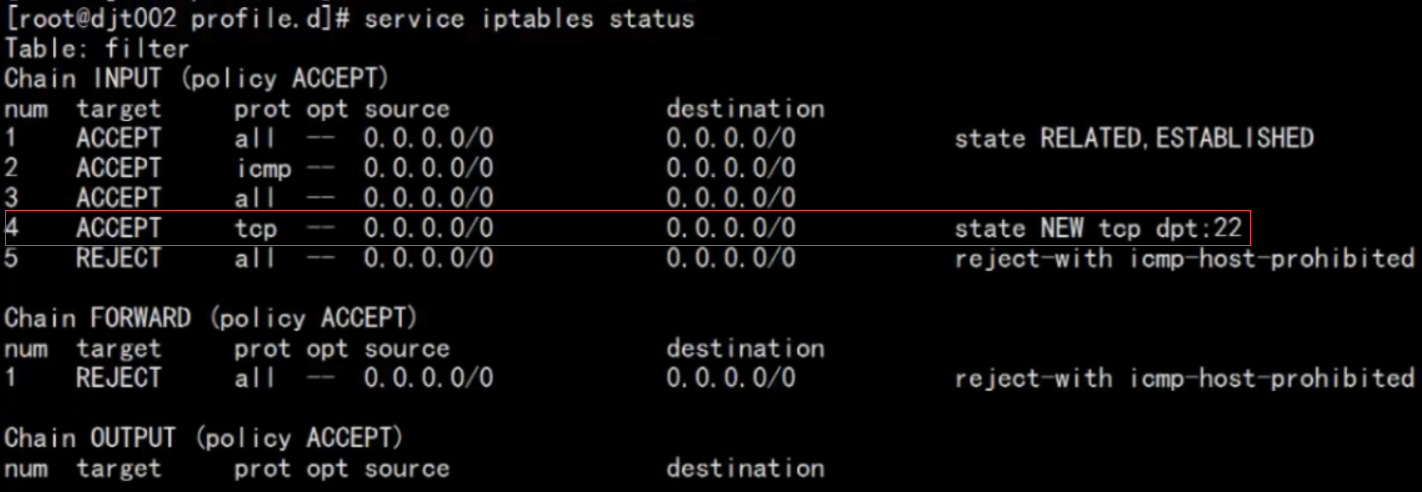
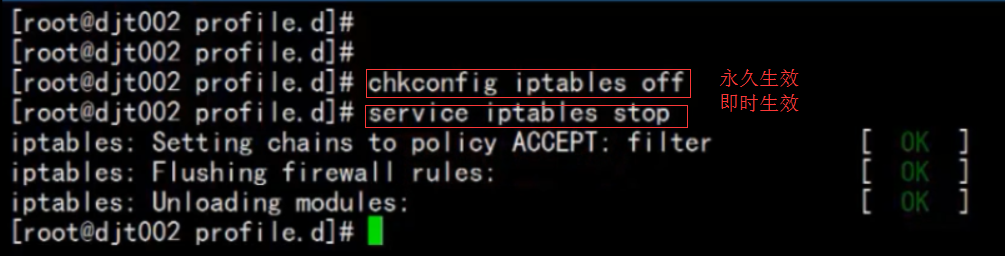
关闭防火墙:

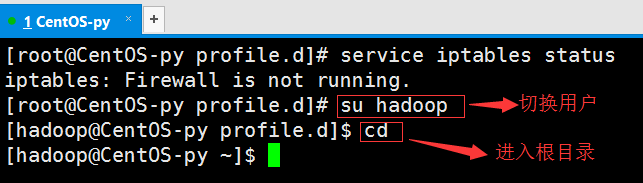
接下来是SSH无密码验证配置:
我们使用新创建的hadoop用户,并进入根目录下,一次输入一下命令,创建秘钥:
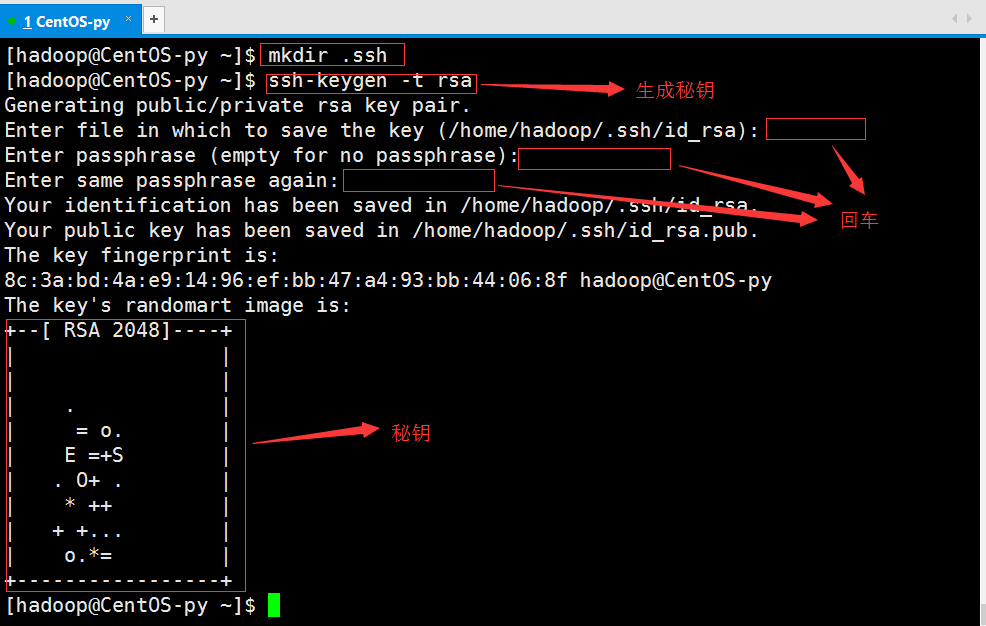
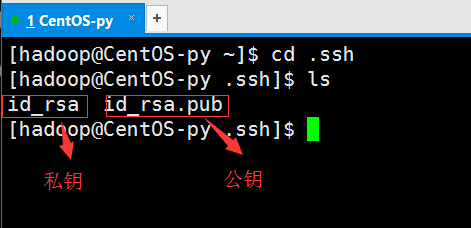
然后将公钥复制到认证文件中去
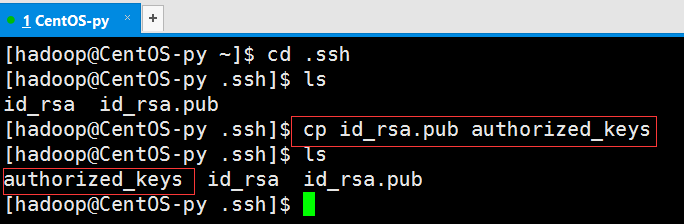
