JVM与GC过程
前言
开发时遇到服务总是莫名其妙的停止,本地调试毫无异常,能够正常启动运行,在测试环境发布后也能正常调用,就是运行一段时间后服务完全无响应了,通过翻报错日志发现出现OOM导致服务异常,于是拉了dump文件进行分析,借此学习了JVM相关知识,以及自己总结的一些编码中的注意事项。
JVM运行时内存布局
从概念上划分的有6个区域入图:
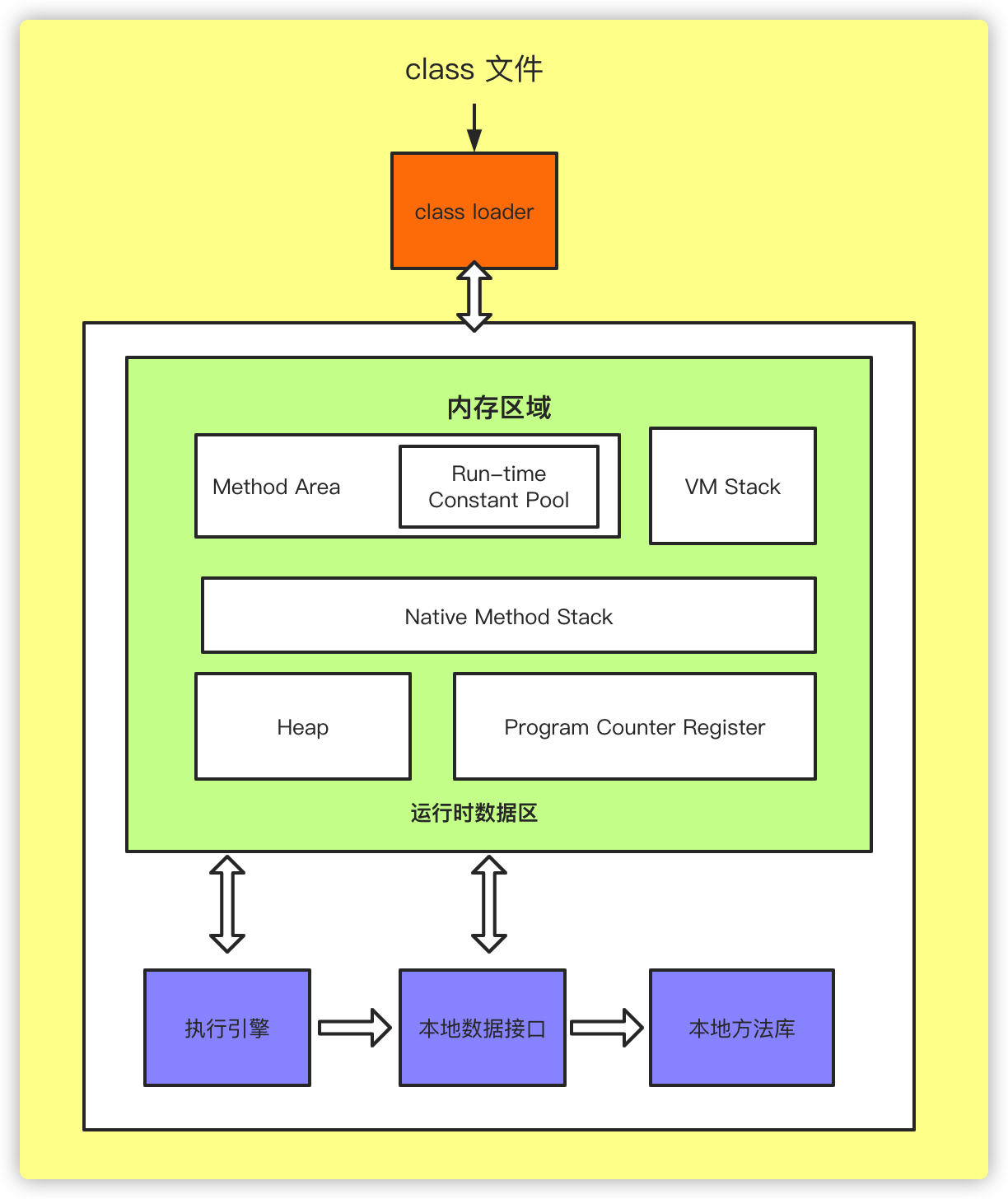
以上六块区域按是否被线程共享,分为两大类:
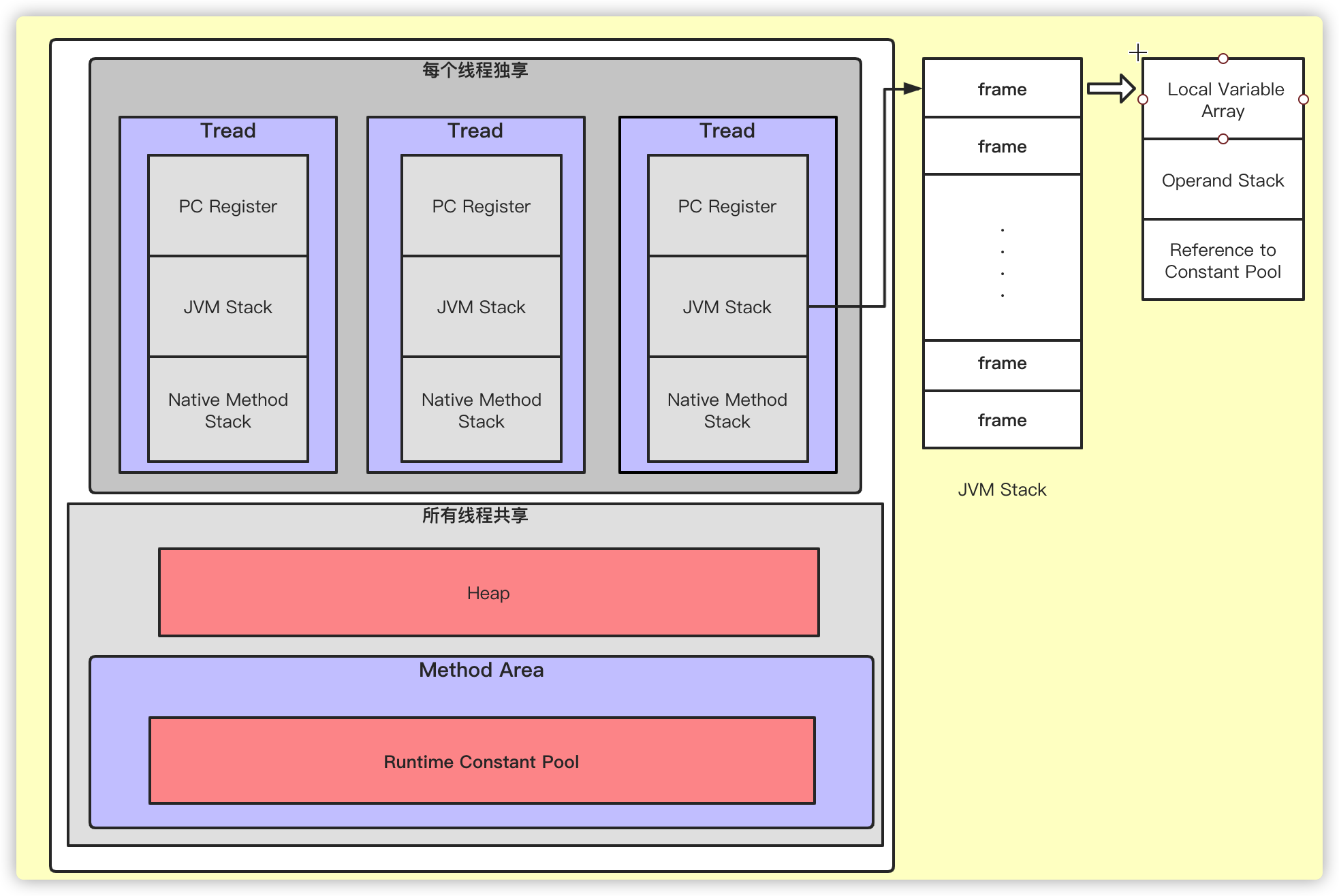
每个线程独享内存
-
PC Register:程序计数器,记录每个线程当前执行的指令。比如当前执行到哪条指令,下一条该执行哪条指令。
-
JVM Stack: 虚拟机栈,记录每个Frame中的局部变量,方法返回地址等,线程中每次有方法调用时都会创建Frame,方法调用结束时Frame销毁。
-
Native Method Stack:原生方法栈,调用操作系统原生本地方法时,所需要的内存区域。
注意: 以上三种内存区域因为是线程独享内存区域,所以其生命周期与线程生命周期相同,也就是说,线程创建时,响应的区域分配内存,线程销毁时,释放响应内存。
所有线程共有内存
- Heap: 堆内存区域,用于存放类的实例对象及Arrays等实例,GC回收的主要区域。
- Method Area: 方法区,存放类结构,类成员定义,static静态成员等。
- Runtime Constant Pool:运行时常量池,如:字符串,int -128~127 范围的值等,它属于方法区的一部分。
以上6个区域,除了PC Register区不会抛出StackOverflowError或OutOfMemoryError ,其它5个区域,当请求分配的内存不足时,均会抛出OutOfMemoryError(即:OOM),其中thread独立的JVM Stack区及Native Method Stack区还会抛出StackOverflowError。还有一块内存区域是不受JVM管控的,就是堆外内存。
GC垃圾回收
垃圾回收回收的是无任何引用的对象占据的内存空间而不是对象本身。换言之,垃圾回收只会负责释放那些对象占有的内存。对象是个抽象的词,包括引用和其占据的内存空间。当对象没有任何引用时其占据的内存空间随即被收回备用,此时对象也就被销毁。但是如何判断哪些对象是垃圾?
