玩转Guava(二)
集合操作
guava对现有jdk 中集合进行了扩展并进行了一系列优化使集合使用起来更加方便。
不可变集合
在开发中很多时候是需要使用不可变集合,不可变集合顾名思义就是说集合是不可被修改的。集合的数据项是在创建的时候提供,并且在整个生命周期中都不可改变。比如我们在购物场景中,用户选完商品最后生成购物清单,每个商品数量和种类不可变,我们要是保存在可变集合中,当某个环节运算不小心将商品数量增加和减少我们是完全不知情的,但是使用不可变集合保存时,当出现异常增加或减少数量,此时会直接报错。
在JDK中提供了Collections.unmodifiableXXX系列方法来实现不可变集合, 但是存在一些问题:
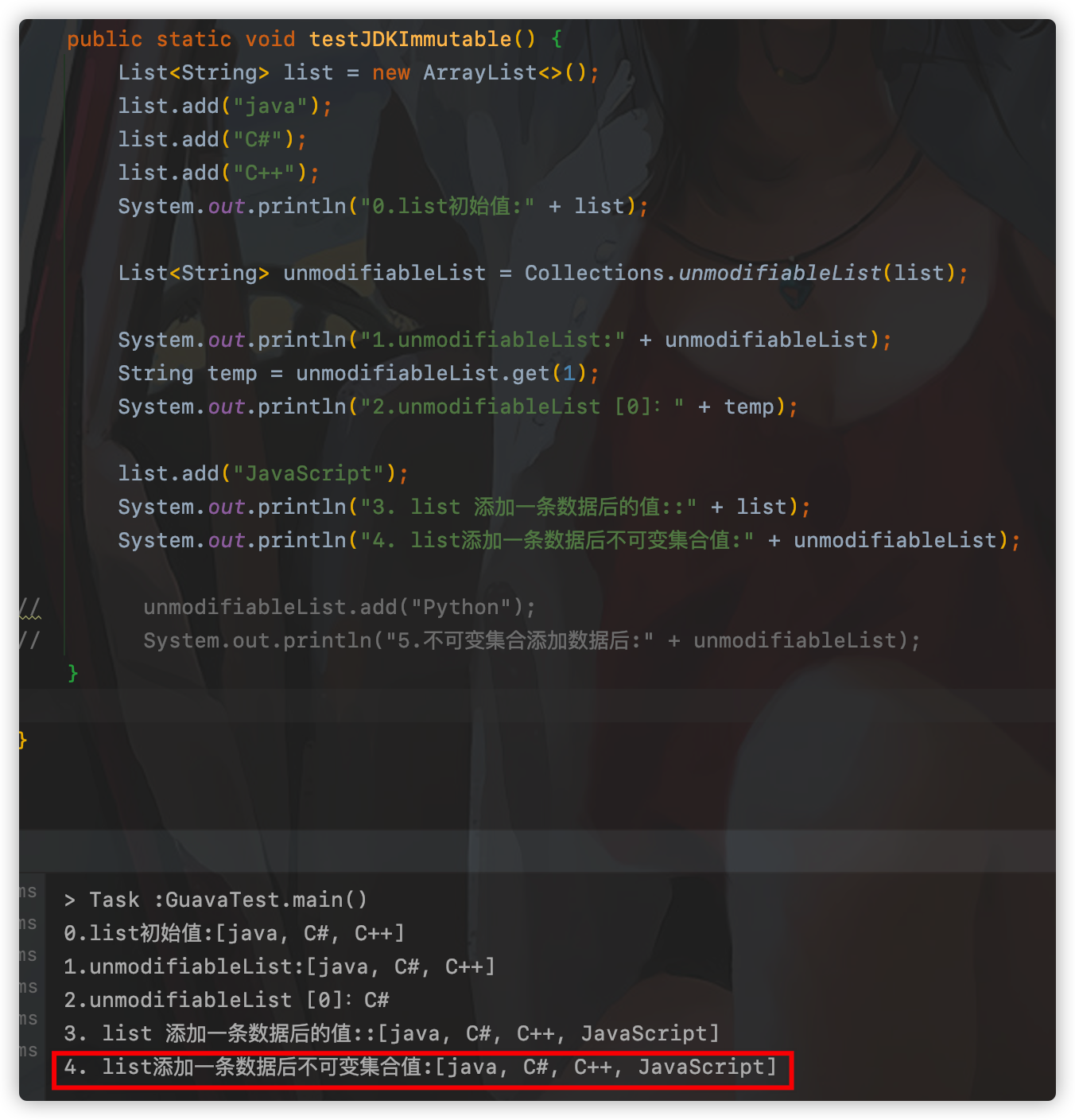
上面通过list创建不可变集合,最后通过向list里面添加数据,不可变集合也随着变化,无法达到真正的不可变集合。JDK提供的不可变集合有如下缺点:
- 笨重而且累赘:不能舒适地用在所有想做防御性拷贝的场景;
- 不安全:要保证没人通过原集合的引用进行修改,返回的集合才是事实上不可变的;
- 低效:其数据结构本质还是集合,包装过的集合仍然保有可变集合的开销,比如并发修改的检查、散列表的额外空间,等等。
所以Guava重做了不可变集合。
不可变集合可以用如下多种方式创建:
-
copyOf方法,如
ImmutableSet.copyOf(set); -
of方法,如
ImmutableSet.of(“1”, “2”, “3”)或```` ImmutableMap.of(“1”, 2, “3”, 4);``` -
Builder工具,如
public static final ImmutableSet<Language> LANGUAGE_TYPE = ImmutableSet.<Language>builder() .addAll(ASIA_LANGUAGE) .add(new EuropeLanguage("French","EN")) .build();
