
pandas与excel
一、创建excel
import pandas as pd df = pd.DataFrame() df.to_excel('C:/Temp/output.xls') print('Done!')
试着添加一些数据
import pandas as pd
df = pd.DataFrame({'ID': [1, 2, 3], 'Name': ['Tim', 'Victor', 'Nick']})
df.to_excel('C:/Temp/output.xls')
print('Done!')
效果图: 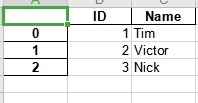
使用‘ID’为excel的索引
df = df.set_index('ID')
效果图: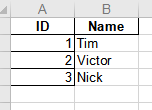
二、读取excel
import pandas as pd
people = pd.read_excel('C:/Temp/People.xlsx')
print(people.shape) # 打印文件(行数, 列数)---输出结果:(19972, 6)
print(people.columns)
# 打印出列名----输出结果:
# Index(['ID', 'Type', 'Title', 'FirstName', 'MiddleName', 'LastName'], dtype='object')
print(people.head()) # 打印头部(默认前5行)
print(people.head(3)) # 打印前3行
print(people.tail(3)) # 打印末尾3行
people = pd.read_excel('C:/Temp/People.xlsx', header=1) # 假如excel第一行数据为"脏数据",以第二行为标题行(程序以0开始计数)
people = pd.read_excel('C:/Temp/People.xlsx') # 假如第一行为空,不用加header,照样可以识别标题行
# 假如没有标题行,第一行为正常数据,可自定义标题行
people = pd.read_excel('C:/Temp/People.xlsx', header=None)
people.columns =['ID', 'Type', 'Title', 'FirstName', 'MiddleName', 'LastName']
print(people.columns)
people = people.set_index('ID', inplace=True)
people.to_excel('C:/Temp/output.xlsx')
# 打开文件后再次保存,会自动生成序列号(0, 1, 2, 3……)
df = pd.read_excel('C:/Temp/output.xlsx')
df.to_excel = ('C:/Temp/output2.xlsx')
# 解决方法:打开时,指定index列
df = pd.read_excel('C:/Temp/output.xlsx', index_col='ID')
import pandas as pd
# 字典转换为序列
df = {'x':100, 'y':200, 'z':300}
s1 = pd.Series(df)
print(s1)
输出结果:
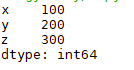
转换为序列方法2:
L1 = [100, 200, 300] L2 = ['x', 'y', 'z'] s1 = pd.Series(L1, index=L2) print(s1)
输出结果:
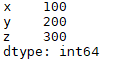
三、读取数据,自动填充数字
原始excel表:
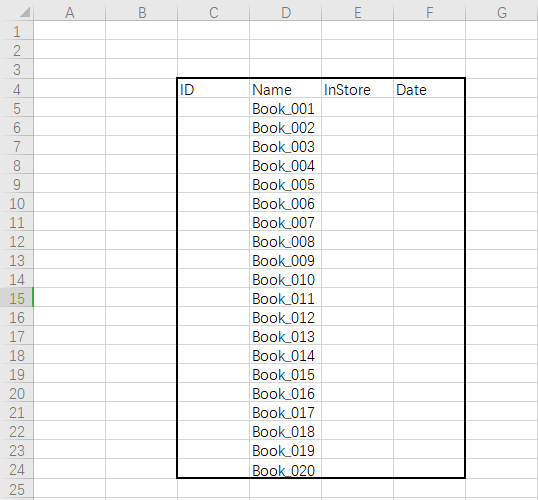
1、读取数据
import pandas as pd
#books = pd.read_excel('D:/temp/Books.xlsx')
books = pd.read_excel('D:/temp/Books.xlsx', skiprows=3, parse_cols='C:F', index_col=None)
books['ID'].at[0] = 100
# ID列第一行数据写入100
# 注意:如果pandas版本使用0.21.0及以上,parse_col则改为usecols
import pandas as pd
#books = pd.read_excel('D:/temp/Books.xlsx')
books = pd.read_excel('D:/temp/Books.xlsx', skiprows=3, parse_cols='C:F', index_col='ID')
# skiprows=3 忽略前三行空白行;parse_cols='C:F' 只取C列到F列数据; index_col='ID' 以ID列为索引列
2、写入数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号