引用计数法

引用计数法思想很简单直接看对象是否被引用,被引用说明不是垃圾,但是其致命缺点就是当对象出现循环引用时,引用计数法就完全失效了,所以JVM中使用了另外一种判断方法。
可达性分析
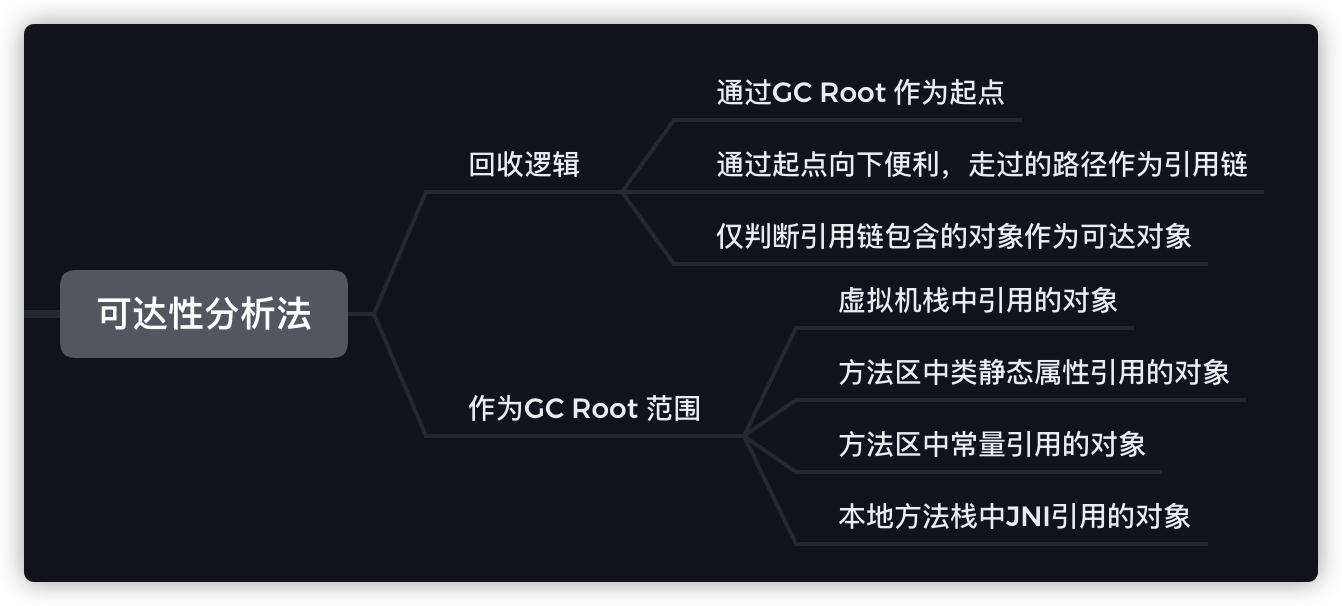
可达性分析解决了循环引用的缺点,使用一个GC Root 作为起点,分析对象引用链上是否包含 GC Root,包含说明在使用,不包含就能回收。
所以经常会遇到一个问题:A B 两个对象相互引用,这两个对象是否会被回收?该问题的关键不在于A B两对象相互引用,在与其引用链上是否有GC Root,有的话不会被回收,没有就会被回收。
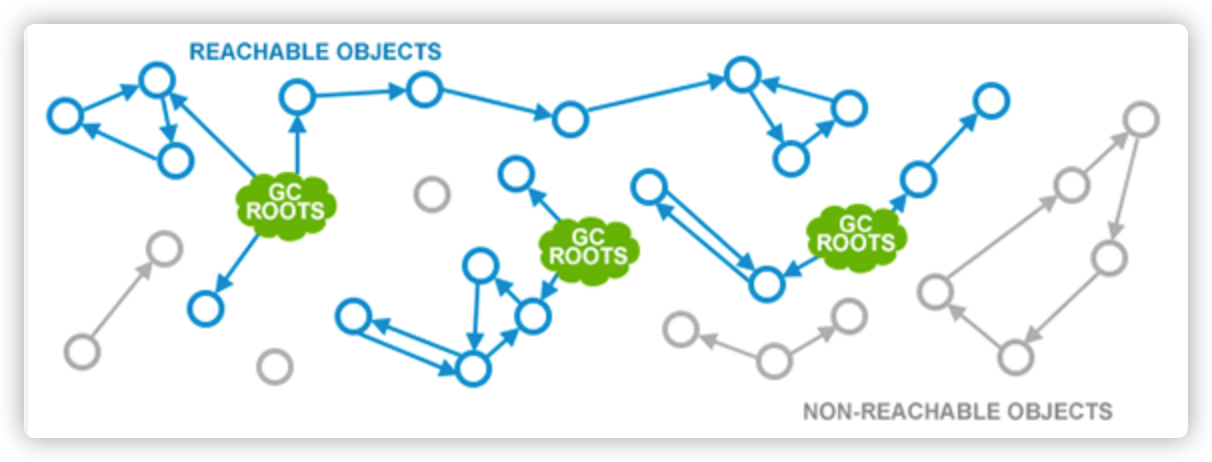
上图蓝色部分都包含GC Root,所以蓝色部分不会被回收,而灰色部分会被回收。
需要GC的内存区域

在JVM内存布局中,我们知道了thread独享的区域:PC Regiester、JVM Stack、Native Method Stack,其生命周期都与线程相同(即:与线程共生死),所以无需GC。线程共享的Heap区、Method Area则是GC关注的重点对象。
GC 算法
- mark-sweep 标记清除法
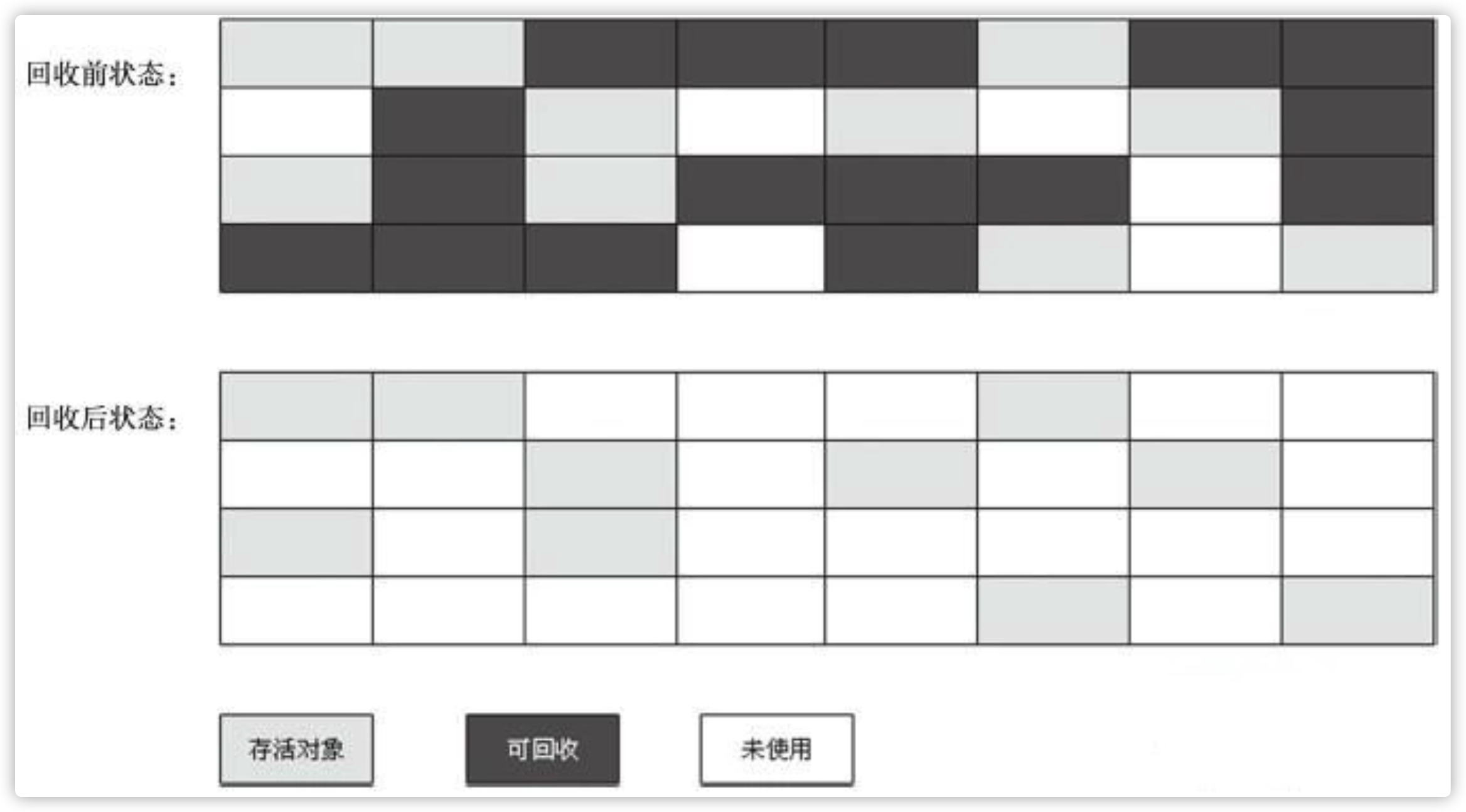
上图黑色区域表示待清理的垃圾对象,标记出来后直接清空,该方法简单粗暴,但是有明显的缺点,回收后会产生大量内存碎片。
- mark-copy 标记复制法
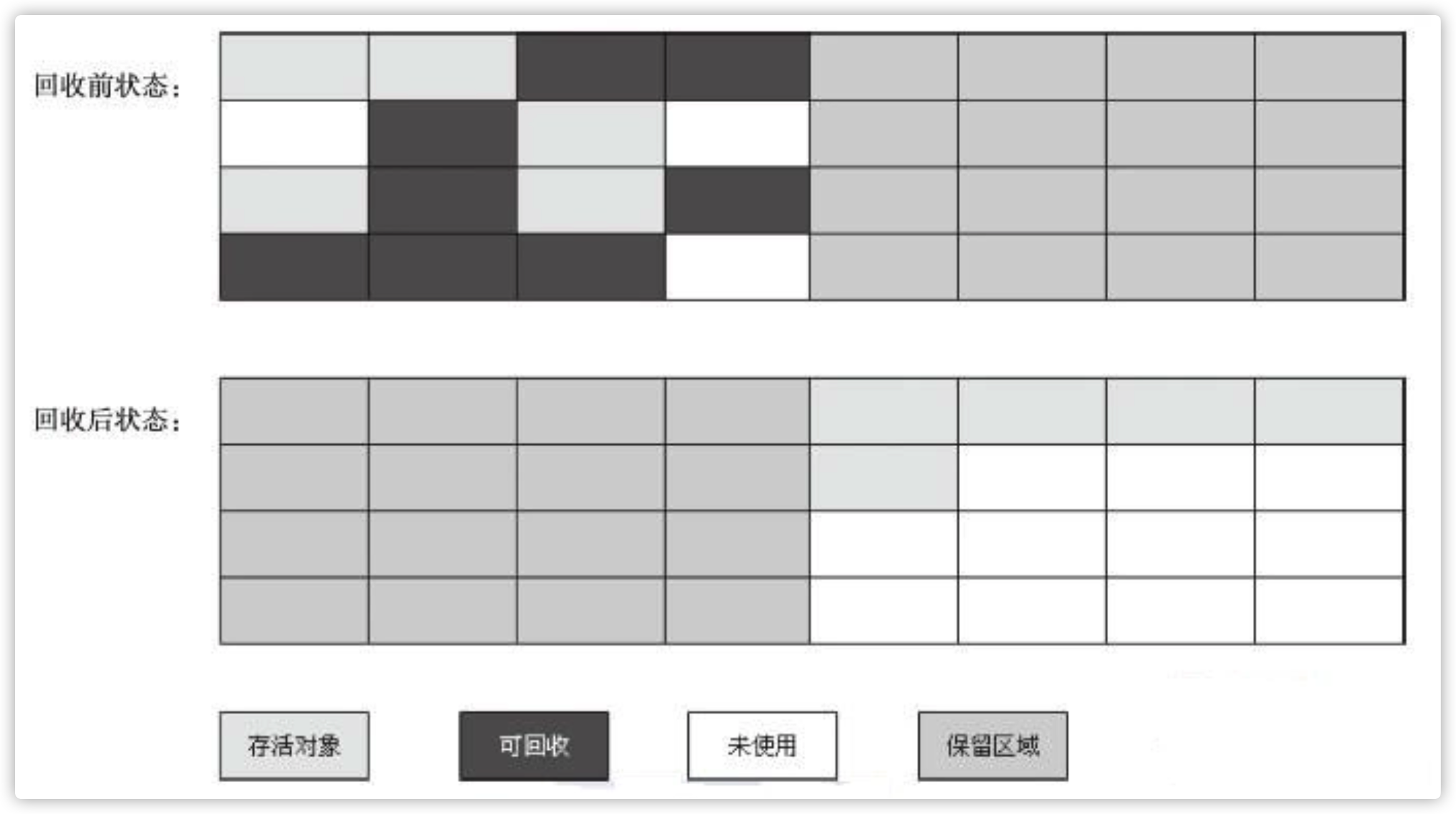
该方法就是将内存对半分,总是保留一块内存处于空状态,将另一半中存活的对象全部复制到空的内存中去,然后清理所有,这样另一半又变成空状态,该方法解决了内存碎片问题,但是其自身永远有一半内存处于空闲状态,导致内存浪费严重。
- mark-compact 标记-整理法
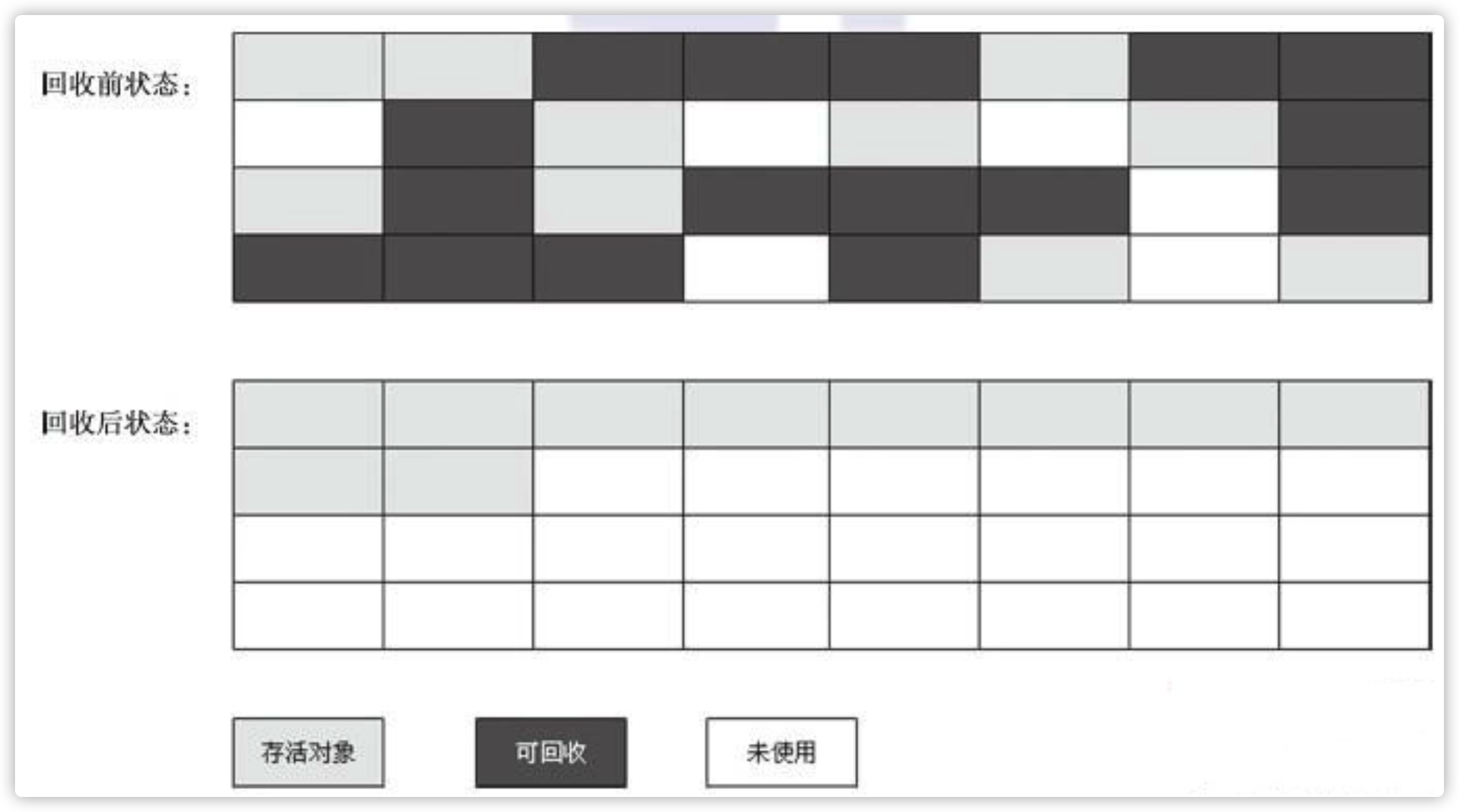
该方法为了解决前两种方法不足产生的,将垃圾对象清理后,在将剩下可用对象进行内存移动,让使用的内存空间连续,这样就解决了内存碎片问题,但是移动可用对象的过程又大大降低了GC效率,所以其缺点就是效率太低。