使用vi命令进行查看:
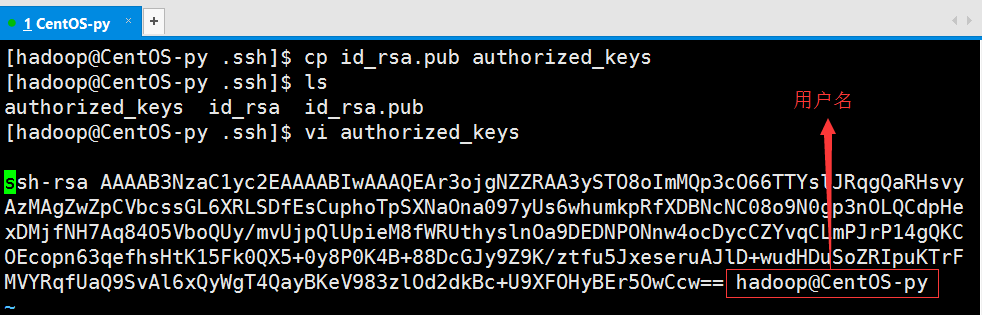
设置文件权限:

使用ssh访问当前节点,如果出现下图所示内容表示SSH无密码访问配置成功:

3. Hadoop伪分布环境搭建及配置
在这里,我选择把Hadoop安装到我们刚开始时创建的java目录里。我们先进入该目录,然后切换到我们的root用户,再使用wget命令实现在线下载: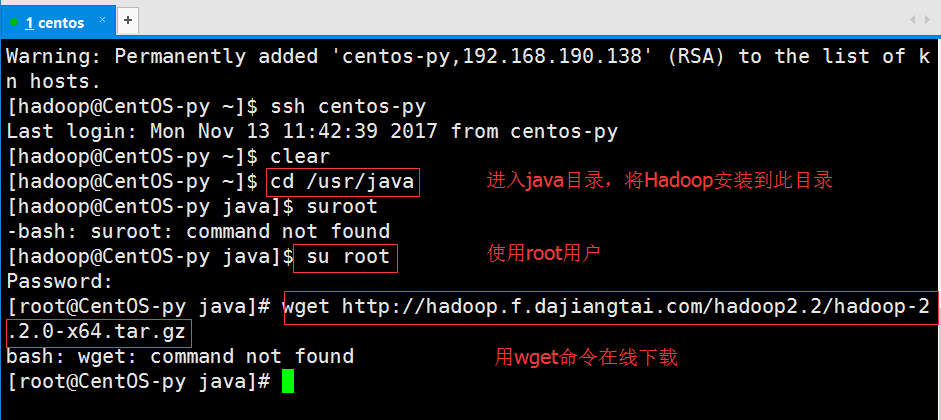
由于是第一次使用,所以wget命令并没有安装,于是我们先安装此命令再进行下载:
安装完成后再次运行命令以下载Hadoop:
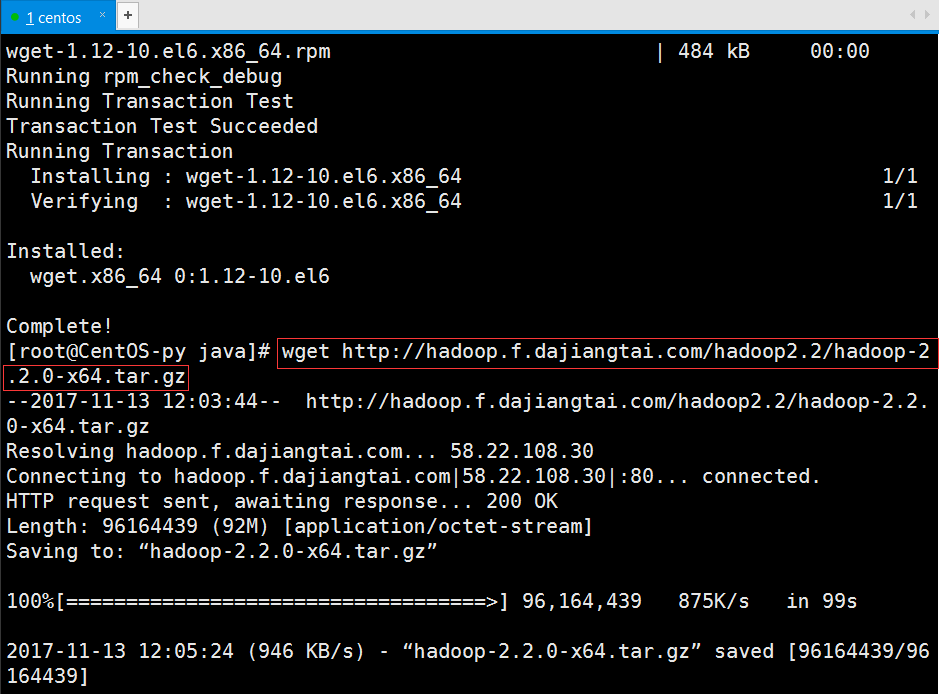
