Kafka集群部署 (守护进程启动)
1、Kafka集群部署
1.1集群部署的基本流程
下载安装包、解压安装包、修改配置文件、分发安装包、启动集群
1.2集群部署的基础环境准备
安装前的准备工作(zk集群已经部署完毕)
关闭防火墙
chkconfig iptables off && setenforce 0
创建用户
groupadd kafka && useradd kafka && usermod -a -G kafka kafka
创建工作目录并赋权
mkdir -p /home/tuzq/software/kafka mkdir -p /home/tuzq/software/kafka/servers chmod 755 -R /home/tuzq/software/kafka
切换到kafka用户下
su kafka (本次实验,笔者使用root用户,即模拟在root下的安装。实际生产环境安装时请在指定用户下安装)
1.3 Kafka集群部署
1.3.1、下载安装包
http://kafka.apache.org/downloads.html
在linux中使用wget命令下载
wget http://mirrors.hust.edu.cn/apache/kafka/0.8.2.2/kafka_2.11-0.8.2.2.tgz1.3.2、解压安装包
tar -zxvf /home/tuzq/software/kafka_2.11-0.9.0.1.tgz -C /home/tuzq/software/kafka/servers/
cd /home/tuzq/software/kafka/servers/
ln -s kafka_2.11-0.9.0.1 kafka修改kafka的环境变量
vim /etc/profile
在文件的最底部写上:
#set kafka env
export KAFKA_HOME=/home/tuzq/software/kafka/servers/kafka
export PATH=$PATH:$KAFKA_HOME/bin
保存,然后执行:
source /etc/profile1.3.3、修改配置文件
[root@hadoop1 kafka]# cp /home/tuzq/software/kafka/servers/kafka/config/server.properties
/home/tuzq/software/kafka/servers/kafka/config/server.properties.bak
[root@hadoop1 kafka]# vim /home/tuzq/software/kafka/servers/kafka/config/server.properties
输入以下内容:
#broker的全局唯一编号,不能重复
broker.id=0
##用来监听链接的端口,producer或consumer将在此端口建立连接
port=9092
# 处理网络请求的线程数量
num.network.threads=3
# 用来处理磁盘IO的现成数量
num.io.threads=8
# 接受套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接受套接字的缓冲区大小
socket.receive.buffer.bytes=102400
# 请求套接字的缓冲区的大小
socket.request.max.bytes=104857600
# kafka运行日志存放的路径
log.dirs=/home/tuzq/software/kafka/servers/logs/kafka
# topic在当前broker上的分片个数
num.partitions=2
# 用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
# segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#滚动生成新的segment文件的最大时间
log.roll.hours=168
# 日志文件中每个segment的大小,默认为1G
log.segment.bytes=1073741824
# 周期性检查文件的时间,这里是300秒,即5分钟
log.retention.check.interval.ms=300000
##日志清理是否打开
log.cleaner.enable=true
#broker需要使用zookeeper保存meta数据
zookeeper.connect=hadoop11:2181,hadoop12:2181,hadoop13:2181
# zookeeper链接超时时间
zookeeper.connection.timeout.ms=6000
