
Python操作rabbitmq系列(六):进行RPC调用
此刻,我们已经进入第6章,是官方的最后一个环节,但是,并非本系列的最后一个环节。因为在实战中还有一些经验教训,并没体现出来。由于马上要给同事没培训celery了。我也来不及写太多。等后面,我们再慢慢补充。
RPC:是远程过程调用。百度写了一大堆。此刻,我们简单点说:比如,我们在本地的代码中调用一个函数,那么这个函数不一定有返回值,但一定有返回。若是在分布式环境中,香我们前几章的例子,发送消息出去后,发送端是不清楚客户端处理完后的结果的。由于rabbitmq的响应机制,顶多能获取到客户端的处理状态,但并不能获取处理结果。那么,我们想像本地调用那样,需要客户端处理后返回结果该怎么办呢。就是如下图:
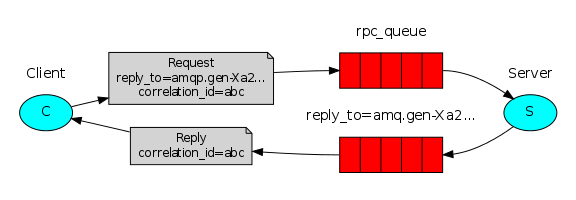
client发送请求,同时告诉server处理完后要发送消息给:回调队列的ID:correlation_id=abc,并调用replay_to回调队列对应的回调函数。请上代码:
客户端:
客户端:发消息也收消息
import pika
import uuid
class FibonacciRpcClient(object):
def __init__(self):
# 创建连接
self.connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
self.channel = self.connection.channel()
# 创建回调队列
result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue
# 这里:这个是消息发送方,当要执行回调的时候,它又是接收方
# 使用callback_queue 实现消息接收。即是回调。注意:这里的回调
# 不需要对消息进行确认。反复确认,没玩没了就成了死循环
#这里设置回调
self.channel.basic_consume(self.on_response, no_ack=True,
queue=self.callback_queue)
# 定义回调的响应函数。
# 判断:若是当前的回调ID和响应的回调ID相同,即表示,是本次请求的回调
# 原因:若是发起上百个请求,发送端总得知道回来的对应的是哪一个发送的
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
# 设置响应和回调通道的ID
self.response = None
self.corr_id = str(uuid.uuid4())
# properties中指定replay_to:表示回调要调用那个函数
# 指定correlation_id:表示回调返回的请求ID是那个
# body:是要交给接收端的参数
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=self.corr_id,
),
body=str(n))
# 监听回调
while self.response is None:
self.connection.process_data_events()
# 返回的结果是整数,这里进行强制转换
return int(self.response)
fibonacci_rpc = FibonacciRpcClient()
print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call(30)
print(" [.] Got %r" % response)
服务端:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='rpc_queue')
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n - 1) + fib(n - 2)
def on_request(ch, method, props, body):
#收到的消息
n = int(body)
print(" [.] fib(%s)" % n)
#要处理的任务
response = fib(n)
#发布消息。通知到客户端
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id= props.correlation_id),
body=str(response))
#手动响应
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request, queue='rpc_queue')
print(" [x] Awaiting RPC requests")
channel.start_consuming()
结果:

OK,我们的rabbitmq系列,就暂时告一段落。这其中还有一个实际的问题,我们还没有解决。就是:一个消息到达队列,我们需要多少个消费端去处理,这些消费端又该如何进行管理,比如:那些消费端工作已经做完,那些有出异常挂掉,队列除了使用prefetch_count属性又该如何进一步来平衡各消费端的负载等等。看样子我们还有很多事要做