- generation-collect 分代收集算法
上述三种方法都有各自的优缺点,在现代JVM中,往往都是综合使用,经过大量实际分析,发现内存中的对象大致分为两类:有些生命周期很短,比如局部变量/临时对象。而另外一些存活很久,比如websocket长连接中的connection 对象。大部分对象都属于前者,很少有对象在GC后存活下来,所以诞生了分代思想。以JDK7 Hotspot 为例子:
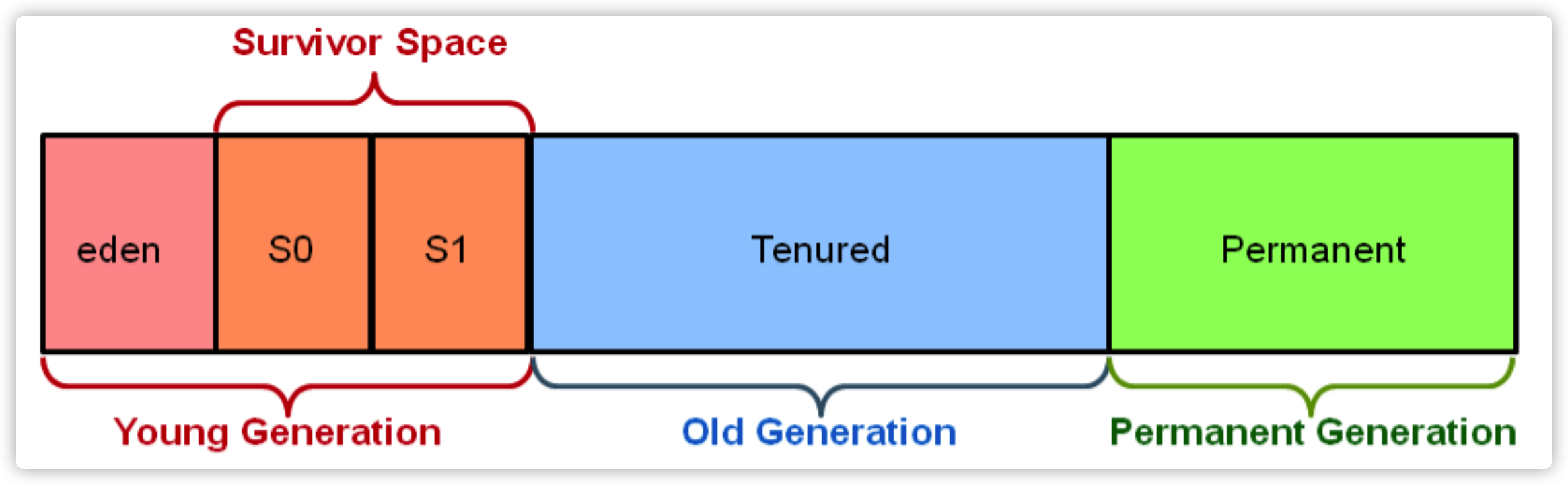
将内存分成了三大块:
- 年青代(Young Genaration)(eden,S0,S1三个区)
- 老年代(Old Generation)
- 永久代(Permanent Generation)
(JDK7)对应的JVM相关参数:
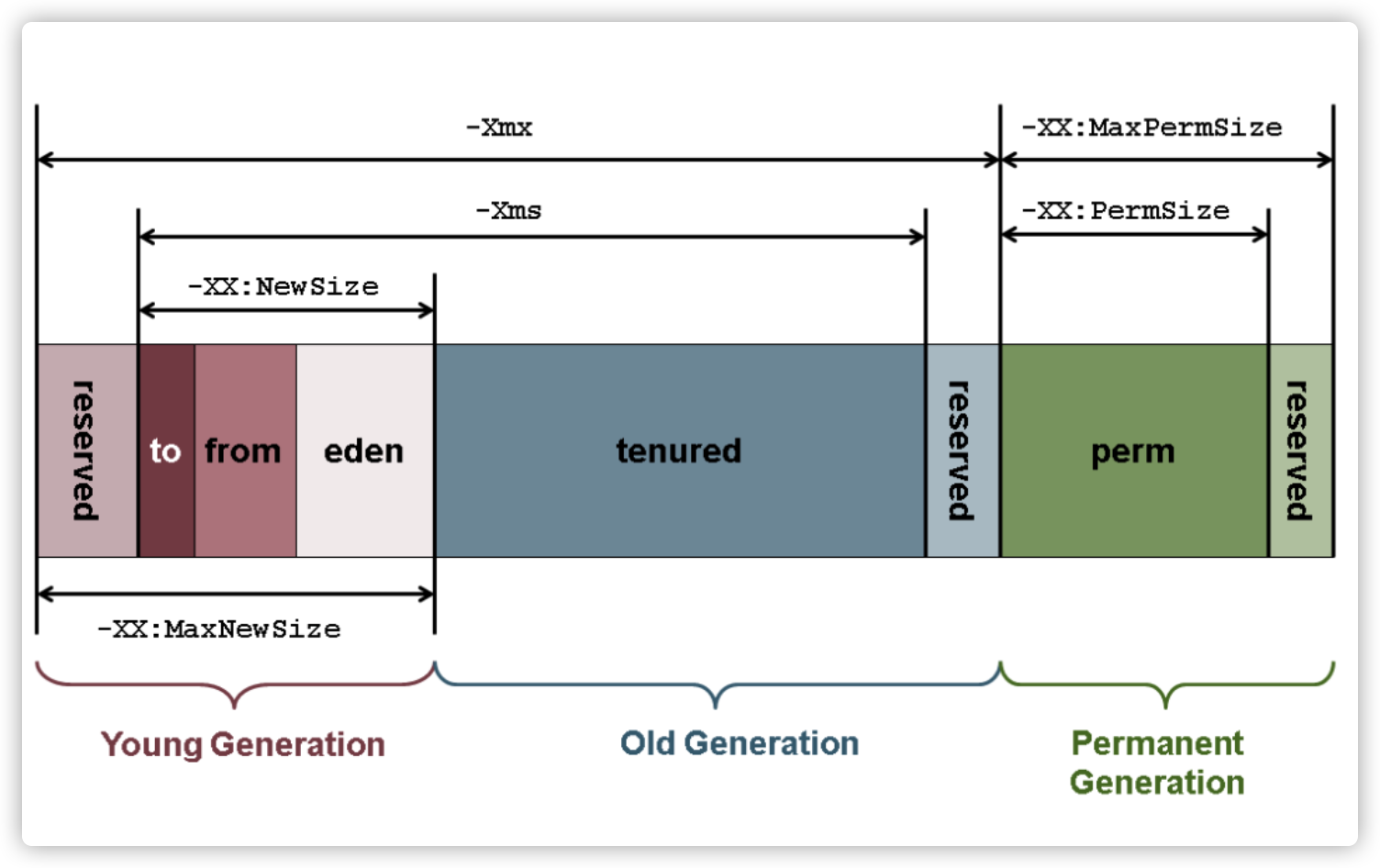
从JDK8开始,用MetaSpace区取代了Perm区(永久代),所以相应的jvm参数变成-XX:MetaspaceSize 及 -XX:MaxMetaspaceSize。
Hotspot GC 全过程
-
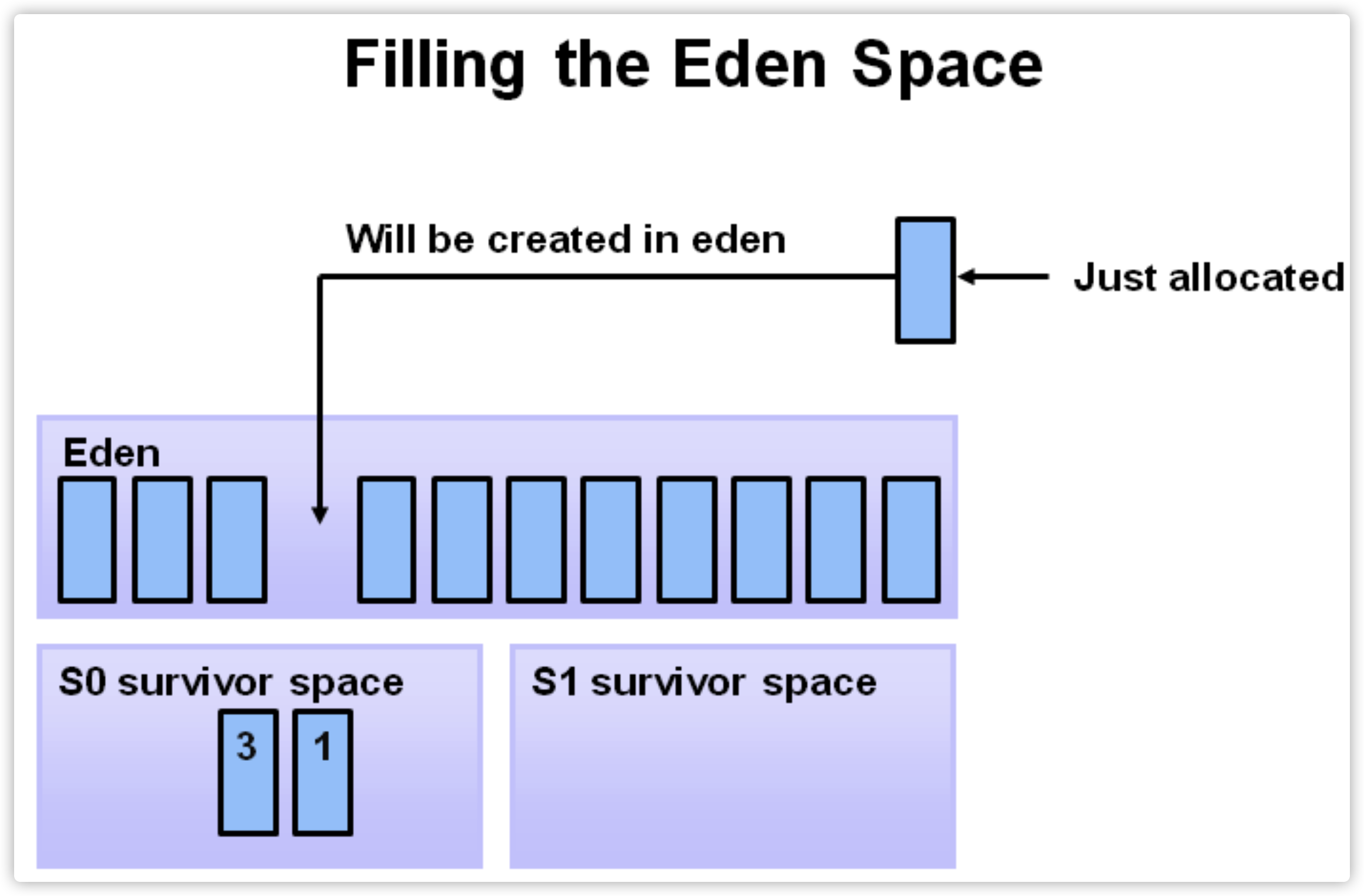
开始时,对象分配在eden区,S0(图中from区域)以及 S1(图中to区域)几乎空着。

-
引用运行,越来越多对象分配在eden区域
-
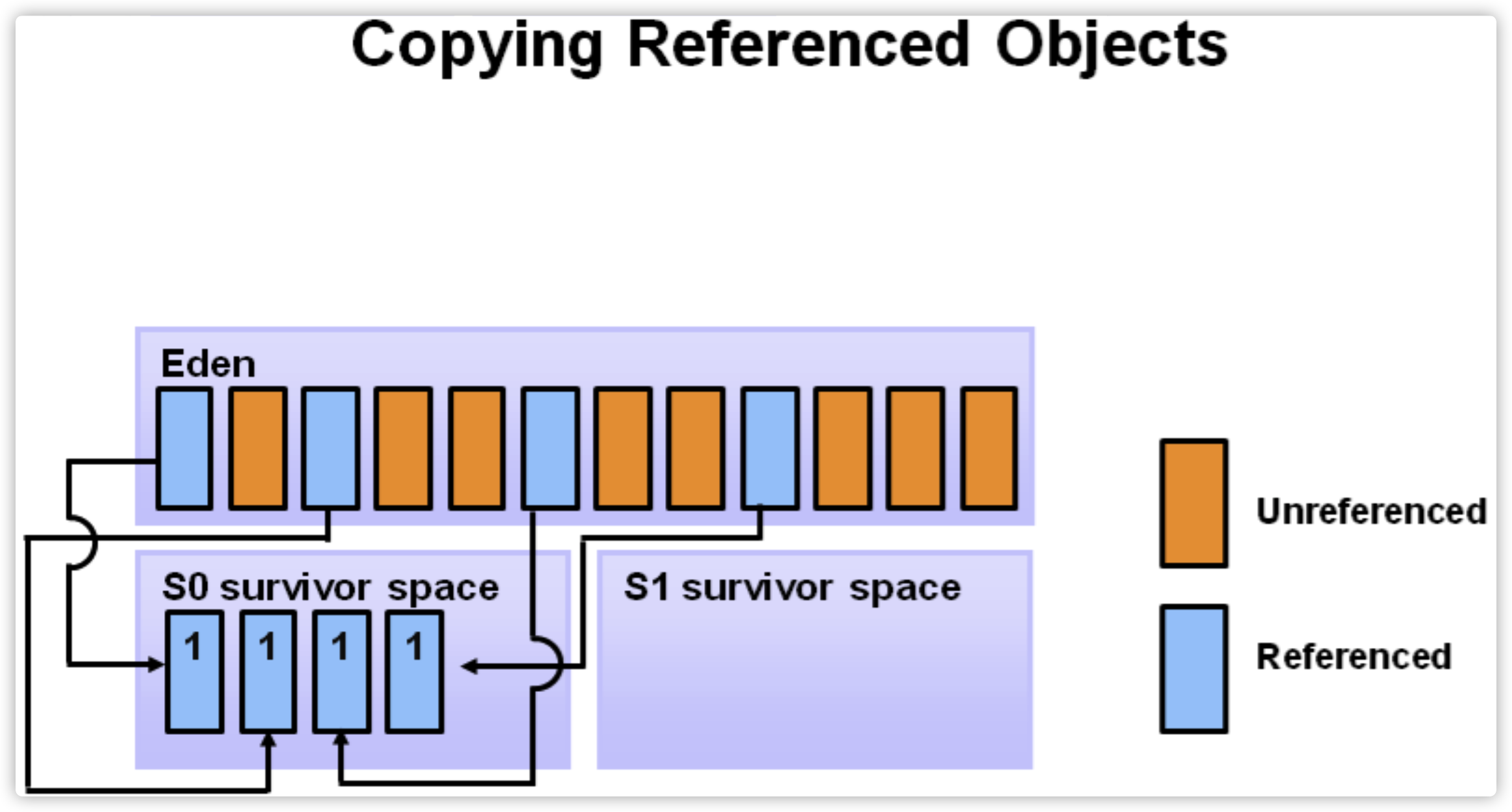
当eden区域放不下时,就会发生minor GC(young GC),利用可达性分析标记出垃圾对象(下图中黄色区域),然后将有用对象移动到S0区域(图中4个淡蓝色方框),将标记出来的垃圾对象全部清除,此时eden区域就全部清理干净了。整个过程使用了 mark-sweep方法回收eden区,使用mark-copy 方法将可用对象移动到 S0区域。
-
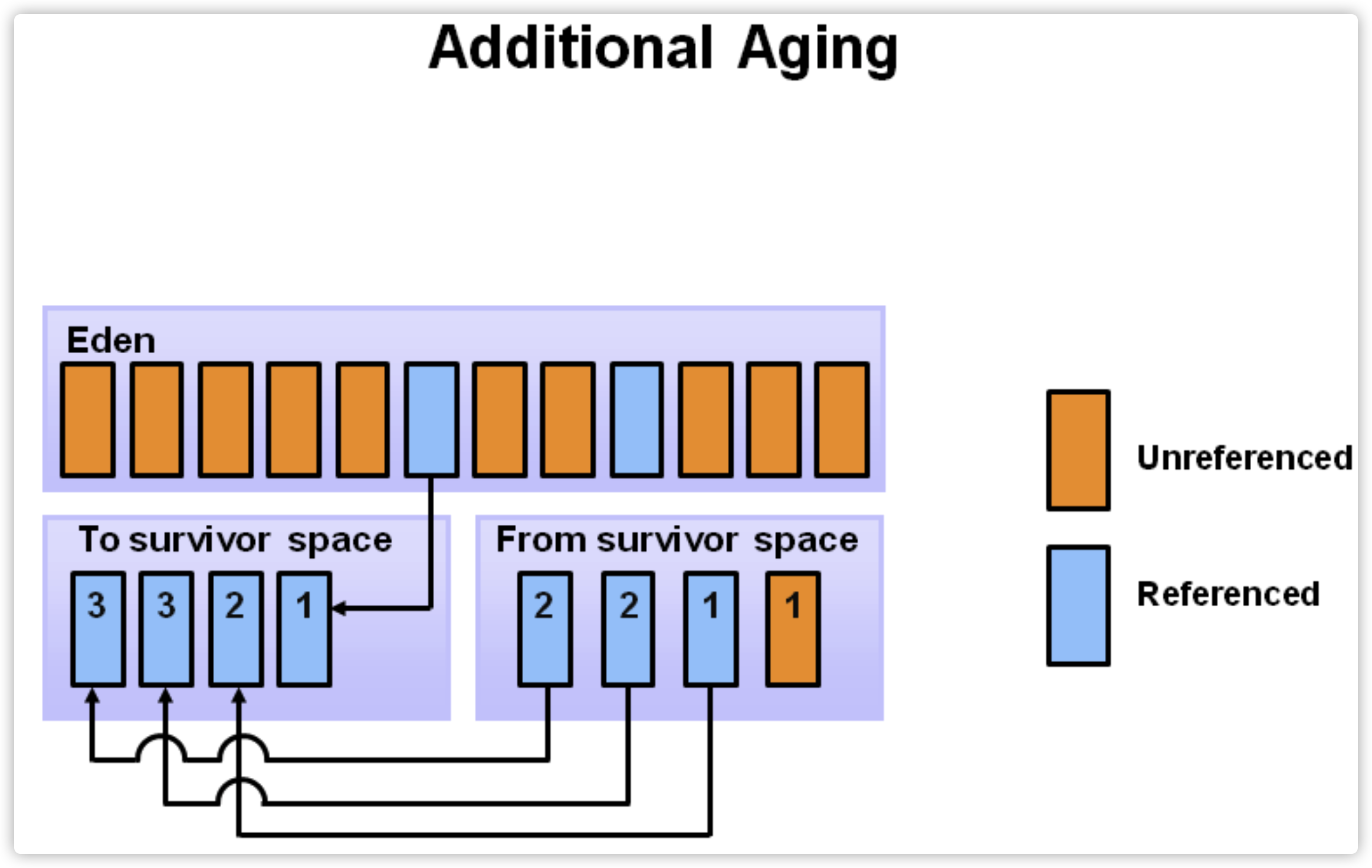
随着时间推移,eden如果又满了,再次触发minor GC,同样还是先做标记,这时eden和s0区可能都有垃圾对象了(下图中的黄色块),注意:这时s1(即:to)区是空的,S0区和eden区的存活对象(S0 区域满了),将直接搬到s1区。然后将eden和S0区的垃圾清理掉,这一轮minor GC后,eden和S0区就变成了空的了。