下载完后我们可用ls命令查看下载的安装包,然后解压该文件进行安装:
如图所示,解压成功并修改文件名为hadoop。
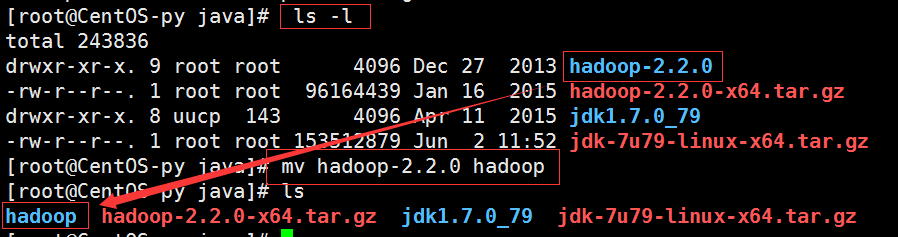
我们查看文件可知Hadoop文件权限为root用户,于是我们需要将文件权限赋给Hadoop用户。
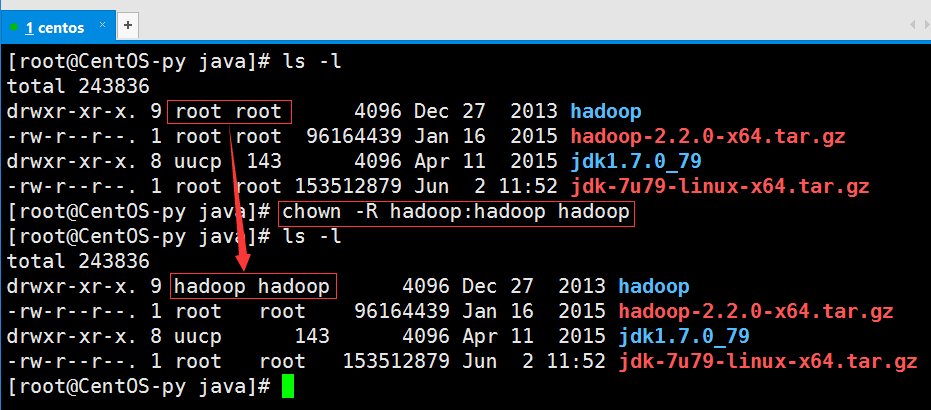
接下来就是创建hadoop的数据目录,并将权限赋给hadoop用户。
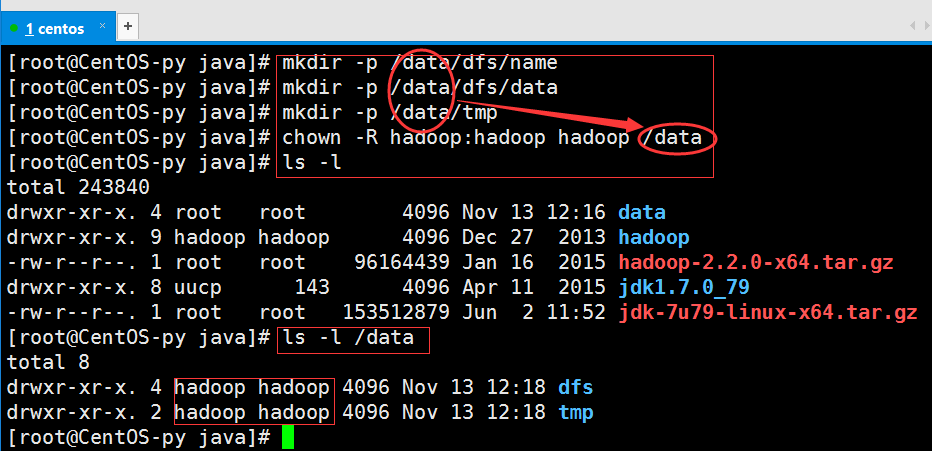
hadoop的环境就基本搭建完毕了,然后我们需要修改一下hadoop的配置文件。

