MySQL-漫谈(二)
一条 Select 语句是如何执行的
我们在使用mysql时,使用最多的就是查数据,当我们输入select 语句后,mysql 如何给我们返回对应的数据的?
MySQL基本架构
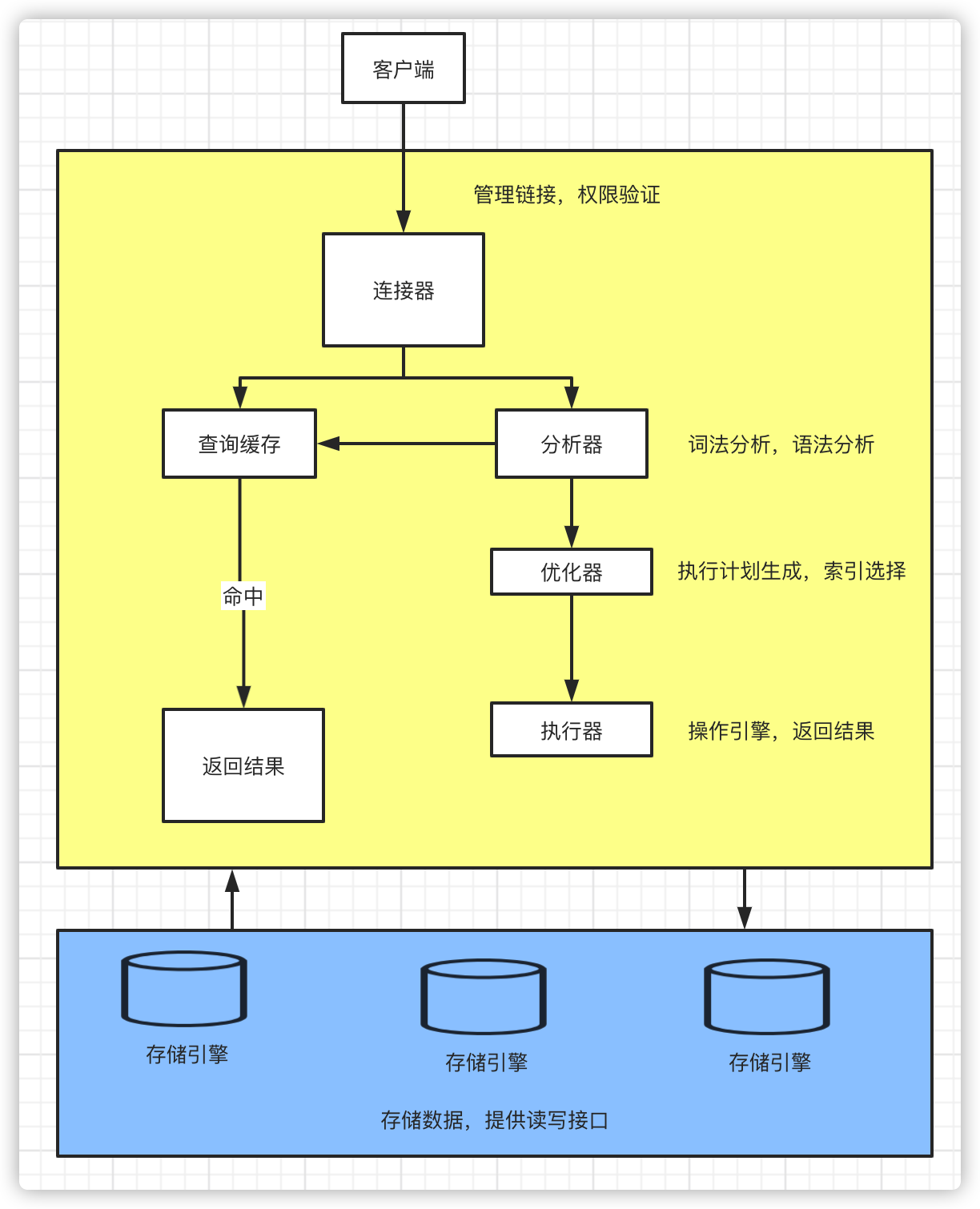
MySQL分为Server层和存储引擎层两个部分,Server 层包括:
- 连接器
- 查询缓存
- 分析器
- 执行器等,以及所有的内置函数(如日期、时间、数学和加密函数等)和跨存储引擎的功能(如存储过程、触发器、视图)
- 存储引擎层负责数据的存储和提取,支持 InnoDB、MyISAM、Memory 等多个存储引擎。
执行步骤
第一步:链接,我们会先连接到 MySQL 数据库,此时就是连接上连接器。连接器负责和客户建立连接,获取权限,维持和管理连接。
mysql -h $ip -u root -p
第二步:查询缓存,MySQL 会现在查询缓存看看之前是不是执行过这条语句,如果有就直接返回。但是在 MySQL 8.0 之后,此模块已被移除。
第三步:分析语句,如果缓存没有获取到,MySQL就开始分析我们的语句,他需要知道我们要干什么,我们的命令是不是错了,分析器会先做词法分析,识别出字符串以及它代表的含义。然后再进行语法分析,判断我们编写的 SQL 语句有没有错误,如果有错误就会抛出错误。
第四步:优化语句,分析完语句后,MySQL就知道我们正在的命令了,但是我们的命令可能不是最有效率的,所以MySQL会优化我们的命令,获得最优的执行方案。
第五步:执行器得到上一步的优化后的指令后就开始执行,调用存储引擎获取执行命令后的结果。
注: 第二步的时候获取缓存,但MySQL8.0直接把这个模块(Query Cache)移除掉了,原因是什么?