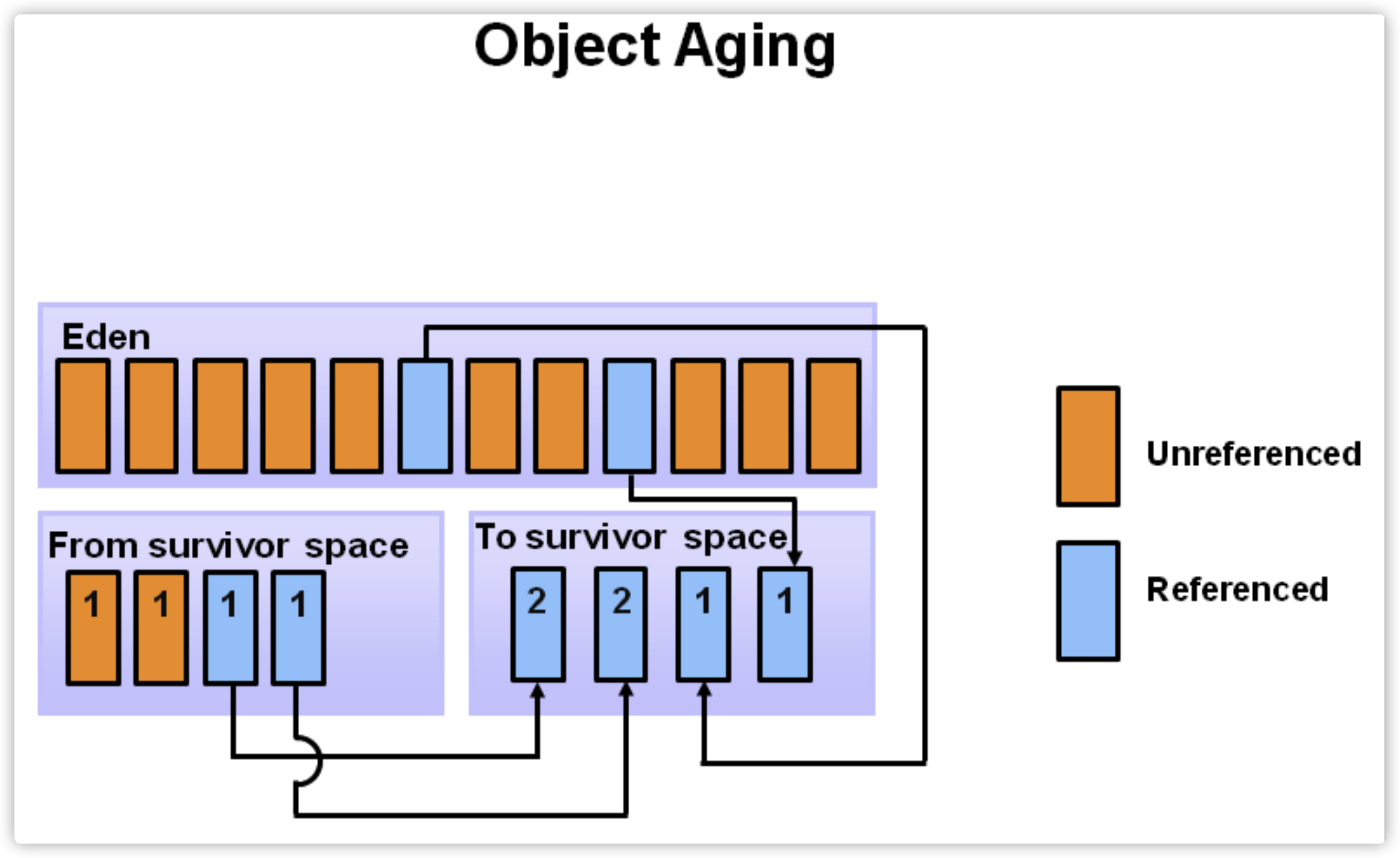
-
随着对象的不断分配,eden空可能又满了,这时会重复刚才的minor GC过程,不过要注意的是,这时候s0是空的,所以s0与s1的角色其实会互换,即:存活的对象,会从eden和s1区,向s0区移动。然后再把eden和s1区中的垃圾清除,这一轮完成后,eden与s1区变成空的,如下图。
-
对于那些比较“长寿”的对象一直在s0与s1中挪来挪去,一来很占地方,而且也会造成一定开销,降低gc效率,于是有了“代龄(age)”及“晋升”。
对象在年青代的3个区(edge,s0,s1)之间,每次从1个区移到另1区,年龄+1,在young区达到一定的年龄阈值(-XX:MaxTenuringThreshold)后,将晋升到老年代。下图中是8,即:挪动8次后,如果还活着,下次minor GC时,将移动到Tenured区。
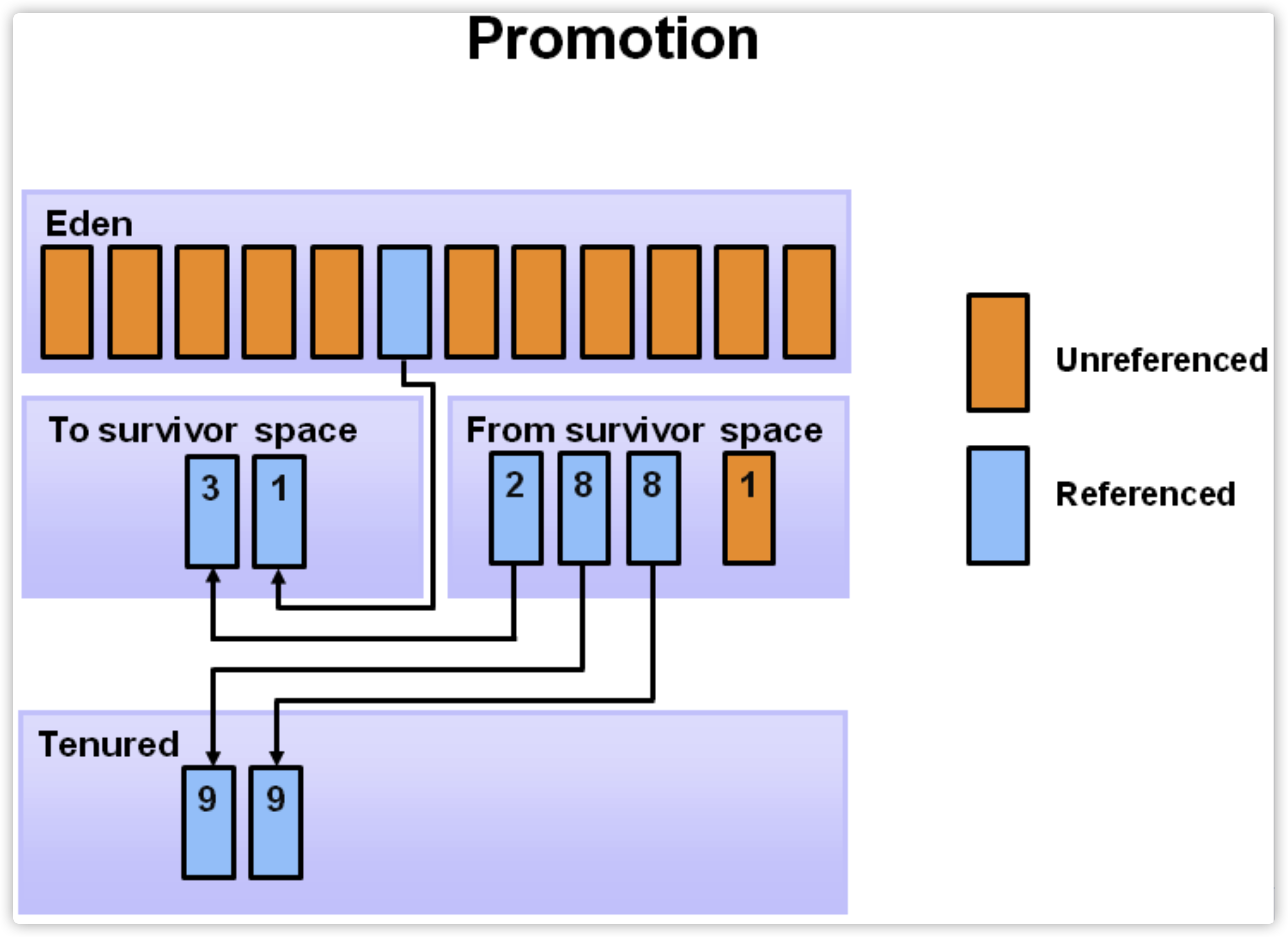 7. 对象先分配在年青代,经过多次Young GC后,如果对象还活着,晋升到老年代。
7. 对象先分配在年青代,经过多次Young GC后,如果对象还活着,晋升到老年代。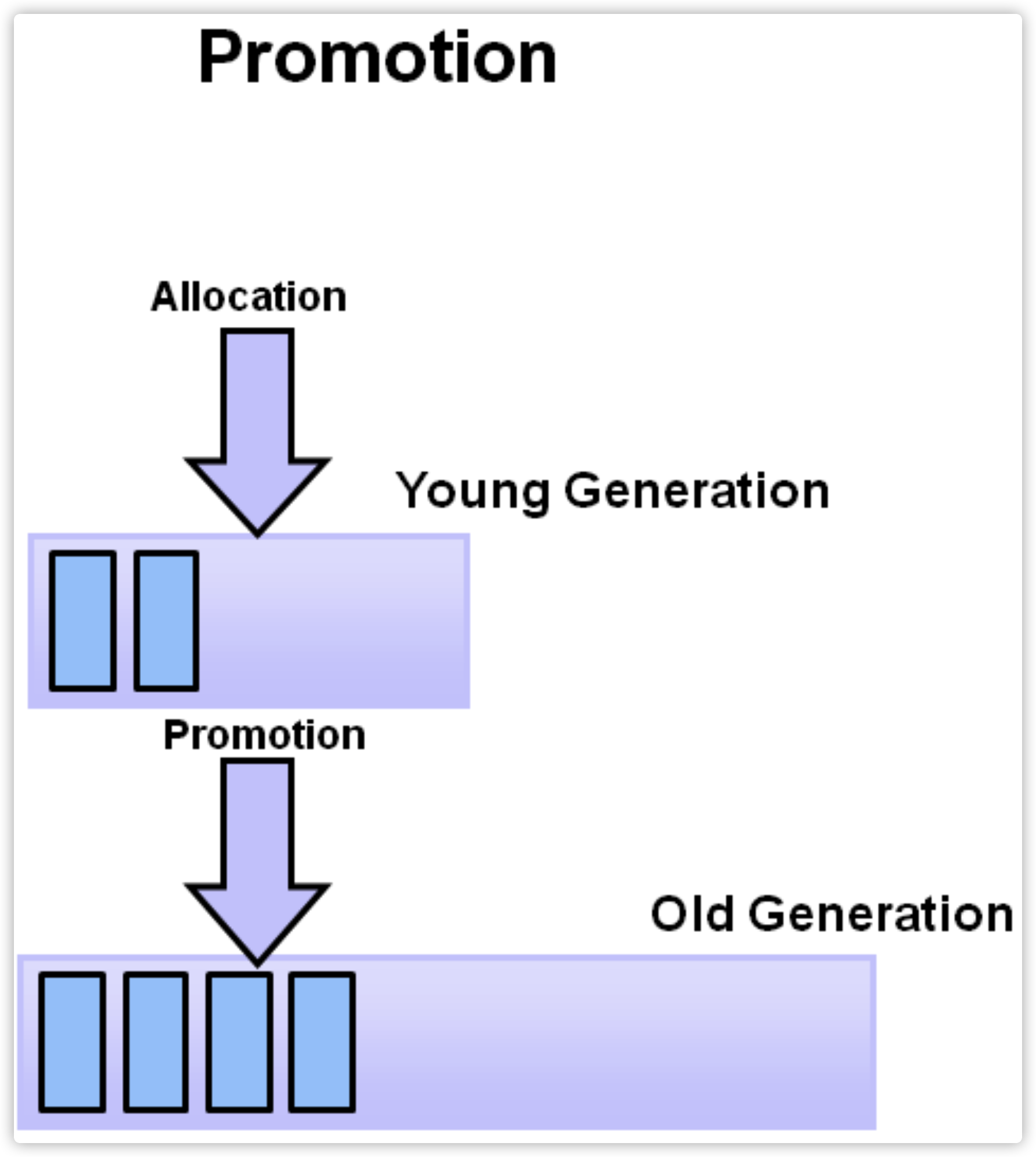
-
如果老年代,最终也放满了,就会发生major GC(即Full GC),由于老年代的的对象通常会比较多,因为标记-清理-整理(压缩)的耗时通常会比较长,会让应用出现卡顿的现象,这也是为什么很多应用要优化,尽量避免或减少Full GC的原因。
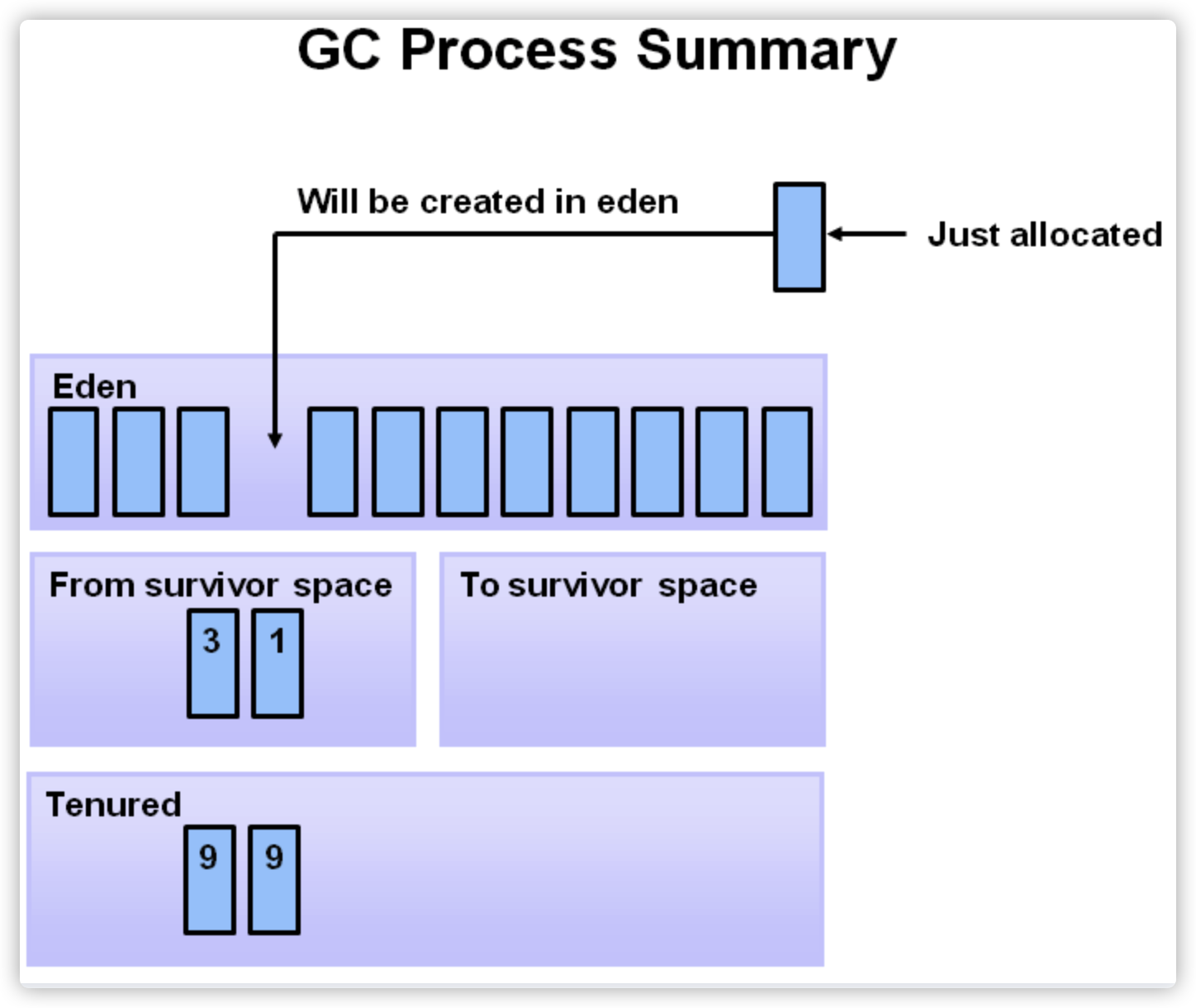
上述所有流程为oracle官网提供,但是其他晋升为老年代的方式没有提到:
- 大对象会跨过年轻代直接分配到老年代。可以通过-XX:PretenureSizeThreshold参数设置对象大小。如果参数被设置成5MB,超过5MB的大对象会直接分配到老年代。这样做的目的,是为了避免大对象在Eden区及两个Survivor区之间大量的内存复制,大对象的内存复制耗时比普通对象要高很多。