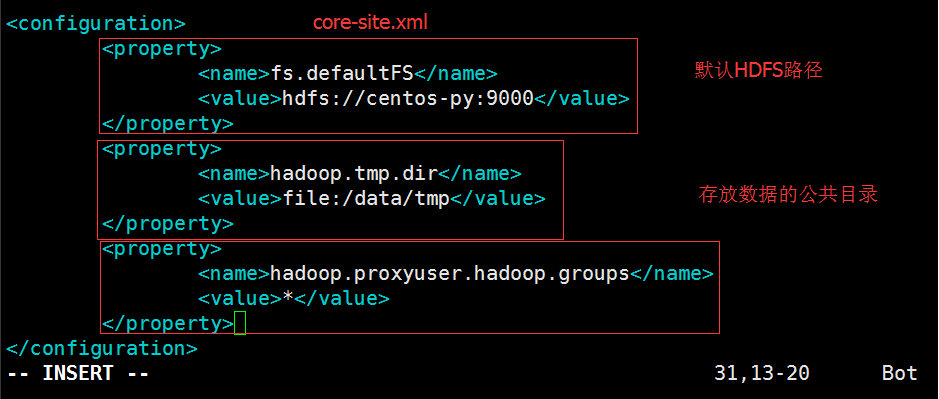
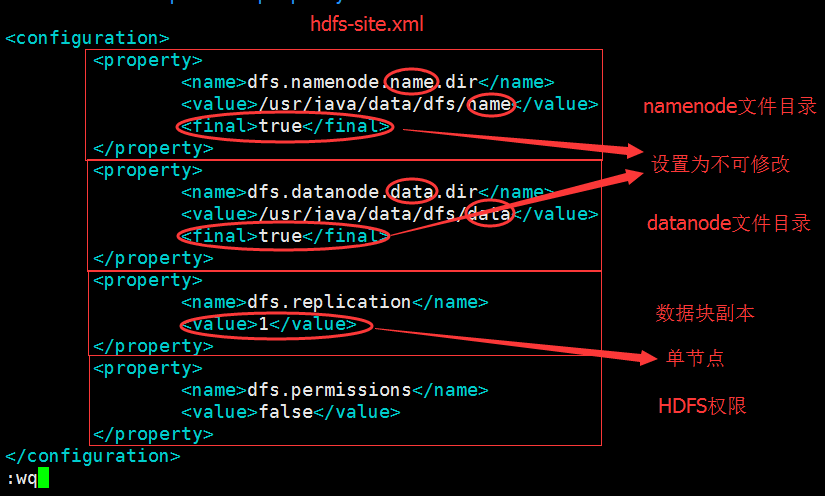
如上图大方框中所示的都是其配置文件,我们需要修改core-site.xml、hdfs-siteml配置文件(注意:一下所有文件修改都是用过vi+文件名指令进行)
接下来我们要编译一下文件:mapred-site.xml、yarn-site.xml和slaves文件。编辑mapred-site.xml文件之前我们要先执行cp mapred-site.xml.template mapred-site.xml命令以生成mapred-site.xml配置文件,然后分别用vi/vim命令进行编辑,分别添加一下内容:
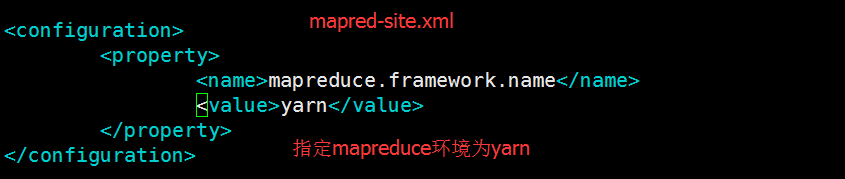
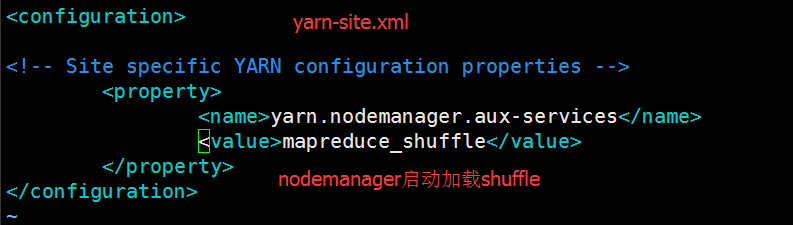
以下指定DataNode和Namenode在同一节点上(图中标注错误,应该是slaves文件):
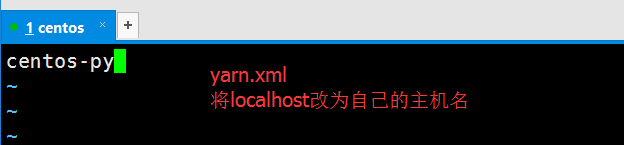
接下来,我们需要设置hadoop环境变量,此操作必须在root用户下操作,然后在配置文件末尾追加以下内容:

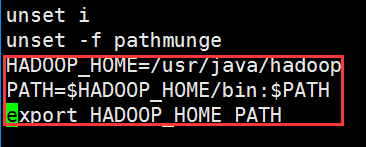
最后,我们使用source /etc/profile命令使配置生效。到此为止,我们已经完成了hadoop的安装与配置工作。
