
Python爬虫系列(三):requests高级耍法
昨天,我们更多的讨论了request的基础API,让我们对它有了基础的认知。学会上一课程,我们已经能写点基本的爬虫了。但是还不够,因为,很多站点是需要登录的,在站点的各个请求之间,是需要保持回话状态的,有的站点还需要证书验证,等等这一系列的问题,我们将在今天这一环节,加以讨论。
1.会话对象
会话:session,就是你点进这个站点后,由浏览器与服务器之间保持的一次连接。这次连接里面,你跳转页面,或发起其他请求,服务器要求某些数据验证。服务器不会叫你在每次跳转时候进行验证,而是用已验证的结果进行跳转。这样就节省服务器资源,底层的TCP连接也会被重用。
跨请求保持数据(客户端存数据):
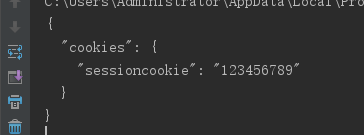
s = requests.Session()
s.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
r = s.get("http://httpbin.org/cookies")
print(r.text)
回话提供请求默认数据(数据会被存到服务端):
s = requests.Session()
s.auth = ('user', 'pass')
s.headers.update({'x-test': 'true'})
# 'x-test' 和 'x-test2' 一起发送给url
s.get('http://httpbin.org/headers', headers={'x-test2': 'true'})
注意:即便使用了session,方法级别的参数,仍然不会再跨请求保持。
以下代码,另个请求分别有自己的cookies
s = requests.Session()
r = s.get('http://httpbin.org/cookies')
print(r.text)
# '{"cookies": {}}'
r = s.get('http://httpbin.org/cookies', cookies={'from-my': 'browser'})
print(r.text)
# '{"cookies": {"from-my": "browser"}}'
会话上下文管理器:是指用with 块限定会话对象的使用范围
with requests.Session() as s:
s.get('http://httpbin.org/cookies/set/sessioncookie/123456789')
2.请求与响应对象
任何时候,我们往服务器发消息,都会返回一个response的响应对象,同时,还能获得我们自己创建的request对象
r = requests.get('http://en.wikipedia.org/wiki/Monty_Python')
print (r.headers)
print (r.request.headers)
在发送请求之前,需要对body获header做一些额外处理,使用如下方法:
from requests import Request, Session
s = Session()
req = Request('GET', url,
data=data,
headers=header
)
#要想获取有状态的请求,使用:
prepped = s.prepare_request(req)
而不是使用:
prepped = req.prepare()
# do something with prepped.body
# do something with prepped.headers
resp = s.send(prepped,
stream=stream,
verify=verify,
proxies=proxies,
cert=cert,
timeout=timeout
)
print(resp.status_code)
3.SSL 证书验证
requests.get('https://requestb.in')
requests.get('https://github.com', verify=True)
requests.get('https://github.com', verify='/path/to/certfile')
# 将验证路径保持在会话中
s = requests.Session()
s.verify = '/path/to/certfile'
# 忽略对SSL的验证
requests.get('https://kennethreitz.org', verify=False)
4.客户端证书
requests.get('https://kennethreitz.org', cert=('/path/client.cert', '/path/client.key'))
#证书在会话中
s = requests.Session()
s.cert = '/path/client.cert'
注意:本地证书的私有 key 必须是解密状态。目前,Requests 不支持使用加密的 key。
这里补充一句:当登录12306时喊你要安装证书。当向有证书验证要求的站点,就使用上面的代码
http://5.CA 证书 科普:
Requests 默认附带了一套它信任的根证书,来自于 Mozilla trust store。然而它们在每次 Requests 更新时才会更新。这意味着如果你固定使用某一版本的 Requests,你的证书有可能已经 太旧了。