- 动态对象年龄判定。如果在Survivor空间中相同年龄对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象会直接进入老年代,而不用等到MaxTenuringThreshold中设置的年龄上限。上图,年龄为1的对象超过了Survivor空间的一半,所以这几个对象会直接进入老年代。
借助《码出高效-Java开发手册》一书中流程图看下整个GC过程:
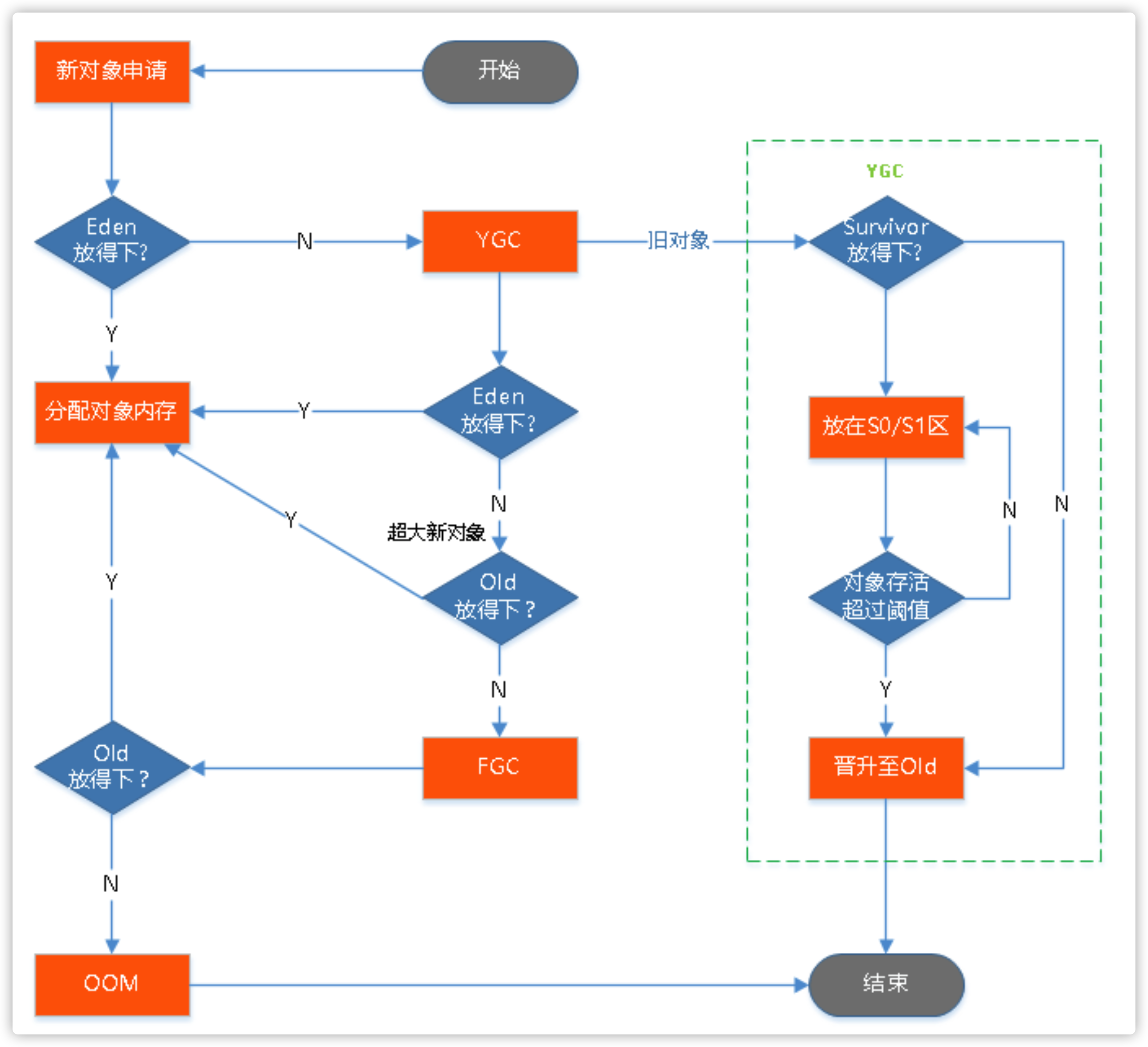
垃圾回收器
不算最新的ZGC垃圾回收器,历史上出现过7种经典的垃圾回收器。
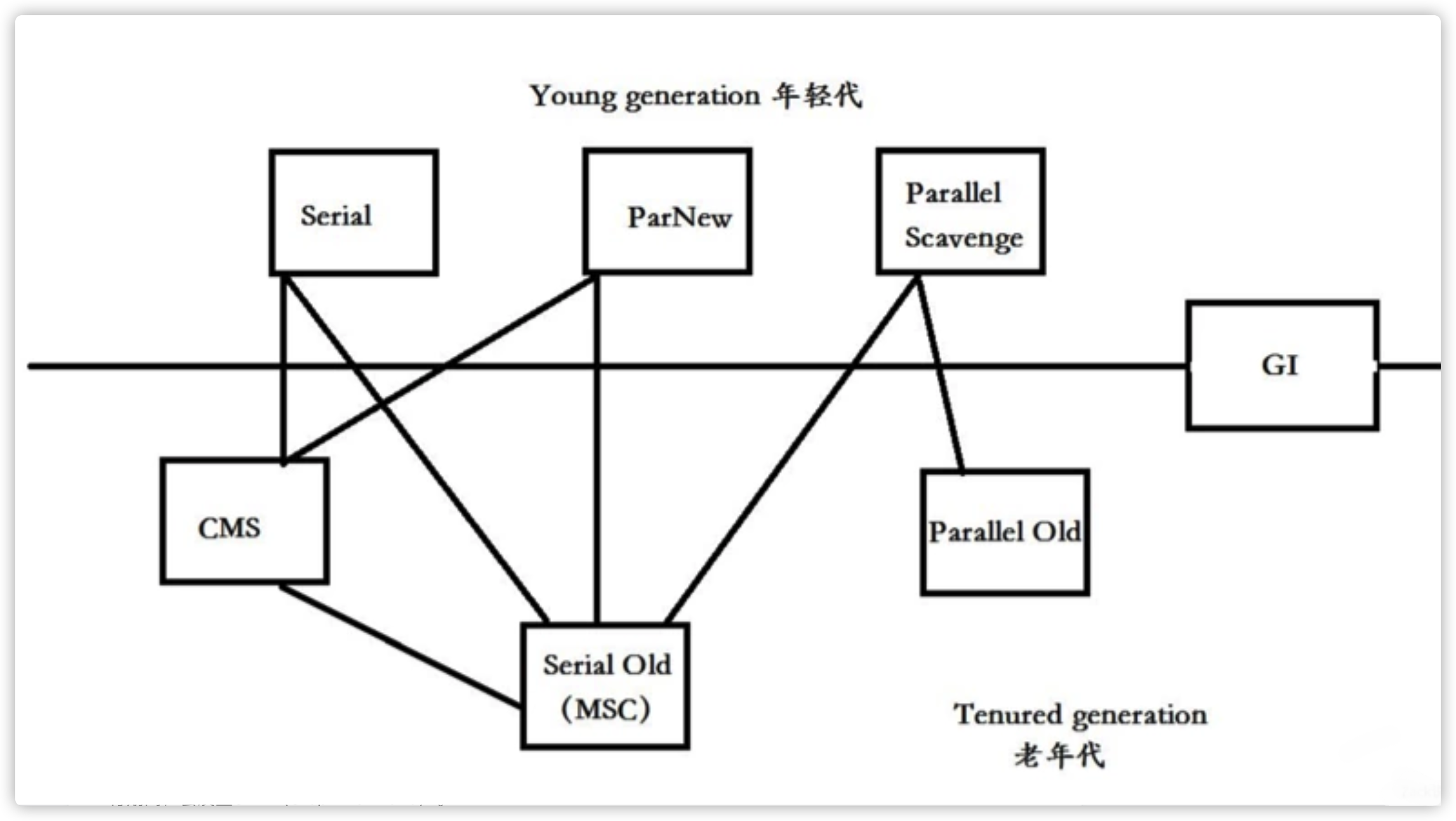
这些回收器都是基于分代的,把G1除外,按回收的分代划分,横线以上的3种:Serial ,ParNew, Parellel Scavenge都是回收年青代的,横线以下的3种:CMS,Serial Old, Parallel Old 都是回收老年代的。
Serial 收集器
单线程用标记-复制算法,快刀斩乱麻,单线程的好处避免上下文切换,早期的机器,大多是单核,也比较实用。但执行期间,会发生STW(Stop The World)。
ParNew 收集器
Serial的多线程版本,同样会STW,在多核机器上会更适用。
Parallel Scavenge 收集器
ParNew的升级版本,主要区别在于提供了两个参数:-XX:MaxGCPauseMillis 最大垃圾回收停顿时间;-XX:GCTimeRatio 垃圾回收时间与总时间占比,通过这2个参数,可以适当控制回收的节奏,更关注于吞吐率,即总时间与垃圾回收时间的比例。
Serial Old 收集器
因为老年代的对象通常比较多,占用的空间通常也会更大,如果采用复制算法,得留50%的空间用于复制,相当不划算,而且因为对象多,从1个区,复制到另1个区,耗时也会比较长,所以老年代的收集,通常会采用“标记-整理”法。从名字就可以看出来,这是单线程(串行)的, 依然会有STW。
Parallel Old 收集器
一句话:Serial Old的多线程版本。
CMS 收集器
Concurrent Mark Sweep,从名字上看,就能猜出它是并发多线程的。这是JDK 7中广泛使用的收集器,有必要多说一下:
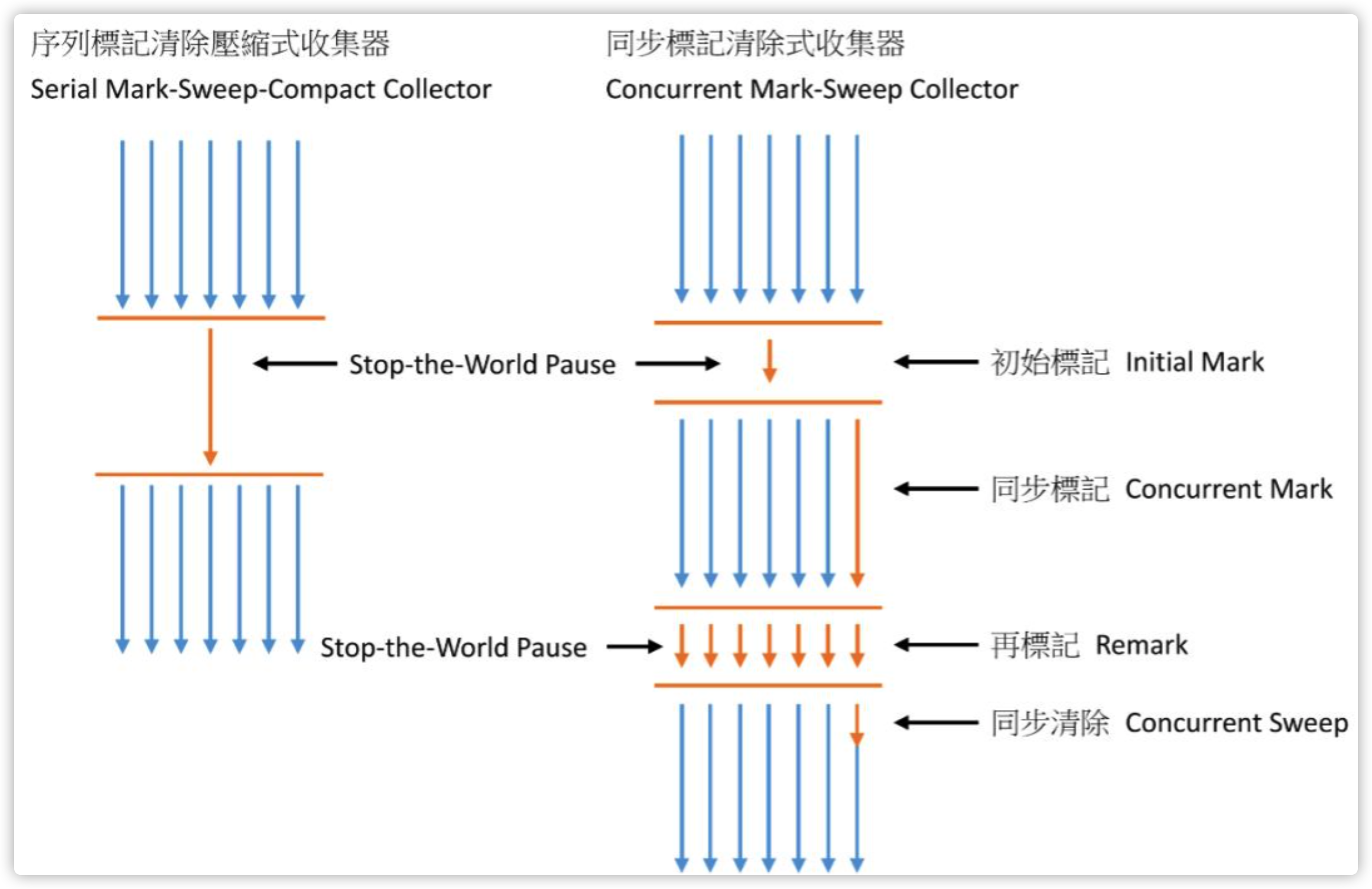
相对 Serial Old收集器或 Parallel Old收集器而言,这个明显要复杂多了,分为4个阶段:
-
Inital Mark 初始标记:主要是标记GC Root开始的下级(注:仅下一级)对象,这个过程会STW,但是跟GC Root直接关联的下级对象不会很多,因此这个过程其实很快。
-
Concurrent Mark 并发标记:根据上一步的结果,继续向下标识所有关联的对象,直到这条链上的最尽头。这个过程是多线程的,虽然耗时理论上会比较长,但是其它工作线程并不会阻塞,没有STW。
-
Remark 再标志:为啥还要再标记一次?因为第2步并没有阻塞其它工作线程,其它线程在标识过程中,很有可能会产生新的垃圾。试想下,保洁阿姨从走廊过道开始默默地将每个工位垃圾清理出来,从开始清理到清理完这个过程中,有的工位上又有垃圾产生了,所以,要完全把垃圾清理干净,她应该喊一下:所有员工不要再扔垃圾了(STW),然后把新产生的垃圾收走。当然,因为刚才已经把收过一遍垃圾,所以这次收集新产生的垃圾,用不了多长时间(即:STW时间不会很长)。
-
Concurrent Sweep:并行清理,这里使用多线程以“Mark Sweep-标记清理”算法,把垃圾清掉,其它工作线程仍然能继续支行,不会造成卡顿。
刚才我们不是提到过“标记清理”法,会留下很多内存碎片吗?确实,但是也没办法,如果换成“Mark Compact标记-整理”法,把垃圾清理后,剩下的对象也顺便排整理,会导致这些对象的内存地址发生变化,别忘了,此时其它线程还在工作,如果引用的对象地址变了,就天下大乱了。
另外,由于这一步是并行处理,并不阻塞其它线程,所以还有一个副使用,在清理的过程中,仍然可能会有新垃圾对象产生,只能等到下一轮GC,才会被清理掉。虽然仍不完美,但是从这4步的处理过程来看,以往收集器中最让人诟病的长时间STW,通过上述设计,被分解成二次短暂的STW,所以从总体效果上看,应用在GC期间卡顿的情况会大大改善,这也是CMS一度十分流行的重要原因。
G1 收集器
G1的全称是Garbage-First,为什么叫这个名字,呆会儿会详细说明。鉴于CMS的一些不足之外,比如: 老年代内存碎片化,STW时间虽然已经改善了很多,但是仍然有提升空间。G1就横空出世了,它对于heap区的内存划思路很新颖,有点算法中分治法“分而治之”的味道。如下图:
 G1将heap内存区,划分为一个个大小相等(1-32M,2的n次方)、内存连续的Region区域,每个region都对应Eden、Survivor 、Old、Humongous四种角色之一,但是region与region之间不要求连续。所有的垃圾回收,都是基于1个个region的。JVM内部知道,哪些region的对象最少(即:该区域最空),总是会优先收集这些region(因为对象少,内存相对较空,肯定快),这也是Garbage-First得名的由来,G即是Garbage的缩写, 1即First。
G1将heap内存区,划分为一个个大小相等(1-32M,2的n次方)、内存连续的Region区域,每个region都对应Eden、Survivor 、Old、Humongous四种角色之一,但是region与region之间不要求连续。所有的垃圾回收,都是基于1个个region的。JVM内部知道,哪些region的对象最少(即:该区域最空),总是会优先收集这些region(因为对象少,内存相对较空,肯定快),这也是Garbage-First得名的由来,G即是Garbage的缩写, 1即First。
注:Humongous,简称H区是专用于存放超大对象的区域,通常>= 1/2 Region Size,且只有Full GC阶段,才会回收H区,避免了频繁扫描、复制/移动大对象。
young GC前: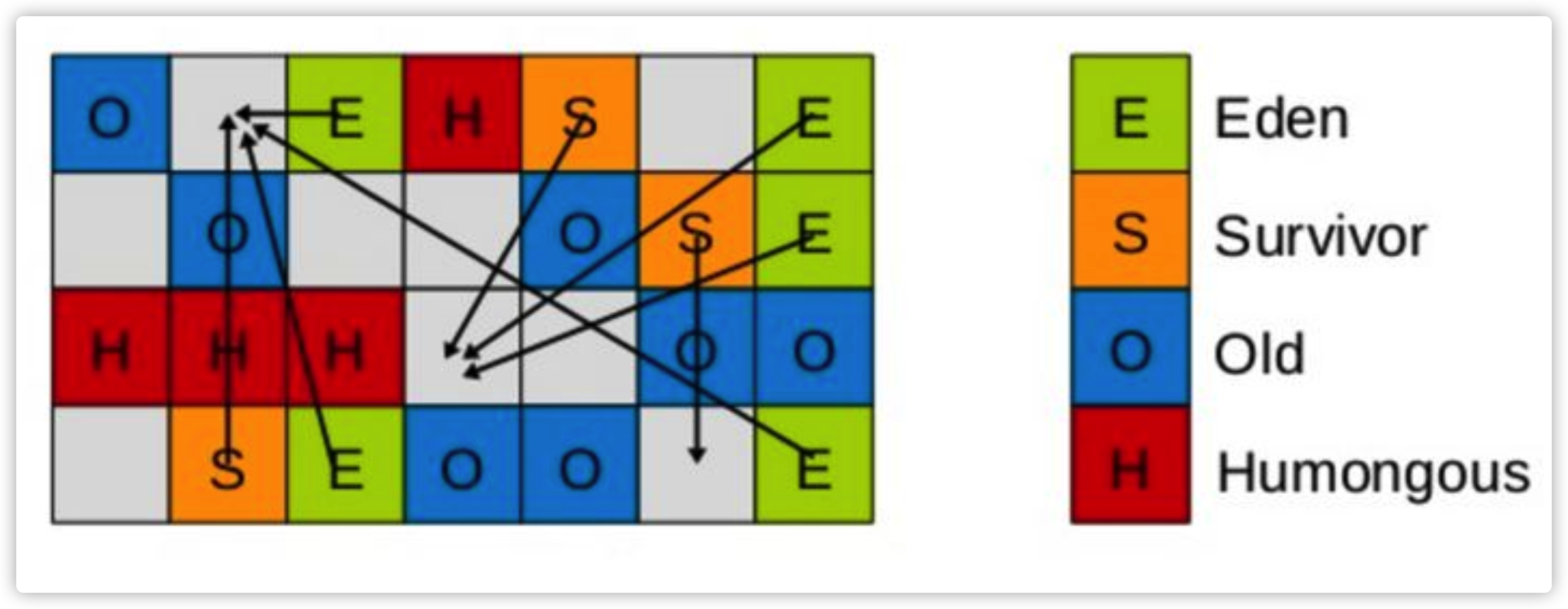
young GC后: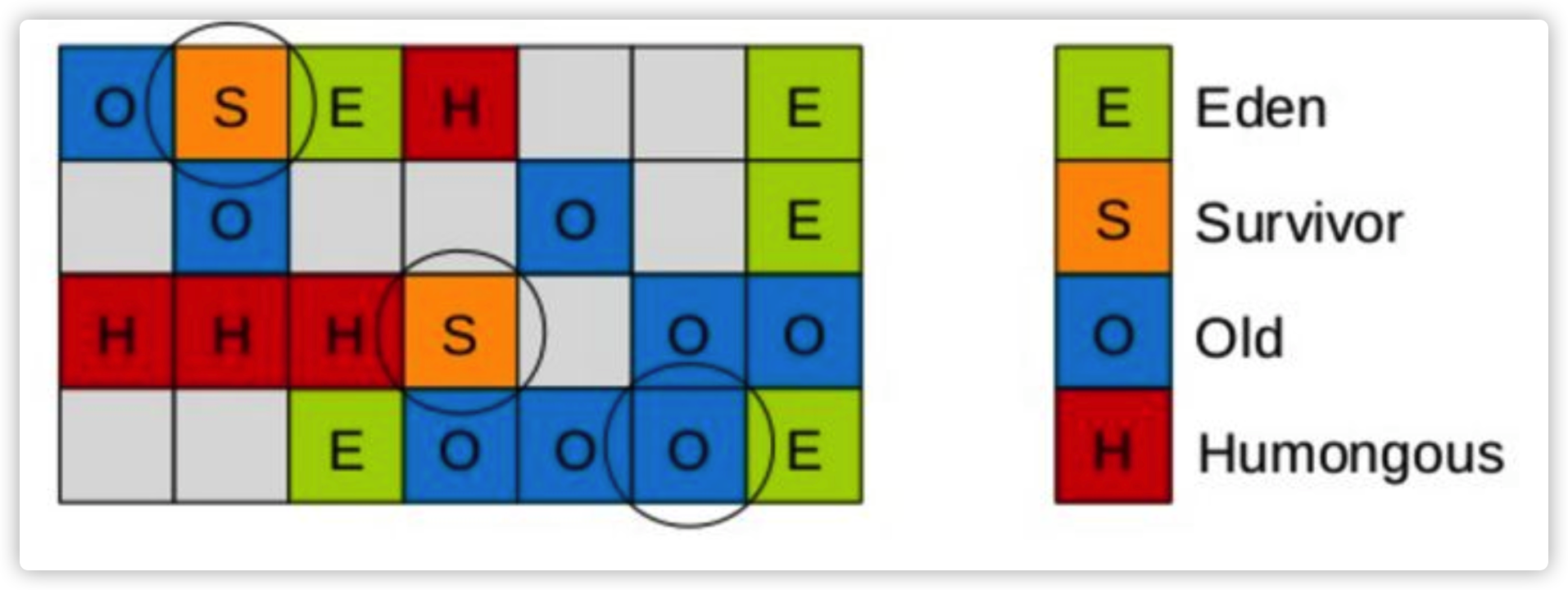
由于region与region之间并不要求连续,而使用G1的场景通常是大内存,比如64G甚至更大,为了提高扫描根对象和标记的效率,G1使用了二个新的辅助存储结构:
Remembered Sets:简称RSets,用于根据每个region里的对象,是从哪指向过来的(即:谁引用了我),每个Region都有独立的RSets。
Collection Sets :简称CSets,记录了等待回收的Region集合,GC时这些Region中的对象会被回收(copied or moved)。