4. 测试与运行
我们先切换到hadoop目录,退到安装目录,然后格式化Namenode。
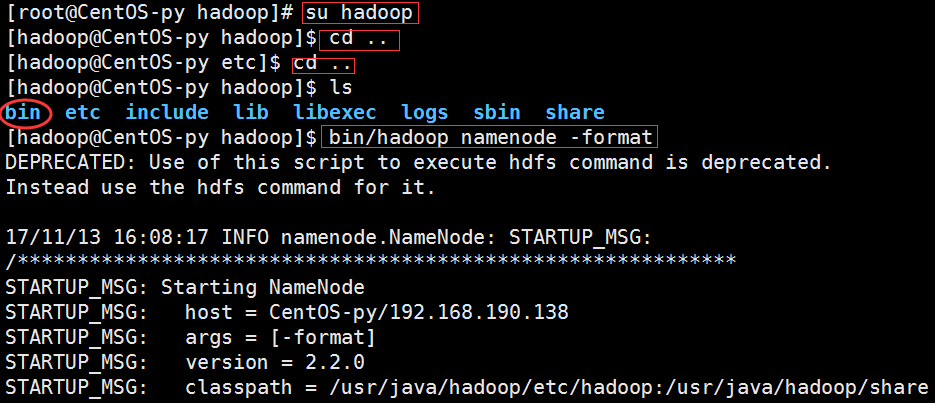
接下来我们启动集群并查看进程(由于我已经启动过,所以内容和你们稍有不同,但我们可以看到已经启动了的进程,如大方框所示):
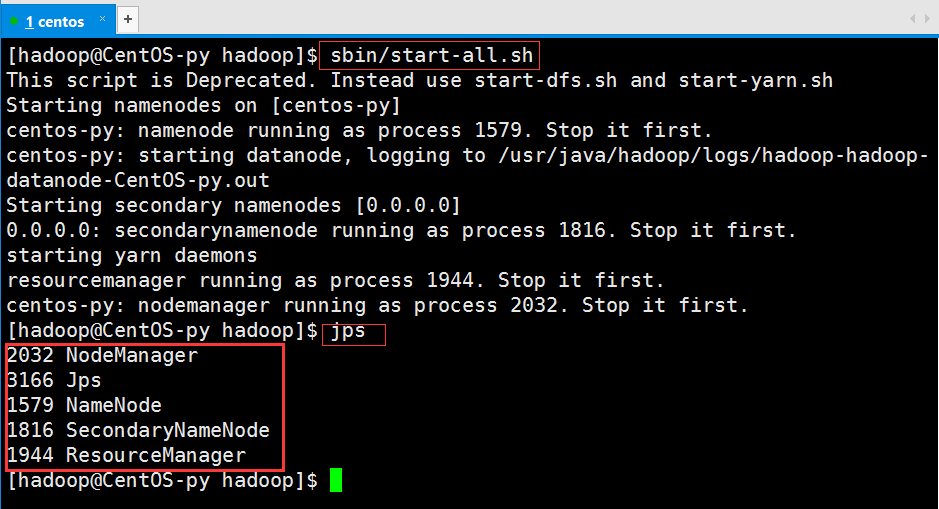
到此,hadoop2.2.0单节点伪分布集成环境就搭建完成了。
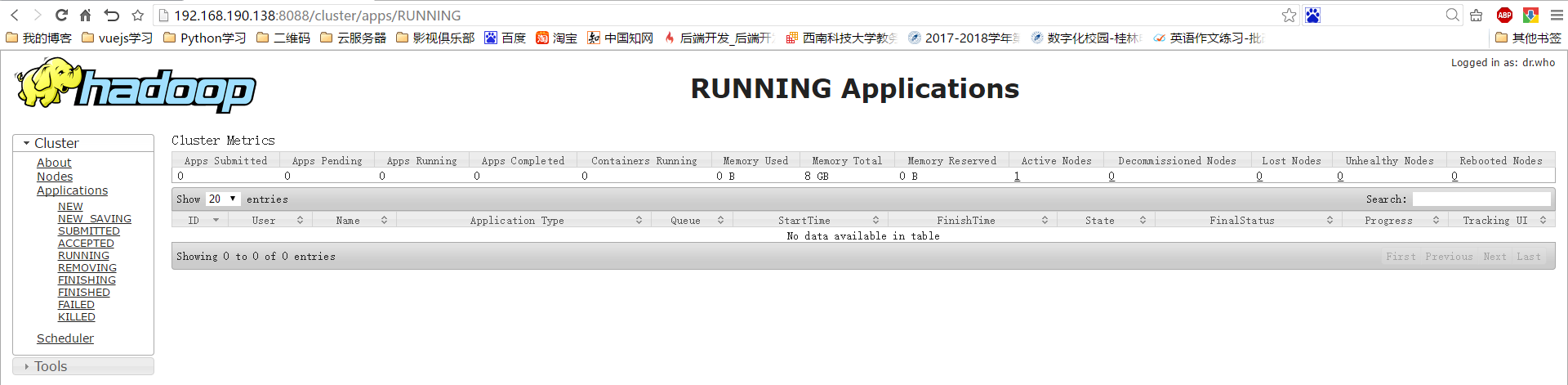
然后我们就可以在网页上查看我们的Hadoop环境的情况了!