先了解下Query Cache的具体规则,如果数据表被更改,那么和这个数据表相关的全部Cache全部都会无效,并删除。这里“数据表更改”包括: INSERT, UPDATE, DELETE, TRUNCATE, ALTER TABLE, DROP TABLE, or DROP DATABASE等。试想一下,如果一个表新增(insert)一条数据,该表对应的所有缓存都会被删除,实际场景就是一张表的数据缓存刚建立好,该表有更新,所有缓存失效,并进行重新建立,而建立的缓存几乎还没用到又会失效,Query Cache在建立缓存与缓存失效之间反复横跳,而它忘记的自己的初衷,提高高效的查询,除非该表是一张静态条,缓存才能发挥作用。
MySQL 通信协议
我们大致知道一条select语句的执行过程了,但是整个过程中MySQL是怎样通信的?
要知道MySQL通信协议就要知道它是怎样连接的,MySQL是应用,分为客户端与服务端,客户端与服务端是需要进行连接的,Mysql的主要连接方式包括:Unix套接字,内存共享,命名管道,TCP/IP套接字等,这么多连接方式,我们到底使用的是哪一种?共享内存与命名管道只能是客户端与服务端在同一机器,并且是widows环境下才能使用,在Linux和Unix环境下,可以使用Unix套接字进行Mysql服务器的连接;Unix套接字其实不是一个网络协议,只能在客户端和Mysql服务器在同一台电脑上才可以使用 ,但是客户端与服务端往往不在一个服务器上,这个时候连接使用的是TCP/IP套接字 ,TCP连接就需要经典的三次握手了。
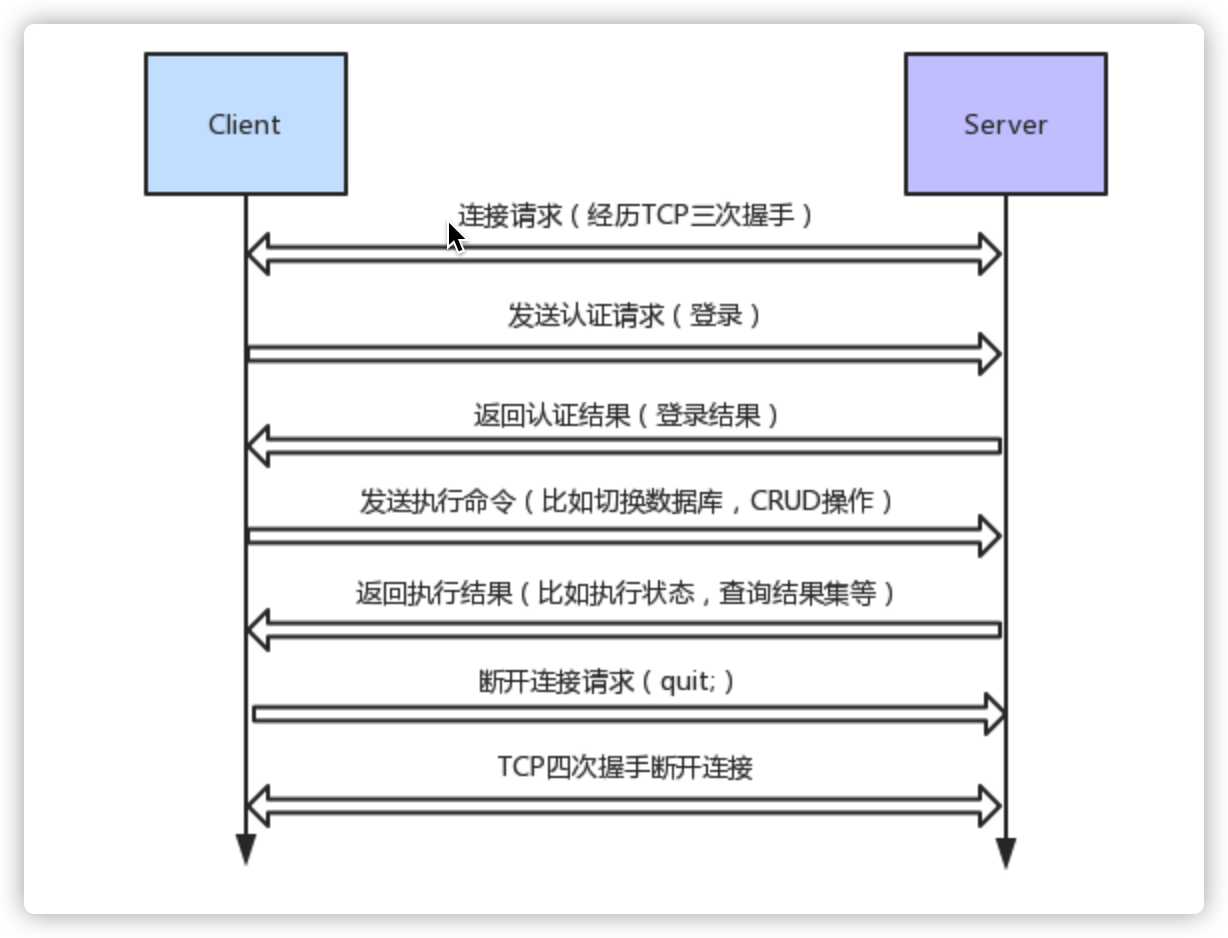
当我们crud时整个mysql执行过程大致为:
- 首先Client先与Server通过TCP三次握手建立连接
- 建立连接之后,Server发送Handshake数据包给Client,Handshake含有数据库的版本、协议版本、用于后期加密的Salt等。
- Client接收到Server的Handshake包之后,解析其中数据,最主要是获得Salt,然后把用户名、密码(利用salt+sha1进行加密)、schema(要操作的数据库名)等信息打包成一个AuthPacket,用来认证请求。
- Server接受到AuthPacket之后,对其的身份进行验证,验证成功发送一个OK Packet。否则发送Error Packet。
- Client接受到OK Packet之后就发送Query Packet给Server。
- Server返回结果查询的,将Result Packet返回给Client。
- Client解析Result Packet完毕,发送Request Quit。
- 四次握手断开连接。
drop、delete与truncate的区别
| Delete | Truncate | Drop | |
| 类型 | DML | DDL | DDL |
| 是否支持回滚 | 支持 | 不支持 | 不支持 |
| 删除类容 | 仅删除对应的数据 | 表结构还在,删除表中所有数据 | 从数据库中删除表,表中所有的数据,索引,权限 |
| 删除速度 | 速度慢,逐行删除 | 删除速度快 | 速度最快 |