通常情况下我们通过copyOf 方法创建不可变集合,该方法创建不可变集合时有如下特点:
- 在常量时间内使用底层数据结构是可能的——例如,ImmutableSet.copyOf(ImmutableList)就不能在常量时间内完成。
- 不会造成内存泄露——例如,你有个很大的不可变集合ImmutableList
hugeList, ImmutableList.copyOf(hugeList.subList(0, 10))就会显式地拷贝,以免不必要地持有hugeList的引用。 - 不改变语义——所以ImmutableSet.copyOf(myImmutableSortedSet)会显式地拷贝,因为和基于比较器的ImmutableSortedSet相比,ImmutableSet对hashCode()和equals有不同语义。
Guava 不可变集合通过提供asList方法来方便读取集合元素。
新集合类型
Guava引入了很多JDK没有的、但我们发现明显有用的新集合类型。这些新类型是为了和JDK集合框架共存,而没有往JDK集合抽象中硬塞其他概念。作为一般规则,Guava集合非常精准地遵循了JDK接口契约。
Multiset
当我们往ArrayList添加元素时,我们可以放入很多重复的元素,但是当我们需要统计重复元素出现的次数时,需要遍历集合并且统计每个每个元素数量,当我们使用Multiset替换ArrayList 时我们可以很轻松拿到重复元素个数。我们如何理解Multiset呢?我们可以理解为:
-
没有元素顺序限制的ArrayList
-
Map<E, Integer>,键为元素,值为计数
当把Multiset看成普通的Collection时,我们可以将其用作ArrayList,支持所有api方法使用:
- add(E)添加单个给定元素。
- iterator()返回一个迭代器,包含Multiset的所有元素(包括重复的元素)。
- size()返回所有元素的总个数(包括重复的元素)。
当我们当把Multiset看作Map<E, Integer>时,它也提供了符合性能期望的查询操作
- count(Object)返回给定元素的计数。HashMultiset.count的复杂度为O(1),TreeMultiset.count的复杂度为O(log n)。
- entrySet()返回Set<Multiset.Entry
>,和Map的entrySet类似。 - elementSet()返回所有不重复元素的Set
,和Map的keySet()类似。 - 所有Multiset实现的内存消耗随着不重复元素的个数线性增长。
BiMap
传统上,实现键值对的双向映射需要维护两个单独的map,并保持它们间的同步。但这种方式很容易出错,而且对于值已经在map中的情况,会变得非常混乱。但是BiMap 解决了这个问题,BiMap是特殊的Map:
- 可以用 inverse()反转BiMap<K, V>的键值映射
- 保证值是唯一的,因此 values()返回Set而不是普通的Collection
- 在BiMap中,如果你想把键映射到已经存在的值,会抛出IllegalArgumentException异常。如果对特定值,你想要强制替换它的键,请使用 BiMap.forcePut(key, value)。
Table
通常来说,当你想使用多个键做索引的时候,你可能会用类似Map<FirstName, Map<LastName, Person>>的实现,这种方式很丑陋,使用上也不友好。Guava为此提供了新集合类型Table,它有两个支持所有类型的键:”行”和”列”。Table提供多种视图,以便你从各种角度使用它:
- rowMap():用Map<R, Map<C, V>>表现Table<R, C, V>。同样的, rowKeySet()返回”行”的集合Set
。 - row(r) :用Map<C, V>返回给定”行”的所有列,对这个map进行的写操作也将写入Table中。
- 类似的列访问方法:columnMap()、columnKeySet()、column(c)。(基于列的访问会比基于的行访问稍微低效点)
- cellSet():用元素类型为Table.Cell<R, C, V>的Set表现Table<R, C, V>。Cell类似于Map.Entry,但它是用行和列两个键区分的。
Table有如下几种实现:
- HashBasedTable:本质上用HashMap<R, HashMap<C, V>>实现;
- TreeBasedTable:本质上用TreeMap<R, TreeMap<C,V>>实现;
- ImmutableTable:本质上用ImmutableMap<R, ImmutableMap<C, V>>实现;注:ImmutableTable对稀疏或密集的数据集都有优化
- ArrayTable:要求在构造时就指定行和列的大小,本质上由一个二维数组实现,以提升访问速度和密集Table的内存利用率。
集合工具类
Lists类提供的常用方法:

Sets类提供的工具方法:
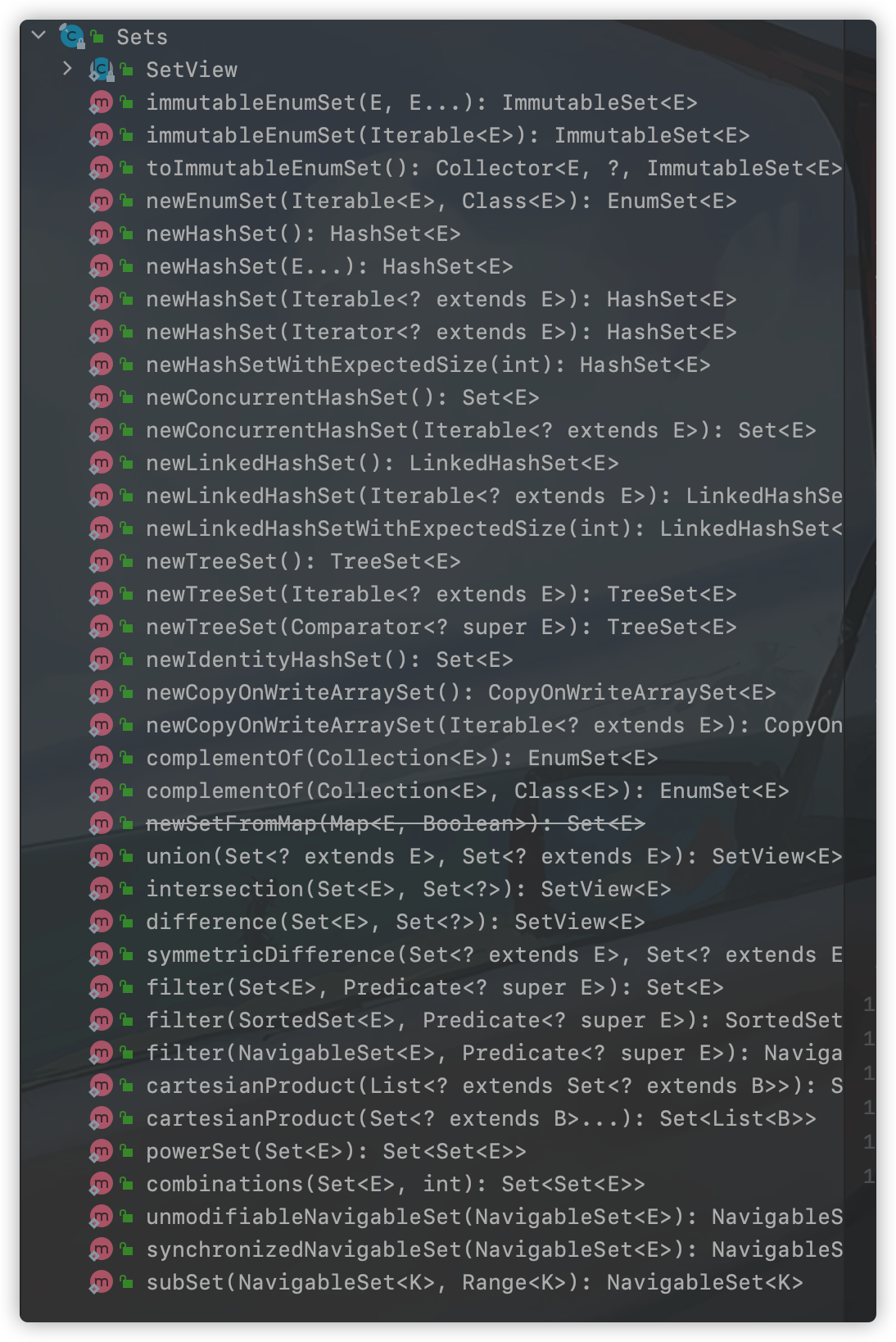
以上方法都是Guava对操作集合类工具方法封装,让开发者操作集合更加简便。
guava对Map提供的工具方法很多,使Map相关操作变得格外简单,以下是相关API:
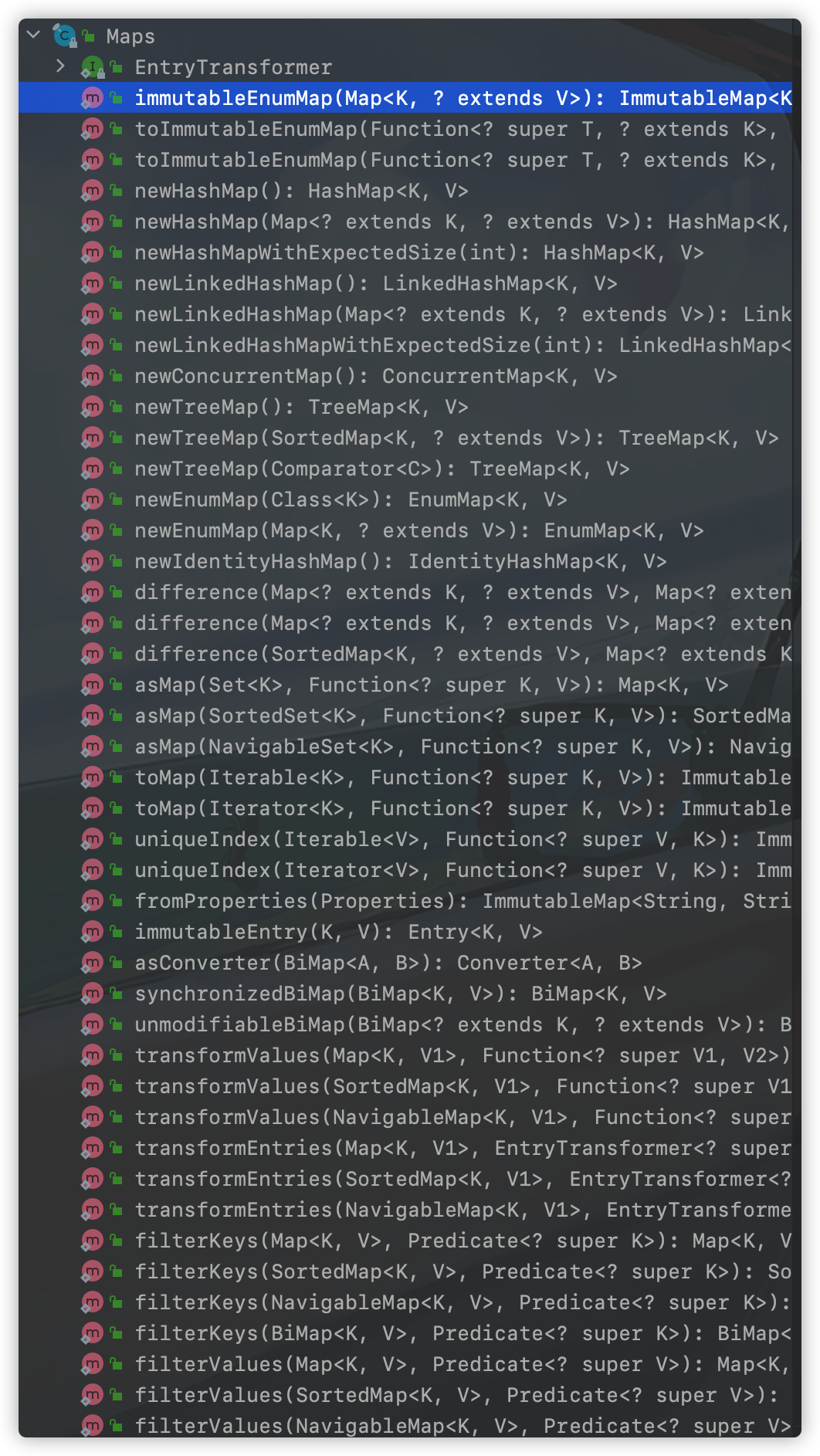
很多工具方法通过名字就明白其使用场景。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号