# partition buffer中,消息的条数达到阈值,将触发flush到磁盘
log.flush.interval.messages=10000
# 消息buffer的时间,达到阈值,将触发flush到磁盘
log.flush.interval.ms=3000
#删除topic需要server.properties中设置delete.topic.enable=true否则只是标记删除
delete.topic.enable=true
#此处的host.name为本机IP(重要),如果不改,则客户端会抛出:Producer connection to localhost:9092 unsuccessful 错误! (如果是hadoop2机器,下面配置成hadoop2)
host.name=hadoop1
#外网访问配置(如果是hadoop2的,下面是192.168.106.92)
advertised.host.name=192.168.106.91
1.3.4、分发安装包
将包分发到hadoop2和hadoop3上
[root@hadoop1 software]# pwd
/home/tuzq/software
[root@hadoop1 software]# scp -r kafka root@hadoop2:$PWD
[root@hadoop1 software]# scp -r kafka root@hadoop3:$PWD
然后分别在hadoop1机器上创建软连
[root@hadoop2 software]# cd /home/tuzq/software/kafka/servers/
[root@hadoop2 servers]# ls
kafka kafka_2.11-0.9.0.1
[root@hadoop2 servers]# rm -rf kafka
[root@hadoop2 servers]# ln -s kafka_2.11-0.9.0.1 kafka
[root@hadoop2 servers]#
在hadoop2上修改配置
[root@hadoop3 servers]# cd /home/tuzq/software/kafka/servers/
[root@hadoop3 servers]# ls
kafka kafka_2.11-0.9.0.1
[root@hadoop3 servers]# rm -rf kafka
[root@hadoop3 servers]# ls
kafka_2.11-0.9.0.1
[root@hadoop3 servers]# ln -s kafka_2.11-0.9.0.1 kafka
[root@hadoop3 servers]# ls
kafka kafka_2.11-0.9.0.1
[root@hadoop3 servers]#
修改kafka的环境变量
vim /etc/profile
在文件的最底部写上:
#set kafka env
export KAFKA_HOME=/home/tuzq/software/kafka/servers/kafka
export PATH=$PATH:$KAFKA_HOME/bin
保存,然后执行:
source /etc/profile1.3.5、再次修改配置文件(重要)
依次修改各服务器上配置文件的的broker.id,分别是0,1,2不得重复。
1.3.6、启动集群(注意在三台服务器上都要执行下面的命令)
依次在各节点上启动kafka
cd $KAFKA_HOME
bin/kafka-server-start.sh config/server.properties
让kafka后台运行:
[root@hadoop1 kafka]# bin/kafka-server-start.sh config/server.properties 1>/dev/null 2>&1 &
[1] 9412
[root@hadoop1 kafka]# jps
4624 DataNode
4241 DFSZKFailoverController
9475 Jps
9412 Kafka
5093 NodeManager
3981 JournalNode
4974 ResourceManager
4095 NameNode
[root@hadoop1 kafka]#
从上面可以看出有一个kafka进程 9412 Kafka
停止kafka的命令:
[root@hadoop1 kafka]# bin/kafka-server-stop.sh config/server.properties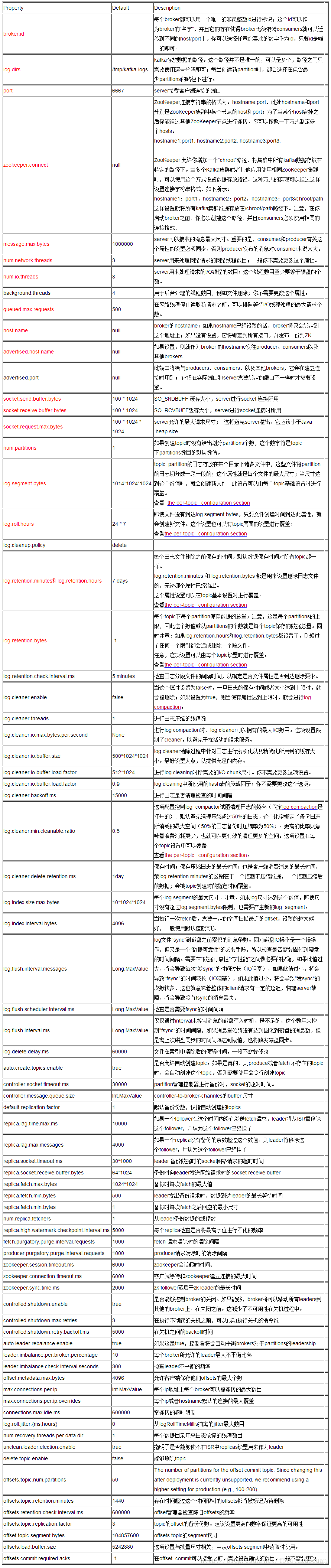


 浙公网安备 33010602011771号
浙公网安备 33010602011771号