RSets的引入,在YGC时,将年青代Region的RSets做为根对象,可以避免扫描老年代的region,能大大减轻GC的负担。注:在老年代收集Mixed GC时,RSets记录了Old->Old的引用,也可以避免扫描所有Old区。
Old Generation Collection(也称为 Mixed GC)
按oracle官网文档描述分为5个阶段:【Initial Mark(STW) -> Root Region Scan】 -> Cocurrent Marking -> Remark(STW) -> Copying/Cleanup(STW && Concurrent)
-
Initial Mark(STW)/Root Region Scan(存活对象的“初始标记”依赖于Young GC,GC 日志中会记录成young字样)
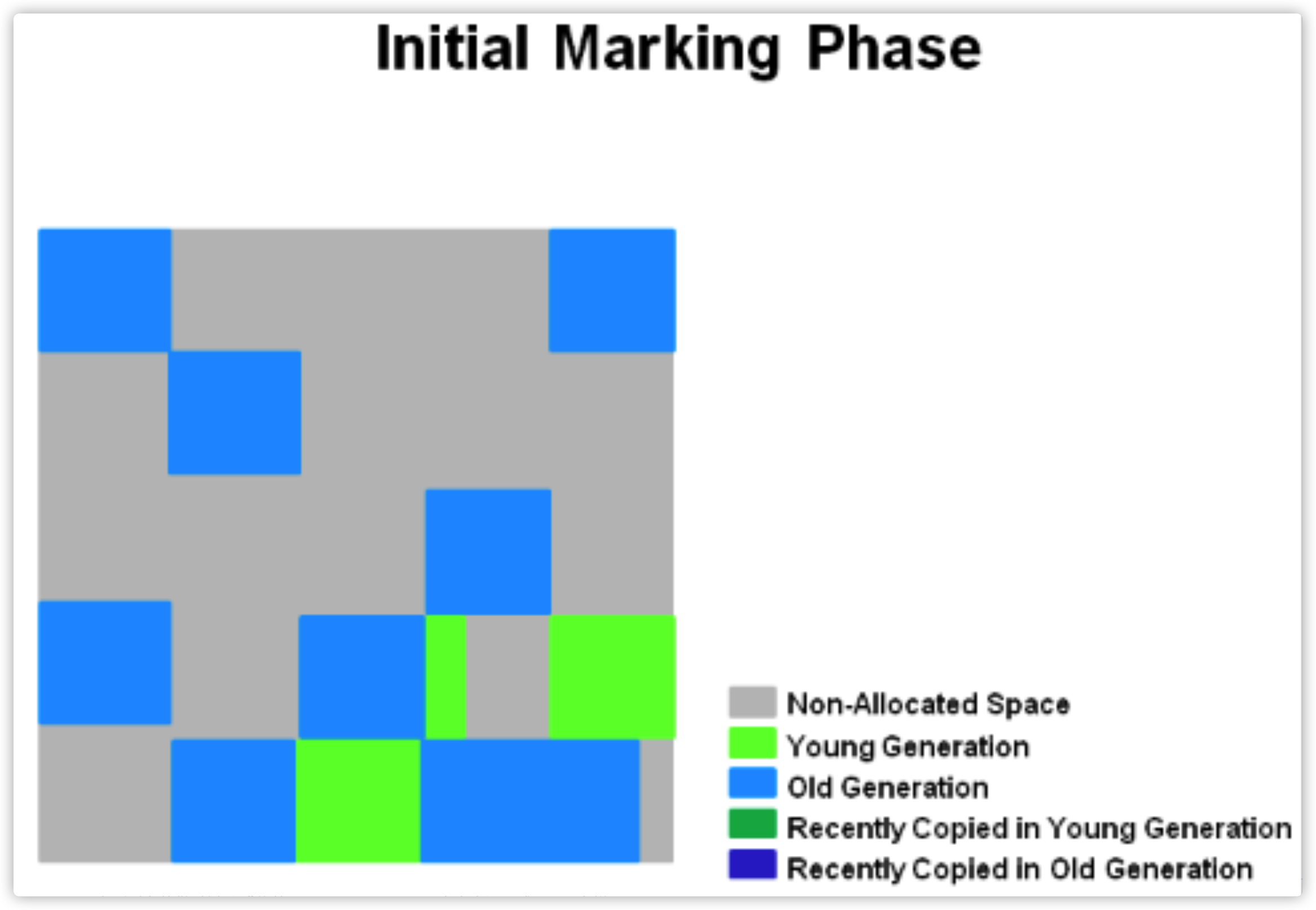
-
Cocurrent Marking (并发标记过程中,如果发现某些region全是空的,会被直接清除)
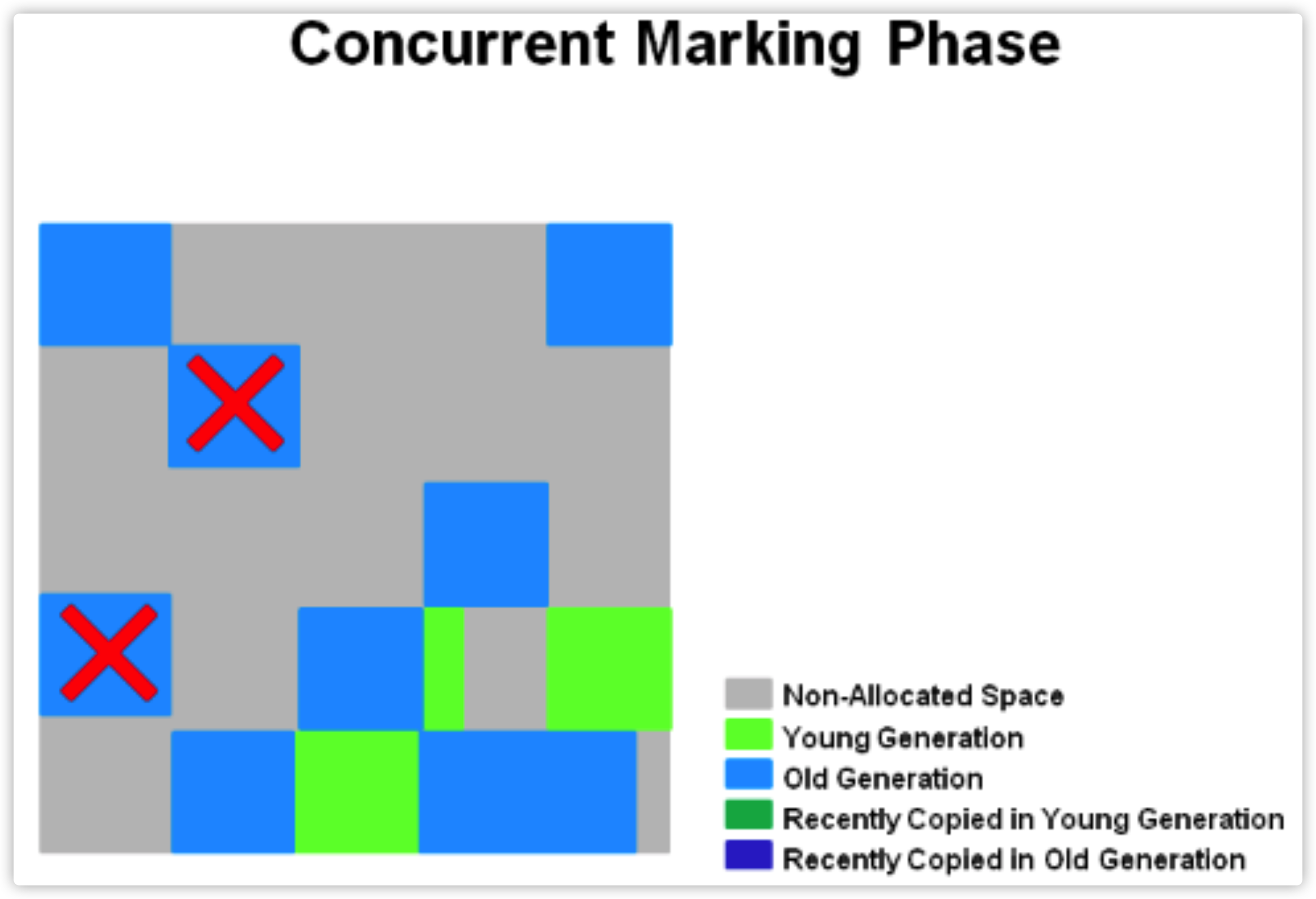
-
Remark(STW)
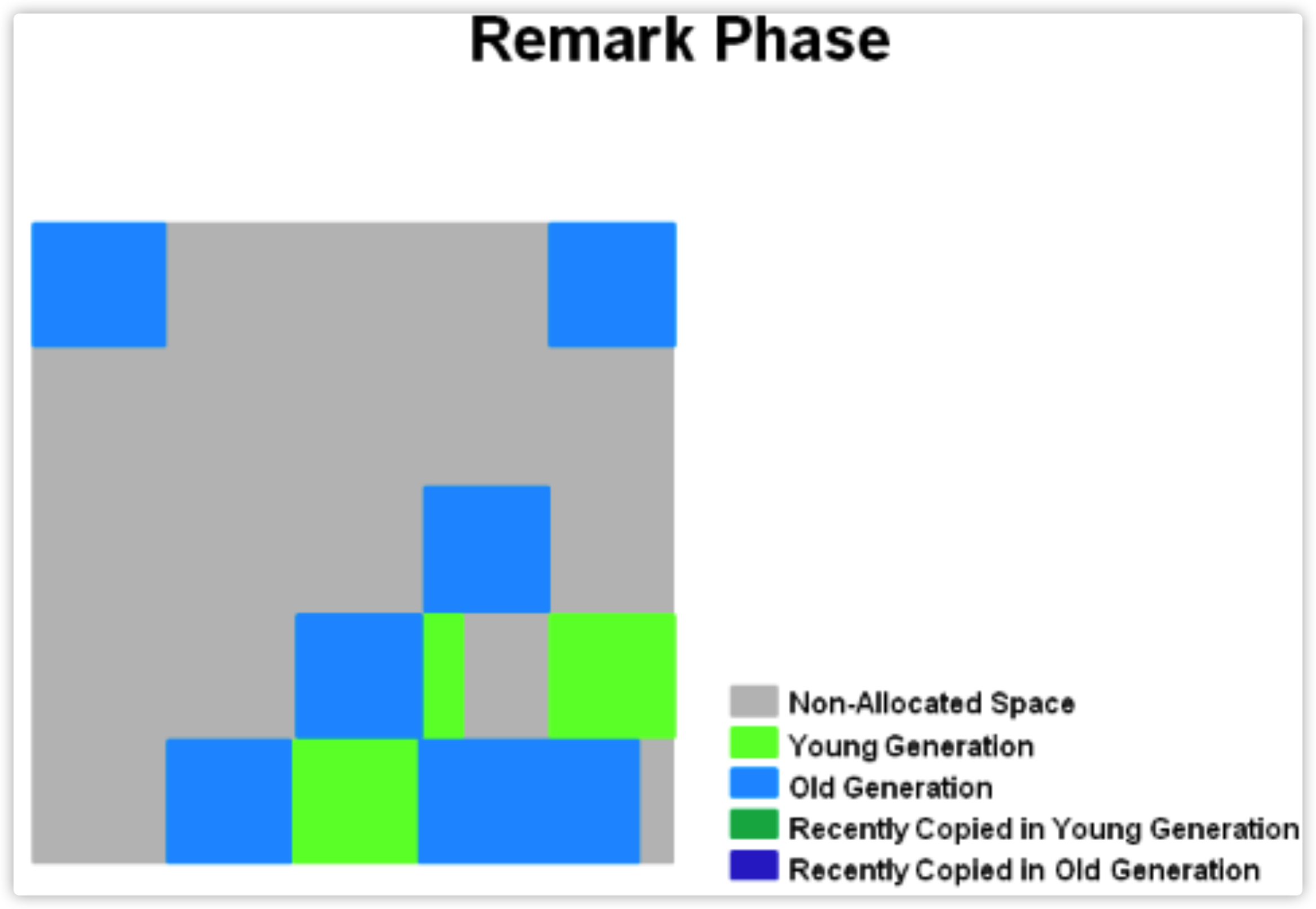
-
Copying/Cleanup(STW && Concurrent)(并发复制/清查阶段,这个阶段,Young区和Old区的对象有可能会被同时清理,GC日志中,会记录为mixed字段,这也是G1的老年代收集,也称为Mixed GC的原因)

通过这几个阶段的分析,虽然看上去很多阶段仍然会发生STW,但是G1提供了一个预测模型,通过统计方法,根据历史数据来预测本次收集,需要选择多少个Region来回收,尽量满足用户的预期停顿值(-XX:MaxGCPauseMillis参数可指定预期停顿值)。与CMS相比,G1有内存整理过程(标记-压缩),避免了内存碎片;STW时间可控(能预测GC停顿时间)。
注:如果Mixed GC仍然效果不理想,跟不上新对象分配内存的需求,会使用Serial Old GC(Full GC)强制收集整个Heap。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号