为了方便访问,我们可以在Windows下配置hostname到IP地址的对应关系。首先以管理员身份运行记事本,然后打开C:\Windows\System32\drivers\etc下的hosts.txt文件,在文件末尾加入一行配置:
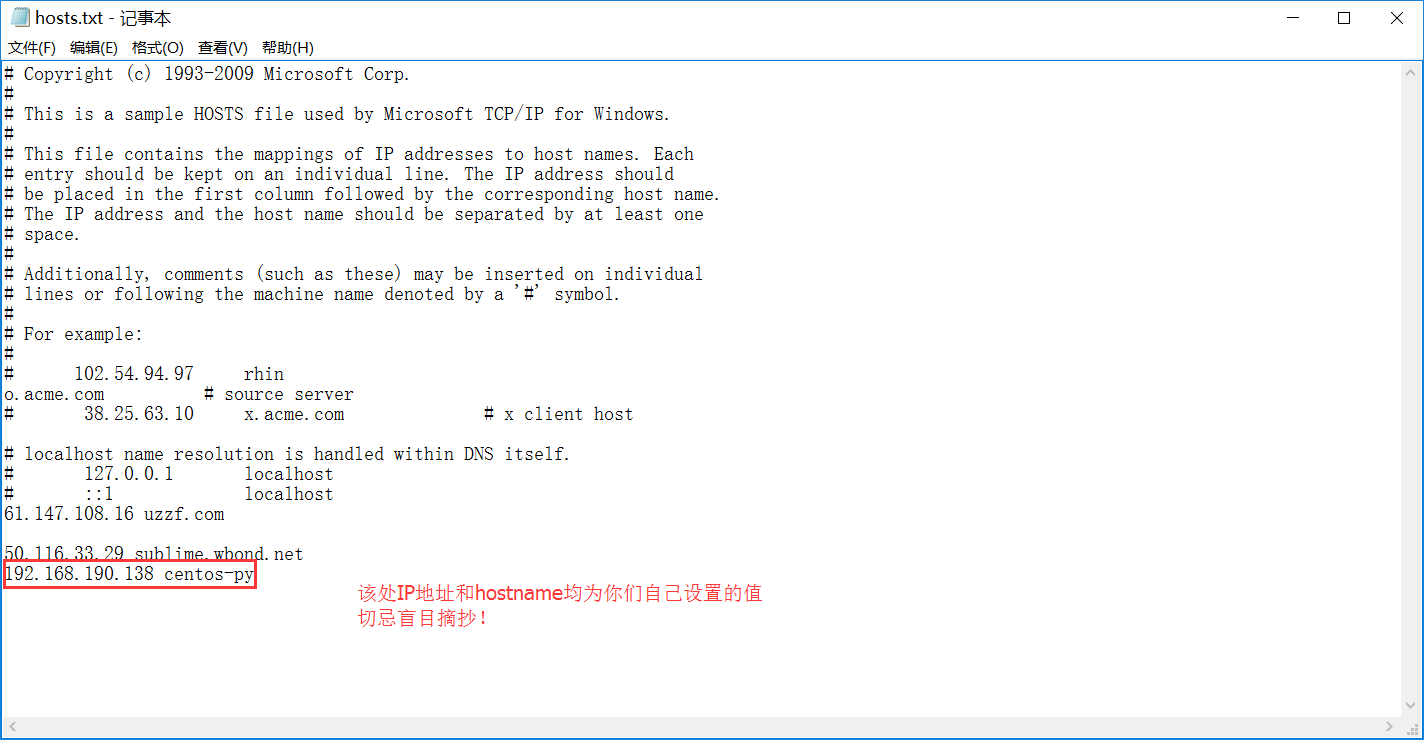
配置好后就可以用我们的主机名替代IP地址进行访问了。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号