一般来说,在删除速度上,drop> truncate > delete,在使用drop和truncate时一定要注意,虽然可以恢复,但为了减少麻烦,还是要慎重。如果想删除部分数据用delete,注意带上where子句,回滚段要足够大;如果想删除表,当然用drop; 如果想保留表而将所有数据删除,如果和事务无关,用truncate即可;如果和事务有关,或者想触发trigger,还是用delete;如果是整理表内部的碎片,可以用truncate跟上reuse stroage,再重新导入/插入数据。
undo log/ redo log /binlog
undo log(回滚日志)
undo log主要是保证事务的原子性,事务执行失败就回滚,用于在事务执行失败后,对数据回滚。undo log是逻辑日志,记录的是SQL。(可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。)在事务提交后,undo log日志不会立即删除,会放到一个待删除的链表中,有purge线程判断是否有其他事务在使用上一个事务之前的版本信息,然后决定是否可以清理,简单的来说就是前面的事务都提交成功了,这些undo才能删除。change buffer是什么(就是将更新数据页的操作缓存下来)在更新数据时,如果数据行所在的数据页在内存中,直接更新内存中的数据页。如果不在内存中,为了减少磁盘IO的次数,innodb会将这些更新操作缓存在change buffer中,在下一次查询时需要访问这个数据页时,在执行change buffer中的操作对数据页进行更新。适合写多读少的场景,因为这样即便立即写了,也不太可能会被访问到,延迟更新可以减少磁盘I/O,只有普通索引会用到,因为唯一性索引,在更新时就需要判断唯一性,所以没有必要。
redo log(重做日志)
redo log就是为了保证事务的持久性。因为change buffer是存在内存中的,万一机器重启,change buffer中的更改没有来得及更新到磁盘,就需要根据redo log来找回这些更新。优点是减少磁盘I/O次数,即便发生故障也可以根据redo log来将数据恢复到最新状态。缺点是会造成内存脏页,后台线程会自动对脏页刷盘,或者是淘汰数据页时刷盘,此时收到的查询请求需要等待,影响查询。
binlog(二进制日志)
binlog是Mysql sever层维护的一种二进制日志,与innodb引擎中的redo/undo log是完全不同的日志;其主要是用来记录对mysql数据更新或潜在发生更新的SQL语句,并以"事务"的形式保存在磁盘中;其主要作用有:
-
复制:MySQL Replication在Master端开启binlog,Master把它的二进制日志传递给slaves并回放来达到master-slave数据一致的目的。
-
数据恢复:通过mysqlbinlog工具恢复数据。
-
增量备份。
注: 中间件canal就是利用bingo 第一条作用原理实现的,canal模拟mysql slave与mysql master的交互协议,伪装自己是一个mysql slave,向mysql master发送dump协议,mysql master收到mysql slave(canal)发送的dump请求,开始推送binlog增量日志给slave(也就是canal),mysql slave(canal伪装的)收到binlog增量日志后,就可以对这部分日志进行解析,获取主库的结构及数据变更;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号