从 Requests 2.4.0 版之后,如果系统中装了 certifi 包,Requests 会试图使用它里边的 证书。这样用户就可以在不修改代码的情况下更新他们的可信任证书。
6.响应体内容工作流
import requests
# 默认情况下,发起请求会同时下载响应头和响应体(就是响应内容)
tarball_url = 'https://github.com/kennethreitz/requests/tarball/master'
# 如果将stream=True 则会推迟响应内容的下载
r = requests.get(tarball_url, stream=True)
# 这里就是:满足某种条件才去下载
if int(r.headers['content-length']) < TOO_LONG:
content = r.content
# 在请求中把 stream 设为 True,Requests 无法将连接释放回连接池,
# 除非消耗了所有的数据,或者调用了 Response.close。
# 这样会带来连接效率低下的问题。如果在使用 stream=True 的同时还在部分读取请求的 body(或者完全没有读取 body),
# 那么就应该使用 with 语句发送请求,这样可以保证请求一定会被关闭
with requests.get('http://httpbin.org/get', stream=True) as r:
# 这里处理响应
content = r.content
7.保持活动状态(持久连接)科普
同一会话内的持久连接是完全自动处理的,同一会话内你发出的任何请求都会自动复用恰当的连接。
注意:只有所有的响应体数据被读取完毕连接才会被释放回连接池;所以确保将 stream 设置为 False 或读取 Response 对象的 content 属性。
8.流式上传
Requests支持流式上传,这允许发送大的数据流或文件,而无需先把它们读入内存。要使用流式上传,需,为请求体,提供一个类文件对象即可:
with open('massive-body') as f:
requests.post('http://some.url/streamed', data=f)
注意的问题:
最好使用二进制模式打开文件。这是因为 requests 有默认设置 header 中的 Content-Length,在这种情况下该值会被设为文件的字节数。如果用文本模式打开文件,就可能碰到错误
9.块编码请求
对于出去和进来的请求,Requests 也支持分块传输编码。要发送一个块编码的请求,仅需为请求体提供一个生成器(或任意没有具体长度的迭代器)
def gen():
yield 'hi'
yield 'there'
requests.post('http://some.url/chunked', data=gen())
注意:
对于分块的编码请求,最好使用 Response.iter_content() 对其数据进行迭代。在理想情况下,request 会设置 stream=True,这样就可以通过调用 iter_content 并将分块大小参数设为 none,从而进行分块的迭代。如果要设置分块的最大体积,可以把分块大小参数设为任意整数。
说白了,就是段点续传
妹的,报了一堆错。先记录在这,后面遇到了再研究
10.POST 多个分块编码的文件
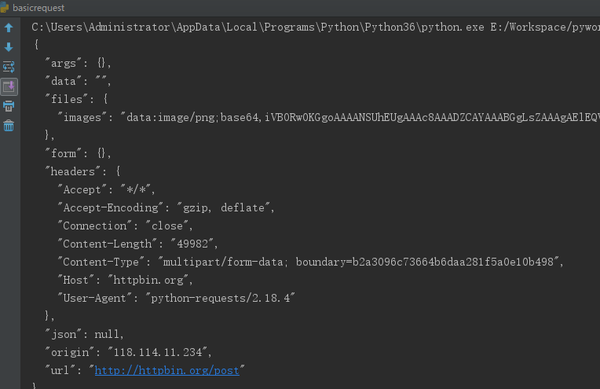
上传图片
import requests
url = 'http://httpbin.org/post'
multiple_files = [
('images', ('foo.png', open('foo.png', 'rb'), 'image/png')),
('images', ('bar.png', open('bar.png', 'rb'), 'image/png'))]
r = requests.post(url, files=multiple_files)
print (r.text)
11.事件挂钩
import requests
def print_url(r, *args, **kwargs):
print(r.url)
# Requests有一个钩子系统,你可以用来操控部分请求过程,或信号事件处理。
# 在产生响应之前调用print_url 就是server响应之前的回调
hooks = dict(response=print_url)
r = requests.get('http://httpbin.org', hooks=dict(response=print_url))
print (r.text)
也没看有什么用
12.自定义身份验证
import requests
from requests.auth import AuthBase
class PizzaAuth(AuthBase):
def __init__(self, username):
# setup any auth-related data here
self.username = username
def __call__(self, r):
# modify and return the request
r.headers['X-Pizza'] = self.username
return r
#注意:auth参数必须是一个可调用对象 实现了 __call__ 方法
requests.get('http://pizzabin.org/admin', auth=PizzaAuth('kenneth'))
作用就是在请求发出之前,有机会修改请求
13.流式请求
import requests
r = requests.get('http://httpbin.org/stream/20', stream=True)
for line in r.iter_lines():
# filter out keep-alive new lines
if line:
decoded_line = line.decode('utf-8')
print(json.loads(decoded_line))
就是将请求参数设置stream=True
import requests
r = requests.get('http://httpbin.org/stream/20', stream=True)
#当使用 decode_unicode=True 在 Response.iter_lines() 或 Response.iter_content() 中#时,需要提供一个编码方式,以防服务器没有提供默认回退编码,从而导致错误
if r.encoding is None:
r.encoding = 'utf-8'#设置编码方式
for line in r.iter_lines(decode_unicode=True):
if line:
print(json.loads(line))
#注意:iter_lines 不保证重进入时的安全性。多次调用该方法 会导致部分收到的数据丢失。#如果要在多处调用它,就应该使用生成的迭代器对象:
lines = r.iter_lines()
# 保存第一行以供后面使用,或者直接跳过
first_line = next(lines)
for line in lines:
print(line)
不晓得各位看懂什么是流式请求没。指的不是请求是流,而是请求返回的数据流。返回一点即取一点。而不是普通的是返回完成后在取内容
14.代理
import requests
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080",
}
requests.get("http://example.org", proxies=proxies)
代理:就是你访问一个网站,其实并不是你直接访问的,而是你发请求给A机器,A机器取请求B机器。B返回给A,A再返回给你。代理就是中间人的意思。为什么需要代理?因为:反爬虫网站一般使用IP来识别一个机器。老是一个IP再不停访问网站,该网站就会把这个IP拉入黑名单,不允许访问。这时,就需要很多IP再扰乱反爬虫工具的思维,避免封IP。
15.SOCKS
除了基本的 HTTP 代理,Request 还支持 SOCKS 协议的代理。这是一个可选功能,若要使用, 你需要安装第三方库。
在后面的项目实战中,我们将会使用
16.HTTP动词
GET、OPTIONS、HEAD、POST、PUT、PATCH、DELETE
GET POST最常用
PUT,DELETE在调用rest的接口时,也会用到
17.定制动词
有些服务器不接受GET POST等,要求用自定义的,就使用如下方法
r = requests.request('MKCOL', url, data=data)
r.status_code
18.响应头链接字段
许多 HTTP API 都有响应头链接字段的特性,它们使得 API 能够更好地自我描述和自我显露。
比如在使用分页的情况下最有用
url = 'https://api.github.com/users/kennethreitz/repos?page=1&per_page=10'
r = requests.head(url=url)
print(r.headers['link'])
print(r.links["next"])
19.阻塞和非阻塞
使用默认的传输适配器,Requests 不提供任何形式的非阻塞 IO。 Response.content 属性会阻塞,直到整个响应下载完成。如果你需要更多精细控制,该库的数据流功能(见 流式请求) 允许你每次接受少量的一部分响应,不过这些调用依然是阻塞式的。
如果你对于阻塞式 IO 有所顾虑,还有很多项目可以供你使用,它们结合了 Requests 和 Python 的某个异步框架。典型的优秀例子是 grequests 和 requests-futures。
20.Header 排序
在某些特殊情况下你也许需要按照次序来提供 header,如果你向 headers 关键字参数传入一个OrderedDict,就可以向提供一个带排序的 header。然而,Requests 使用的默认 header 的次序会被优先选择,这意味着如果你在 headers 关键字参数中覆盖了默认 header,和关键字参数中别的 header 相比,它们也许看上去会是次序错误的。
如果这个对你来说是个问题,那么用户应该考虑在 Session 对象上面设置默认 header,只要将 Session 设为一个定制的 OrderedDict 即可。这样就会让它成为优选的次序。
以上内容,是request的高级耍法,也不算好高级。接下来的一周,我们将着重讨论如何解析网页。当然,这一部分内容不会包含JS生成的HTML。这个我们将会在项目实战环节再讨论。
最近培训新人,搞得很晚才下班。精力不够哇。若是喜欢我的系列文章,还请帅哥美女点个赞,足矣

